결과 table에 임의의 기준으로 row번호를 부여할 때 사용하는 방법 3가지
-
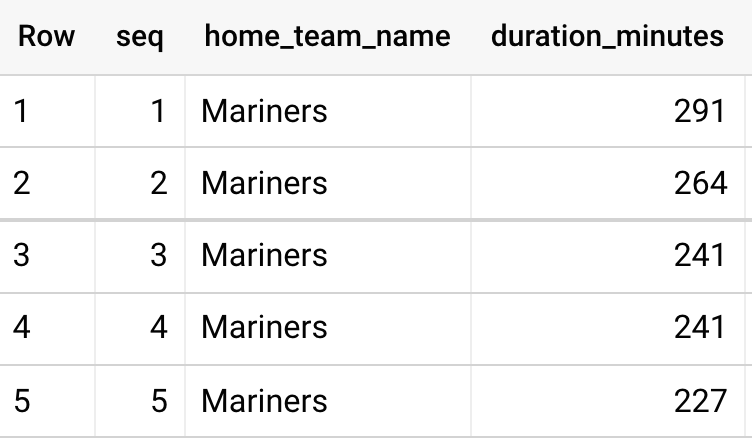
row_number
- 중복된 값( 동점 )이라도 순서대로 번호를 부여한다.
-
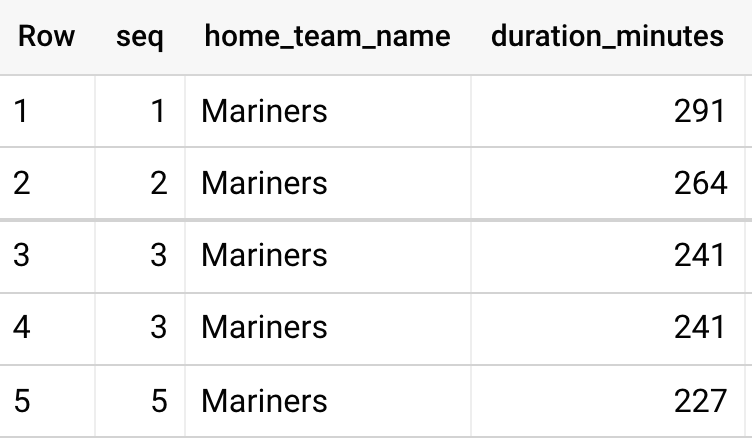
rank
- 중복된 값( 동점 )이 있다면 해당 개수만큼 건너 뛰고 다음 번호를 부여한다.
- e.g., 2명의 공동 1등 후 다음 순위는 3등으로 순위를 부여.
-
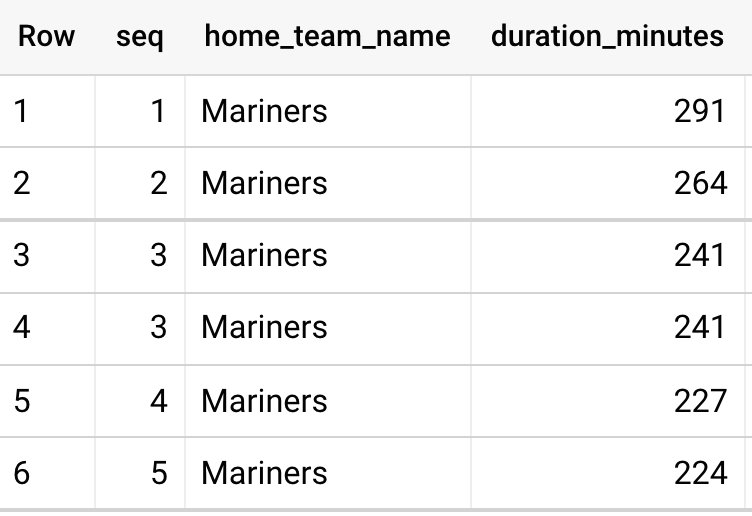
dense_rank
- 중복된 값( 동점 ) 이 있어도 해당 개수만큼 건너 뛰지 않고 다음 번호를 연속으로 부여한다.
- e.g., 2명의 공동 1등 후 다음 순위는 2등으로 순위를 부여.
예시
미국 야구 경기 중, Mariners 팀의 경기 시간( minute )으로 줄세워 본 결과
- row_number
with
t1 as (
select
row_number() over( partition by homeTeamName order by duration_minutes desc ) seq,
homeTeamName home_team_name,
duration_minutes,
from
`bigquery-public-data.baseball.schedules` a
where 1=1
)
select
*
from
t1
where 1=1
and seq <= 5
and home_team_name = 'Mariners'결과
- rank
with
t1 as (
select
rank() over( partition by homeTeamName order by duration_minutes desc ) seq,
homeTeamName home_team_name,
duration_minutes,
from
`bigquery-public-data.baseball.schedules` a
where 1=1
)
select
*
from
t1
where 1=1
and seq <= 5
and home_team_name = 'Mariners'결과
- dense_rank
with
t1 as (
select
dense_rank() over( partition by homeTeamName order by duration_minutes desc ) seq,
homeTeamName home_team_name,
duration_minutes,
from
`bigquery-public-data.baseball.schedules` a
where 1=1
)
select
*
from
t1
where 1=1
and seq <= 5
and home_team_name = 'Mariners'결과

분석가