강의 링크 : https://www.youtube.com/watch?v=59BFOn9zyCQ&list=PLg_wJlcMiuKtGdlIaAZ0rOPPQuTDENnEQ&index=2
Logical Modeling에서 가장 널리 활용되고 있는 Relational Modeling에 대해 알아보자.
1. Relational Model Constraints
-
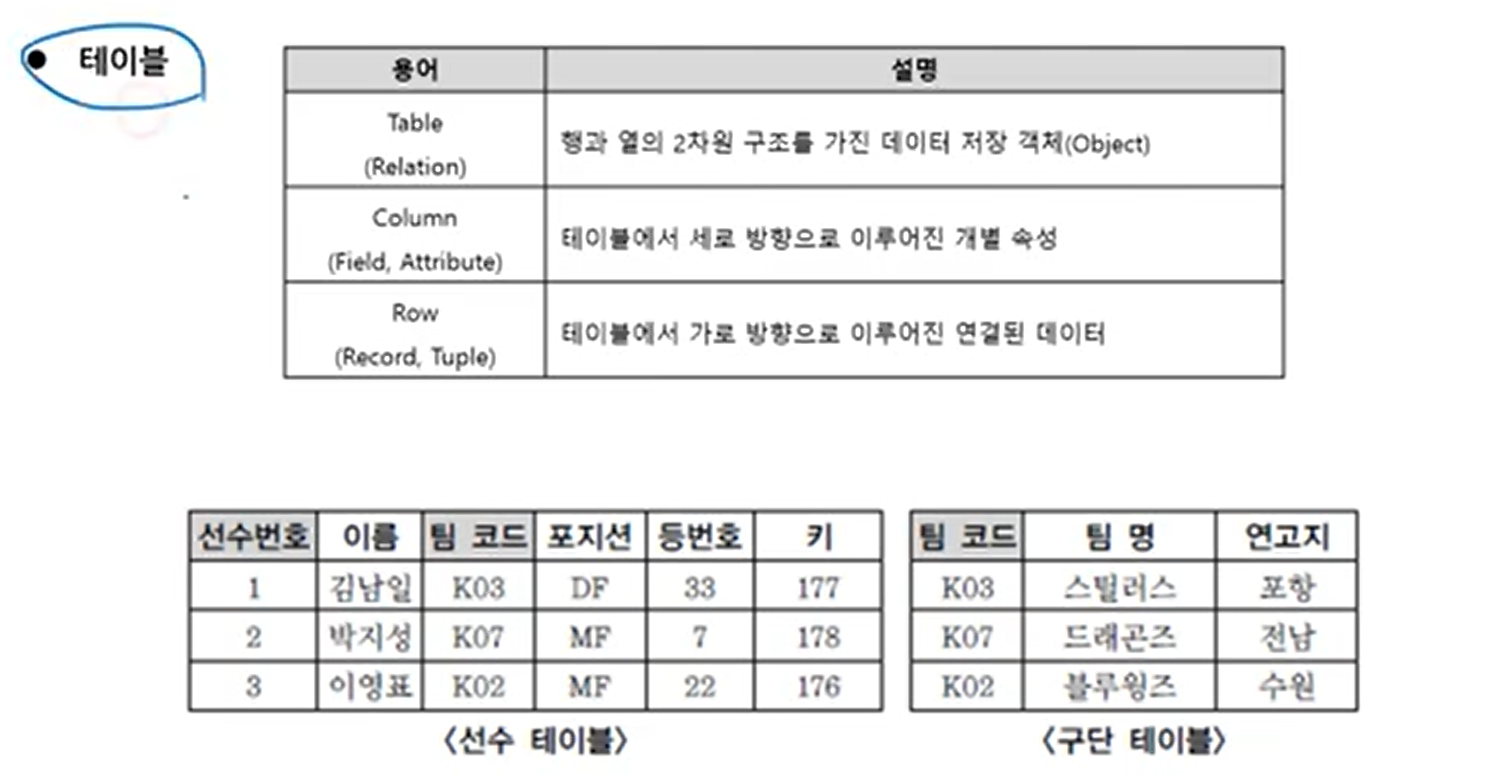
Relational Model = Relational Data Model = Relational Data Base (RDB, 관계형 데이터베이스)
-
Table : 요새 DB 사람들도 Relation이라고 안 부르고 table이라고 부름
-
Column
- Field : 엑셀, DB 모두 사용
- Attribute : 개념적 의미를 지칭할 때 사용
-
Row
- Record : DB 사람들이 사용
- Tuple : 수학적 기반을 갖고 DB 하는 사람들이 사용
-
Relational Model의 제약 (이 조건들은 만족해야 DB라고 할 수 있다!)
-
도메인 제약 (Domain Constraints)
- 속성(Attribute)에 대한 제약
- 속성 값은 원자성(atomicity)을 가지며, 도메인에서 정의된 값이어야 함(데이터 타입, 범위)
- 원자성 : 더 이상 분리되지 않은 단독성
- Composite Attribute와 Multivalued Attribute는 허용되지 않음
cf) 주소 = 시군구 + 상세 주소 - Null 값은 허용됨 (Not Null이 아닌 경우)
- ER Model의 Multivalued Attribute와 Composite Attribute를 처리해 원자성을 가진 값으로 변환시켜 Relation Model에 넣어야 함
빨간 네모 순서대로 도메인에서 벗어난 값, Null 값, 원자성 없는 값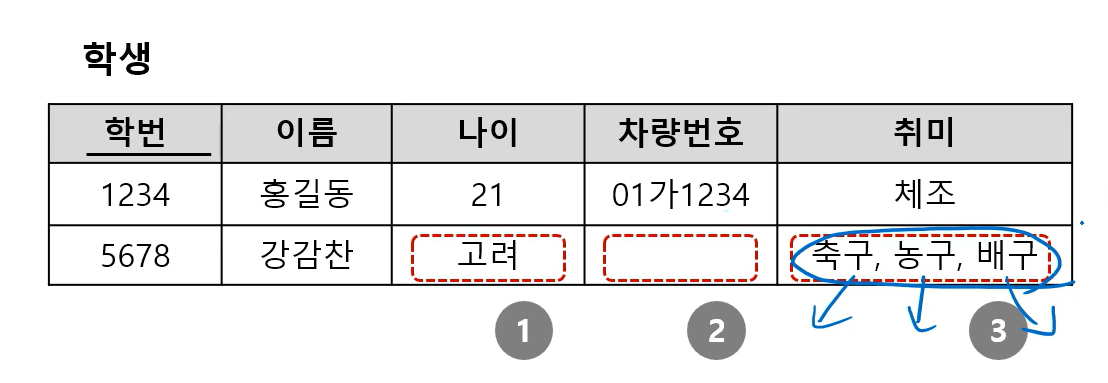
-
키 제약 (Key Constraints) 키 속성의 유무에 관한 제약
- 관계(Relation)에 대한 제약
- 테이블의 모든 레코드는 서로 구분가능해야 함 (똑같은 레코드 x)
- 키 속성이 있어야 함
- 학문적 관점에서는 'Candidate Key(후보키)'
- 설계자가 임의로 우선의 키로 지정한 건 'Primary Key(주키, 기본 키, PK)'
- Candidate Key에다 다른 속성을 더해 묶은 경우는 'Super Key' -> 잘 쓰이지는 않음
- Super Key 중 불필요한 속성을 제거하면 Candidate Key(복수 키인 경우임)
- 그 중 키 하나만 고른 걸 Primary Key
1번 테이블이 키 제약을 위반하고 있음(키를 못 잡음)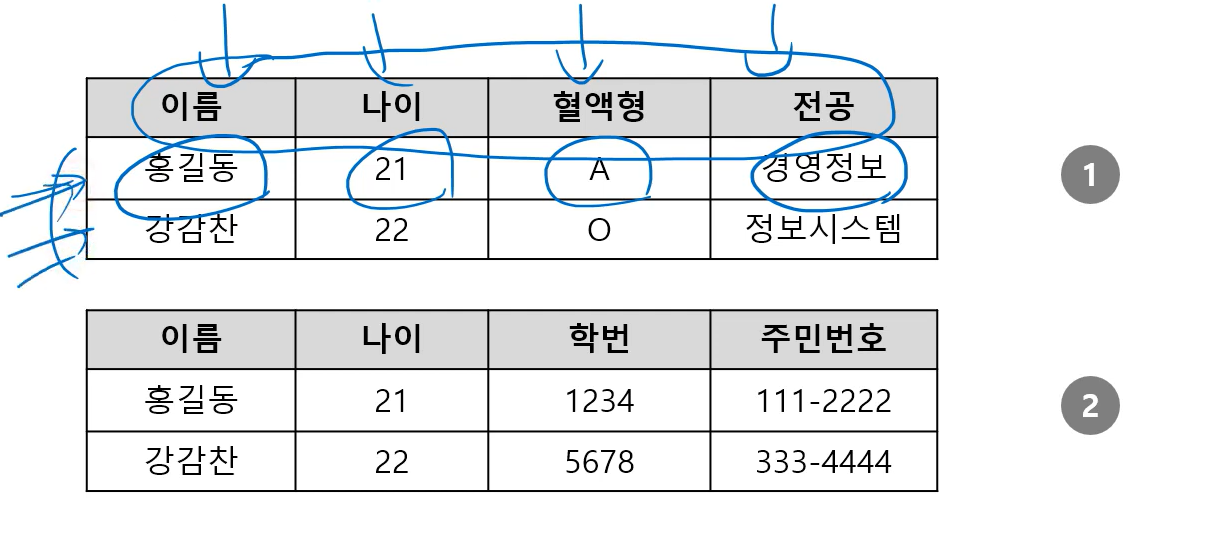
-
개체 무결성 제약 (Entity Integrity Constraints) 키 속성의 레코드에 관한 제약
- 기본키(Primary Key)에 대한 제약
- 기본키(PK)는 UNIQUE & NOT NULL이어야 함 (= 키 속성의 레코드는 무조건 값이 존재하고 중복되지 않아야 함)
2번 레코드만 개체 무결성 제약에 위배되지 않음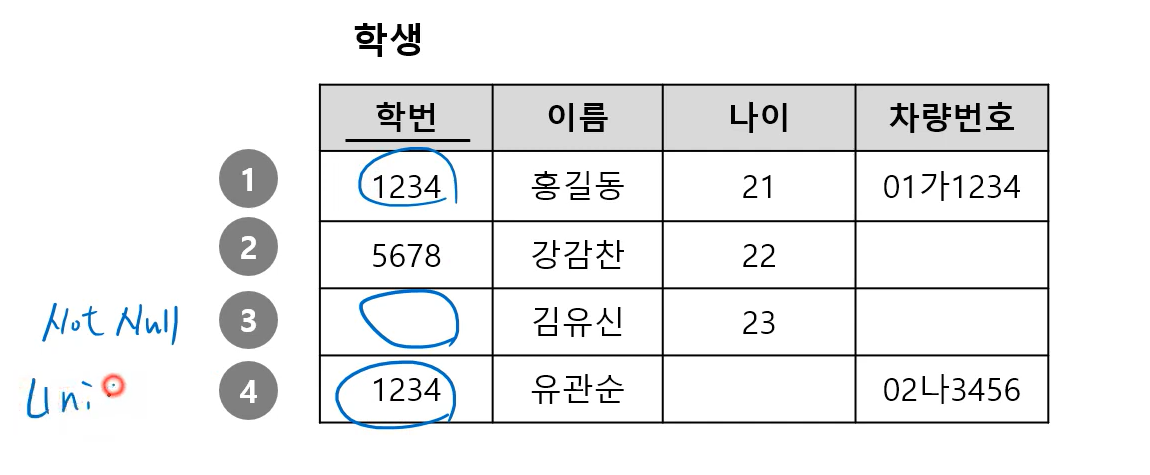
-
참조 무결성 제약 (Referential Integrity Constraints)
- 외래키(Foreign Key, FK)에 대한 제약
- Relation R1이 Relatin R2를 참조하는 경우, R1의 FK는 ...
(1) Null이거나
(2) Null이 아닌 경우, R2에 실제로 존재하는 값으로 구성되어야 함
학생 테이블의 3, 4번 레코드가 참조 무결성 제약을 위배함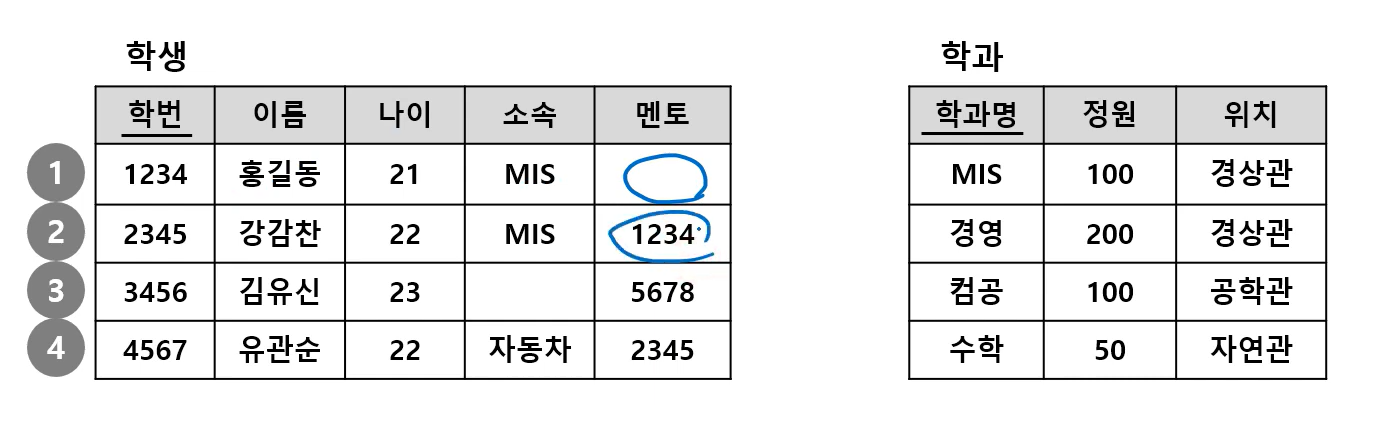
-
※ 외래키(Foregin Key, FK)란?
- Relation R1이 Relation R2를 참조하는 경우, R2의 기본키는 R1에서 외래키로 사용됨
- FK는 자기 자신이 속한 relation을 참고할 수도 있음
- 스스로 셀프 참조할 수 있음 (Unary Relationship)
- 레코드값이 중복되어도 됨 (unique하지 않아도 됨)
- Null 값이라도 됨
- 동일 테이블에 PK와 FK가 모두 존재하는 경우
학생 테이블의 '소속'은 학과 테이블의 '학과명'을 참조하는 FK임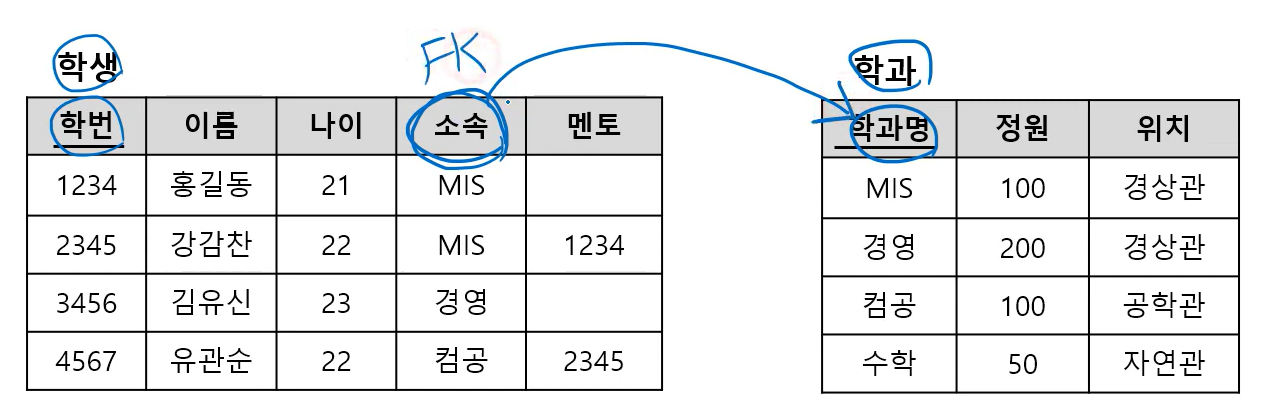
학생 테이블의 '멘토'는 동일 테이블의 '학번'을 참조함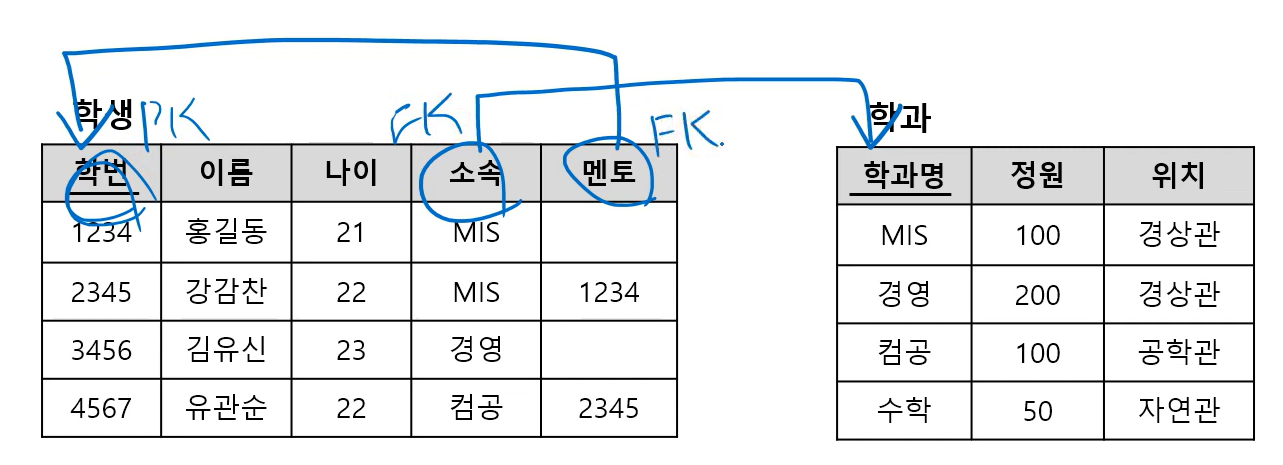
FK가 세 개 -> 개체 무결성 위배, 참조 무결성 위배, 참조 무결성 위배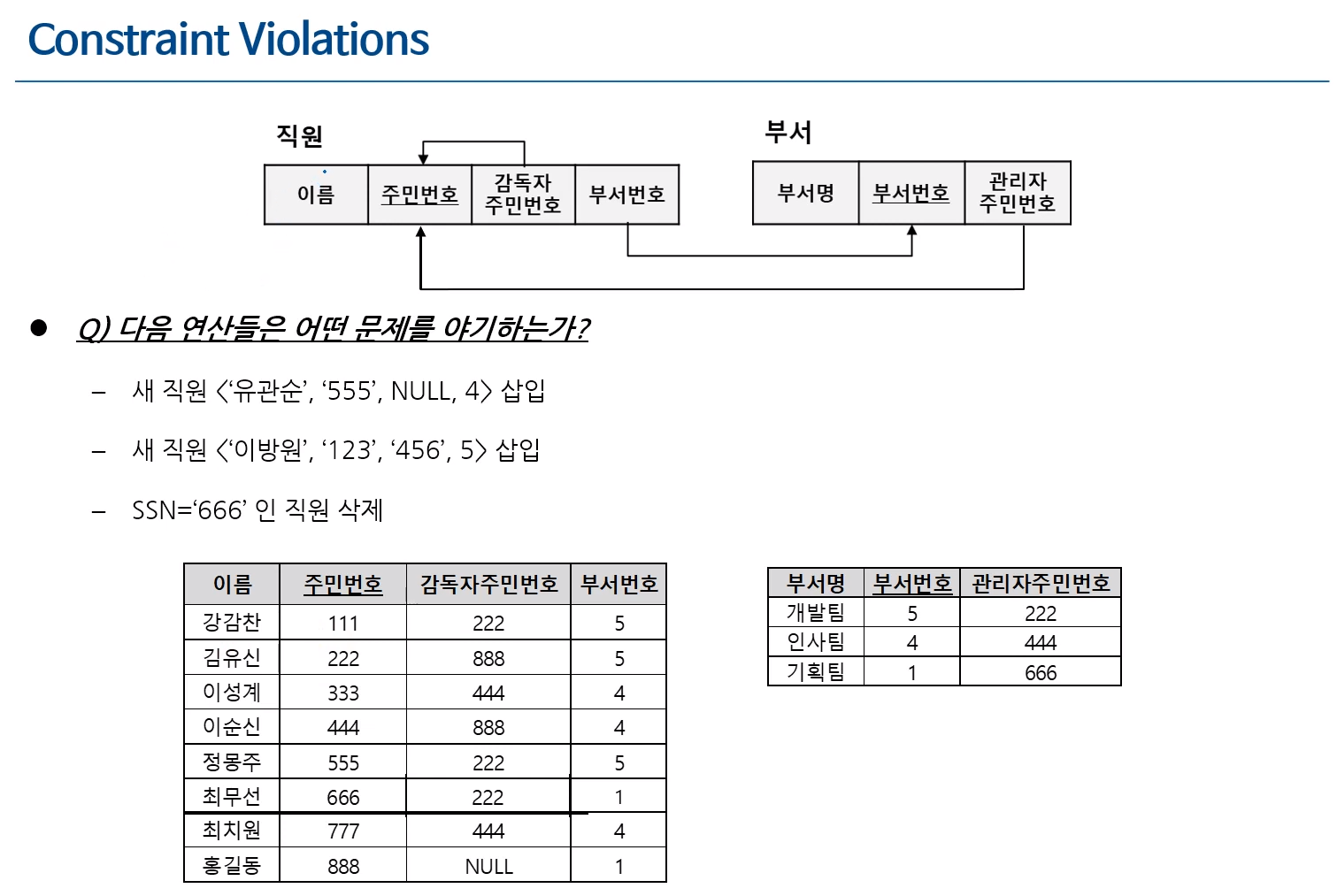
- 동일 테이블에 PK와 FK가 모두 존재하는 경우
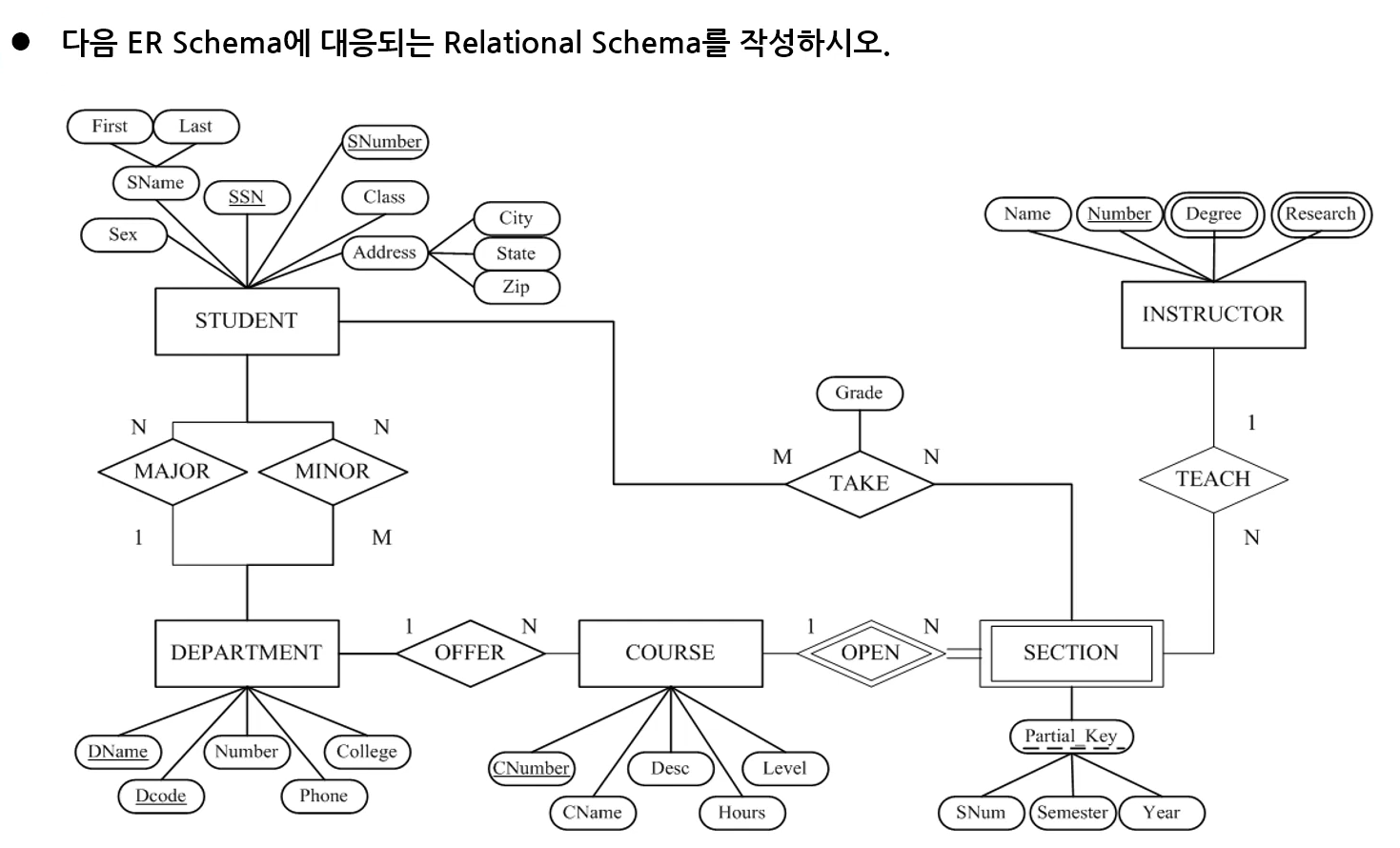
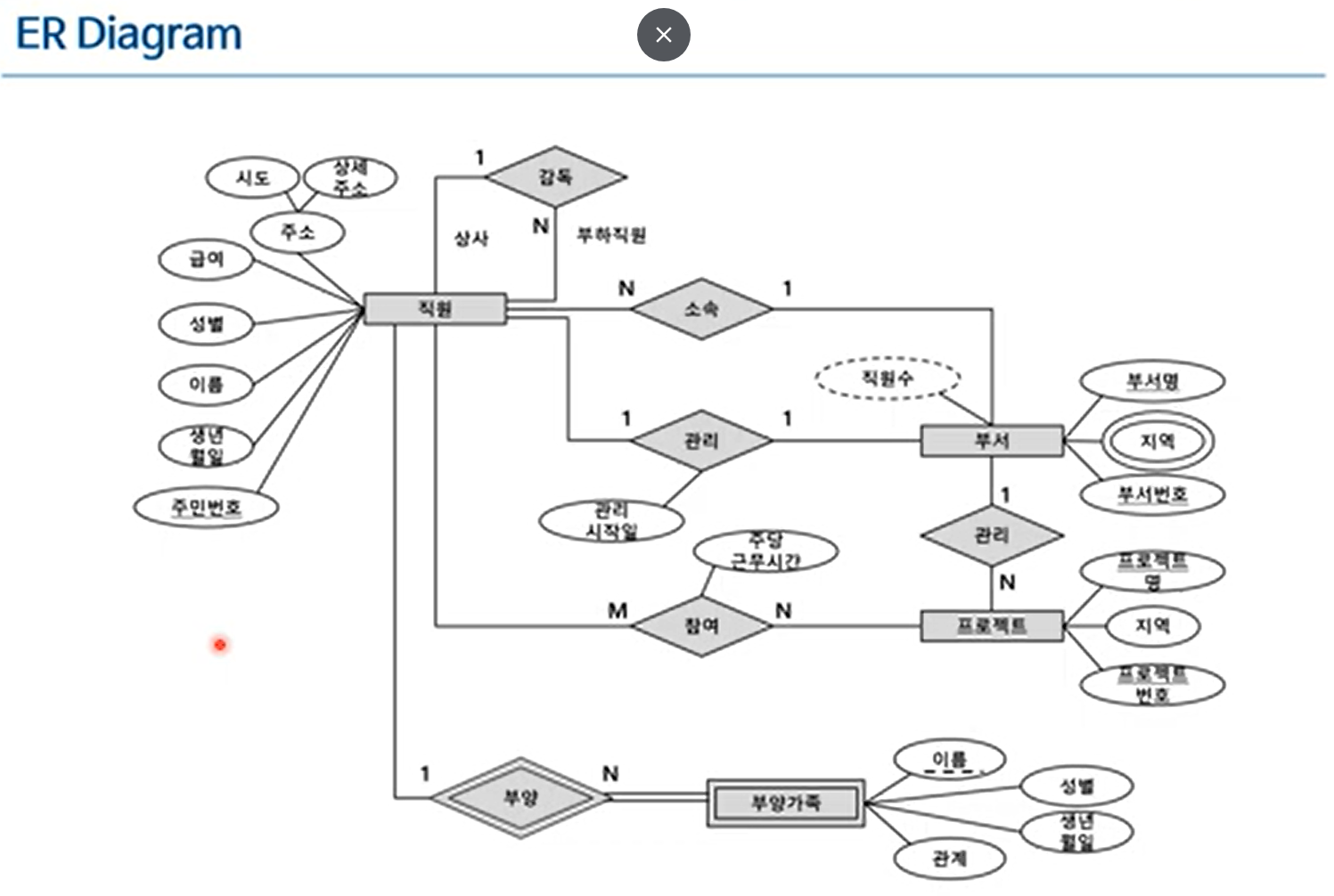
2. ER-to-Relational Model 변환 규칙
- Step 1: Mapping of Strong Entity Types (Entity → Table)
- Step 2: Mapping of Weak Entity Types (Entity → Table)
- Step 3: Mapping of Binary 1:N Relationship Types (Relationship Out, FK)
- Step 4: Mapping of Binary 1:1 Relationship Types (Relationship Out, FK)
- Step 5: Mapping of Binary M:N Relationship Types (Relationship → Table)
- Step 6: Mapping of N-ary Relationship Types (Relationship → Table)
- Step 7: Mapping of Multivalued attributes (Multivalued attribute → Table)
※ composite attribute는 step 1, 2에서 처리됨
※ 테이블을 만드는 단계는 step 1, 2, 5, 6, 7
)
- Relational Schema에서 화살표는 PK, FK의 참조키를 나타냄(화살표의 뿌리가 FK, 머리가 PK)
1) Step 1: Mapping of Strong Entity Types
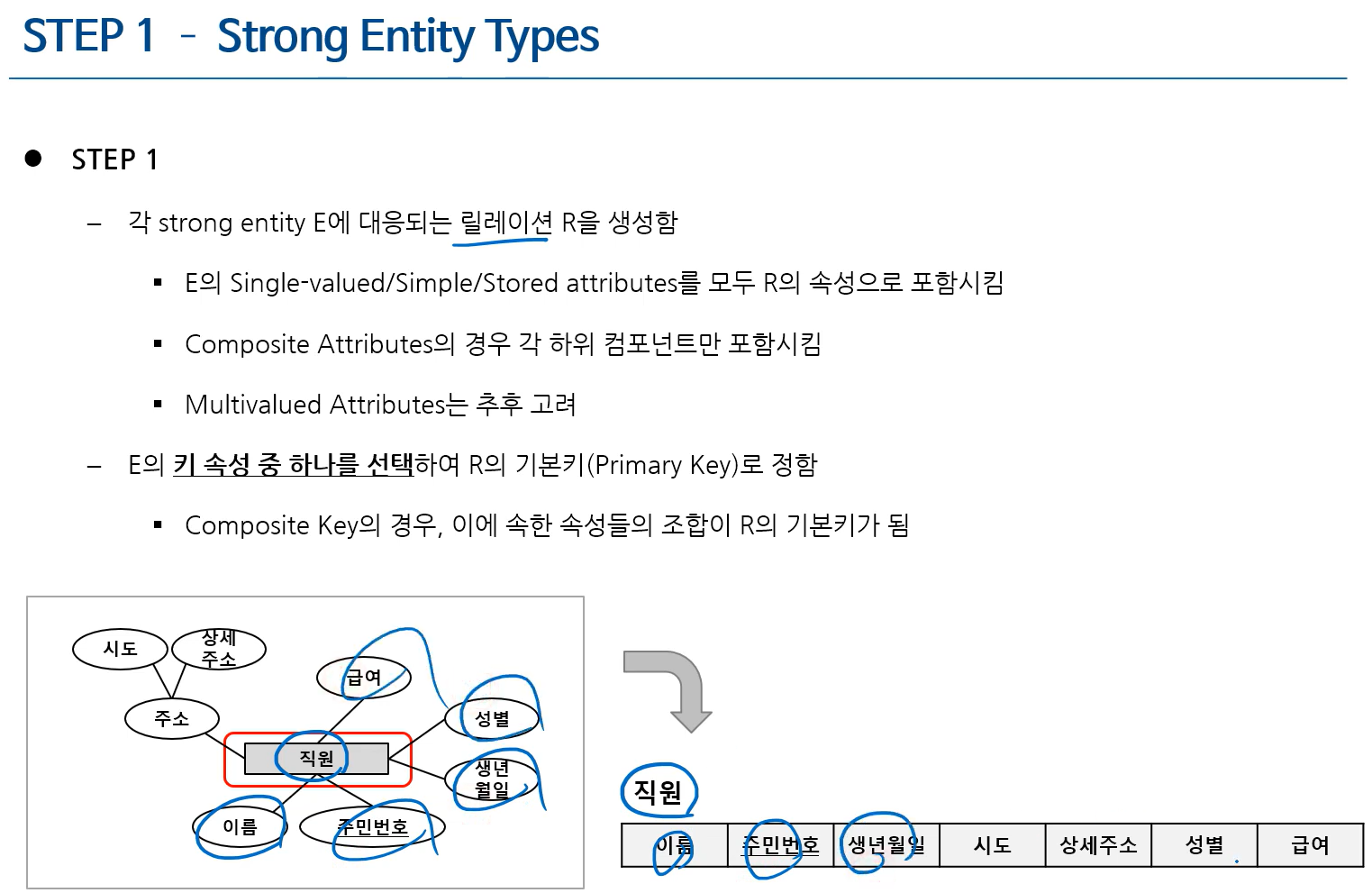
- ER diagram에서는 identifier가 두 개 이상일 수 있지만, 테이블에서는 반드시 하나여야 함
- 테이블에서는 PK가 두 속성의 집합이라도 됨 (PK : 시도+상세주소 or 주민번호 or 시도+상세주소+주민번호)
identifier와 PK의 차이?
- 테이블에서는 PK가 두 속성의 집합이라도 됨 (PK : 시도+상세주소 or 주민번호 or 시도+상세주소+주민번호)
2) Step 2: Mapping of Weak Entity Types
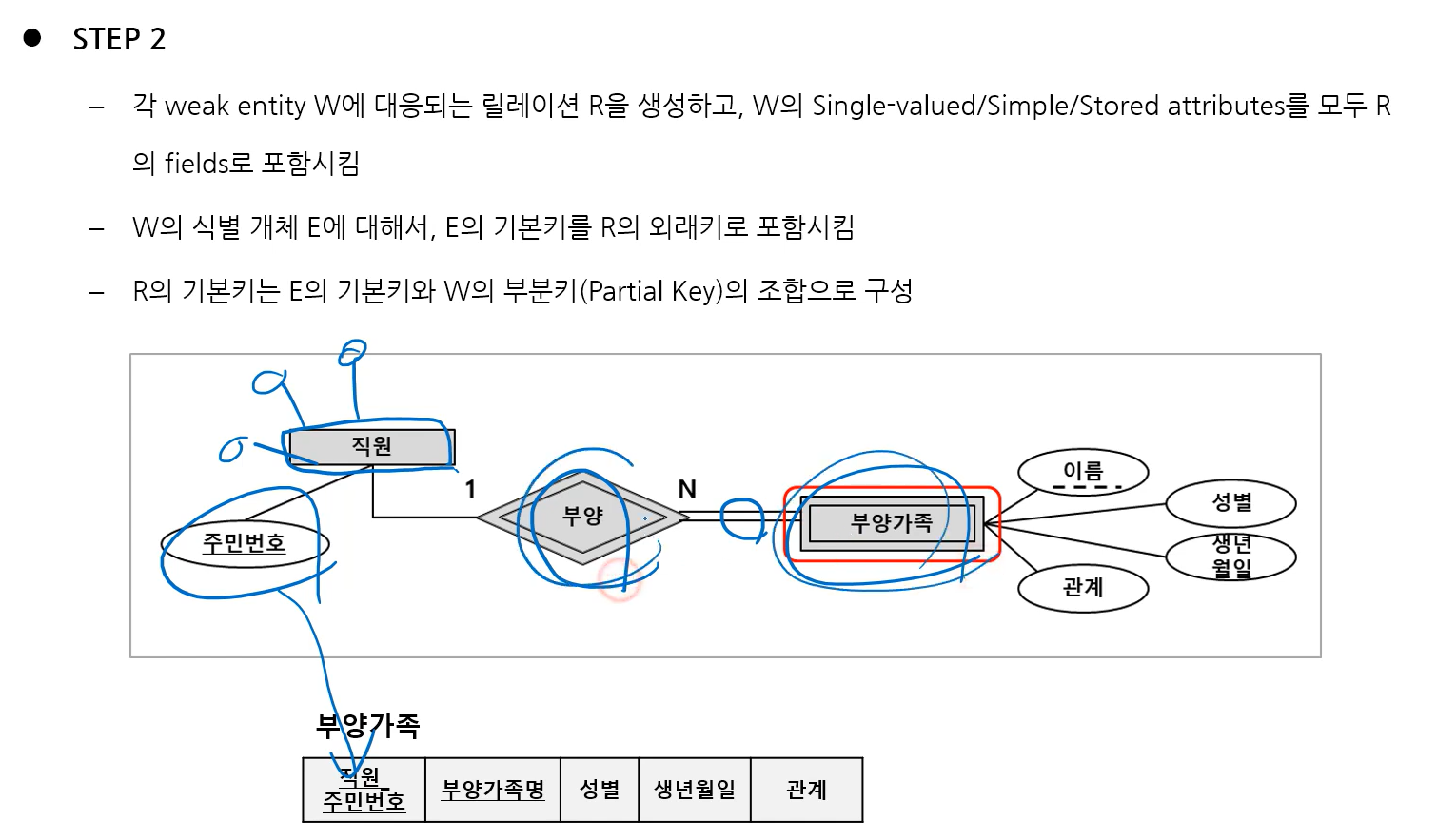
3) Step 3: Mapping of Binary 1:N Relationship Types
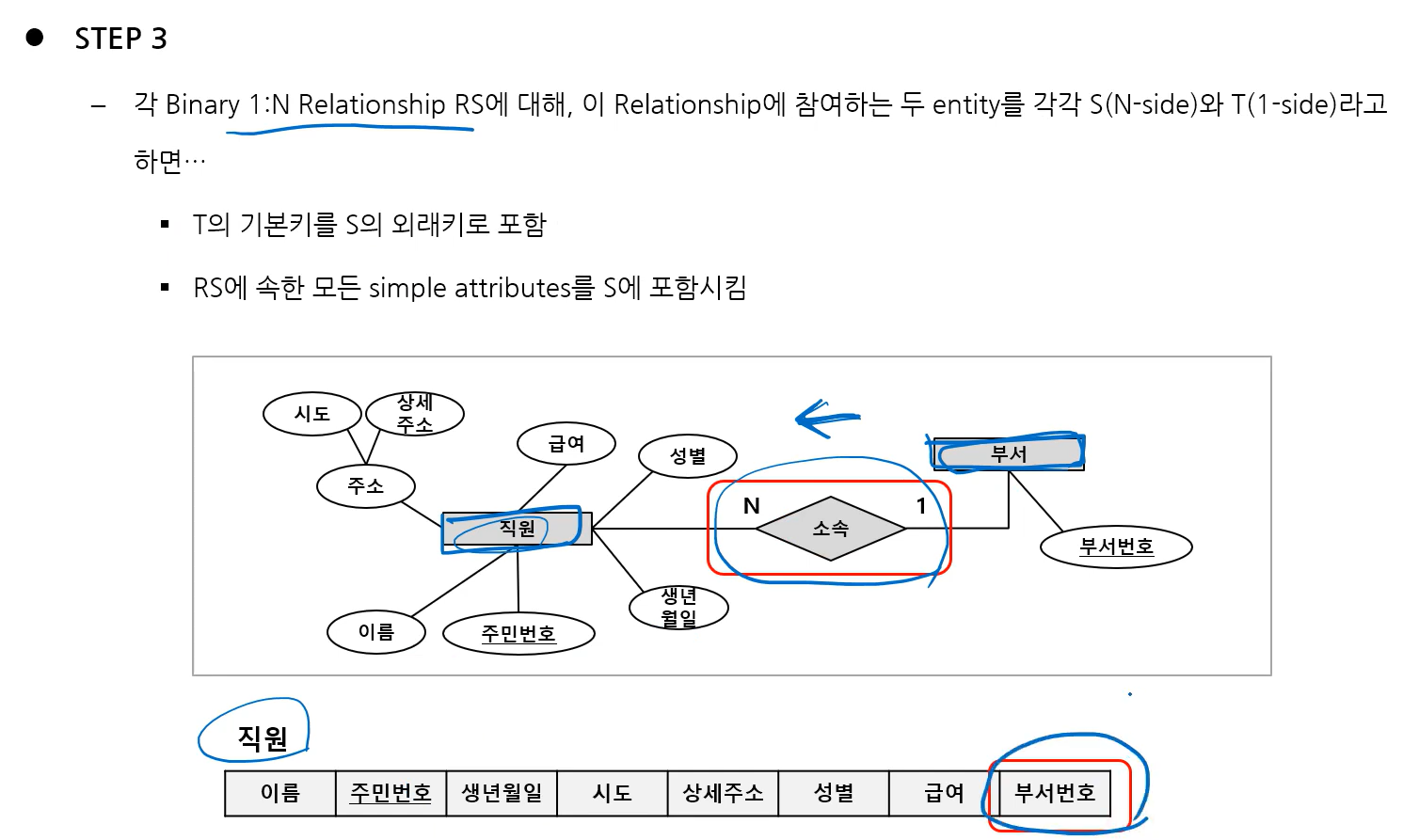
- 1:N에서 1 쪽에 있는 엔터티의 PK를 1 반대쪽의 엔터티의 속성에 추가하고 PK 밑줄은 제거함
4) Step 4: Mapping of Binary 1:1 Relationship Types

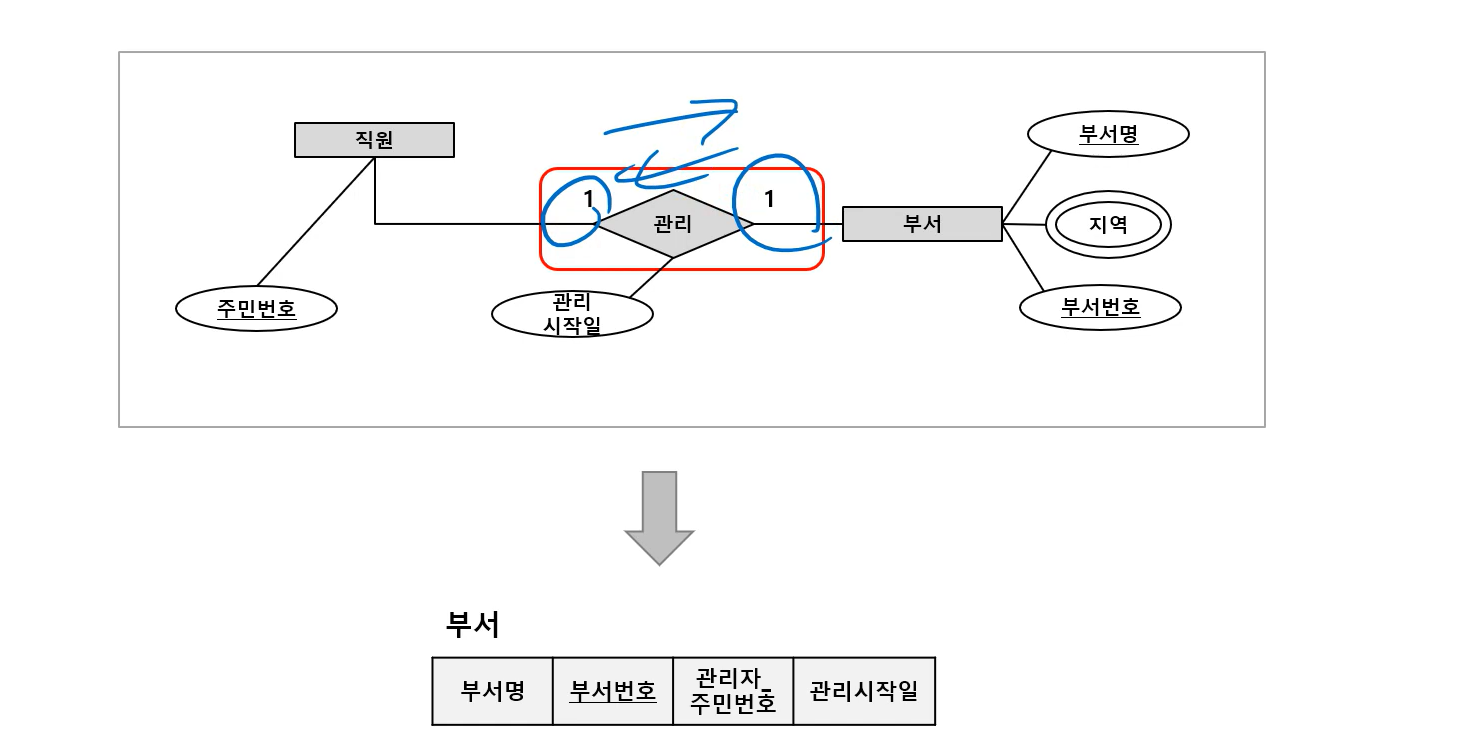
5) Step 5: Mapping of Binary M:N Relationship Types
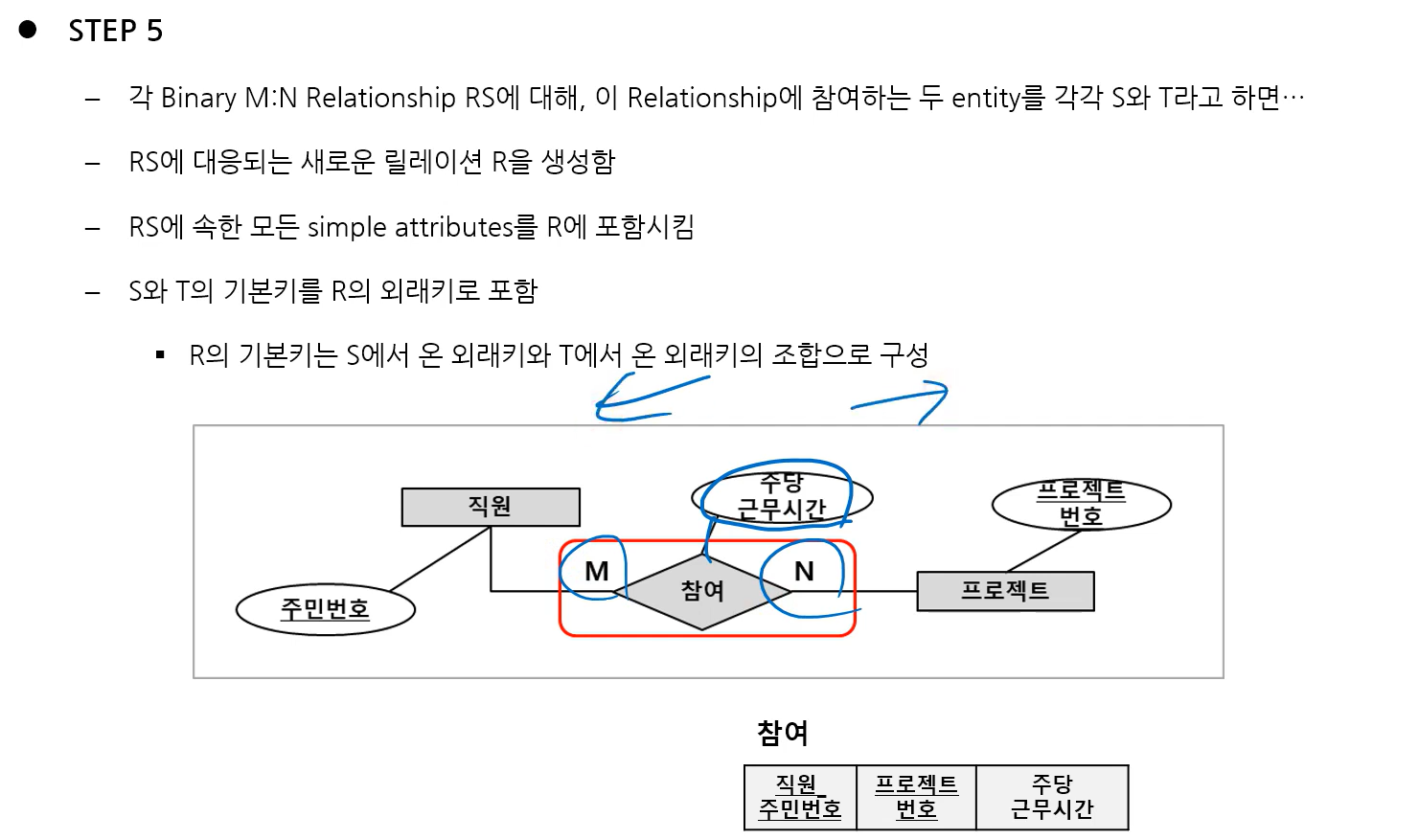
- 해당 관계를 별도의 테이블로 구성함
- 다른 엔터티의 PK 두 개를 함께 사용해 composite key가 됨
6) Step 6: Mapping of N-ary Relationship Types

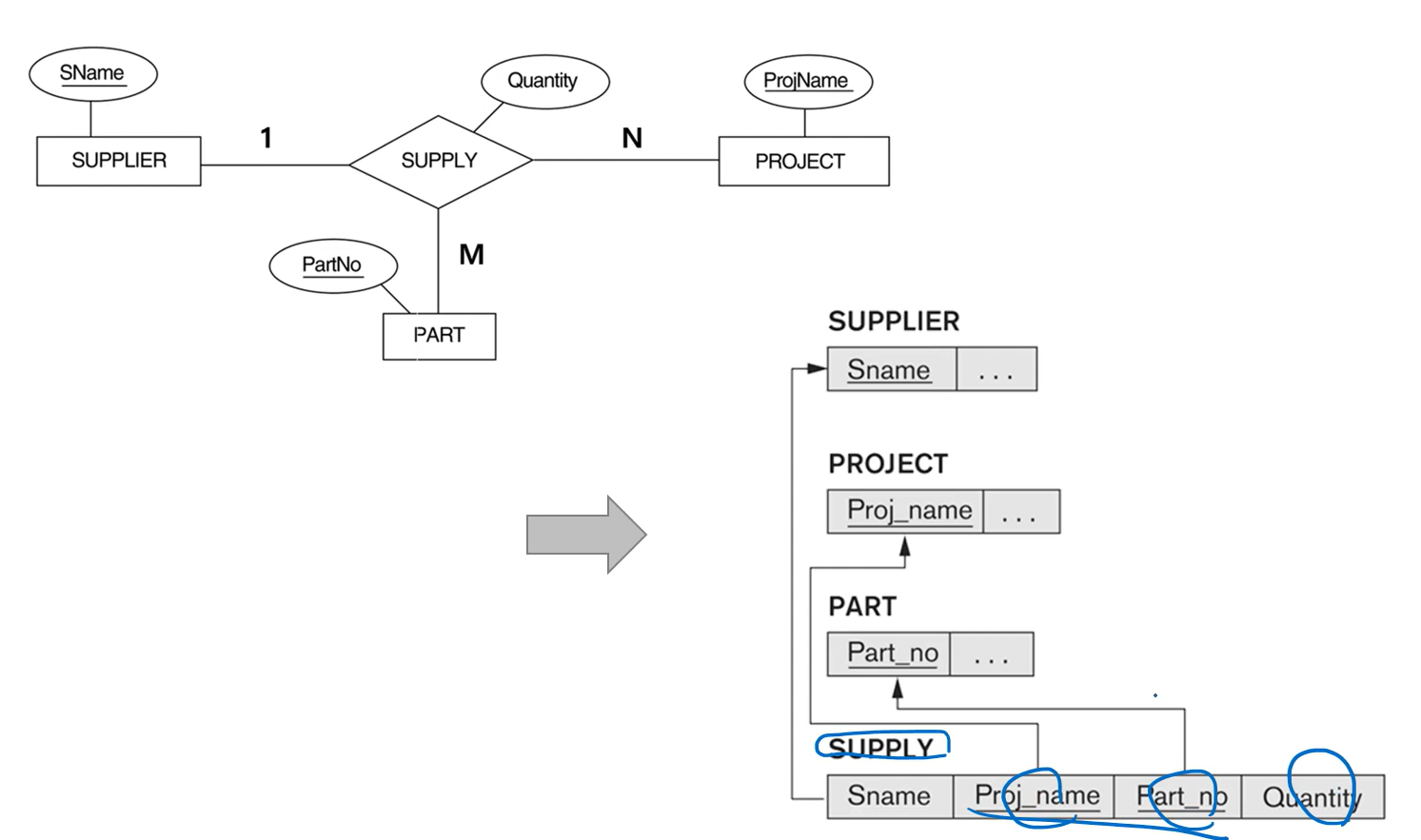
- 관계를 테이블로 뺀 후, 관계차수에서 1이 아닌 쪽의 PK는 새로운 테이블의 FK로, 1인 쪽의 PK는 일반 속성으로 넣음 (+원래 관계의 속성도 테이블에 일반 속성으로 넣음)
- 줄 그어진 속성은 FK이자, 새로운 테이블에서의 PK 조합이자, 줄그어진 각각 속성은 PK의 Composite Key임
- 흔하지는 않으나 이해하기에 복잡함
7) Step 7: : Mapping of Multivalued attributes
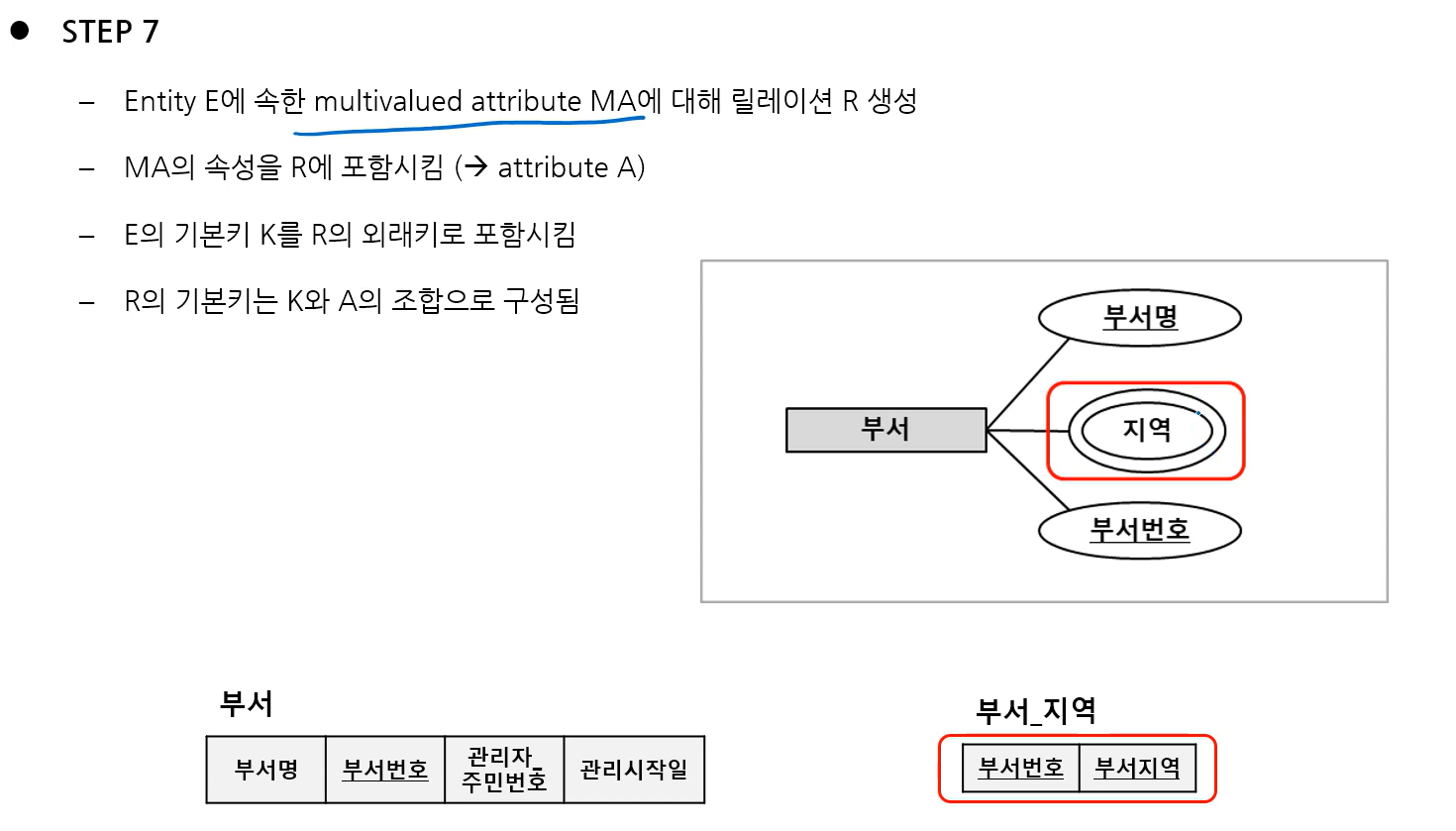
- MA 자신을 새 테이블의 속성으로 넣고, 자기가 속한 엔터티의 PK를 복사해 넣음
- 두 속성 모두에 줄을 그어 PK로 만듦
3. Generalizaiton - ERD
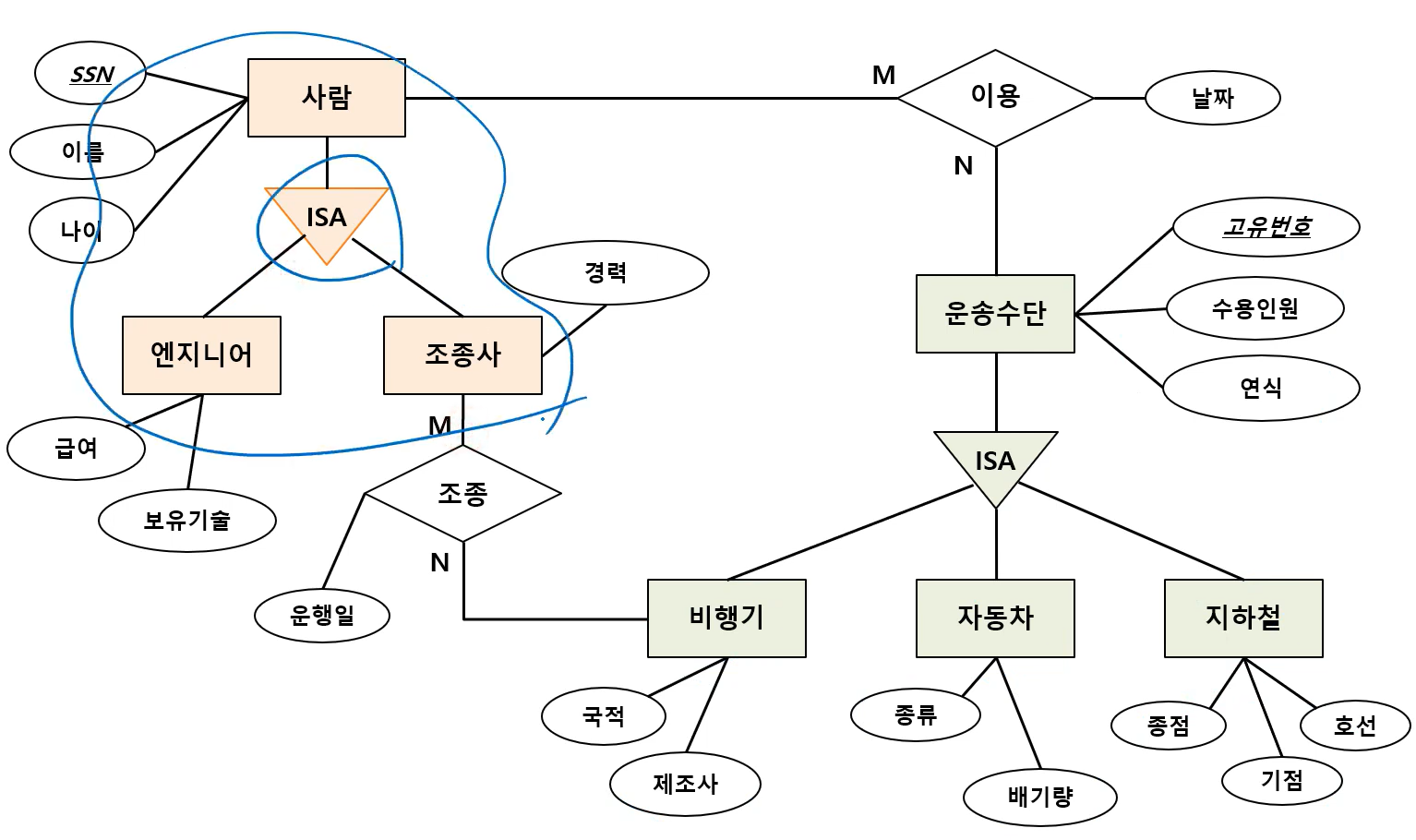
- '사람'을 step 1에 따라 테이블화, '엔지니어'랑 '조종사'도 step 1에 따라 테이블화
- 부모 엔티티의 PK를 받아 자식 엔티티의 PK로 만들기
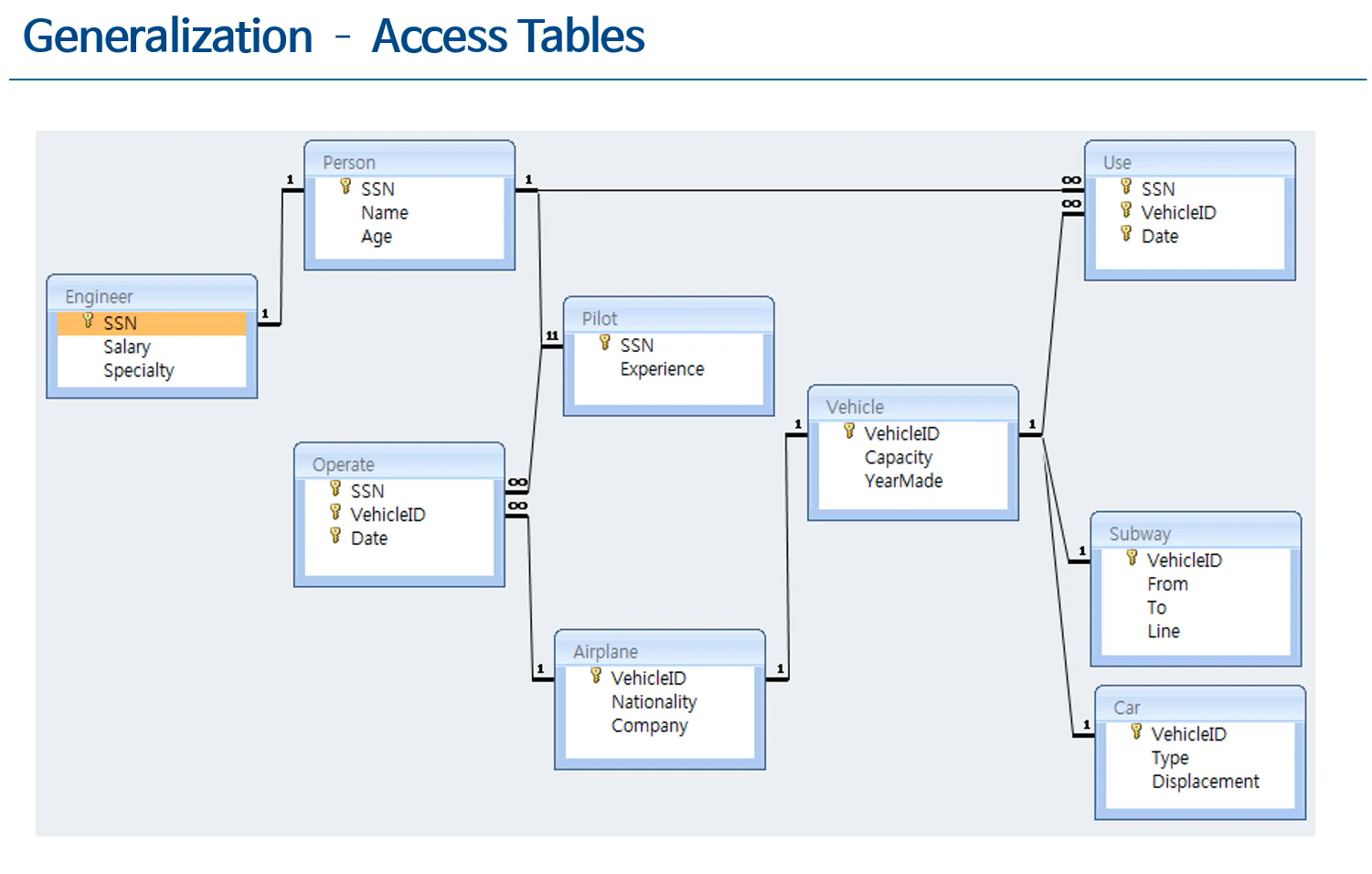
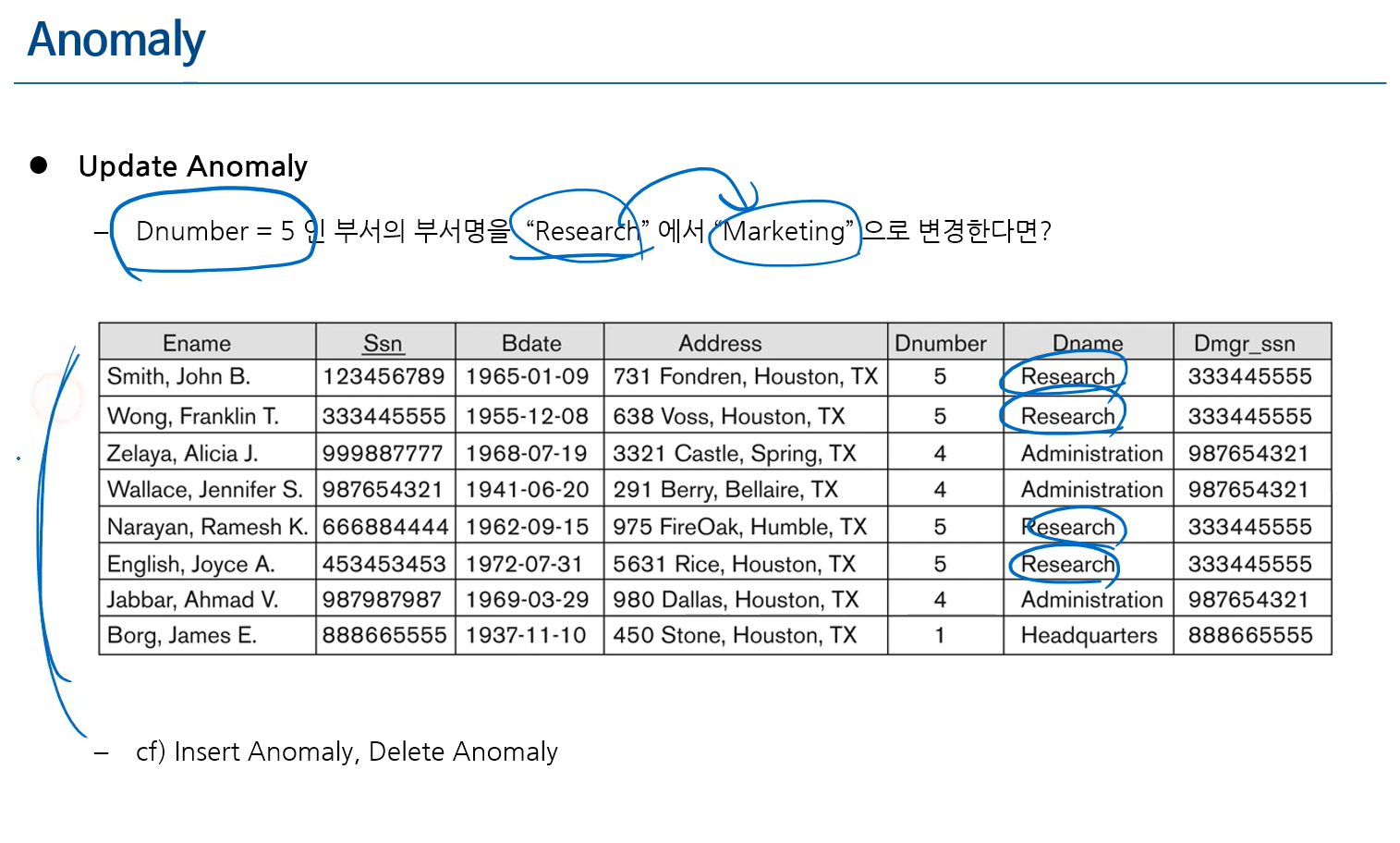
4. Redundant Information in Tuples (Normalization, 정규화)
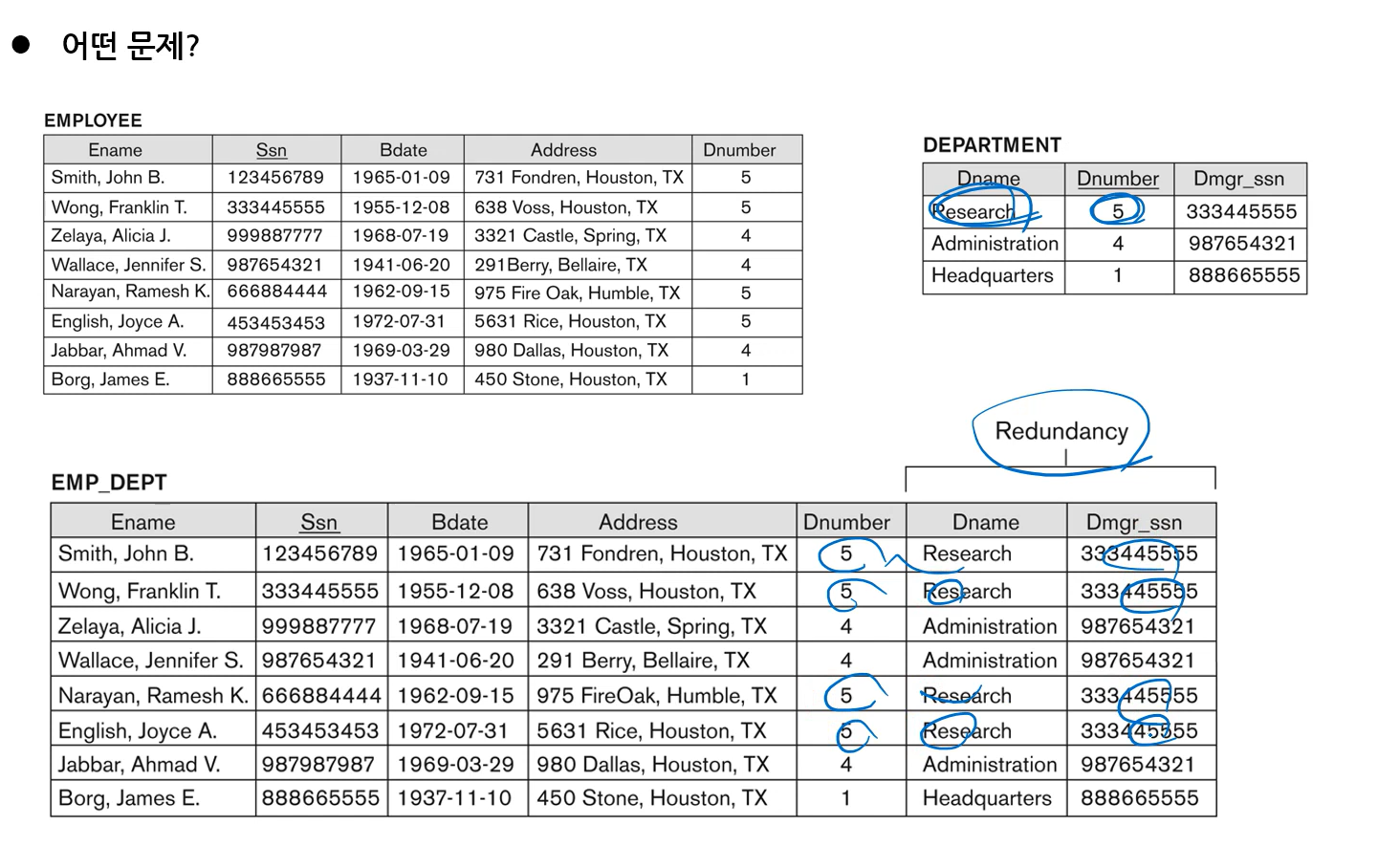
중복(Redundancy) 문제 발생 (아래 테이블) = update anomaly 발생
-
정규화 : 테이블을 깔끔하게 예쁘게 만드는 법
- Functional Dependency(함수적 종속성) : 정규화의 핵심 기법
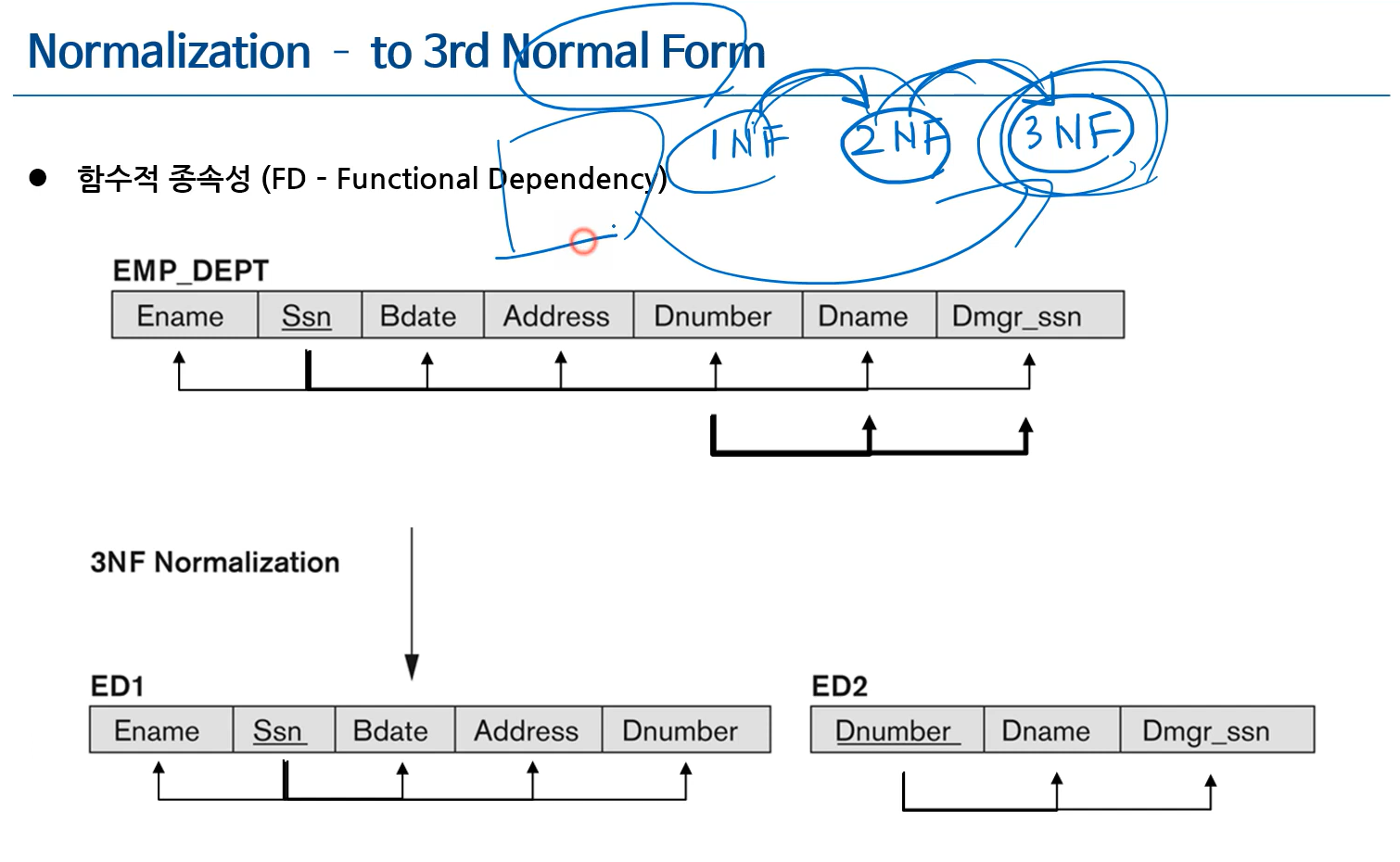
- Functional Dependency(함수적 종속성) : 정규화의 핵심 기법
-
1NF 2NF 3NF ... 그러나 3NF가 제일 중요함
-
PK가 아닌 것이 함수적 종속성 중 왕의 역할을 하는 것이 지저분한 테이블임 (PK가 다른 속성과 종속 관계를 갖고 있어야 함)
예, SSN을 알면 부서명을 알 수 있다. -
3NF Normalization
- Functional Dependency를 사용한 정규화
- PK도 아닌 게 왕의 역할을 하면 그와 그 종속 속성들은 따로 새 테이블로 빼고, 그 왕 역할 하는 속성을 그 테이블의 PK로 지정하기
- 기존의 테이블에서도 그 왕 역할하던 속성은 그대로 일반 속성(FK)으로 유지하기
※ 해 보면 좋은 것