오늘의 주제는
- 회사에서 사용했던 STACK 찍먹 2탄 (1탄은 회사다닐때 했었다..)
- ELK
- Kafka
- Redis
- AWS (Lambda, S3, CloudFront, Route53)
스택에 관한 스터디는 우리끼리 알아보고 공유하는거라 정확하지 않을 수 있고, 너무 겉핥기이겠지만 정말 어떻게 사용했었는지, 왜썼는지정도는 알아야 할 것 같아서 시작되었다.
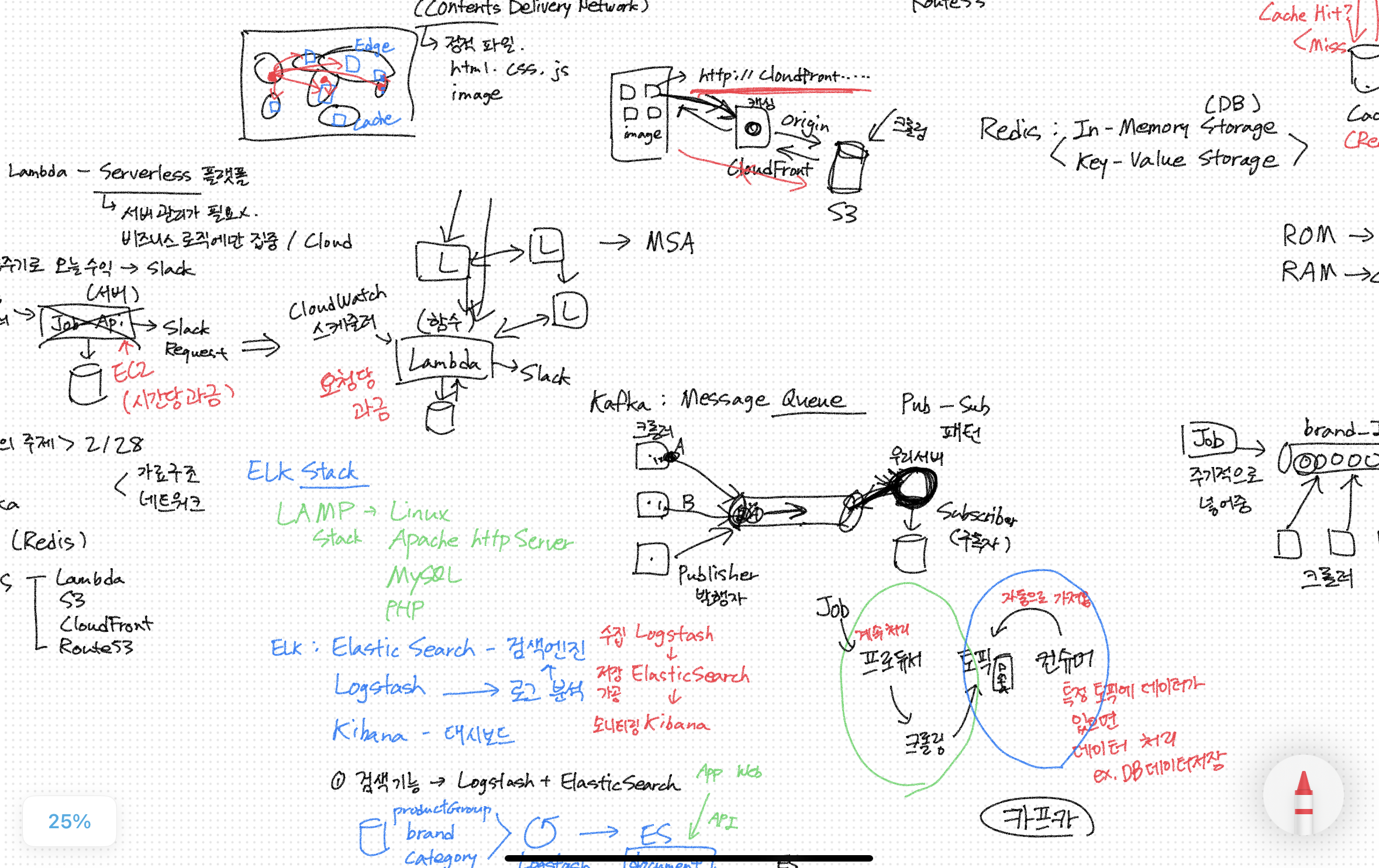
ELK
Elastic Search, Logstash, Kiana
- Elastic Search : 데이터 저장, 가공
- Logstash : 데이터 수집
- Kibana : 모니터링
굳이 순서로 이해해보면
- Logstash로 필요한 데이터를 수집해주고
- Elastic Search에 ( Documents라는곳에 저장됨 ) 저장하여 가공한다.
- 로그를 붙였다면 kibana에서 로그를 확인할 수 있다.
실제로 어디에 사용하였는가 ?
-
검색기능 : EL
왜 DB에서 하지않고 ES에서 하는가?
=> 자연어처리(동의어 / 유의어, 오타 보정), 유사도 등을 제공해준다. -
로그 모니터링 : ELK
logback(로깅프로그램)을 이용하여 Logstash에 커스텀해준채로 넘겨주고, ES에 저장을 하여 kibana에서 로그를 확인한다.
Kafka
크롤링을 위해 사용
Producer - Topic - consumer
Topic은 여러개의 Partition을 가지고있음 : 분산처리를 위해
내가 이해하도록 적어보자면...
producer(크롤러)가 데이터를 가져오면 지정해둔 Topic-Partition에 차곡차곡 쌓아두고, consumer는 그 Topic-Partition을 구독하여 데이터를 사용한다.
Topic-Partition에 쌓이고 해당 Topic-Partition을 중간에 컨슈머가 구독을하여도 그동안의 Topic-Partition 히스토리들을 가져올 수도 있다.
Redis
캐시사용을 위해 !
- In-memory Storage(DB) : RAM
- key-value 형식으로
- Replication : 여러대의 서버를 두어서, 한쪽이 죽어도 다른곳에 캐시가 남아있으므로 안전함
실제로 어디에 사용하였는가 ?
- 유저에따라 바뀌지 않는 데이터(홈화면, 카테고리 등..)
AWS
Lambda
severless 플랫폼
- severless : 서버관리(환경셋팅같은)가 필요없어 비즈니스 로직에만 집중. (실제로는 서버가 있지만, 서버가 없는것처럼 느껴진다)
- 요청당 과금 (일반 서버는 시간당 과금)
CloudFront
CDN : Contents Delivery Network
- 본 서버에서 분산 네트워크를 두고, 근처에있는 분산 네트워크로 접속하여 사용하도록 하는 것
- 어느 분산네트워크를 사용할지는 캐시처리된다
- 대체도메인을 통해 접근
- 유튜브,넷플릭스 등 큰 기업에서도 많이 씀
- S3에 직접 접근하면 보안문제도 있어서 CloudFront에서 origin 설정을하여 접근할 수 있음
실제로 어디에 사용하였는가 ?
- 크롤러가 S3에 이미지 저장
- 이미지 호출
- CloudFront에 있으면 그걸 사용, 없으면 S3까지 갔다와야함
(처음 호출하여 CloudFront에 쌓이고나면 S3까지 갔다올 필요 없어서 빠름)
버킷 : 폴더인데 다양한 기능이 있는 폴더 ..Route53
- IP주소 : 네트워크 주소 (www.naver.com 처럼 사람이 알아보기 쉬운게 도메인)
- MAC주소 : 기기별로 부여되는 주소
- 포트 : App 별 주소
*.domain_name : *(서브도메인)은 커스터마이징이 가능하고, 서브도메인에따라 보내주는 경로를 지정해줄 수 있다.
공부하며 정리&기록하는 ._. 씅로그

Front-end