공부한 것들
질문 리뷰
Q. 파이썬과 자바는 인터프리터? 컴파일? (컴파일과 런타임)
기계어(Machine Language) : CPU 가 직접 이해할 수 있는 0 과 1 로 구성된 이진 코드
어셈블리어(Assembly Language) : 기계어에 대한 프로그래밍 저급 언어로 기계어와 1:1 매핑됨
사람이 쓰는 개발언어를 기계어로 번역해주는 것이 컴파일러(Compiler) 와 인터프리터(Interpreter)
컴파일러(Compiler) : 고급 프로그래밍 언어로 작성된 프로그램 소스 코드 전체를 스캔해서 이를 모두 기계어로 한번에 번역해서 실행파일을 생성
- C++, Java, Kotlin 등에서 컴파일러 사용
- 장점
- 초기 스캔은 오래 걸리나, 한번 스캔을 마치고 나면 실행파일을 만들어두고 계속 사용하기 때문에 실행 속도는 인터프리터보다 빠름
- 오류 메시지 생성시 전체 코드를 검사한 후 오류 메시지를 생성하기에 실행 전 오류를 발견할 수 있음
- 배포 시 소스코드가 아닌 실행 파일을 제공하기 때문에 소스코드가 노출되지 않아 보안성이 높음
- 생성된 실행파일은 컴파일된 환경과 무관하게 독립적으로 실행이 가능함
- 단점
- 소스가 길고 복잡해질수록 초기 스캔시간 및 컴파일 시간이 길어짐
- 기계어로 번역시 오브젝트 코드(Object Code) 파일을 만드는데, 이를 다시 묶어서 하나의 실행 파일로 만드는 링킹(Linking) 작업을 해야함.
그러므로 인터프리터보다 많은 메모리를 사용함
인터프리터(Interpreter) : 고급 프로그래밍 언어로 작성된 프로그램 소스 코드를 한 줄씩 읽고 즉시 실행
- Python, JavaScript, Ruby 등이 인터프리터 언어
- 장점
- 코드를 한 줄씩 실행하기 때문에, 에러를 빠르게 찾고 수정할 수 있으며, 코드 변경시 빌드 과정이 따로 필요 없어 테스트 및 개발 속도가 빠른편
- 링킹 과정을 거치지 않기 때문에 메모리 효율이 좋음
- 소스 코드만 있다면 다양한 플랫폼에서 실행 가능
- 단점
- 매번 코드를 한 문장씩 읽고 번역하고 실행하는 과정을 거치기 때문에 컴파일러에 비해 실행 속도가 느림
- 모든 소스를 사전에 검사하지 않기 때문에 런타임 도중에만 발견되는 오류를 미리 확인할 수 없음
런타임(Runtime) : 특정 프로그램이 실제로 실행되는 동안의 동작
특정 프로그램이 필요로 하는 시스템 자원(RAM, 시스템 변수, 환경변수 등) 을 할당받고 실제로 시스템 자원을 사용해 어떠한 처리를 하는 동작
런타임 환경(Runtime Environment) : 애플리케이션이 OS 의 시스템 자원(RAM, 시스템 변수, 환경변수 등) 에 액세스 할 수 있도록 해주는 실행 환경
Q. i 와 I 는 같은 자료형인가?
자료형은 같게 저장할 수 있으나 각 자료형 별 저장된 값이 상이할 수 있음
- i 와 I 를 자료형 별로 저장시
- char : 기본 문자 자료형 그대로 저장
- String : 문자나 문자열 저장
- int, byte, short, long : ASCII/유니코드 값으로 저장
- Character : 래퍼 클래스로 저장
- float, double : ASCII/유니코드 값을 부동소수점으로 변환해서 저장
Q. 객체자료형의 특징
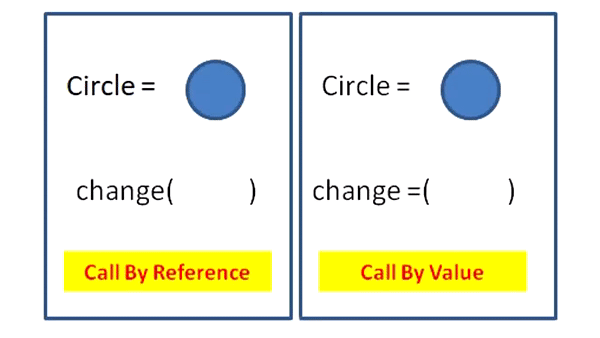
Q. Call By Value 와 Call By Reference
Call By Value(값에 의한 호출)
- 함수가 인수로 전달받은 값을 복사하여 처리하는 방식
- 변수가 가진 값을 복사하여 전달하므로 원본 값은 변경되지 않음. 값의 불변성(Immutability) 을 유지하는데 용이
- 실제 인수는 다른 메모리 위치에 생성됨
Call By Reference(참조에 의한 호출)
- 값의 주소를 참조해서 직접 값에 영향을 주는 방식
- 변수 값을 변경하면, 호출한 쪽에서 해당 변수의 값이 변경됨.
이는 전달되는 값이 변수의 주소이므로, 변수의 값을 변경하면 해당 주소에 저장된 값이 변경되기 때문 - 실제 인수는 같은 메모리 위치에 생성됨
- Call By Reference 에서 기존 값이 영향 받는 단점을 보완할 수 있는 방법으로 깊은 복사(Deep Copy) 를 이용하는 방법이 있음.
Q. 깊은복사와 얕은복사
-
깊은 복사(Deep Copy)
- 실제 값 복사
- 객체의 모든 필드를 복사해서 새로운 객체를 생성함. 객체의 상태를 완전히 복제할 때 사용
- 메모리를 많이 사용하고, 복사 과정에서 성능 저하 발생할 수 있음 -
얕은 복사(Shallow Copy)
- 주소 값 복사
- 객체의 참조 주소만 복사하여 새로운 객체를 생성함. 객체의 참조 주소만 복사하기 때문에 원본 객체와 복사된 객체가 동일한 데이터를 참조
- 메모리를 적게 사용하고, 성능이 뛰어남. 하지만 참조된 데이터를 변경하면 원본 데이터에도 영향을 끼침
| 특징 | 얕은 복사 (Shallow Copy) | 깊은 복사 (Deep Copy) |
|---|---|---|
| 복사 방식 | 1차 데이터만 복사, 참조 데이터는 주소 복사 | 모든 데이터와 참조 데이터까지 재귀적으로 복사 |
| 원본과의 독립성 | 복사본과 원본이 참조 데이터 공유 | 복사본과 원본이 완전히 독립적 |
| 수행 속도 | 상대적으로 빠름 | 상대적으로 느림 |
| 메모리 사용량 | 원본과 공유하므로 적음 | 복제된 데이터를 저장하므로 많음 |
| 데이터 변경 영향 | 참조 데이터 변경 시 원본에 영향 | 복사본 변경 시 원본에 영향 없음 |
과제
기초 단계 질문(기본 개념)
Q. 자료형이란 무엇이며, 왜 필요한가요?
자료형(Data Type) : 데이터를 구성하고 관리하는 기본 개념으로, 데이터의 크기, 형식, 해석 방식을 정의.
자료형의 필요&중요 이유
- 데이터, 메모리 관리
- 자료형은 데이터의 크기와 형식을 정의하는데, 이때 자료형을 명시함으로서 프로그램이 데이터를 메모리에 효율적으로 저장 및 관리할 수 있음
- 코드의 명확성(유지보수성)
- 자료형 명시로 인해 해당 데이터가 어떤 역할을 하는지 쉽게 파악할 수 있기에 가독성이 올라감
- 유효성 검사 및 에러 검출
- 자료형은 데이터의 유효성을 보장함. 잘못된 데이터 사용시 컴파일러 혹은 런타임이 감지하고 에러를 검출할 수 있음
- 성능
- 자료형이 명확하면 기계의 해석시 데이터에 적합한 연산을 선택하기에 성능 최적화 가능
Q. 정적 타입과 동적 타입의 차이점은 무엇인가요?
| 특징 | 정적 타입 | 동적 타입 |
|---|---|---|
| 타입 결정 시점 | 컴파일 시점 | 런타임 시점 |
| 자료형 선언 | 명시적으로 선언하거나 컴파일러가 추론 | 선언 필요 없음 |
| 타입 검사 | 컴파일러가 타입을 검사 | 런타임에 인터프리터가 타입을 검사 |
| 유연성 | 낮음 | 높음 |
| 오류 탐지 시점 | 컴파일 단계에서 오류를 탐지 | 런타임에서 오류를 탐지 |
| 주요 언어 | C, C++, Java, TypeScript, Go | Python, JavaScript, Ruby, PHP |
| 성능 | 일반적으로 빠름 | 상대적으로 느릴 수 있음 |
Q. 기본 데이터 타입(primitive types) 과 참조 타입(reference types) 의 차이는 무엇인가요?
기본 데이터 타입(primitive types) : 기본적인 데이터 구조로 값 자체를 메모리에 저장하기에 크기가 고정되어 있음
참조 타입(reference types) : 실제 데이터는 메모리의 다른 위치에 저장되고, 변수는 해당 데이터의 참조(주소)를 저장함. 주로 객체, 배열, 함수 등의 복잡한 데이터 구조를 다룸
| 특징 | Primitive Types | Reference Types |
|---|---|---|
| 저장 방식 | 값 자체를 저장 | 값의 메모리 주소를 저장 |
| 메모리 할당 | 스택(Stack) | 힙(Heap)에 데이터 저장, 스택에는 참조 저장 |
| 크기 | 고정 크기 | 크기가 동적 |
| 값 복사 | 값을 복사 (독립적) | 참조를 복사 (공유됨) |
| 변경 가능성 | 대부분 불변 | 대부분 변경 가능 |
| 성능 | 빠름 | 참조를 따라가야 하므로 상대적으로 느릴 수 있음 |
| 주요 예시 | 숫자, 문자, 불리언 등 | 객체, 배열, 리스트, 함수 등 |
Q. 타입변환
타입변환 : 하나의 데이터 타입을 다른 데이터 타입으로 변환하는 과정으로 서로 다른 데이터 타입 간의 연산이나 호환성을 위해 사용함
명시적 형변환(Explicit Conversion)
- 정의
- 개발자가 명시적으로 변환 함수 혹은 캐스팅 연산자를 사용해 데이터 타입 변환을 요청
- 타입 캐스팅(Type Casting)으로 불림 - 특징
- 개발자의 명확한 의도 파악 가능
- 변환 과정에서 데이터 손실 발생 가능
묵시적 형변환(Implicit Conversion)
- 정의
- 컴파일러나 인터프리터가 자동으로 데이터 타입을 변환하는 방식 - 특징
- 개발자가 직접 변환 코드를 작성하지 않음
- 시스템이 변환해도 된다고 판단하는 경우 변환을 자동으로 수행함
- 데이터 손실이 일어나지 않음
주의사항
- 묵시적 변환시에는 자동변환되어 예상치 못한 결과값이 도출될 수 있음
- 명시적 변환 시 데이터의 크기나 범위가 다를 경우 데이터 손실이 일어날 수 있음
Q. 묵시적 형변환과 명시적 형변환의 차이점은 무엇인가요?
| 특징 | 명시적 변환 (Explicit Conversion) | 묵시적 변환 (Implicit Conversion) |
|---|---|---|
| 변환 요청 주체 | 개발자가 명시적으로 요청 | 컴파일러나 인터프리터가 자동 수행 |
| 코드 가독성 | 변환 과정이 명확히 드러남 | 변환 과정이 코드에 드러나지 않음 |
| 데이터 손실 가능성 | 발생할 수 있음 | 안전한 변환만 수행 |
| 사용 용이성 | 변환 함수나 캐스팅 연산자를 명시적으로 사용해야 함 | 추가 코드 작성 없이 자동 변환 |
| 변환 방향 | 데이터 크기와 무관하게 변환 가능 | 작은 크기/범위 → 큰 크기/범위로만 변환 |
Q. 형변환 시 발생할 수 있는 데이터 손실은 어떤 경우에 일어나나요?
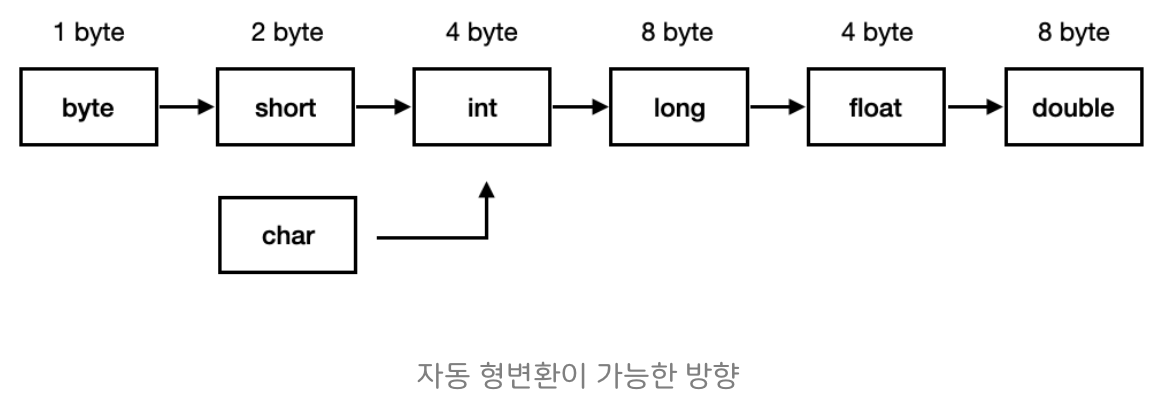
long 은 8byte float 는 4byte 인데 왜 long->float 가 가능한지?
-> 일반적으로 메모리 설계상 정수 타입보다 실수 타입이 더 크게 되어있기 때문
char 타입은 문자 자료형이지만, 아스키 코드 숫자를 저장하기에 사실상 정수형 타입으로 볼 수 있음
범위 초과
오버플로(Overflow) / 언더플로(Underflow)
큰 자료형에서 작은 자료형으로 변환 시(ex long->int) 표현 범위를 벗어나는 부분은 잘리거나 왜곡된 값으로 변환될 수 있음
크기 축소 변환
크기 축소 변환 : 큰 범위(크기) 의 데이터 타입에서 작은 범위(크기) 의 데이터 타입으로 변환시 일부 데이터가 잘리거나 왜곡될 수 있음
ex) 큰 정수형 -> 작은 정수형 변환 시 데이터가 잘리거나 왜곡 되어 예상치 못한 데이터 발생(long->short) 에서 long 데이터가 short 로 담을 수 없는 경우
정밀도 손실
정밀도 손실 : 데이터 변환 시 원래 값의 정밀도가 유지되지 못할 수 있음
ex) 실수->정수 변환 시 소수점 이하가 잘려나가고 부동소수점 연산(float->double, double->float) 에서 반올림 오차 발생 가능
중급 단계 질문(메모리와 자료형
Q. 각 자료형이 메모리에서 어떻게 저장되나요?
메모리 구조
-
코드 영역 (Text Segment)
- 실행할 프로그램의 코드가 저장.
- 보통 읽기 전용.
-
데이터 영역 (Data Segment)
- 전역 변수와 정적 변수(static variables)가 저장.
- 프로그램이 종료될 때까지 유지. -
힙 영역 (Heap)
- 동적 메모리 할당에 사용.
- 런타임에 필요에 따라 크기가 증가하거나 감소. -
스택 영역 (Stack)
- 함수 호출 시 사용되는 지역 변수와 매개변수가 저장.
- LIFO(Last In, First Out) 구조로 빠르게 접근.
기본 자료형(Primitive Types) 저장 방식
- 특징
- 메모리에 값을 직접 저장- 보통 크기가 고정되어 있음
- 저장 흐름
- int
- 정수는 2진수로 변환되어 메모리에 저장됨
int a = 10; -> 10을 2진수 00000000 00000000 00000000 00001010 로 변환 후 메모리에 4바이트 크기로 저장
- 정수는 2진수로 변환되어 메모리에 저장됨
- float, double
- 부동소수점 표현방식(IEEE 754 표준)을 사용
float a = 1.23; -> 1.23을 부동소수점 형식으로 변환 후 메모리에 4바이트 크기로 저장
- 부동소수점 표현방식(IEEE 754 표준)을 사용
- char
- 문자 하나를 저장하며 ASCII 혹은 Unicode 로 변환
char a = 'A'; -> A 를 ASCII 값 65로 변환 후 메모리에 1바이트 크기로 저장
- 문자 하나를 저장하며 ASCII 혹은 Unicode 로 변환
- boolean
- 참 또는 거짓 값을 메모리에 1비트 혹은 1바이트를 사용하여 저장
참조 자료형(Reference Types) 저장 방식
- 특징
- 값 자체가 아니라 값의 메모리 주소(참조)를 저장
- 실제 데이터는 Heap 영역에 저장되고, 참조 변수는 Stack 영역에 저장
-
Object
-
객체 생성시 데이터는 힙 영역에 저장되고, 변수는 해당 객체의 메모리 주소를 저장함
class Example { int x = 10; } Example obj = new Example();obj 는 스택에 생성되고, 힙에 생성된 객체 Example 의 메모리 주소를 가지게 됨
-
-
Array
- 힙 영역에 저장되며, 스택에는 배열의 참조가 저장됨
array 는 스택에 저장되고, 배열 데이터 [1,2,3] 은 힙에 저장int[] array = {1,2,3};
- 힙 영역에 저장되며, 스택에는 배열의 참조가 저장됨
-
String
- 문자열은 힙에 저장되지만, 같은 값을 가진 문자열은 메모리 방지를 줄이기 위해 문자열 상수 풀(String Pool)에 저장되기도 함
| 자료형 | 저장 위치 | 저장 내용 |
|---|---|---|
| Primitive | 스택 | 값 자체 (예: int, float, char) |
| Reference | 스택 & 힙 | 스택에 참조(주소), 힙에 실제 데이터 저장 |
| 전역 변수 | 데이터 영역 | 프로그램 실행 동안 지속 |
| 동적 할당 | 힙 | 힙에 데이터 저장, 스택에 참조 저장 |
| 코드 | 코드 영역 | 실행할 명령어 저장 |
Q. 문자열이 메모리에 저장되는 방식은 어떻게 다른가요?
- 문자열의 특징
-
Immutable(불변성)
- Java 에서는 문자열은 불변이므로 문자열 생성 이후 내용 변경 불가능.
새로운 문자열이 만들어지면 기존 문자열 수정이 아닌 새로운 객체 생성
- Java 에서는 문자열은 불변이므로 문자열 생성 이후 내용 변경 불가능.
-
String Pool 사용
- Java 는 문자열 상수 풀(String Pool) 이라는 특별한 메모리 영역을 사용해서 문자열의 중복 생성을 방지하고 메모리 사용량을 최적화함
String str1 = "Hello"; String str2 = "Hello"; // str1과 동일한 문자열 참조
- 문자열 저장 방식
- new 연산자 이용
- 값의 중복 여부에 상관없이 힙 영역에 인스턴스가 생성됨.
- 문자열 리터럴 생성
- 리터럴 방식으로 저장시 힙 메모리 안의 String Pool 에 값을 저장함. 이후 똑같은 문자열을 저장하려고 하면 앞서 만들어둔 인스턴스의 주소값을 참조함
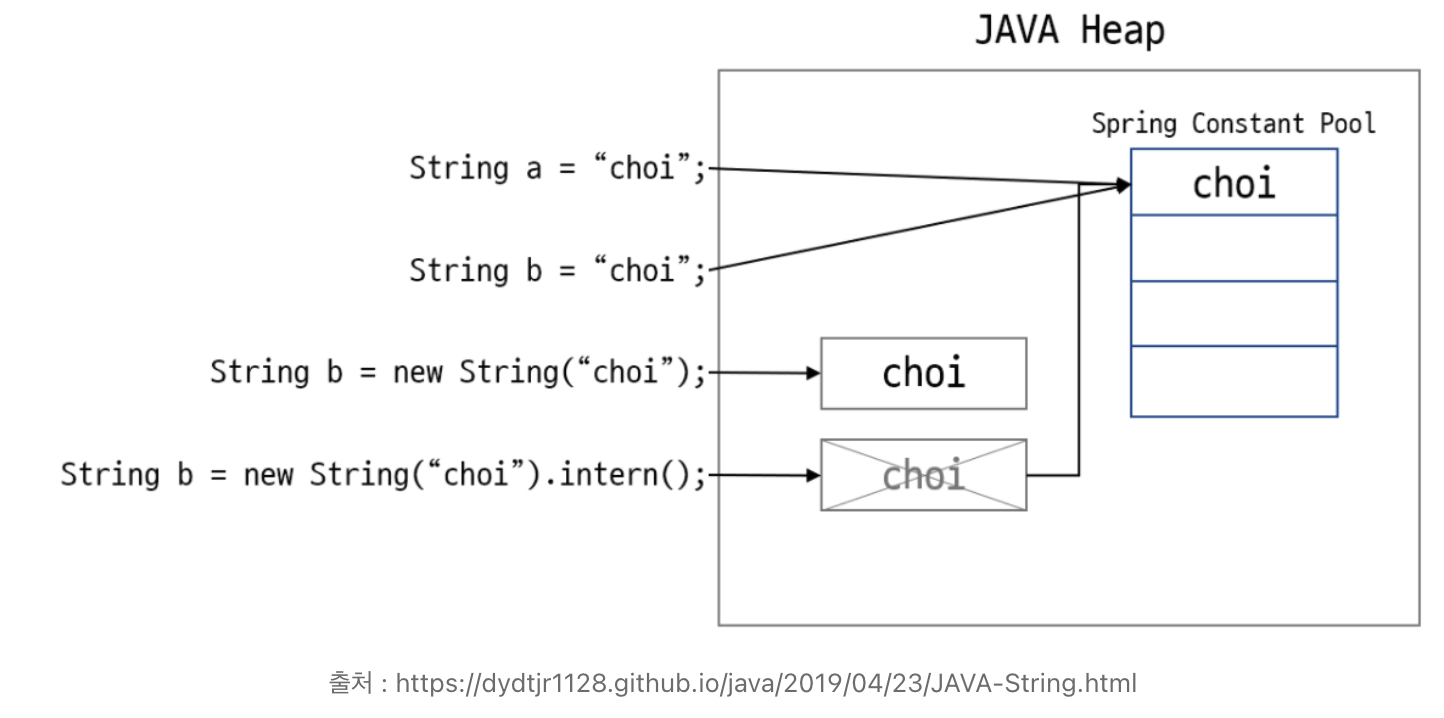
- 리터럴 방식으로 저장시 힙 메모리 안의 String Pool 에 값을 저장함. 이후 똑같은 문자열을 저장하려고 하면 앞서 만들어둔 인스턴스의 주소값을 참조함
Q. 포인터와 참조의 차이점은 무엇인가요?
포인터(Pointer)
- 메모리 주소 저장 변수
- 변수나 객체의 메모리 주소를 직접 조작 가능
참조(Reference)
- 변수나 객체에 대한 별칭(alias)
- 참조 사용시 변수 자체처럼 동작하지만, 실제로는 원본 데이터를 참조함
- 직접 주소를 조작하지 않음
| 특징 | 포인터 (Pointer) | 참조 (Reference) |
|---|---|---|
| 메모리 주소 | 메모리 주소를 저장 | 별칭(alias)로, 내부적으로 주소를 사용 |
| NULL 가능성 | NULL 값을 가질 수 있음 | NULL을 가질 수 없음 (항상 유효해야 함) |
| 선언 및 초기화 | 선언 후 초기화하지 않아도 됨 | 선언과 동시에 초기화가 필요 |
| 재할당 가능 여부 | 다른 주소를 가리키도록 변경 가능 | 초기화 이후 다른 객체를 참조할 수 없음 |
| 연산 가능 여부 | 주소를 기반으로 산술 연산 가능 | 직접 연산 불가 |
| 사용 목적 | 메모리 주소의 직접 조작, 동적 메모리 관리 | 변수나 객체에 대한 간편하고 안전한 접근 |
Q. 배열과 컬렉션
배열(Array)
- 동일한 타입의 요소를 연속적인 메모리 공간에 저장하는 고정 크기의 데이터구조
- 인덱스를 사용하여 요소에 접근하고, 인덱스는 0부터 시작함
- 특징
- 고정 크기 : 배열 크기는 선언 시점에 고정되고, 실행중 변경 불가
- 단일 타입 저장 : 동일한 데이터 타입의 요소만 저장 가능
- 인덱스를 통한 접근 : 인덱스를 통해 O(1) 시간 복잡도로 접근 가능
- 연속된 메모리 공간 사용 : 메모리에 연속적으로 저장되어있기에 데이터 처리 속도가 빠름
컬렉션(Collection)
- 객체의 그룹을 저장하고 조작하기 위한 데이터 구조로, 배열보다 유연함
- 크기가 동적이고, 다양한 데이터 타입의 요소를 저장할 수 있는 구조 제공
- 특징
- 동적 크기 : 컬렉션은 데이터의 추가/삭제에 따라 크기가 자동으로 조정됨
- 다양한 데이터 타입 : 대부분의 컬렉션은 여러 데이터 타입의 객체를 저장 가능
- 데이터 추가, 삭제, 검색, 정렬, 필터링 등의 기능 제공
- List, Set, Map 등의 인터페이스와 그 구현체 ArrayList, HashSet, HashMap 이 제공됨
- 비연속적 메모리 할당 : 요소가 반드시 연속된 메모리 공간에 저장되지 않아도 됨
| 특징 | 배열 (Array) | 컬렉션 (Collection) |
|---|---|---|
| 크기 | 고정 크기 | 동적 크기 |
| 데이터 타입 | 동일한 데이터 타입의 요소만 저장 가능 | 다양한 데이터 타입의 객체 저장 가능 |
| 메모리 구조 | 연속된 메모리 공간에 저장 | 비연속적인 메모리 공간에 저장 가능 |
| 기능성 | 제한적 (추가/삭제/정렬 등의 기능 없음) | 추가, 삭제, 검색, 정렬 등 고급 기능 제공 |
| 성능 | 빠름 (특히 인덱스 기반 접근) | 성능은 구현체에 따라 다름 (HashMap 등은 빠름) |
| 사용 목적 | 고정된 크기의 단순 데이터 저장 | 동적으로 크기가 변하는 데이터 저장 및 관리 |
| 사용 예 | 정수 배열, 문자 배열 등 | 리스트, 셋, 맵 등 |
| 사용 상황 | 배열 (Array) | 컬렉션 (Collection) |
|---|---|---|
| 데이터 크기가 고정 | 배열이 적합 | 불필요하게 메모리를 낭비할 수 있음 |
| 데이터 크기가 유동적 | 부적합 | 크기가 동적으로 조정되는 컬렉션이 적합 |
| 단순 데이터 저장 및 접근 | 배열이 적합 | 컬렉션의 오버헤드가 불필요 |
| 데이터 추가, 삭제, 정렬, 검색 등의 작업 필요 | 구현하기 어려움 | 컬렉션이 적합 (이미 기능이 구현되어 있음) |
| 성능이 매우 중요한 경우 (고정 크기) | 배열이 적합 (연속된 메모리, 인덱스 접근 빠름) | 컬렉션은 약간의 성능 오버헤드가 발생 가능 |
Q. 정적 배열과 동적 배열의 차이점은 무엇인가요?
정적 배열(Static Array)
- 컴파일 시점에 크기가 고정되는 배열로 메모리가 Stack 또는 데이터 영역에 할당됨
- 특징
- 고정된 크기 : 배열의 크기가 선언 시점에 정해지며, 실행중 변경 불가능
- 빠른 접근 속도 : 메모리가 연속적으로 할당되기 때문에 인덱스 기반 접근 속도가 빠름
- 스택 메모리 사용 : 지역 변수로 선언된 정적 배열은 스택 메모리를 사용하기에 관리가 간단하지만 크기가 큰 배열은 메모리 부족 문제를 야기할 수 있음
- 크기가 고정되어 있어 데이터 크기가 가변적인 경우 유연성이 떨어짐
정적 배열(Dynamic Array)
- 런타임 시점에 크기가 결정되며, 필요에 따라 크기 조정 가능. 메모리가 Heap 영역에 할당됨
- 특징
- 크기 조정 가능 : 실행중 배열의 크기를 조정할 수 있어 유연성이 높음
- 힙 메모리 사용 : 메모리가 힙에 동적으로 할당되므로, 더 큰 크기의 배열 처리 가능
- 메모리 관리 필요 : 동적으로 할당된 메모리는 명시적으로 해제하는 등의 관리를 하지 않으면 메모리 누수 발생 가능
- 추가 오버헤드 : 크기를 변경하는 경우 기존 데이터 복사 및 새로운 메모리 할당으로 인해 오버헤드 발생 가능
| 특징 | 정적 배열 (Static Array) | 동적 배열 (Dynamic Array) |
|---|---|---|
| 크기 결정 시점 | 컴파일 시점 | 런타임 시점 |
| 메모리 할당 위치 | 스택(Stack) 또는 데이터 영역 | 힙(Heap) |
| 크기 조정 | 불가능 | 가능 |
| 성능 | 빠름 (메모리가 연속적으로 할당됨) | 약간 느림 (동적 메모리 할당 및 복사 필요) |
| 메모리 관리 | 자동 (스택 메모리는 함수 종료 시 해제됨) | 명시적으로 해제해야 함 (delete 또는 free) |
| 유연성 | 낮음 | 높음 |
Q. ArrayList 와 LinkedList 의 성능 차이는 어떻게 되나요?
ArrayList
- 배열 기반의 List 구현체로 내부적으로 동적 배열을 사용해서 데이터를 저장
- 초기 용량 초과시 새로운 배열을 생성하고 기존 데이터를 복사해서 저장
- 인덱스를 사용해서 요소에 접근하기 때문에 요소 접근 속도 빠름.
- 요소 추가, 삭제 시 배열 크기가 조정되므로 빈번한 요소 추가와 삭제 발생은 성능이 저하될 수 있음
- 사용 사례
- 인덱스를 통한 접근이 가능할 때
- 삽입/삭제 동작이 적고 읽기 위주의 작업이 많을 때
- 메모리 효율이 중요할 경우 : 배열 기반이므로 메모리 오버헤드가 적기 때문
LinkedList
- 연결 리스트 기반의 List 구현체로 각 요소가 이전 요소와 다음 요소의 참조를 가지고 있음
- 요소 추가, 삭제시 참조만 변경하면 되기에 해당 동작시 성능이 우수함
- 사용 사례
- 삽입/삭제가 빈번할 때
- 데이터 크기가 동적으로 변할 때
- 메모리 효율이 크게 중요하지 않을 때
ArrayList 와 LinkedList 의 차이
| 특징 | ArrayList | LinkedList |
|---|---|---|
| 내부 구현 방식 | 동적 배열 | 이중 연결 리스트 |
| 데이터 저장 방식 | 연속된 메모리 블록 | 분리된 노드(각 노드는 데이터와 참조를 포함) |
| 인덱스 접근 속도 | 빠름 (O(1), 배열 인덱스 접근) | 느림 (O(n), 순차적으로 노드 탐색 필요) |
| 삽입/삭제 (중간 위치) | 느림 (O(n), 요소 이동 필요) | 빠름 (O(1), 노드 참조만 변경) |
| 삽입/삭제 (끝 위치) | 빠름 (O(1), 크기 초과 시 O(n)) | 빠름 (O(1)) |
| 메모리 사용량 | 적음 (배열 기반, 추가 메모리 오버헤드 적음) | 많음 (노드별 추가 참조 필드 및 메모리 할당) |
두 List의 성능 차이
| 연산 | ArrayList | LinkedList |
|---|---|---|
| 인덱스 접근 | 빠름 (O(1)) | 느림 (O(n)) |
| 삽입 (끝) | 빠름 (O(1), 동적 확장 시 O(n)) | 빠름 (O(1)) |
| 삽입 (중간) | 느림 (O(n)) | 느림 (O(n), 탐색 포함) |
| 삭제 (끝) | 빠름 (O(1)) | 빠름 (O(1)) |
| 삭제 (중간) | 느림 (O(n)) | 느림 (O(n), 탐색 포함) |
| 메모리 효율성 | 높음 | 낮음 |
Q. 제네릭스를 사용하는 이유는 무엇인가요?
제네릭스(Generics)
- Java 에서 타입을 일반화하는 방법으로 클래스, 메서드, 인터페이스에서 사용할 타입을 런타임이 아니라 컴파일 시점에 지정할 수 있도록 지원함.
- 데이터 타입을 파라미터화 하는 방식
- 제네릭스를 사용하면 특정 타입에 종속되지 않고, 다양한 타입을 지원하는 클래스나 메서드를 정의할 수 있음
ArrayList<String> list = new ArrayList<>();<> 가 제네릭스
| 타입 | 설명 |
|---|---|
<T> | 타입(Type) |
<E> | 요소(Element), ex) List<E> |
<K> | 키(Key), ex) Map<K, V> |
<V> | 리턴 값 또는 매핑된 값(Value), ex) Map<K, V> |
<N> | 숫자(Number) |
<S, U, V> | 2번째, 3번째, 4번째에 선언된 타입 |
- 제네릭스 사용이유
- 타입 안정성 제공
-컴파일 시점에 타입을 확인하여 타입 오류를 방지할 수 있고, 잘못된 타입 사용으로 인한 런타임 에러를 줄일 수 있음 - 타입 캐스팅 제거
- 제네릭스를 사용하면 명시적 타입 캐스팅이 필요 없어 코드 가독성과 유지보수성을 높일 수 있음
//제네릭스 없을 때 ArrayList list = new ArrayList(); // Raw 타입 list.add("Hello"); String str = (String) list.get(0); // 명시적 캐스팅 필요//제네릭스 사용할 때 ArrayList<String> list = new ArrayList<>(); list.add("Hello"); String str = list.get(0); // 캐스팅 필요 없음 - 코드 재사용성 증가, 가독성 향상
- 하나의 클래스나 메서드로 다양한 데이터 타입 처리 가능
고급 단계 질문(최적화와 성능)
Q. 박싱(Boxing) 과 언박싱(Unboxing) 이 성능에 미치는 영향은 무엇인가요?
래퍼 클래스(Wrapper Class)
- 기본 데이터 타입을 객체로 다룰수 있도록 제공되는 클래스
| 기본 타입 | 래퍼 클래스 |
|---|---|
byte | Byte |
short | Short |
int | Integer |
long | Long |
float | Float |
double | Double |
char | Character |
boolean | Boolean |
**가비지 컬렉션(Garbage Collection)
- 더 이상 사용되지 않는 객체(메모리)를 자동으로 식별하여 회수하고, 메모리 누수를 방지해 프로그램의 효율성을 유지하는 메모리 관리 방식
- 특징
- 자동 메모리 관리 : GC 가 더 이상 참조되지 않는 객체를 자동으로 회수해 메모리를 정리함
- 힙 메모리 관리 : GC 가 주로 Heap 메모리를 관리하며 동적으로 생성된 객체를 추적함
- 객체의 생명주기 관리 : 객체가 사용중인지, 더 이상 접근 불가한지 여부를 확인함
- 백그라운드에서 동작 : GC 는 JVM 이 자동으로 관리하며 프로그램 실행중에 백그라운드에서 작동함
박싱(Boxing)
- 기본 타입(Primitive Type) 데이터를 래퍼 클래스(Wrapper Class) 로 변환하는 과정
ex) int -> integer, double -> Double
int a = 10;
Integer boxed = Integer.valueOf(a); // 박싱
언박싱(Unboxing)
- 래퍼 클래스 데이터를 기본 타입으로 변환하는 과정
ex) integer -> int, Double -> double
Integer boxed = 20;
int unboxed = boxed.intValue(); // 언박싱
오토박싱, 오토언박싱
int a = 10;
Integer boxed = a; // 오토박싱
int unboxed = boxed; // 오토언박싱박싱과 언박싱이 성능에 미치는 영향
- 박싱과 언박싱의 성능 오버헤드
- 추가메모리 할당
- 박싱 시 새로운 래퍼 객체 생성되는데, 추가적인 메모리 사용과 힙 할당을 필요로 하기에 성능에 영향을 미침
- 객체관리
- 박싱된 객체는 Heap 에 저장되며 가비지 컬렉션(Garbage Collection) 의 부담이 증가할 수 있음
(특히 많은 박싱/언박싱 연산이 발생하면 GC 횟수가 늘어나 성능저하 초래가능) - 메서드 호출 비용
- 언박싱 과정에서 래퍼 클래스의 메서드가 호출되고, 이또한 성능에 영향을 미칠 수 있음
- 반복 연산에서의 영향
- 반복문에서의 많은 박싱, 언박싱이 일어나면 성능저하가 많이 발생할 수 있음 - 메모리 사용의 영향
- 기본 타입은 스택 메모리에 저장되어 메모리 사용량이 적지만,
박싱된 래퍼 클래스는 Heap 메모리에 저장되어 추가적인 오버헤드가 발생함
박싱/언박싱 사용시 주의할점
1. 성능에 민감한 작업에는 남용 금지 : 계산량이 많은 작업의 경우 박싱/언박싱으로 인해 성능저하 발생 가능
2. 제네릭과 래퍼 클래스의 조합 : 제네릭 사용시 박싱/언박싱이 자동 발생하므로 성능에 영향을 미칠 수 있음을 인지해야함
Q. 불변 객체(Immutable Objects) 를 사용하는 이유와 장단점은 무엇인가요?
불변 객체(Immutable Objects)
- 생성된 이후 상태를 변경할 수 없는 객체를 의미
- 특징
- 상태 변경 불가
- 생성된 객체의 내부 상태가 변경되지 않음. 변경하려면 새로운 객체를 생성해야함
- 스레드 안전성
- 불변 객체는 변경되지 않기 때문에 멀티스레드 환경에서 동기화 없이 안전하게 사용 가능
- 참조 투명성
- 동일한 입력 값에 대해 항상 동일한 결과 반환
- 캐싱 가능
- 동일한 값의 불변 객체는 캐싱하여 재사용 가능
사용 이유
1. 안전성 : 멀티스레드 환경에서 동기화 없이도 안전하게 공유 가능
2. 변경 불가 : 객체 상태가 변경되지 않아 예상하지 못한 부작용을 방지
3. 캐싱 가능 : 동일한 값을 가진 객체를 재사용할 수 있어 메모리와 성능 최적화
4. 디버깅 용이 : 객체의 상태가 변하지 않으므로 추적과 디버깅이 쉬움
| 장점 | 단점 |
|---|---|
| 안전성 | 변경되지 않으므로 스레드 간 안전하게 공유 가능. |
| 예측 가능성 | 상태 변경이 불가능하므로 코드의 동작이 예측 가능. |
| 변경 추적 | 상태가 변경되지 않아 디버깅과 문제 원인 추적이 쉬움. |
| 성능 최적화 | 캐싱 및 공유를 통해 동일한 객체를 재사용 가능. |
Q. 메모리 누수를 방지하기 위한 자료형 사용 전략은 어떻게 되나요?
- 불필요한 참조 제거
- 객체를 더 이상 사용하지 않을 때, 해당 객체에 대한 참조를 명시적으로 제거함
- 약한 참조 사용
- 약한 참조를 사용해 가비지 컬렉션이 객체를 회수할 수 있도록 함. WeakReference 와 SoftReference 클래스를 사용하면 약한 참조 구현 가능
- 불변 객체 사용
- 불변 객체는 상태가 변경되지 않으므로 참조로 인해 메모리가 유지되는 문제가 줄어듬
- 정적 필드와 싱글톤 관리
- 정적 필드나 싱글톤 객체 관리시 사용하지 않는 데이터를 명시적으로 제거하거나 필요에 따라 동적으로 재할당함. 이때 정적 참조가 지속되면 객체가 GC 대상에서 제외되므로 주의해야함
- 이벤트 리스너와 콜백 관리
- 이벤트 리스너와 콜백 객체 등록시 약한 참조를 사용하거나 명시적으로 해제하여 메모리 누수를 방지함
