

Introduction to InfiniBand
안녕하세요! 인피니밴드 에센셜 과정에 오신 것을 환영합니다.
이 동영상에서는 인피니밴드가 무엇인지, 주요 구성 요소와 아키텍처에 대해 알아보고자 합니다.
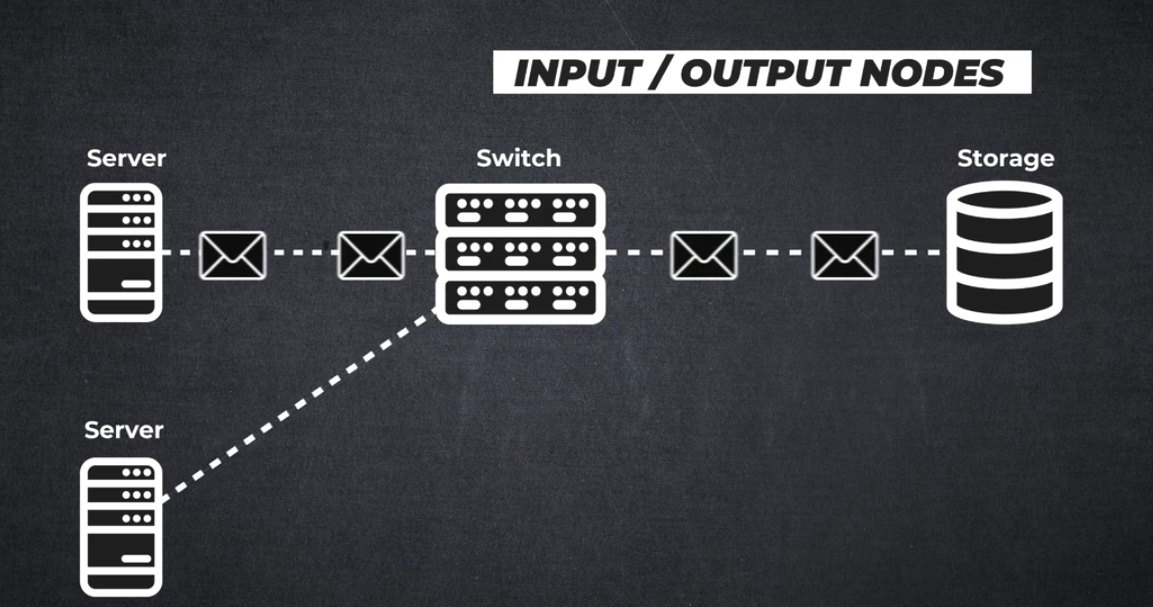
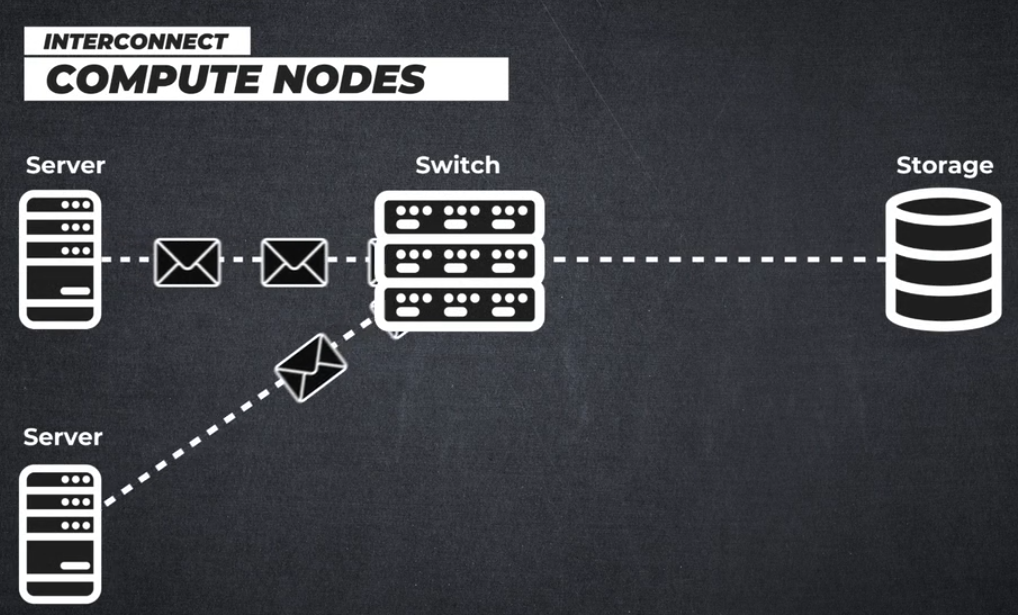
인피니밴드 아키텍처란 무엇인가요?
인피니밴드는 컴퓨팅 노드, 통신 인프라 장비, 스토리지 및 임베디드 시스템을 상호 연결하는 데 사용되는 입력/출력 아키텍처를 정의하는 업계 표준 사양입니다.
아키텍처는 호스트 운영 체제와 독립적이며 Linux, Windows 또는 ESXi가 될 수 있습니다. 아키텍처는 개방형 업계 표준 사양을 기반으로 합니다.
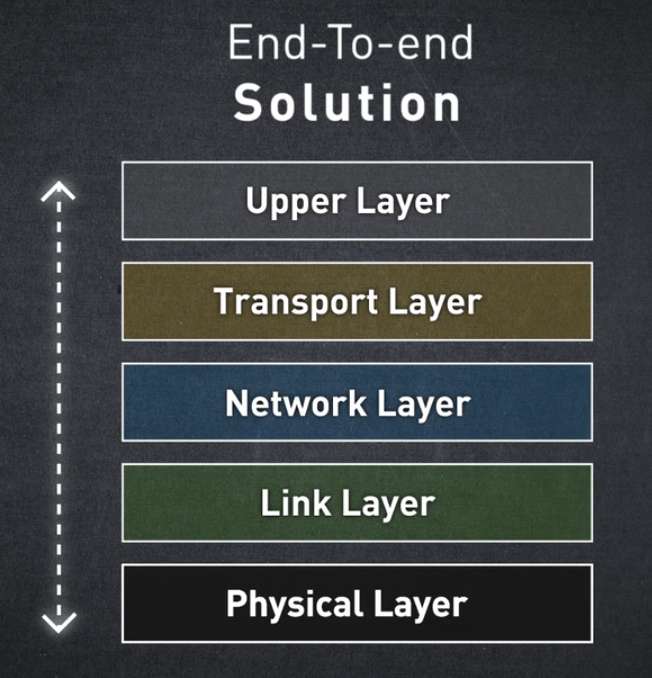
처음부터 InfiniBand는 물리적 계층부터 상위 계층까지 모든 프로토콜 계층을 개선하고 가속하는 엔드투엔드 솔루션을 제공하도록 설계되었습니다.
이 비전이 달성하고자 하는 목표는 다음과 같습니다:
- 최대 네트워크 사용률
- 최대 CPU 사용률
- 최대 애플리케이션 성능
인피니밴드 네트워크 구축에 관련된 주요 구성 요소에 대해 알아보겠습니다:
인피니밴드 스위치
트래픽 이동
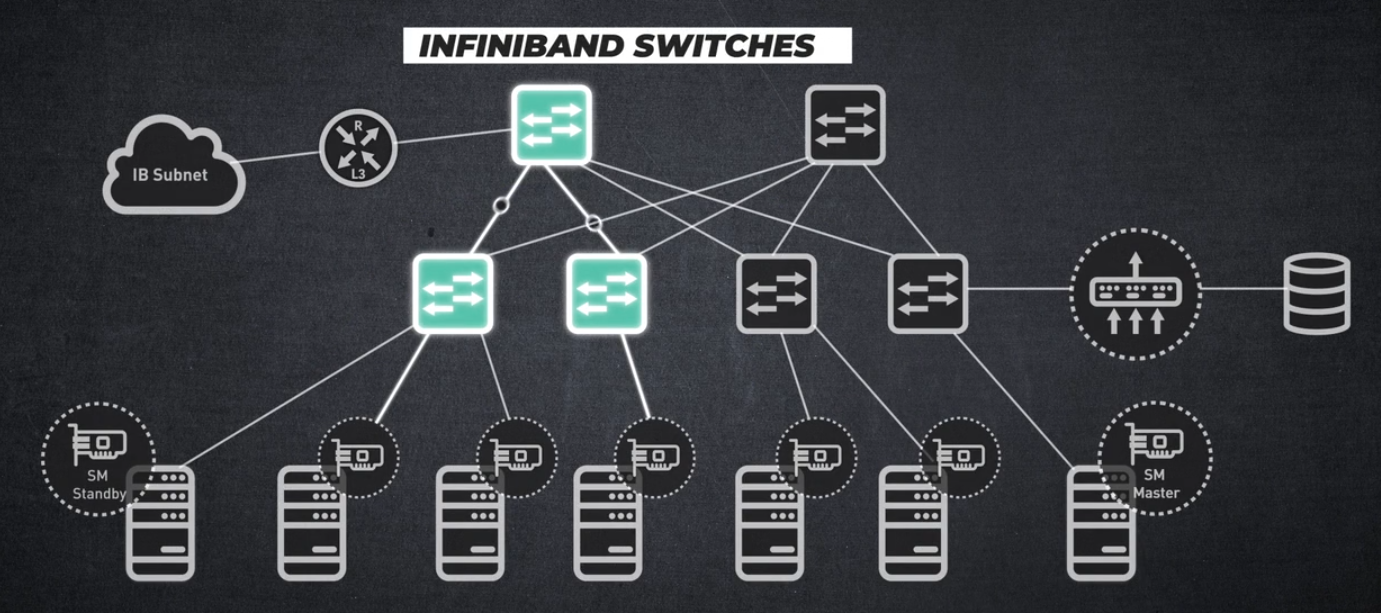
서브넷 매니저
모든 네트워크 활동 관리
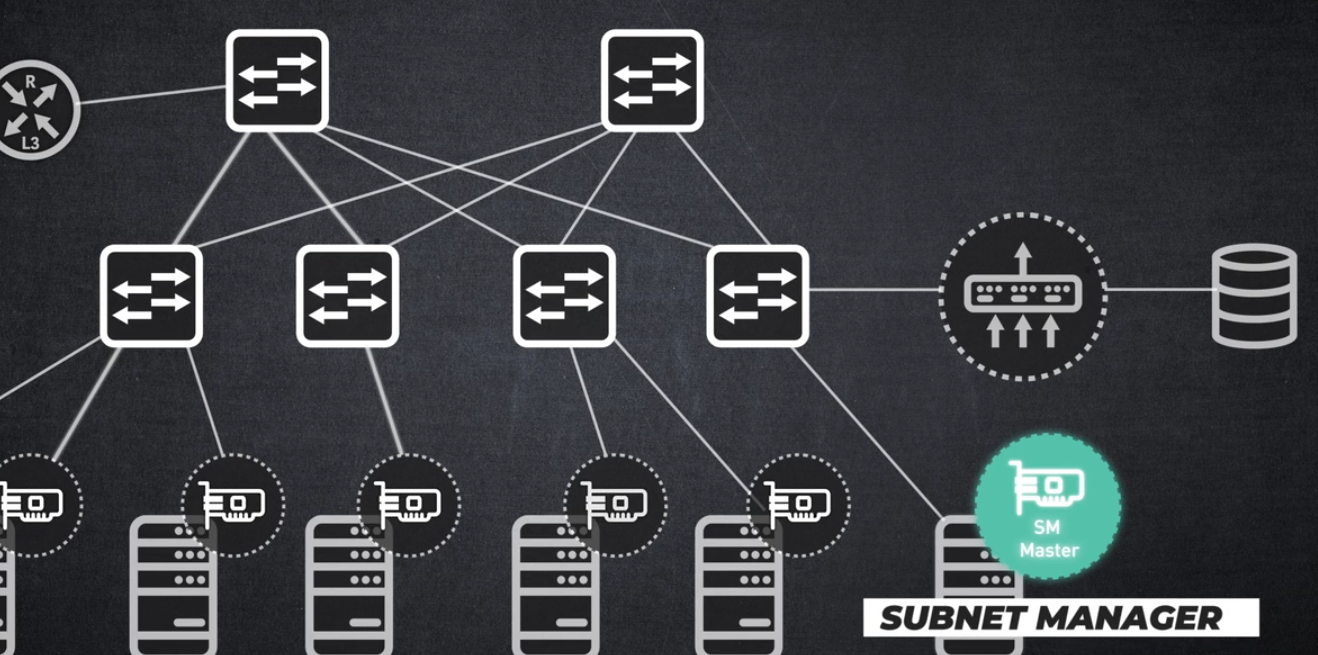
네트워크 호스트
패브릭이 구축되는 클라이언트
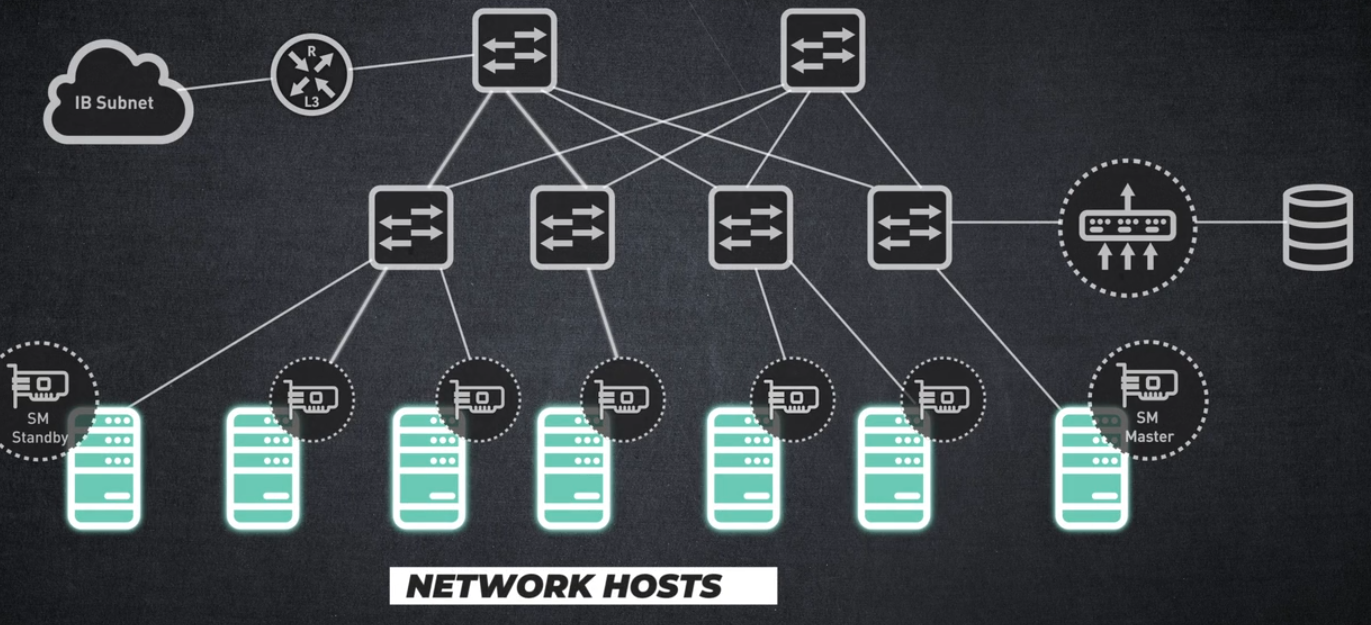
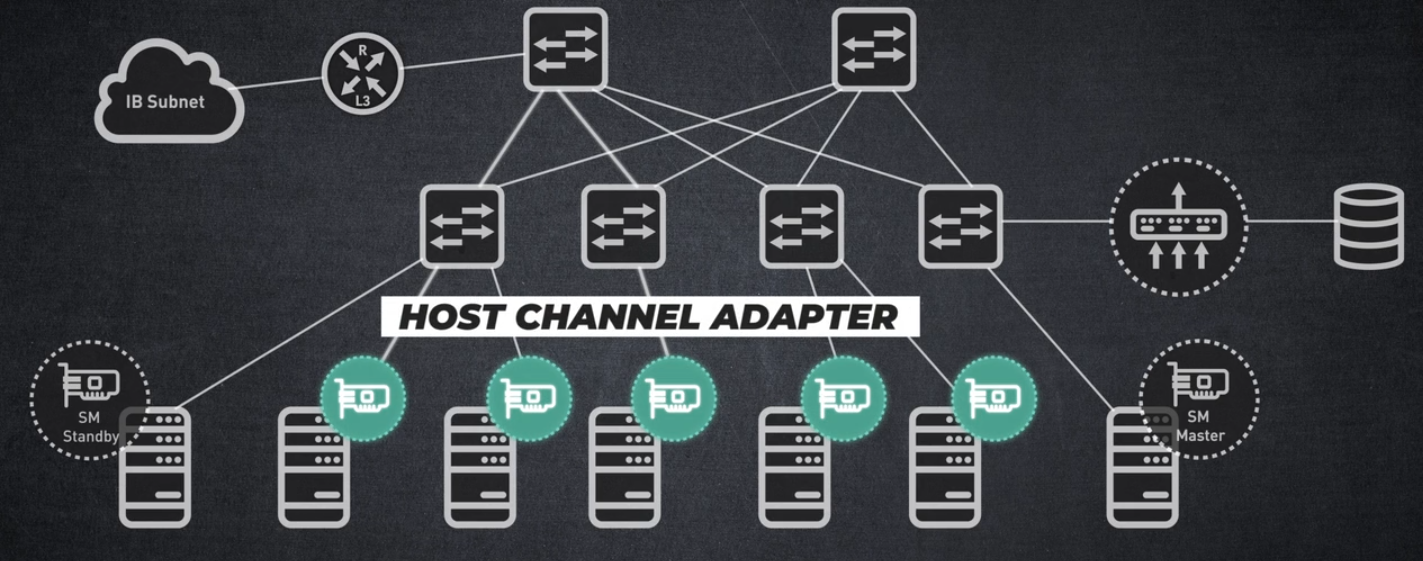
호스트 채널 어댑터
호스트와 스위치 간 InfiniBand 연결을 활성화합니다.
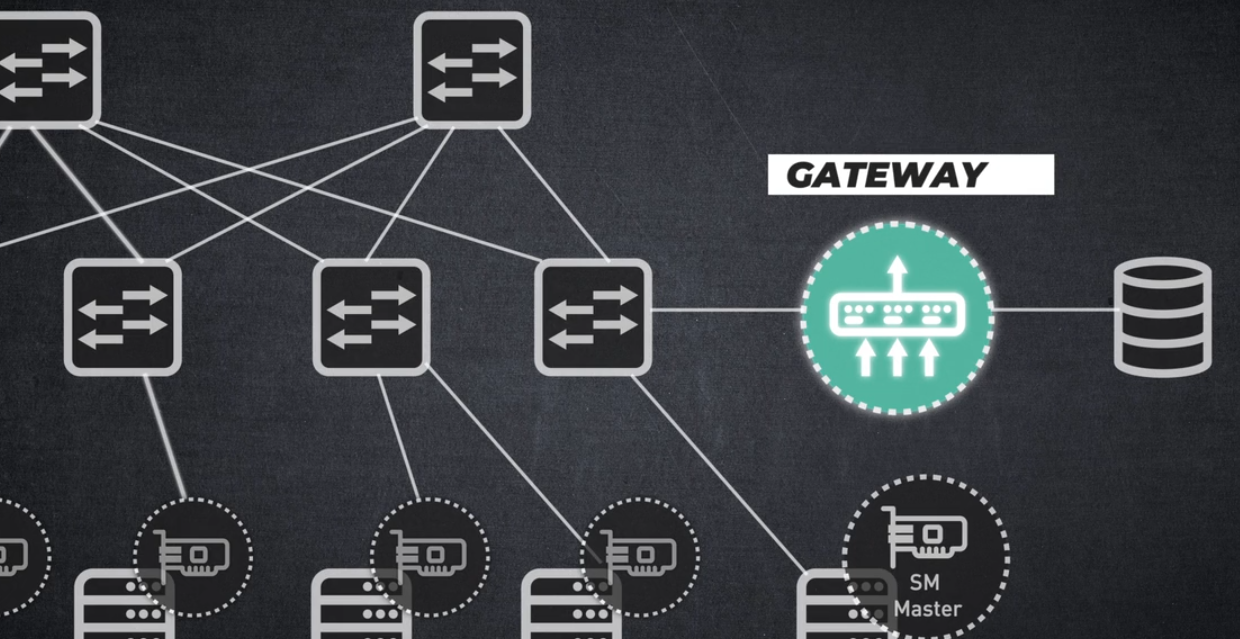
InfiniBand에서 이더넷으로 전환하는 게이트웨이
인피니밴드와 이더넷 기반 네트워크 간 IP 트래픽 교환을 허용합니다.
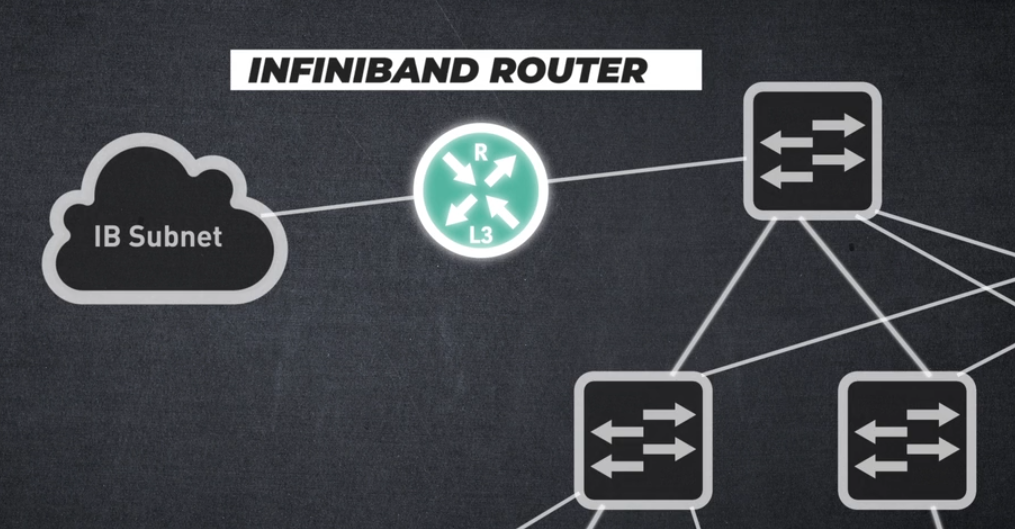
인피니밴드 라우터
여러 인피니밴드 서브넷 간의 상호 연결을 허용하여 어떤 고객이 인피니밴드 기술을 사용하고 있는지 확인할 수 있습니다:
활용 분야

데이터 센터, 클라우드 컴퓨팅, HPC-고성능 컴퓨팅, 머신 러닝 및 인공 지능. 이 세션에서는 인피니밴드가 무엇이며, 어떤 고객이 이 솔루션 또는 기술을 사용하고 있는지 설명합니다.
다음 세션에서는 인피니밴드의 주요 기능에 대해 알아보겠습니다.
InfiniBand Key Features
안녕하세요, InfiniBand 주요 기능 교육 세션에 오신 것을 환영합니다! 이 비디오에서는 인피니밴드의 주요 기능에 대해 알아보겠습니다.
엔비디아 멜라녹스 인피니밴드 인터커넥트는 초고속, 초저지연 확장 가능한 솔루션을 제공합니다.
인피니밴드 기술은 운영 비용과 인프라 복잡성을 줄이면서 슈퍼컴퓨터, 인공지능(AI) 및 클라우드 데이터센터를 규모에 관계없이 운영할 수 있도록 지원합니다.
이 비디오에서는 AI, 딥 러닝, 데이터 과학 및 기타 여러 가속 컴퓨팅 애플리케이션을 위한 인터커넥트 기술로 InfiniBand가 선택되는 주요 특징이 무엇인지 살펴봅니다.
InfiniBand 주요 특징 개요
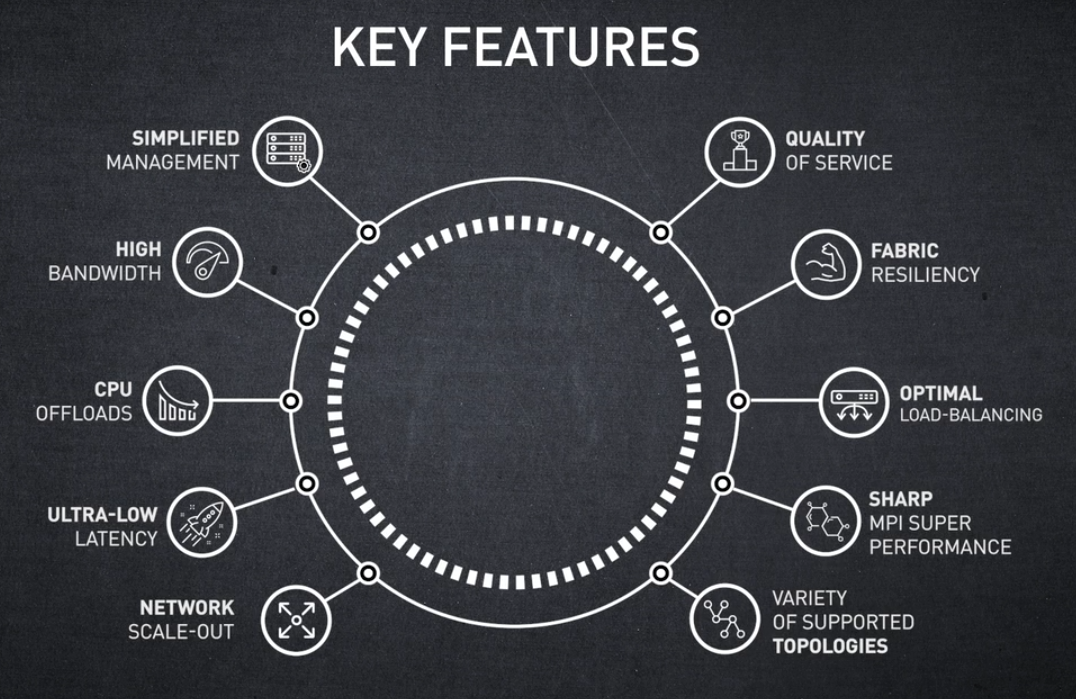
- SIMPLEFIED MANAGEMENT - 관리 간소화
- HIGH BANDWIDTH - 고대역폭
- CPU OFFLOADS - CPU 오프로드
- LOW LATENCY - 초저지연
- EASY SCALE-OUT - 간편한 네트워크 스케일아웃
- QUALITY OF SERVICE - 서비스 품질
- SELF-HEALING NETWORKING - 패브릭 복원력
- LOAD-BALANCING - 적응형 라우팅을 통한 최적의 부하 분산
- SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) - SHARP를 통한 MPI 최고 성능
- FAT-TREE - 다양한 토폴로지 지원
SIMPLEFIED MANAGEMENT
먼저, SIMPLEFIED MANAGEMENT 관리 간소화부터 살펴보겠습니다: InfiniBand는 SDN(Software Defined Network, 소프트웨어 정의 네트워크)의 비전을 진정으로 구현한 최초의 아키텍처입니다.
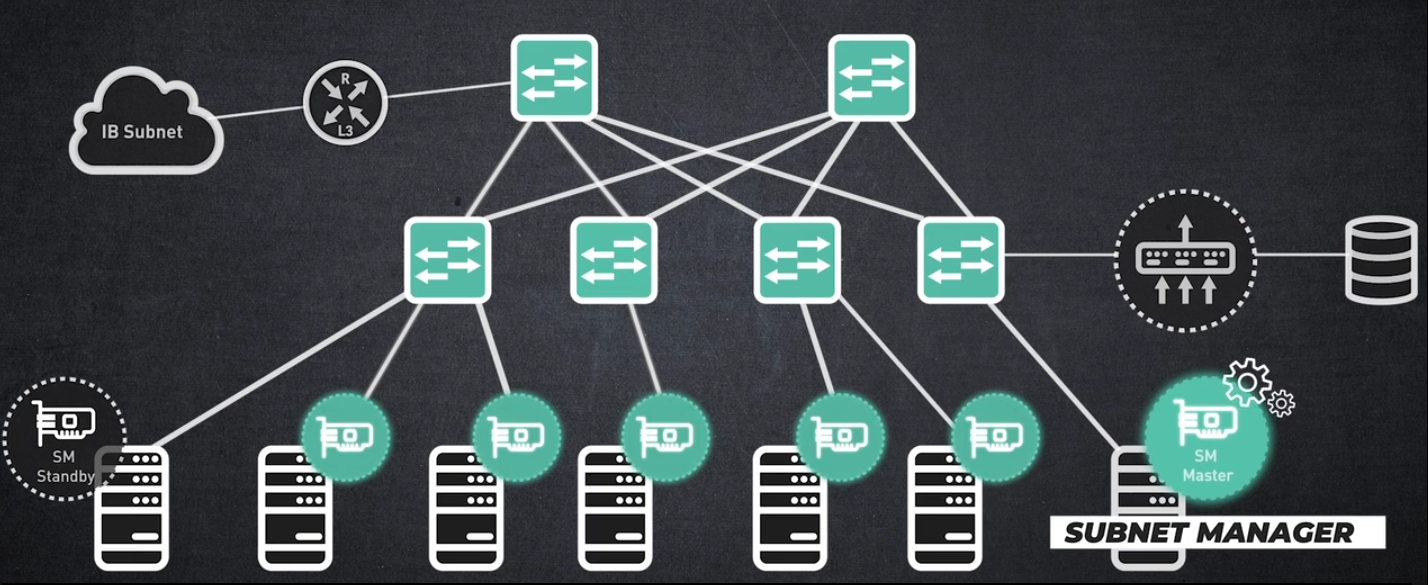
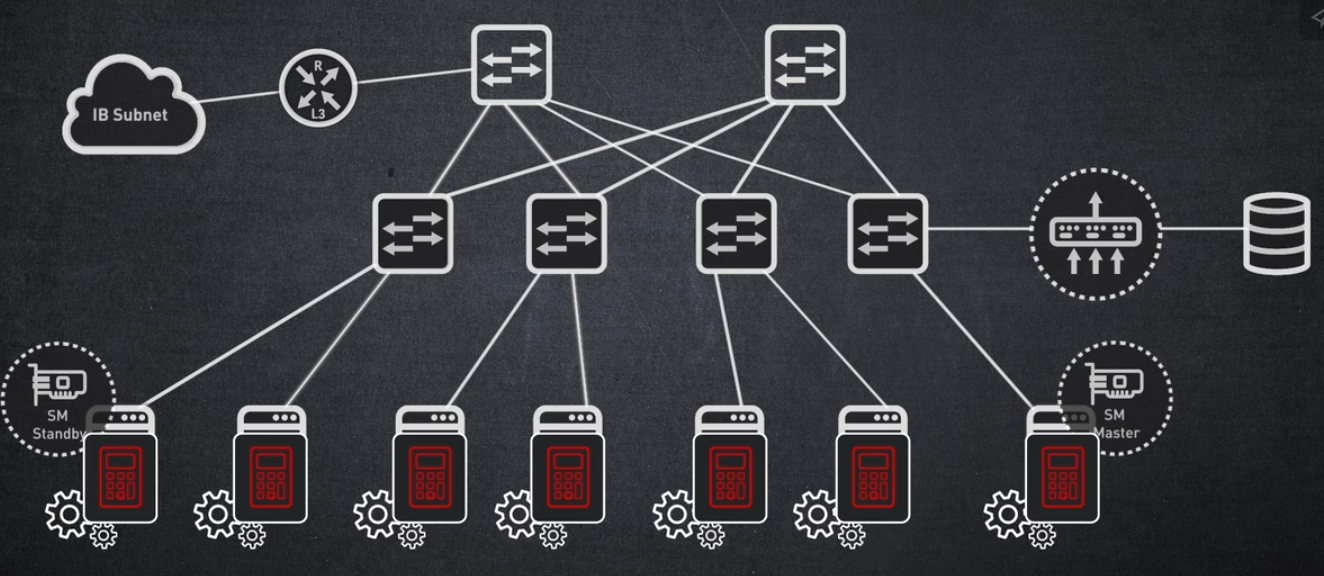
인피니밴드 네트워크는 서브넷 매니저에 의해 관리됩니다.
서브넷 매니저는 전체 네트워크를 실행하고 관리하는 프로그램입니다.
중앙 집중식 라우팅 관리를 제공하므로 네트워크의 모든 노드를 플러그 앤 플레이할 수 있습니다.
모든 InfiniBand 서브넷에는 자체 마스터 서브넷 관리자가 있습니다,
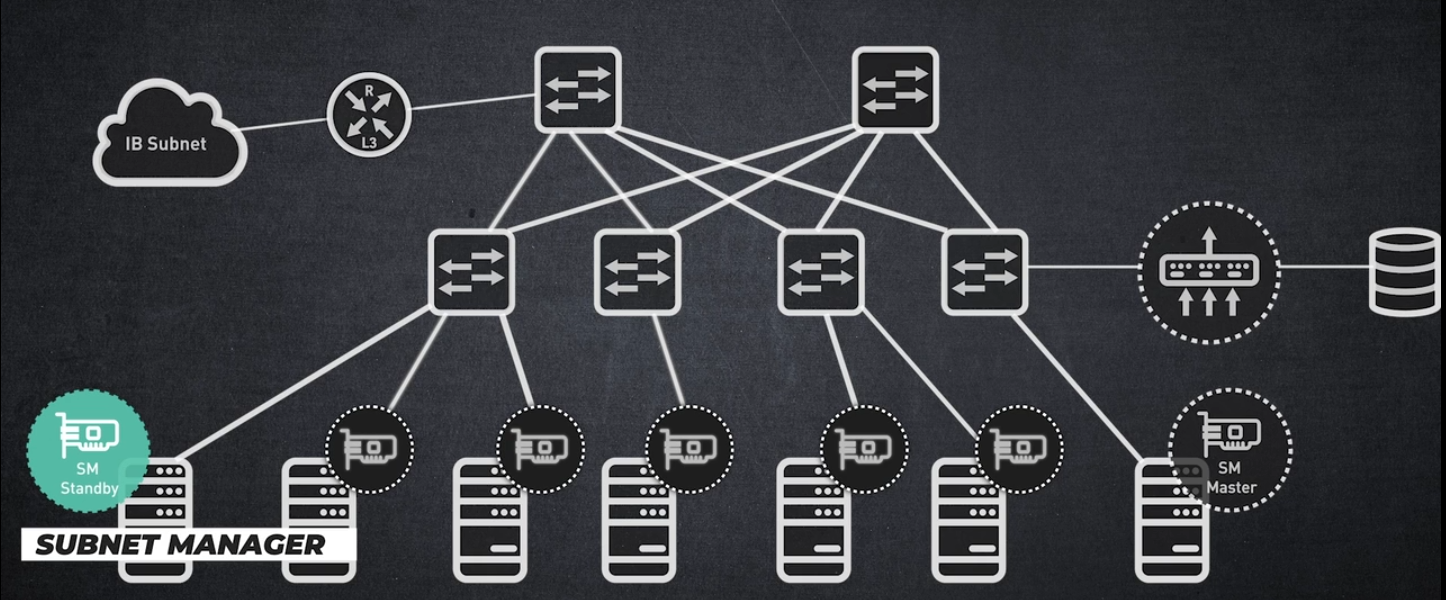
그리고 복원력을 보장하기 위해 두 번째 서브넷 관리자가 대기 상태로 작동합니다.
HIGH BANDWIDTH
다음으로 소개하는 InfiniBand의 주요 기능은 고대역폭입니다.
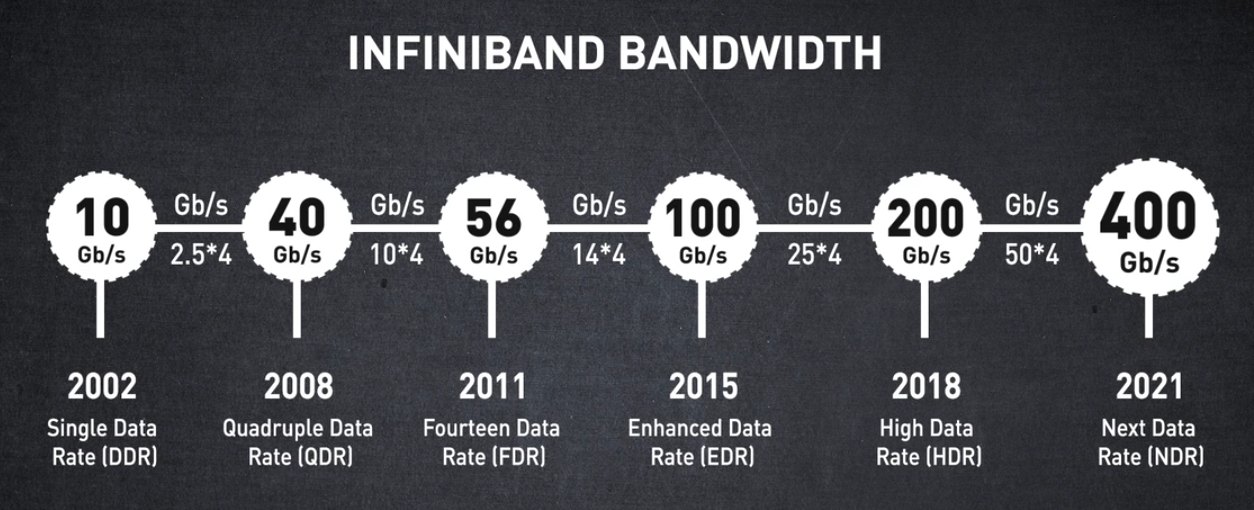
수년에 걸쳐 인피니밴드의 대역폭이 어떻게 발전해왔는지 살펴보세요.
2002년에 초당 10기가비트 속도로 InfiniBand 아키텍처가 시작되었습니다.
이후 최고 대역폭의 논블럭킹 양방향 링크를 제공하고 있습니다.
CPU OFFLOADS
다음 핵심 기능이자 가속 컴퓨팅 애플리케이션에서 가장 중요한 기능 중 하나는 CPU 오프로드입니다.
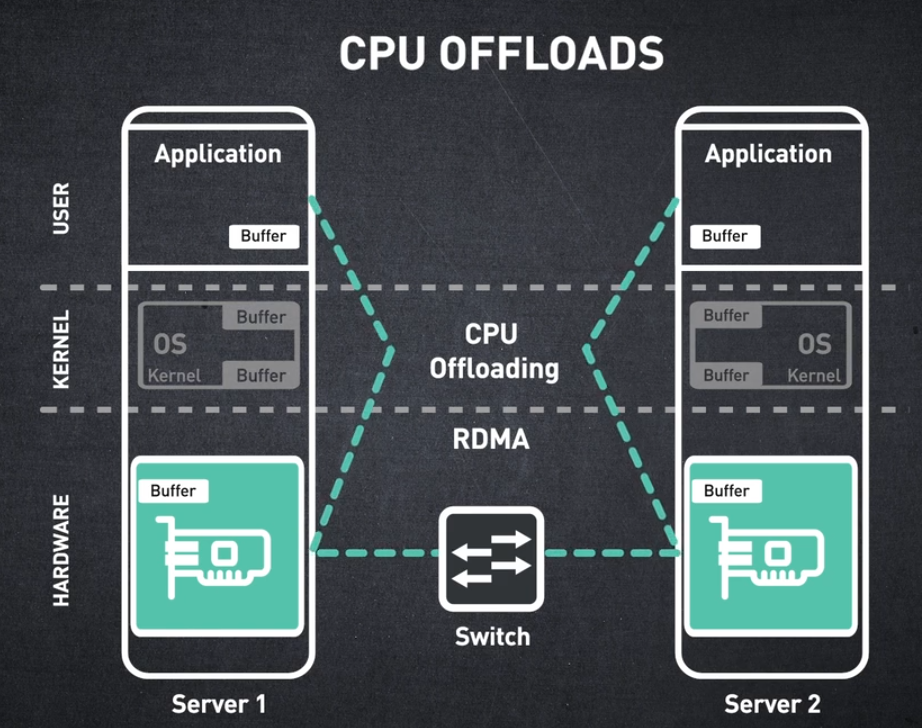
인피니밴드 아키텍처는 최소한의 CPU 개입으로 데이터 전송을 지원합니다. 이는 다음 덕분에 가능합니다:
- 하드웨어 기반 전송 프로토콜
- 커널 바이패스 또는 제로 카피
- 원격 직접 메모리 액세스
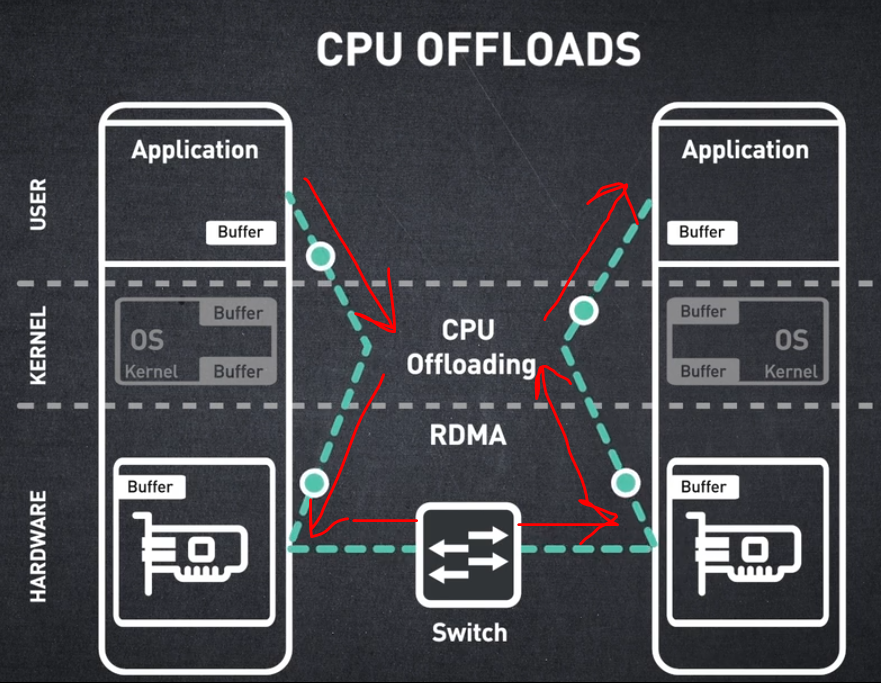
RDMA는 한 노드의 메모리에서 다른 노드의 메모리로 CPU의 개입 없이 직접 메모리에 액세스하는 방식입니다.
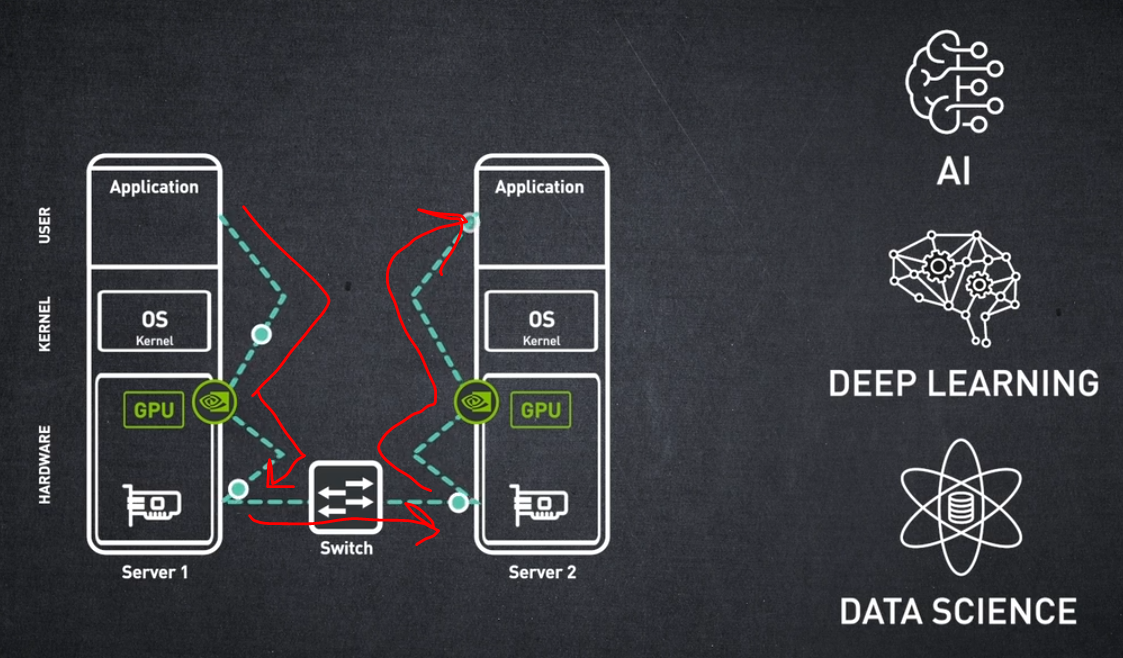
오프로딩 컴퓨팅 노드는 NVIDIA GPU에서도 구현할 수 있습니다. GPU-다이렉트는 한 GPU의 메모리에서 다른 GPU의 메모리로 직접 데이터를 전송할 수 있습니다.
다음과 같은 가속 컴퓨팅 애플리케이션을 지원합니다:
- AI, 딥 러닝 및 데이터 과학에서 GPU 기반 연산이 제공하는 지연 시간 단축 및 성능 향상
LOW LATENCY
이제 레이턴시로 넘어가서 다른 어떤 인터커넥트 기술과도 비교할 수 없는 InfiniBand 레이턴시에 대해 알아보겠습니다.
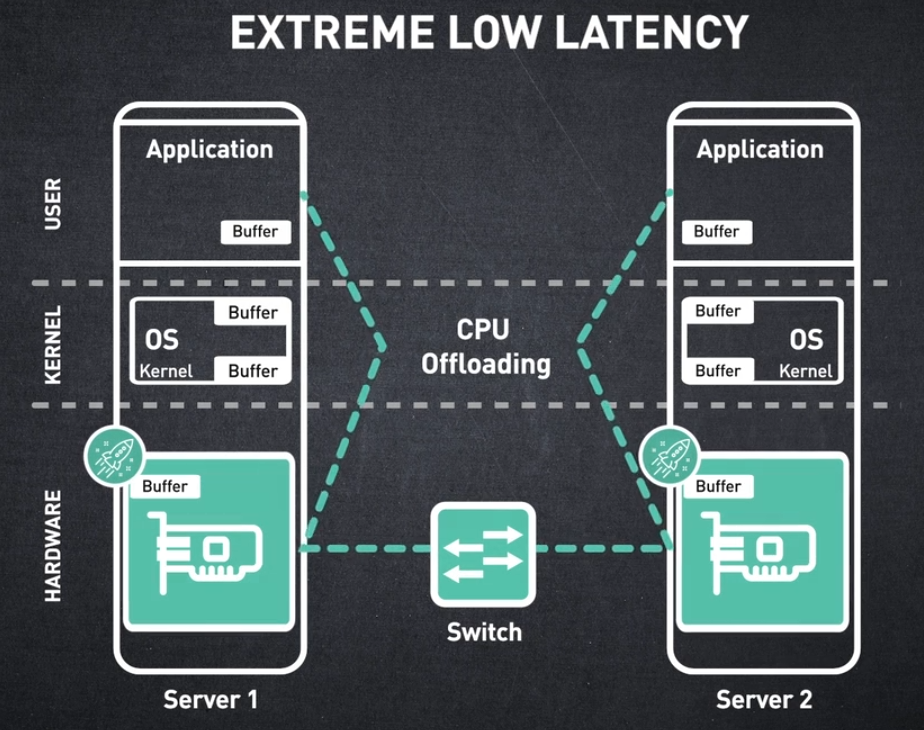
초저지연은 하드웨어 오프로딩과 가속 메커니즘의 조합으로 달성되며, 이는 InfiniBand 아키텍처의 고유한 특징입니다.
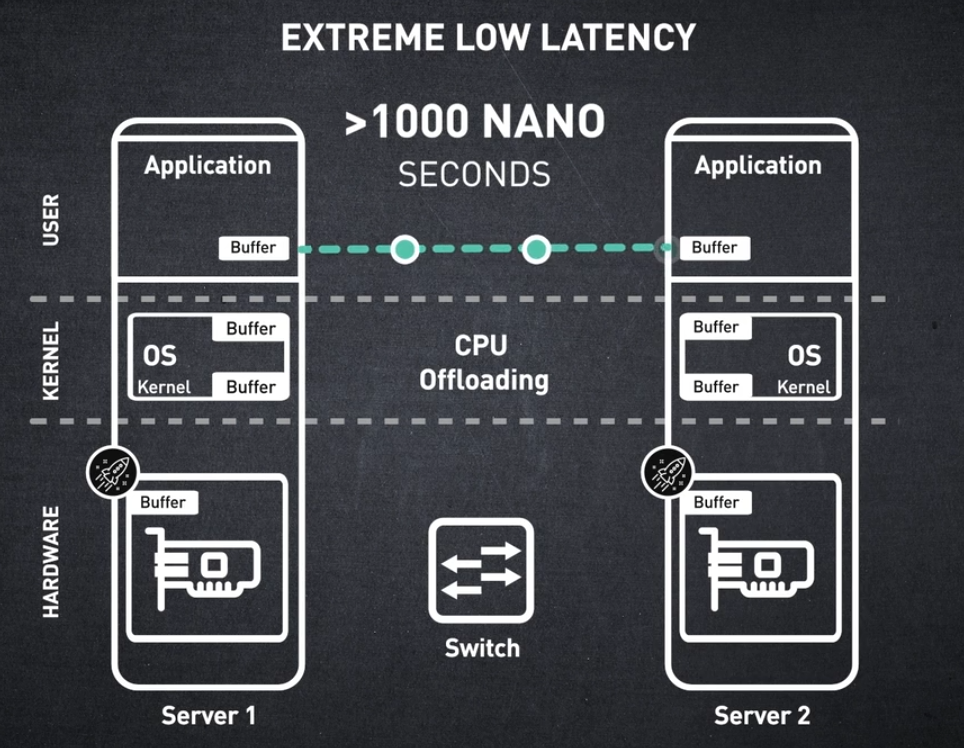
결과적으로 RDMA 세션의 종단 간 대기 시간은 1000나노초 또는 1마이크로초 정도로 낮을 수 있습니다.
EASY SCALE-OUT
네트워크 확장성은 어떻습니까? InfiniBand 서브넷은 어느 크기까지 확장할 수 있나요?
InfiniBand의 주요 장점 중 하나는 단일 서브넷에 최대 48,000개의 노드를 배포할 수 있다는 것입니다.
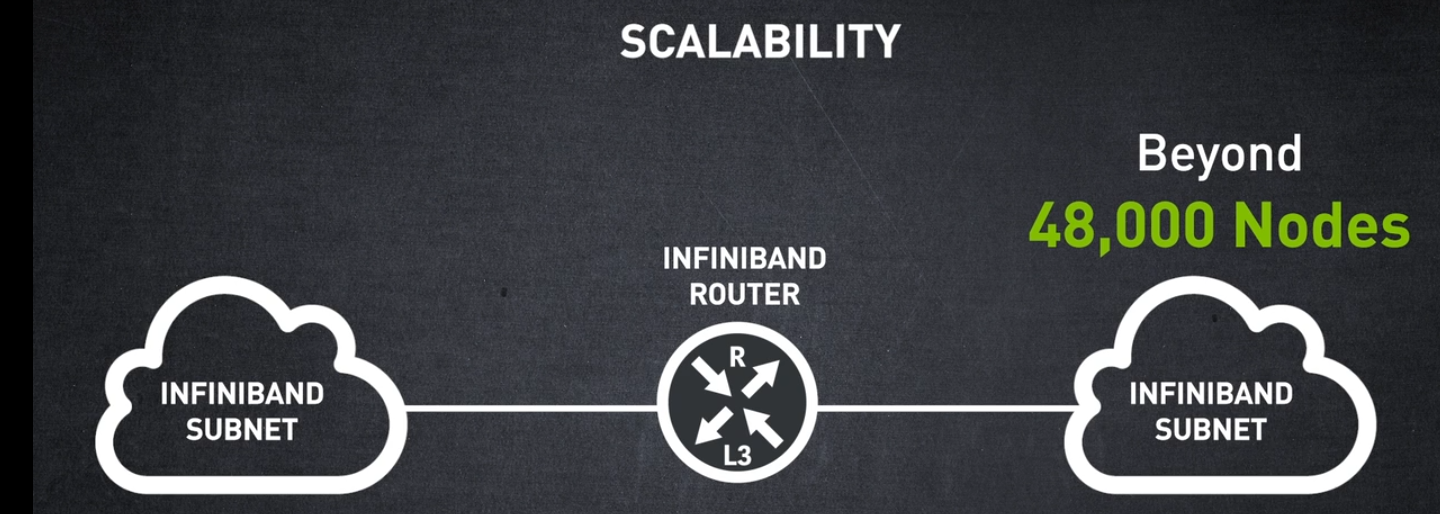
하지만 48,000개 이상의 노드를 쉽게 확장하기 위해 InfiniBand 라우터를 사용하여 여러 InfiniBand 서브넷을 상호 연결할 수 있습니다.
지금까지 우리는 Subnet Manager로 쉽게 관리할 수 있고 CPU 오프로드를 통해 높은 대역폭과 낮은 대기 시간을 제공할 수 있는 확장된 InfiniBand 서브넷을 보유하고 있습니다.
여러분이 이미 이러한 훌륭한 기능에 깊은 인상을 받았기를 바랍니다.
QUALITY OF SERVICE
하지만 서브넷에서 실행 중인 다른 애플리케이션이 있고 일부 애플리케이션을 다른 애플리케이션보다 우선순위로 지정하고 싶다면 어떻게 될까요?
즉, InfiniBand는 서비스 품질을 제공할 수 있습니까?
서비스 품질은 다양한 애플리케이션, 사용자 및 데이터 흐름에 서로 다른 우선순위를 제공하는 기능입니다.


더 높은 우선순위가 필요한 애플리케이션은 다른 포트 대기열에 매핑되고 해당 패킷은 먼저 네트워크의 다음 요소로 전송됩니다.
네트워크가 안정적이고 장애가 없으면 모든 것이 훌륭하게 들립니다.
다음으로, InfiniBand가 장애에 대처하고 거의 감지할 수 없는 네트워크 연속성을 허용하는 기능을 다루겠습니다.
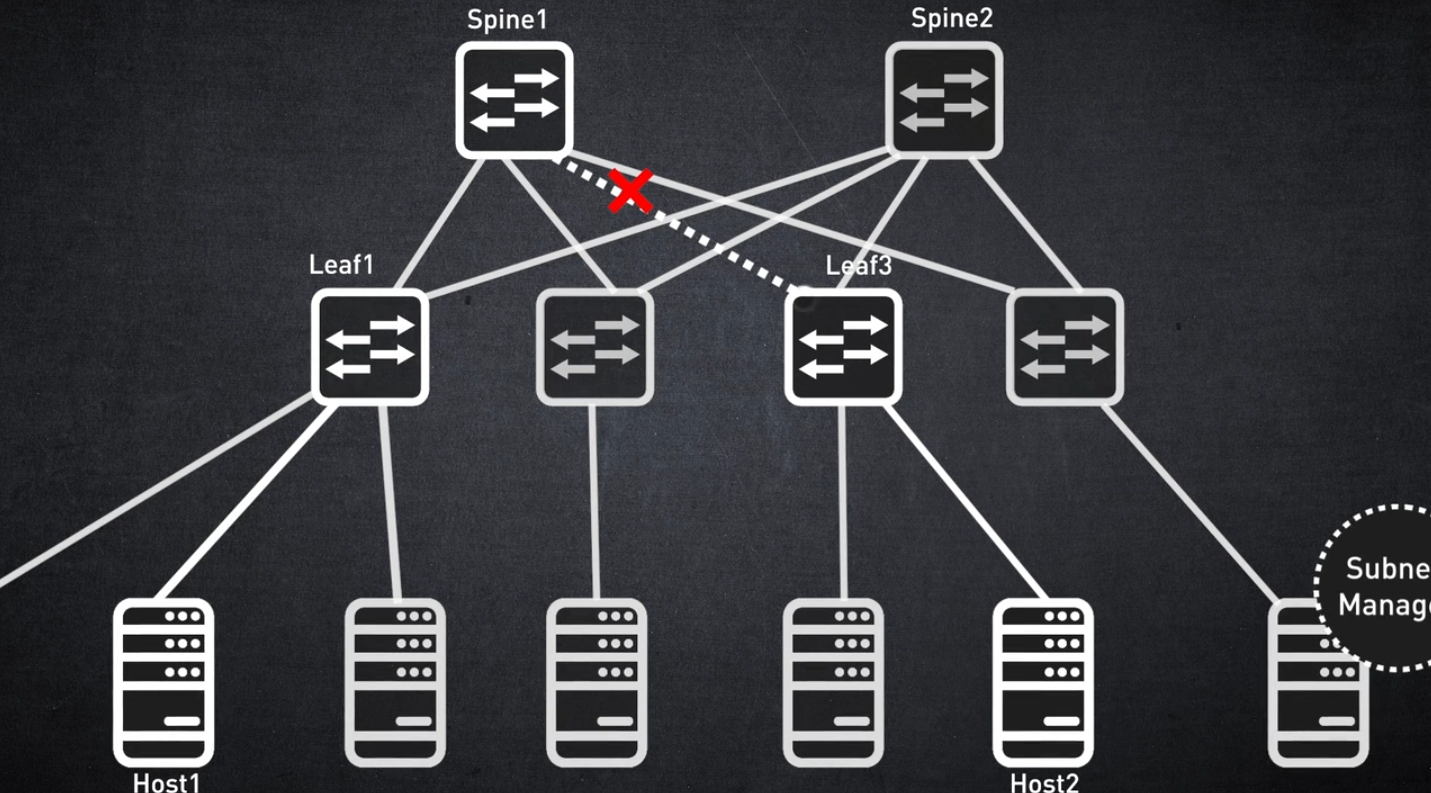
고객이 요구하는 주요 기능 중 하나는 링크 장애가 없는 안정적인 네트워크입니다. 이러한 경우 트래픽 재개는 매우 빨라야 합니다.
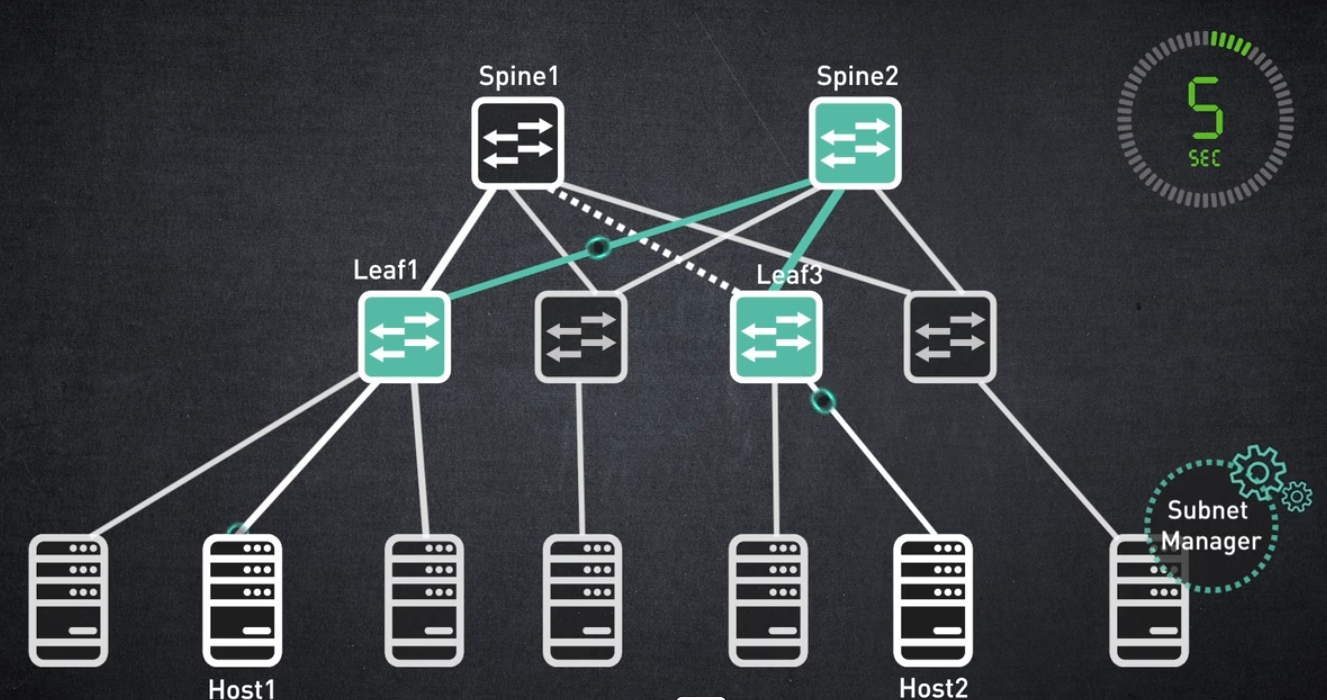
트래픽 재라우팅이 서브넷 관리자 라우팅 알고리즘에만 의존하는 경우 트래픽 갱신에 약 5초가 걸릴 수 있습니다.
SELF-HEALING NETWORKING
NVIDIA InfiniBand 솔루션은 자가 치유 네트워킹이라는 메커니즘을 갖추고 있습니다. 자가 치유 네트워킹은 NVIDIA 스위치의 하드웨어 기반 기능입니다.
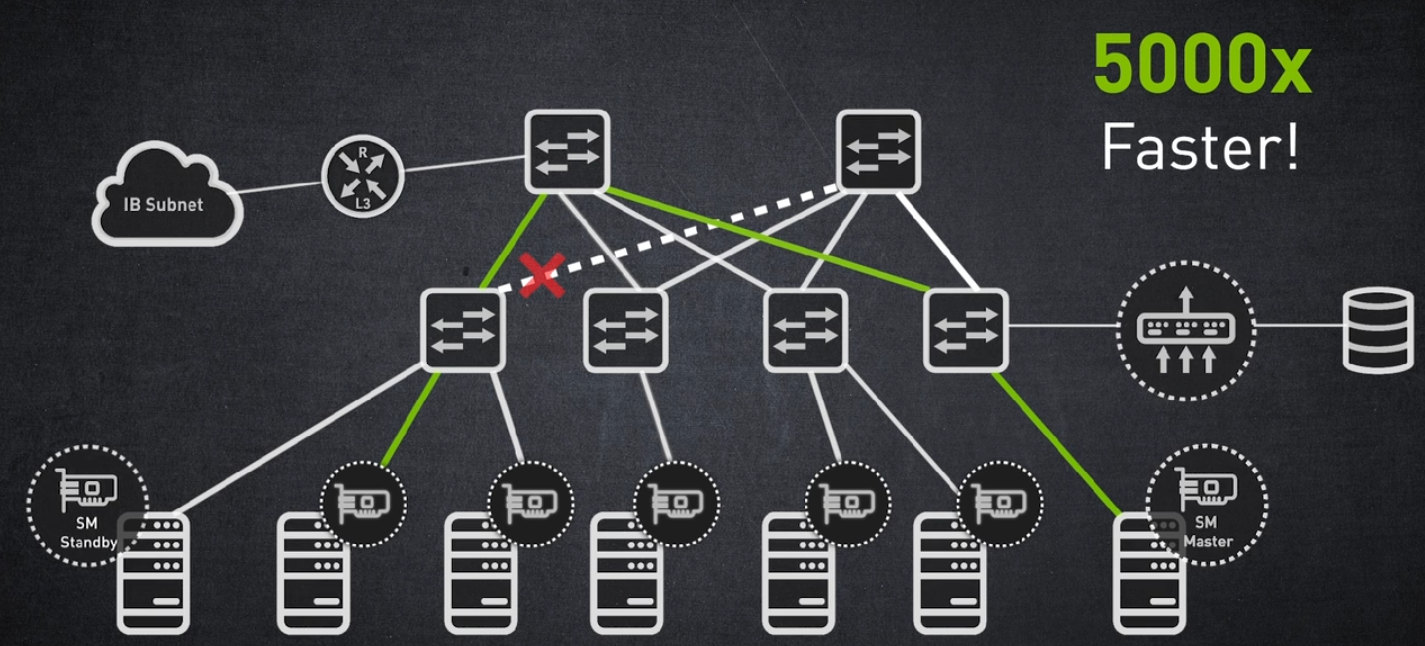
NVIDIA 자가 치유 네트워킹은 5000배 더 빠른 링크 오류 복구를 가능하게 합니다. 이는 복구 시간이 단 1밀리초밖에 걸리지 않는다는 것을 의미합니다.
LOAD-BALANCING
최신 고성능 데이터 센터에서 해결해야 할 또 다른 요구 사항은 네트워크를 최대한 활용하고 최적화하는 방법입니다.
이를 달성하는 한 가지 방법은 로드 밸런싱 체계를 갖추는 것입니다. 로드 밸런싱은 트래픽을 사용 가능한 여러 경로에 분산시킬 수 있는 라우팅 전략입니다.
적응형 라우팅은 각 스위치 포트에서 전송되는 트래픽 양을 동일하게 만드는 기능입니다.

적응형 라우팅은 NVIDIA 스위치 하드웨어에서 활성화되며 적응형 라우팅 관리자에 의해 관리됩니다.
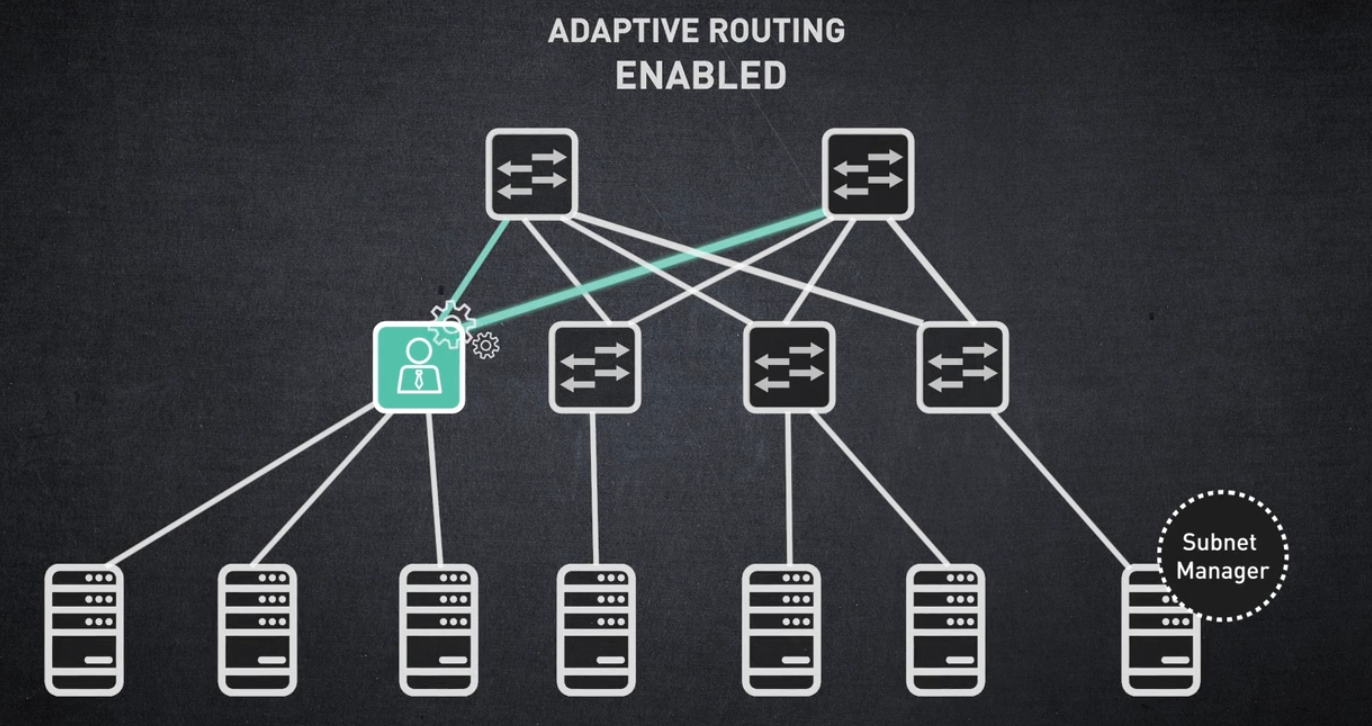
적응형 라우팅이 활성화되면 스위치 "큐 관리자"는 모든 GROUP EXIT 포트 간의 볼륨 레벨을 지속적으로 비교합니다.
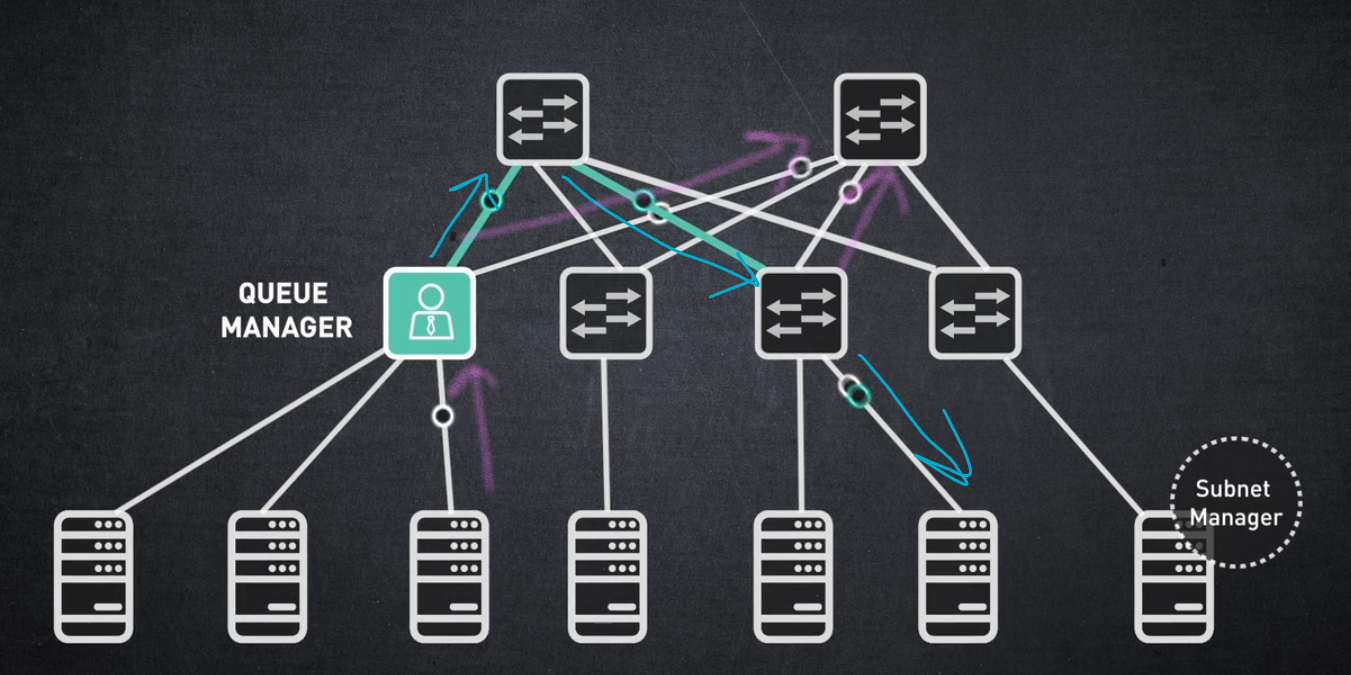
대기열 관리자는 대기열의 로드 균형을 지속적으로 조정하여 흐름을 리디렉션하고 덜 활용되는 대체 포트로 패킷을 보냅니다.
요약하자면: 적응형 라우팅은 모든 패브릭 스위치에서 활성화될 수 있습니다.
적응형 라우팅은 동적 로드 밸런싱을 지원하여 네트워크 내 정체를 방지하고 네트워크 대역폭 활용도를 최적화합니다.
SHARP (Scalable Hierarchical Aggregation and Reduction Protocol)
NVIDIA의 지능형 InfiniBand 스위치는 SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)라는 네트워킹 내 컴퓨팅 기술도 지원합니다.
SHARP는 NVIDIA의 스위치 하드웨어와 중앙 관리 패키지를 기반으로 하는 메커니즘입니다.
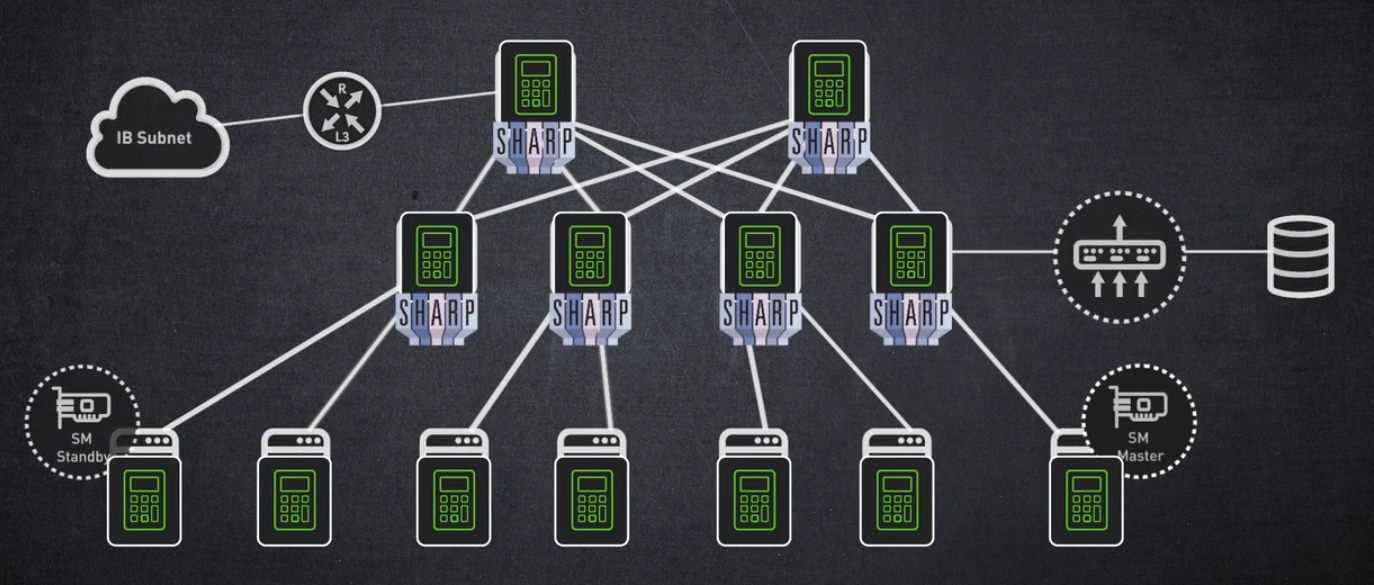
SHARP는 호스트 CPU 또는 GPU에서 네트워크 스위치로 집합적인 작업을 오프로드하고 엔드포인트 간에 데이터를 여러 번 전송할 필요성을 제거합니다. 즉 SHARP는 네트워크를 통과하는 데이터의 양을 줄입니다.
결과적으로 SHARP는 AI, 기계 학습 등과 같은 가속 컴퓨팅 MPI 기반 애플리케이션의 성능을 최대 10배까지 극적으로 향상시킵니다.
FAT-TREE
마지막으로 InfiniBand는 다음을 포함하여 다양한 지원 토폴로지 옵션을 제공합니다.
Fat Tree 지원 옵션은 다음과 같습니다.
- Torus
- Dragonfly + Hypercube
- HyperX
다양한 토폴로지를 지원할 수 있는 InfiniBand는 다음과 같은 다양한 고객의 요구 사항에 응답합니다.

- 총 소유 비용
- 최대 차단 비율
- 패브릭 노드 간 최소 대기 시간과 최대 거리.
SUMMARY
이 세션에서는 InfiniBand를 최신 데이터 센터의 가속화된 컴퓨팅 애플리케이션을 위한 가장 고성능, 효과, 탄력성 및 활용도가 높은 상호 연결 기술로 만드는 주요 핵심 기능에 대해 설명했습니다.
다음 비디오에서는 InfiniBand 아키텍처 및 관리에 대해 알아보겠습니다.
InfiniBand Architecture
InfiniBand 아키텍처 교육 세션에 오신 것을 환영합니다.
이 비디오에서는 InfiniBand 아키텍처를 살펴보고 이것이 어떻게 가속화된 컴퓨팅 애플리케이션을 제공하는지 살펴보겠습니다.
이를 통해 낮은 대기 시간, 높은 대역폭 및 CPU 주기 감소를 활성화할 수 있습니다. 따라서 컴퓨팅 시스템의 고성능 및 효율적인 확장이 가능합니다.

InfiniBand 아키텍처는 기존 TCP/IP 모델과 유사한 방식으로 5개 계층으로 구분되지만 InfiniBand와 IP 네트워크 간에는 많은 차이점이 있습니다.
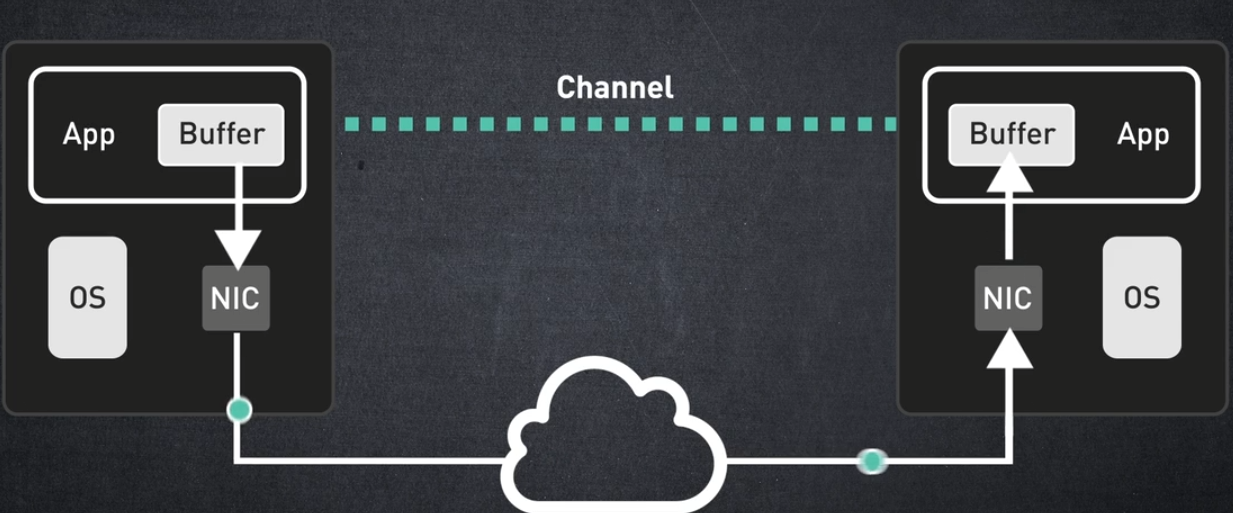
전통적으로 애플리케이션은 필요한 통신 서비스를 제공하기 위해 운영 체제에 의존했지만, InfiniBand를 사용하면 운영 체제를 직접 사용하지 않고도 애플리케이션이 네트워크를 통해 데이터를 교환할 수 있습니다.
이러한 애플리케이션 중심 접근 방식은 InfiniBand 네트워크와 기존 네트워크 간의 주요 차별화 요소입니다.
이제 각 계층이 가속화된 컴퓨팅 애플리케이션에 필요한 빠르고 효율적인 데이터 전송에 어떻게 기여하는지 하향식으로 살펴보겠습니다.
Upper Layer
상위 계층부터 시작하겠습니다.
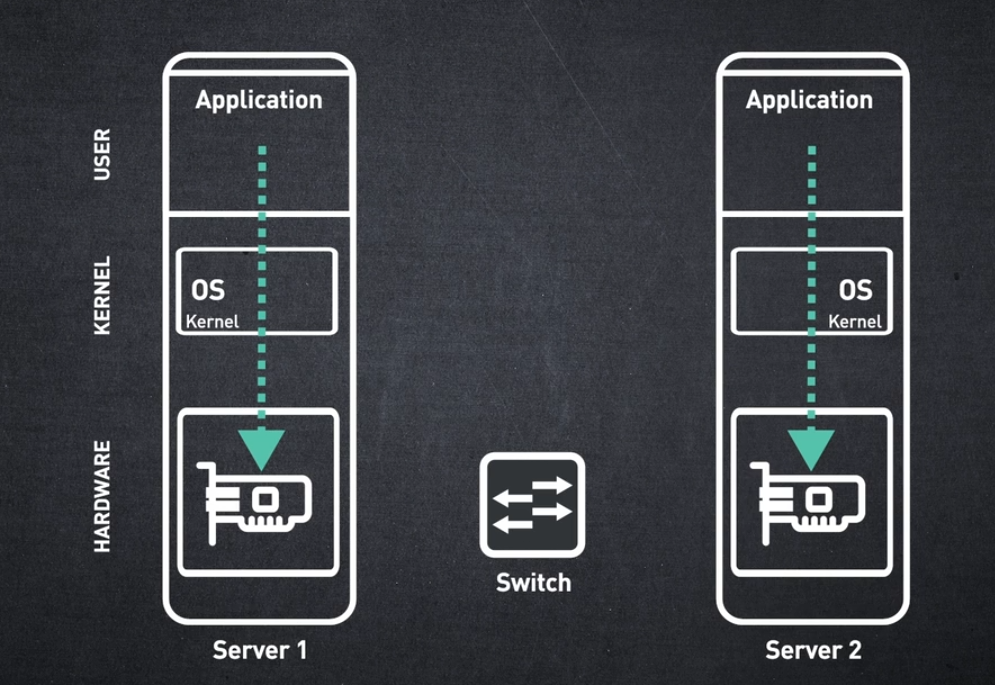
애플리케이션은 InfiniBand 메시지 서비스의 "소비자"입니다. InfiniBand 아키텍처의 최상위 계층은 애플리케이션이 InfiniBand에서 제공하는 서비스 세트에 액세스하는 데 사용하는 방법을 정의합니다.
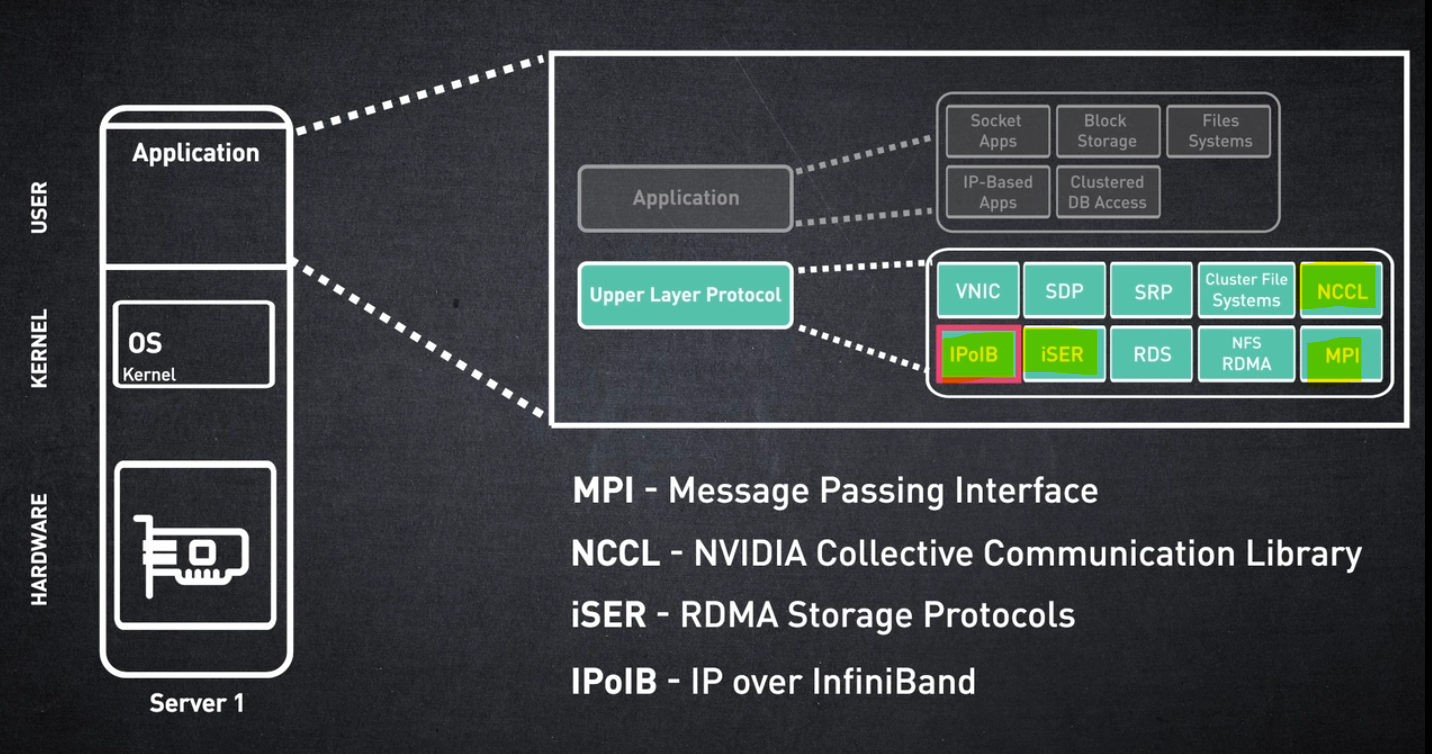
상위 계층 프로토콜은 애플리케이션에서 쉽게 인식할 수 있는 표준 인터페이스를 제공합니다. 지원되는 상위 계층 프로토콜 중 일부는 다음과 같습니다.
• MPI(메시지 전달 인터페이스, Message Passing Interface) - 분산/병렬 컴퓨팅을 위한 라이브러리 인터페이스
• NCCL - NVIDIA 집단 통신 라이브러리
• iSER - RDMA저장 프로토콜
• IPoIB - IP over InfiniBand
Transport Layer
다음으로 전송 계층으로 넘어가겠습니다. 애플리케이션의 메시지가 소스에서 대상으로 어떻게 전송되는지 확인하세요.
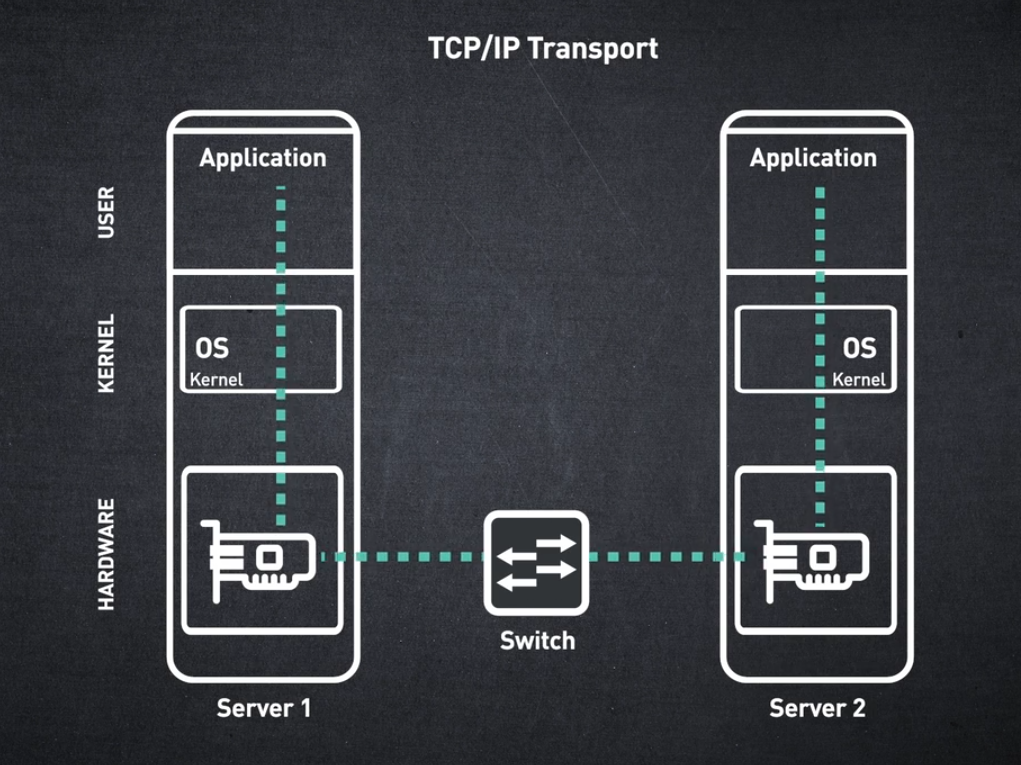
InfiniBand 메시징 서비스는 한 노드의 운영 체제에서 다른 노드의 운영 체제로 데이터를 이동하는 기존 TCP/IP에서 제공하는 서비스와 다릅니다.
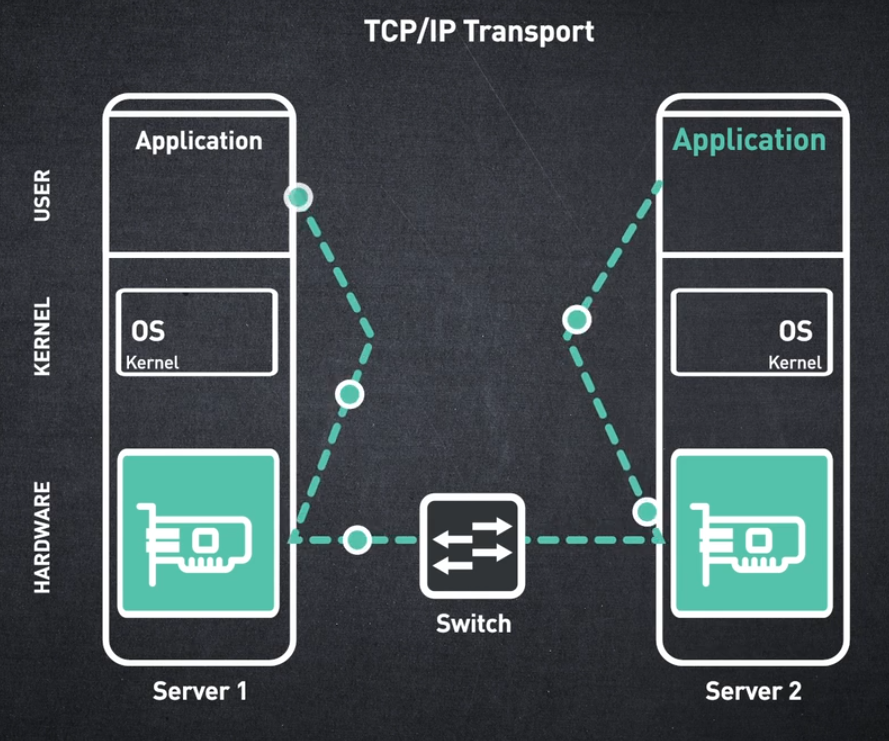
InfiniBand는 HCA 또는 호스트 채널 어댑터라고도 하는 네트워크 어댑터에 의해 구현되는 하드웨어 기반 전송 서비스를 제공합니다. 완전히 별개의 주소 공간에 존재하는 두 개의 애플리케이션을 연결하는 엔드투엔드 "가상 채널"이 생성됩니다.
애플리케이션이 메시지 전송을 요청하면 해당 메시지는 보내는 하드웨어에 의해 전송됩니다. 메시지가 수신 하드웨어에 도착하면 수신 애플리케이션의 버퍼로 직접 전달됩니다.
대기 시간이 매우 짧고 CPU 사용률이 거의 0인 메시지가 네트워크를 통해 이동하는 것을 상상할 수 있습니까?
Network Layer
지금까지 우리는 엔드 노드에 대해 이야기했습니다.
그러나 아마도 라우터나 스위치와 같이 해당 노드를 연결하는 네트워킹 장치가 많이 있을 것입니다.
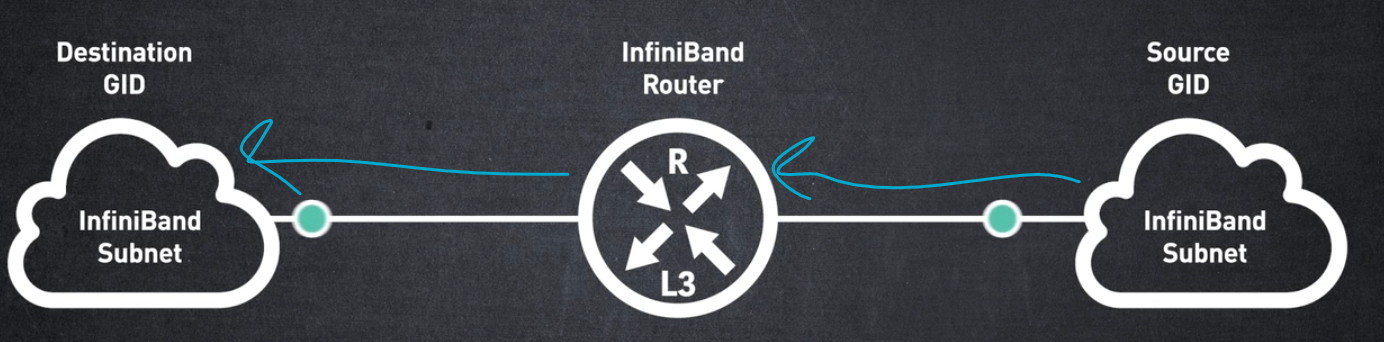
InfiniBand 라우터는 서로 다른 InfiniBand 서브넷을 연결하는 데 사용됩니다. 이를 통해 여러 서브넷에서 네트워크 확장, 트래픽 격리 및 공통 리소스 사용이 가능합니다.
네트워크 계층은 서로 다른 서브넷 간의 패킷 라우팅을 허용하는 프로토콜을 설명합니다. 라우터는 전역 ID 또는 GID라는 네트워크 계층 주소를 사용하여 패킷을 대상 노드로 라우팅합니다.
하지만 패킷이 로컬 서브넷에서 라우팅된다면 어떻게 될까요?
동일한 서브넷의 끝 노드 간 전환은 어떻게 처리됩니까?
Link Layer
이것이 바로 링크 레이어로 연결됩니다.

서브넷의 각 노드에는 로컬 ID 또는 LID라는 주소가 할당됩니다.
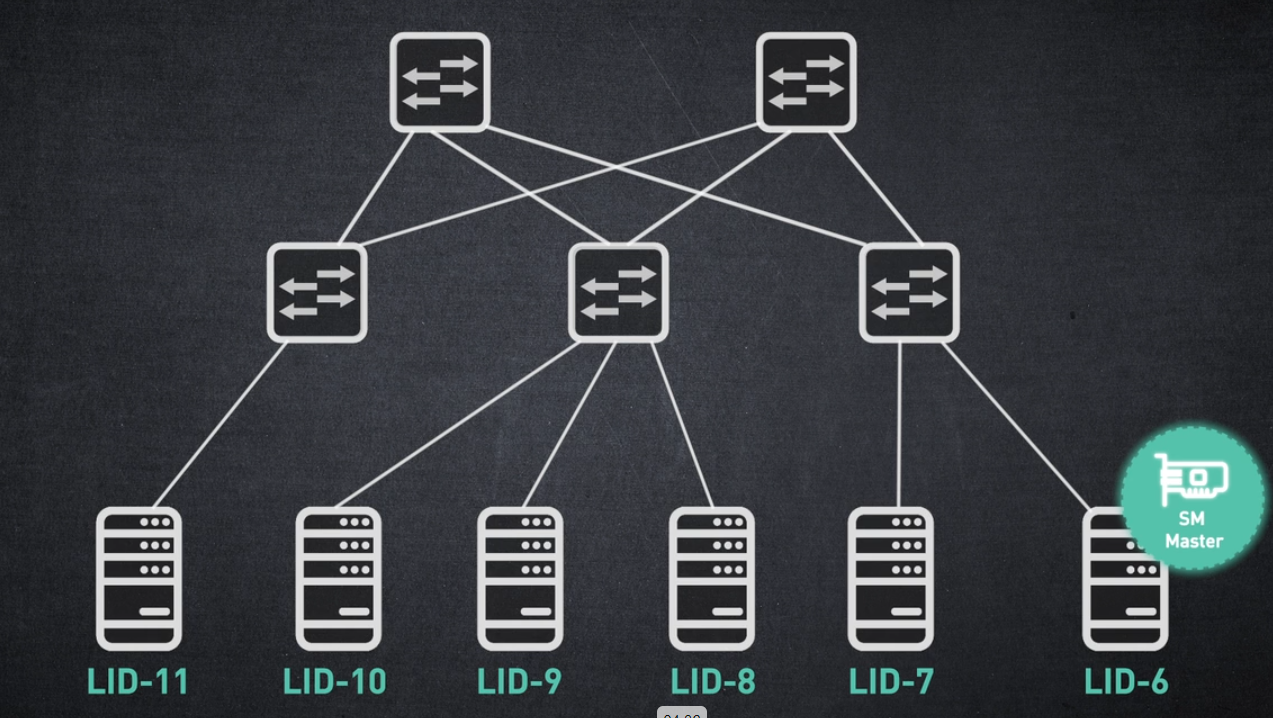
LID는 서브넷을 관리하는 Subnet Manager에 의해 할당되고 유지 관리됩니다.
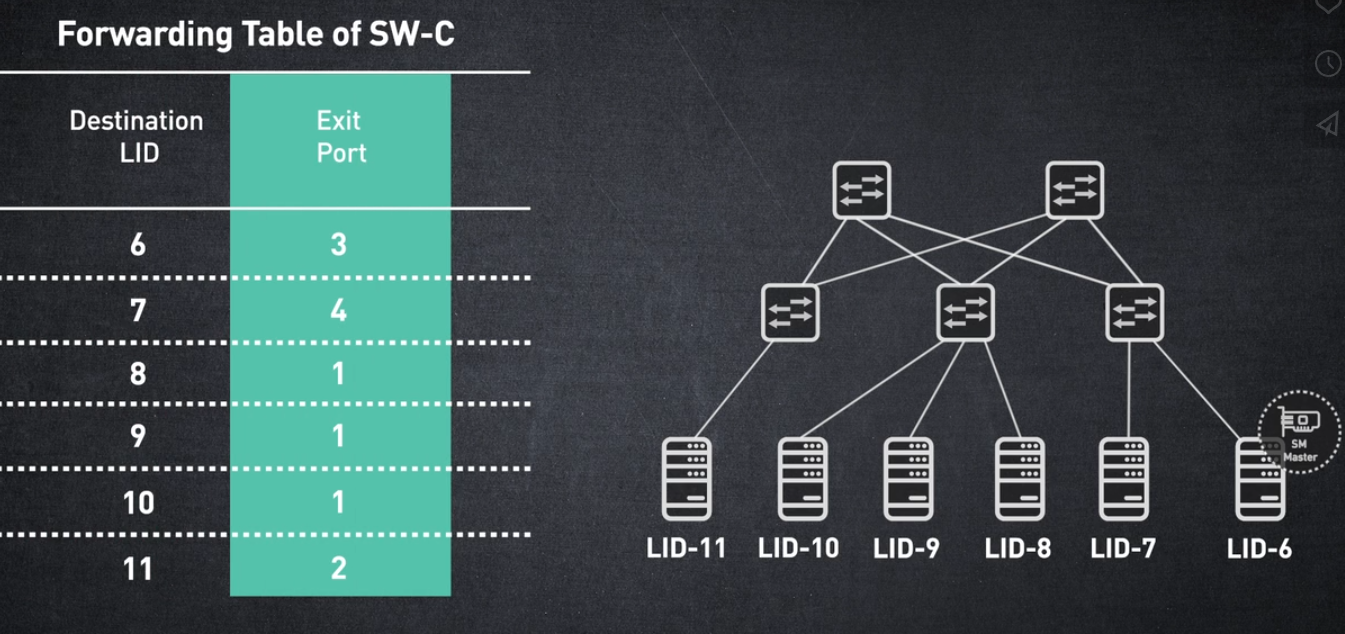
스위치의 전달 테이블은 대상 LID를 종료 포트에 매핑하는 항목으로 채워집니다.
이러한 전달 테이블은 서브넷 관리자에 의해 계산되고 스위치 하드웨어에 프로그래밍됩니다. 패킷이 끝 노드에 의해 생성되면 소스 LID와 대상 LID가 포함됩니다.
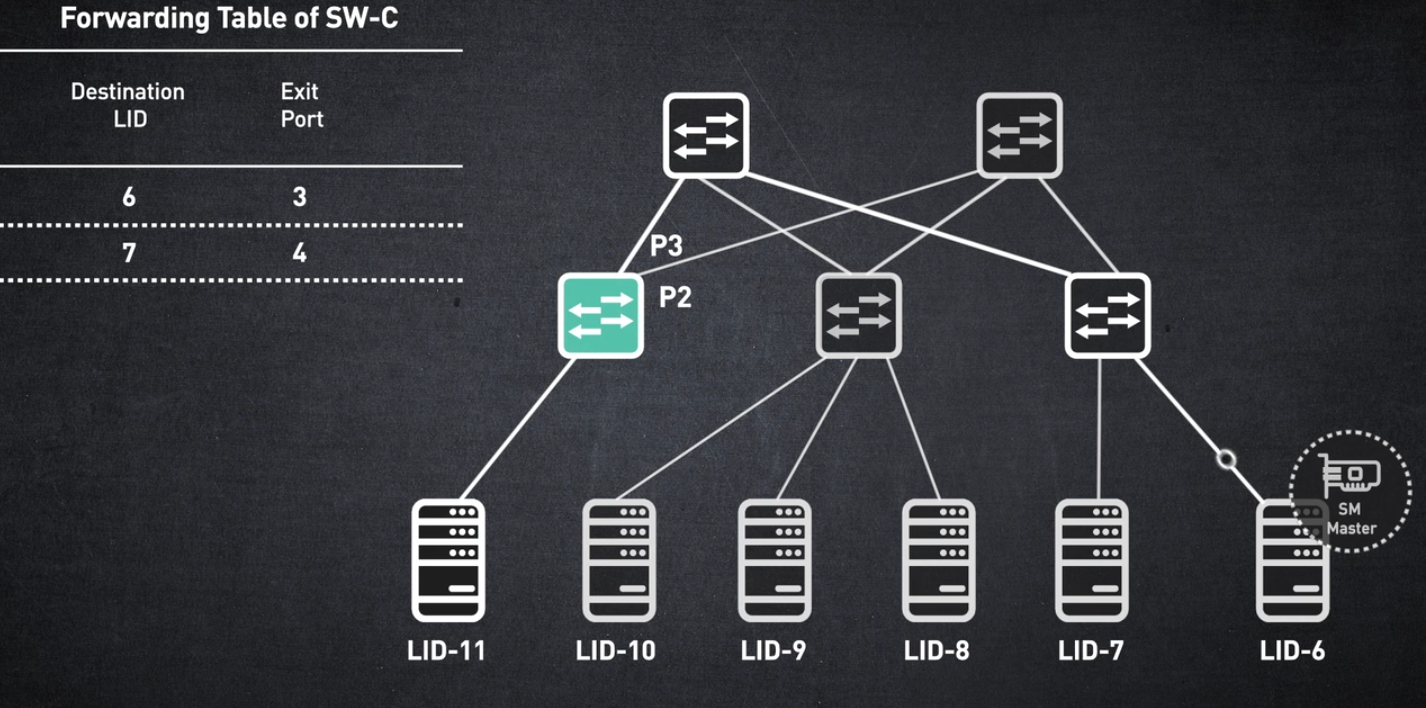
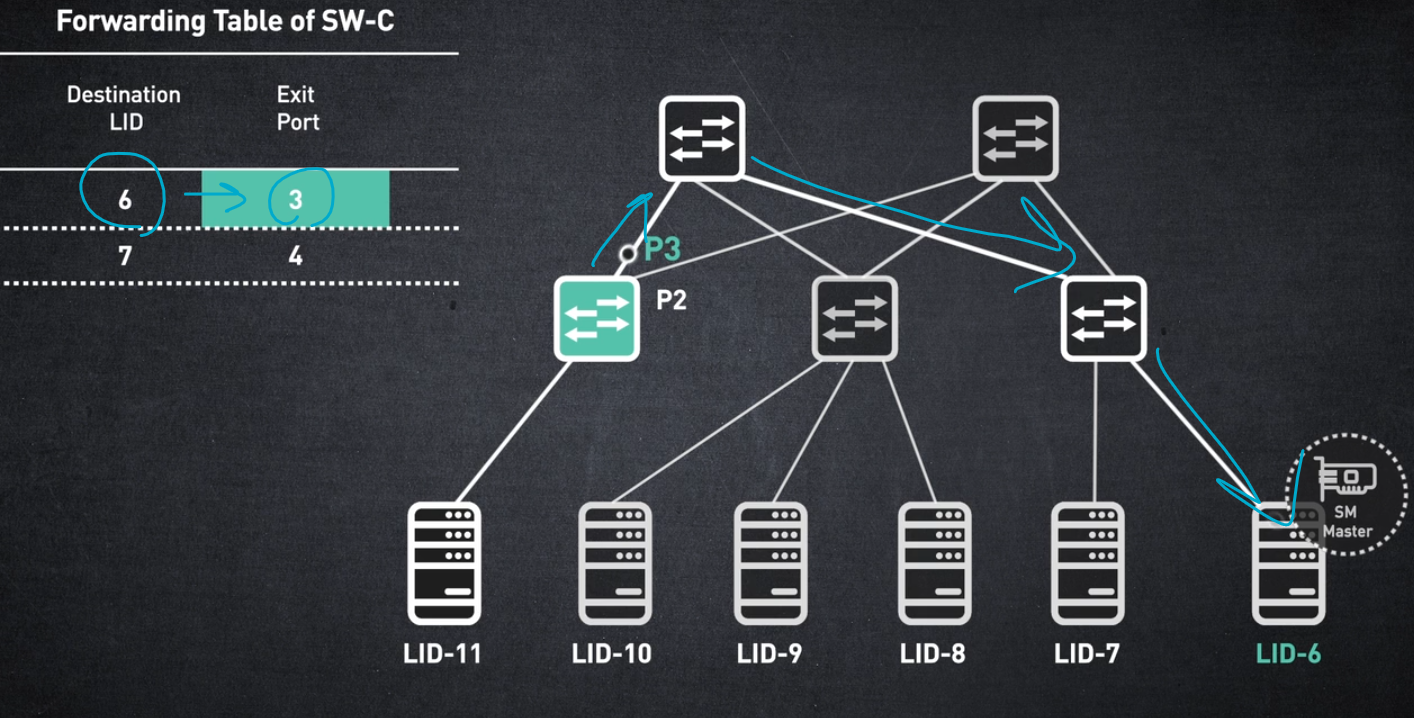
패킷이 스위치에 도착하면 대상 LID가 스위치 항목과 일치하고 해당 출구 포트를 통해 전송됩니다.
Flow Control Mechanism
InfiniBand의 또 다른 핵심 요소는 링크 계층 흐름 제어 메커니즘입니다.
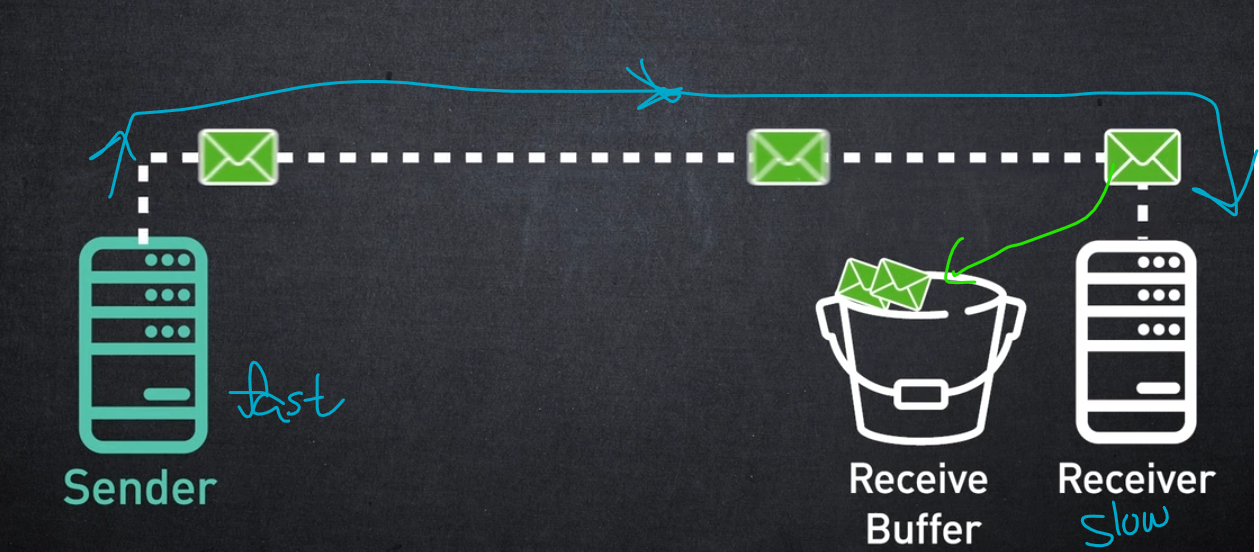
흐름 제어 메커니즘은 빠른 송신자가 느린 수신자에게 과부하를 주지 않도록 송신자와 수신자 사이의 전송 속도를 조정하는 데 사용됩니다.

송신 노드는 수신 버퍼 사용량을 동적으로 추적하고 수신 노드 버퍼에 공간이 있는 경우에만 데이터를 전송합니다.
이것이 InfiniBand를 무손실 네트워크로 만드는 이유입니다.
정상 작동 중에는 네트워크에서 패킷이 삭제되지 않습니다. 무손실 흐름 제어를 통해 데이터 센터 내에서 대역폭을 매우 효율적으로 사용할 수 있습니다.
Physical Layer
이러한 모든 메커니즘은 훌륭해 보이지만 결국 비트가 물리적 매체를 통해 전송될 때 데이터 전송이 발생합니다.
물리 계층은 비트가 회선에 배치되는 방식과 유효한 패킷의 신호 프로토콜을 지정합니다.

또한 물리적 계층은 구리 및 광케이블의 특성과 사양을 정의합니다.
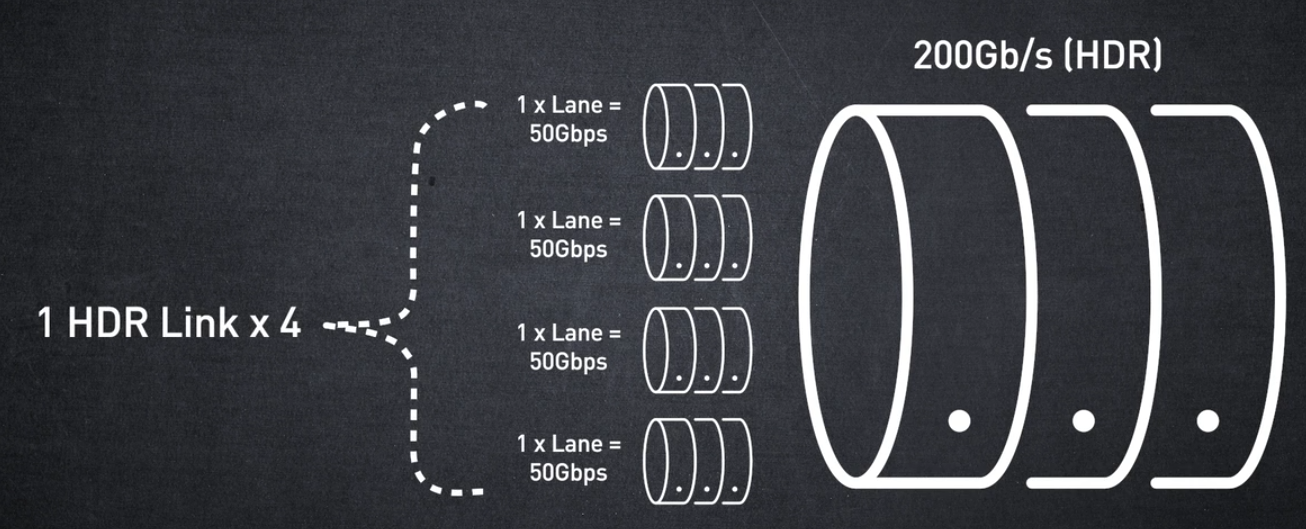
여러 물리적 레인을 통합하면 더 높은 대역폭을 제공할 수 있습니다.
와, 우리는 송신 애플리케이션과 수신 애플리케이션 간에 메시지를 전송하는 데 많은 노력을 기울였습니다.
SUMMARY
우리는 InfiniBand 아키텍처의 다양한 계층을 다루었으며 각 계층이 어떻게 컴퓨팅 및 네트워킹 리소스를 효율적으로 활용하는지 살펴보았습니다.
이 고성능 대역폭은 매우 낮고 거의 0에 가까운 CPU 사용률과 결합되어 컴퓨팅 시스템을 효율적으로 확장할 수 있습니다.
이번 세션에서는 InfiniBand 아키텍처의 기본 계층을 소개했습니다.
Course Completion Certificate

😊✌
