Index
정의
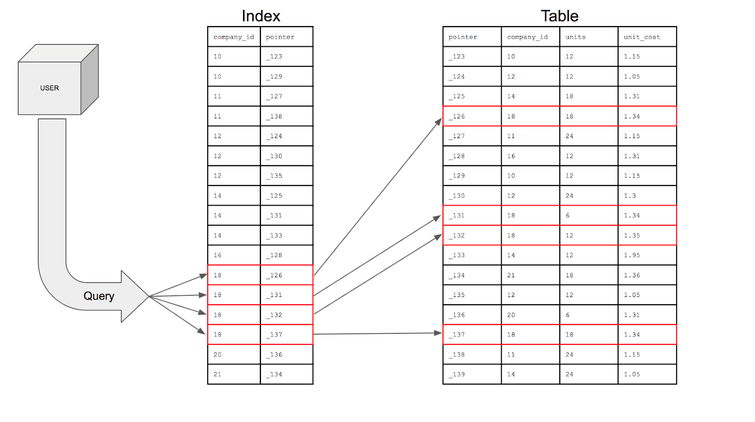
추가적인 쓰기 작업과 저장 공간을 활용하여 DB 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
우리는 보통 책에서 정보를 찾을 때, 맨 앞 또는 맨 뒤에 색인(목록)을 찾는다. 즉, 데이터를 기록할 경우 그 데이터의 이름, 데이터 크기 등의 속성과 그 기록 장소 등을 표로 표시하는 것이 인덱스이다.
DB 성능과 관련된 사항 ex) 프로세서, LOCK, Network I/O, 데이터 I/O 에서 Index는 데이터 I/O에 속한다.
인덱스는 DB 내 저장된 데이터의 주소를 가지고 있는 것이다.
장점
위에서 설명했 듯 인덱스를 이용해 '원하는 데이터를 빠르게 찾을 수 있는 것' 이다. 즉, DB 안의 특정 데이터의 조회를 빠르게 하고 전반적인 시스템의 부하를 줄일 수 있다.
단점
타 성능 악영향
인덱스는 앞서 설명에 데이터의 속성과 그 기록장소 등을 표로 표시하는 것이라고 했다. 이러한 점에서 SELECT를 제외한 모든 동작 INSERT / UPDATE / DELETE 성능에 영향을 미친다.
왜냐하면 각각의 동작은 삽입, 수정, 삭제로 인덱스를 걸어둔 칼럼의 데이터를 변경시키기 때문이다. 칼럼의 데이터가 변경되면 인덱스 테이블의 수정도 필요하다. 즉, 데이터의 삽입 / 수정 / 삭제가 두 번 일어나게 된다.
추가 저장 공간 필요
DB에 저장된 데이터의 주소를 인덱스의 Key 값으로 가지려면 별도의 공간에 저장하므로 추가 저장 공간이 필요하다. 때문에 인덱스를 사용하는 시스템을 설계할 때, 인덱스 영역을 전체 테이블 영역의 30~50% 까지 잡아 놓을 만큼 저장 공간이 많이 필요하다.
공수 필요
공수란, 일정한 작업에 필요한 인원수를 노동 시간이나 노동 일로 나타내는 수치이다. 인덱스를 생성하고 주기적으로 관리할 공수, 즉 인력과 시간이 필요하다.
필요성
RDBMS에서 인덱스는 불가피하다.
일반적인 OLTP(OnLine Transaction Processing, 온라인 트랜잭션 처리) 시스템에서 데이터 조회 업무가 90% 이상이기 때문이다.
때문에 인덱스를 사용할 조건을 몇 가지 꼽자면
- 규모가 작지 않은 테이블
- 삽입 / 수정 / 삭제가 자주 발생하지 않는 칼럼
- 혹은 Join / WHERE / ORDER BY 에 자주 사용되는 칼럼
- 혹은 데이터의 중복도가 낮은 컬럼 등
이런 경우에 사용하면 좋다.
ref

공부하는 백엔드 개발자