
🐼 목 차 🐼
1. 프로젝트 개요
2. 결론
3. 데이터 로드, EDA, 전처리
4. TF-IDF를 통한 메인 메뉴 선정
5. 메뉴 데이터 EDA
6. 모델링을 위한 데이터 준비
7. 요일별 방문자 수 패턴 기반 재고 관리 전략 수립 (K means clustering)
8. 클러스터별 식재료 재고 관리 자동화 전략 수립 (DBSCAN, XGBoost)
1. 프로젝트 개요
🍙 프로젝트 목적
회사 구내식당 관리자는 식재료 재고가 남아돌아 문제를 겪고 있다.
관리자는 식수를 매번 감으로 예측하지만 이용자가 어떤 날은 적고, 어떤날은 많아(불규칙한 변동) 재고 관리 측면에서 손실을 보고 있다.
따라서, 메뉴 정보 데이터와 근무자 정보 데이터를 활용해 식수를 예측하고 식재료 재고를 효율적으로 관리하고자 한다.
- BX : 사내식당 식재료 재고를 효율적으로 관리해 손실을 최소화하고 운영 효율성을 높이자.
- CX : 식사 시간대에 음식이 부족하거나 남지 않도록 하여 고객의 불만을 줄이고 만족도를 높여보자. (적절한 식수 예측)
- DX : 식수 예측과 관련된 정보를 지속적으로 확인하고 개선하자.
- 본사 정원 수, 본사 휴가자 수, 본사 출장자 수, 본사 시간외 근무명령서 승인 건수, 중식계, 석식계, 요일, 메뉴 정보
- Trigger : 최근 식당 식재료 재고 관리 문제로 인한 손실 증가
- Accelerator : 메뉴 정보, 근무자 정보, 중식 및 석식 식수 데이터 등
- Tracker : 식수 예측 정확도와 재고 손실 변화 추이 확인 및 분석
데이터 설명
사용한 데이터
→ 모 회사 구내식당 데이터
데이터 정보
| 컬럼명 | 설명 |
|---|---|
| 일자 | 데이터가 수집된 날짜 |
| 요일 | 해당 날짜의 요일 |
| 본사정원수 | 본사에 근무하는 전체 직원 수 |
| 본사휴가자수 | 본사에 휴가 중인 직원 수 |
| 본사출장자수 | 본사에 출장 중인 직원 수 |
| 본사시간외근무명령서승인건수 | 본사에서 승인된 시간 외 근무 명령서 건수 |
| 현본사소속재택근무자수 | 본사 소속 중 재택 근무 중인 직원 수 |
| 조식메뉴 | 해당 날짜의 조식 메뉴 |
| 중식메뉴 | 해당 날짜의 중식 메뉴 |
| 석식메뉴 | 해당 날짜의 석식 메뉴 |
| 중식계 | 해당 날짜에 중식을 이용한 직원 수 |
| 석식계 | 해당 날짜에 석식을 이용한 직원 수 |
2. 결론
해당 프로젝트에서는 사내식당 식재료 관리 효율화를 위해 두 가지 클러스터링 분석과 예측 모델링을 활용하였다.
메인 메뉴의 선호도가 식당 방문자 수에 영향을 미친다는 가정 하에, TF-IDF를 사용해 메인 메뉴를 분석하였고, 이후 독립변수(중식계 및 석식계 제외 컬럼)들을 기준으로 클러스터링을 수행하였다.
클러스터링 결과를 기반으로 요일별, 월별, 식사 시간대(중식/석식) 및 클러스터별 방문자 수 변동성을 파악하였으며, 이를 통해 XGBoost를 활용한 방문자수 예측 모델을 구축하여 식재료 재고 관리 효율화 및 자동화 전략을 제안하였다.
해당 전략으로 식재료 낭비를 감소하고 고객 만족도를 높일 수 있을 것으로 기대한다.
-
요일별 식수 변동성 분석 (EDA)
- 월요일 : 중식 및 석식 방문자 수가 가장 많아 식재료를 충분히 준비할 필요가 있음
- 화요일 : 중식 방문자 수는 월요일에 비해 감소했으나 석식 방문자 수는 높으므로, 중식 식재료 재고는 감소시키며 석식 재고는 월요일과 비슷하게 유지할 필요가 있음
- 금요일 : 중식 및 석식 방문자 수가 가장 적어, 재고를 최소화할 필요가 있음
- 주 후반으로 갈수록 중식, 석식 모두 식수가 감소하는 트렌드를 보임
- 목요일 : 야근 등 원인으로 인해 석식 방문자 수가 이전에 비해 증가하는 경향이 나타나므로, 석식 식재료 재고량을 증가할 필요가 있음
-
월별 식수 변동성 분석 (EDA)
- 2-3월 : 새해와 관련된 행사나 신입 직원의 입사로 인해 중식 및 석식 방문자 수가 증가하는 경향이 나타나며 이에 따라 해당 시기 식재료 재고를 증가시킬 필요가 있음
- 4-8월: 평균 식수가 감소하는 경향이 있어, 이 기간 동안은 재고를 줄일 필요가 있음
- 9월 이후 : 다시 방문자 수가 증가하므로 재고를 늘릴 필요가 있음
-
메뉴별 식수 분석 (TF-IDF 기반으로 추출된 메뉴 데이터 EDA) :
- 인기 있는 메인 메뉴일 때는 사용자 만족을 위해 재고를 더 준비하고, 인기가 적은 메뉴에 대해서는 개선 또는 조정을 고려할 필요가 있음
- 인기 있는 메인 메뉴일 때는 사용자 만족을 위해 재고를 더 준비하고, 인기가 적은 메뉴에 대해서는 개선 또는 조정을 고려할 필요가 있음
-
클러스터 분석을 통한 재고 관리 전략 :
-
요일별 재고 관리 전략 (K means clustering)
- 실루엣 스코어와 덴드로그램을 참고한 결과, 클러스터 개수 3개가 적절해보임
- 월요일 : 전체 클러스터(0, 1, 2)에서 중식과 석식 방문자 수가 모두 높아, 중식 및 석식 재고를 모두 증가시킬 필요가 있음
- 화요일 : 클러스터 2에서 방문자 수가 높아, 클러스터 2에 해당하는 식재료 재고를 증가시킬 필요가 있음
- 수요일 : 전체 클러스터(0, 1, 2)에서 중식 방문자 수가 높으므로, 중식 재고를 증가시킬 필요가 있음
-
클러스터별 재고 관리 전략 (DBSCAN, XGBoost)
- 클러스터링 결과, 24개의 클러스터 생성됨
- 방문자 수가 많은 클러스터 : 클러스터 2, 7, 10, 11, 23은 중식과 석식 방문자 수가 상대적으로 높으므로, 식재료 재고를 늘릴 필요가 있음
- 방문자 수가 적은 클러스터 : 클러스터 1, 6, 17 등에서는 방문자 수가 적으므로, 재고를 줄이는 전략이 필요함
- 중식과 석식 방문자 수 차이가 큰 클러스터 : 클러스터 2, 7, 10, 11, 23에서는 중식과 석식 방문자 수 차이가 크므로, 이 차이를 고려한 재고 관리가 필요함
- 중식과 석식 방문자 수 차이가 작은 클러스터 : 클러스터 5, 6, 13, 14 등에서는 차이가 작으므로, 균형 잡힌 재고 관리가 필요함
-
추가적인 개선 방안
- 사내식당 방문 데이터를 추가로 수집하여 주단위 및 원단위로 새로운 예측 모델을 구축하고, 재고 관리 전략의 정확성을 더욱 향상시킬 수 있을 것으로 예상됨
- 이를 통해 사내식당 운영의 효율성을 증대시키고, 식재료 부족 및 과잉 문제를 방지할 수 있을것으로 기대함
-
3. 데이터 로드, EDA, 전처리
- 데이터 임포트
import numpy as np
import pandas as pd
df = pd.read_csv('./data/congestion.csv', encoding = "cp949")
df.head(2)일자 요일 본사정원수 본사휴가자수 본사출장자수 본사시간외근무명령서승인건수 현본사소속재택근무자수 조식메뉴 중식메뉴 석식메뉴 중식계 석식계 0 2016-02-01 월 2601 50 150 238 0.0 모닝롤/찐빵 우유/두유/주스 계란후라이 호두죽/쌀밥 (쌀:국내산) 된장찌개 쥐... 쌀밥/잡곡밥 (쌀,현미흑미:국내산) 오징어찌개 쇠불고기 (쇠고기:호주산) 계란찜 ... 쌀밥/잡곡밥 (쌀,현미흑미:국내산) 육개장 자반고등어구이 두부조림 건파래무침 ... 1039.0 331.0 1 2016-02-02 화 2601 50 173 319 0.0 모닝롤/단호박샌드 우유/두유/주스 계란후라이 팥죽/쌀밥 (쌀:국내산) 호박젓국찌... 쌀밥/잡곡밥 (쌀,현미흑미:국내산) 김치찌개 가자미튀김 모둠소세지구이 마늘쫑무... 콩나물밥양념장 (쌀,현미흑미:국내산) 어묵국 유산슬 (쇠고기:호주산) 아삭고추무... 867.0 560.0
- 데이터 타입 확인
df.info<class 'pandas.core.frame.DataFrame'> RangeIndex: 1205 entries, 0 to 1204 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 일자 1205 non-null object 1 요일 1205 non-null object 2 본사정원수 1205 non-null int64 3 본사휴가자수 1205 non-null int64 4 본사출장자수 1205 non-null int64 5 본사시간외근무명령서승인건수 1205 non-null int64 6 현본사소속재택근무자수 1205 non-null float64 7 조식메뉴 1205 non-null object 8 중식메뉴 1205 non-null object 9 석식메뉴 1205 non-null object 10 중식계 1205 non-null float64 11 석식계 1205 non-null float64 dtypes: float64(3), int64(4), object(5) memory usage: 113.1+ KB
일자, 요일, 조식메뉴, 중식메뉴, 석식메뉴가 object, 그 외는 int와 num임을 확인
쉐입은 (1250, 12)이며 결측치는 없음
- 일자와 요일 컬럼은 시간 데이터이므로, datetime 타입으로 변경
import datetime
df['일자'] = pd.to_datetime(df['일자'])
print(df['일자'].min(), df['일자'].max())해당 데이터는 2016년 2월 1일 ~ 2021년 1월 26일까지의 데이터임을 확인
- 요일별 평균 식수 확인
df_dow = pd.DataFrame(df.groupby('요일')[['중식계', '석식계']].mean())
df_dow.index = ['월', '화', '수', '목', '금']
df_dow중식계 석식계 월 653.609959 404.979253 화 823.991803 480.401639 수 905.213389 363.615063 목 1144.331950 538.933610 금 925.620833 520.129167
- 시각화를 통한 요일별 평균 식수 추이 확인
import matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'
plt.style.use(['dark_background'])
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
axes[0].bar(df_dow.index, df_dow['중식계'])
axes[0].set_title('요일별 평균 중식계')
axes[0].set_xlabel('요일')
axes[0].set_ylabel('중식계')
axes[1].bar(df_dow.index, df_dow['석식계'], color='darkgreen')
axes[1].set_title('요일별 평균 석식계')
axes[1].set_xlabel('요일')
axes[1].set_ylabel('석식계')
plt.tight_layout()
plt.show()
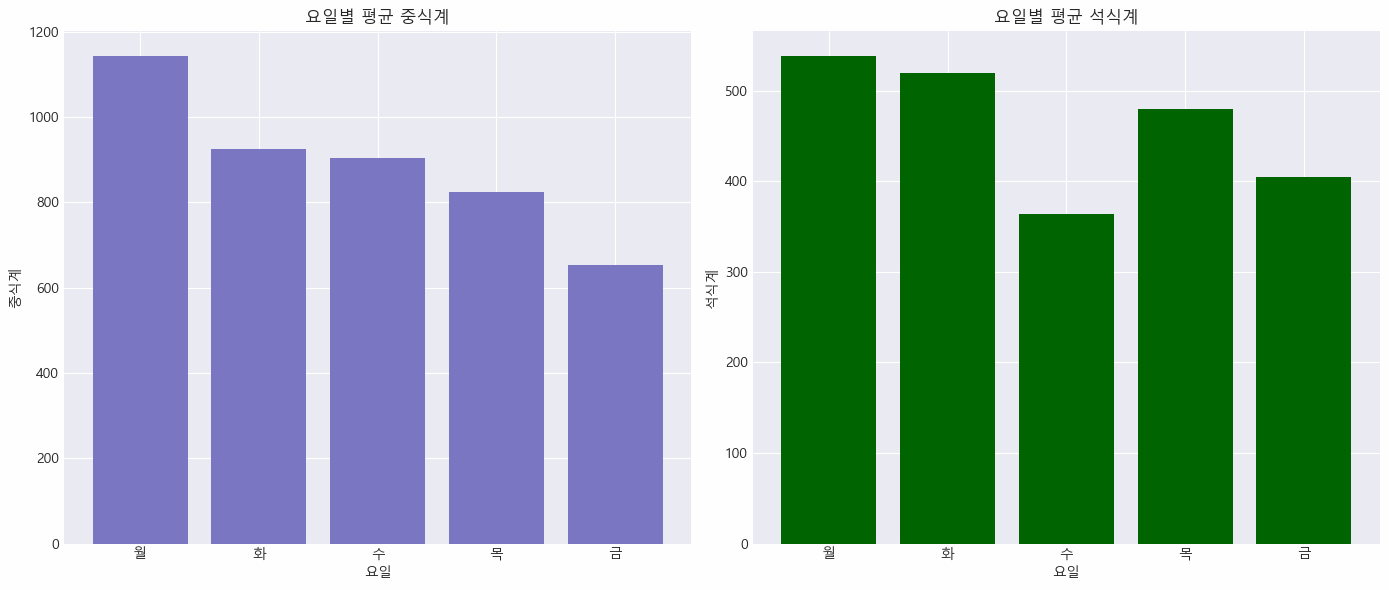
✔️ 월요일이 중식계에 대한 식수가 가장 많은 날은 월요일
→ 주 초반에 직원들이 회사에 많이 출근하고 점심을 먹는 경향이 있음을 나타냄
→ 주 후반으로 갈수록 식수는 감소하며, 금요일이 가장 낮은 중식계 시수를 보임
✔️ 석식계 또한 월요일이 가장 많음을 확인
→ 월요일에 늦게까지 일하는 직원들이 많음을 의미
✔️ 수요일에 식수가 감소함
→ 주중 중반의 수요일이라, 많은 직원들이 피로를 느낄 수 있음
→ 또는 정기적인 외부 미팅이나 회의가 잡혀있는 경우, 외부에서의 식사를 고려할 수 있음
✔️ 목요일의 석식계 식수 증가
→ 주 후반에 접어들며, 업무 마감을 준비하는 시기로 원인을 유추해볼 수 있음
✔️ 금요일의 석식계 식수 감소
→ 많은 직원들이 주말을 앞두고 조기 퇴근하거나, 사회적 약속이 많은 시기이므로 외부에서 식사하는 경우가 있는 듯 함
- 월별 평균 식수 확인
df['month'] = df["일자"].dt.month # month 컬럼 추가
df_month = df.groupby('month')[['중식계', '석식계']].mean()
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
axes[0].bar(df_month.index, df_month['중식계'])
axes[0].set_xticks(df_month.index)
axes[0].set_title('월별 평균 중식계')
axes[0].set_xlabel('월')
axes[0].set_ylabel('중식계')
axes[1].bar(df_month.index, df_month['석식계'], color='darkgreen')
axes[1].set_xticks(df_month.index)
axes[1].set_title('월별 평균 석식계')
axes[1].set_xlabel('월')
axes[1].set_ylabel('석식계')
plt.tight_layout()
plt.show()
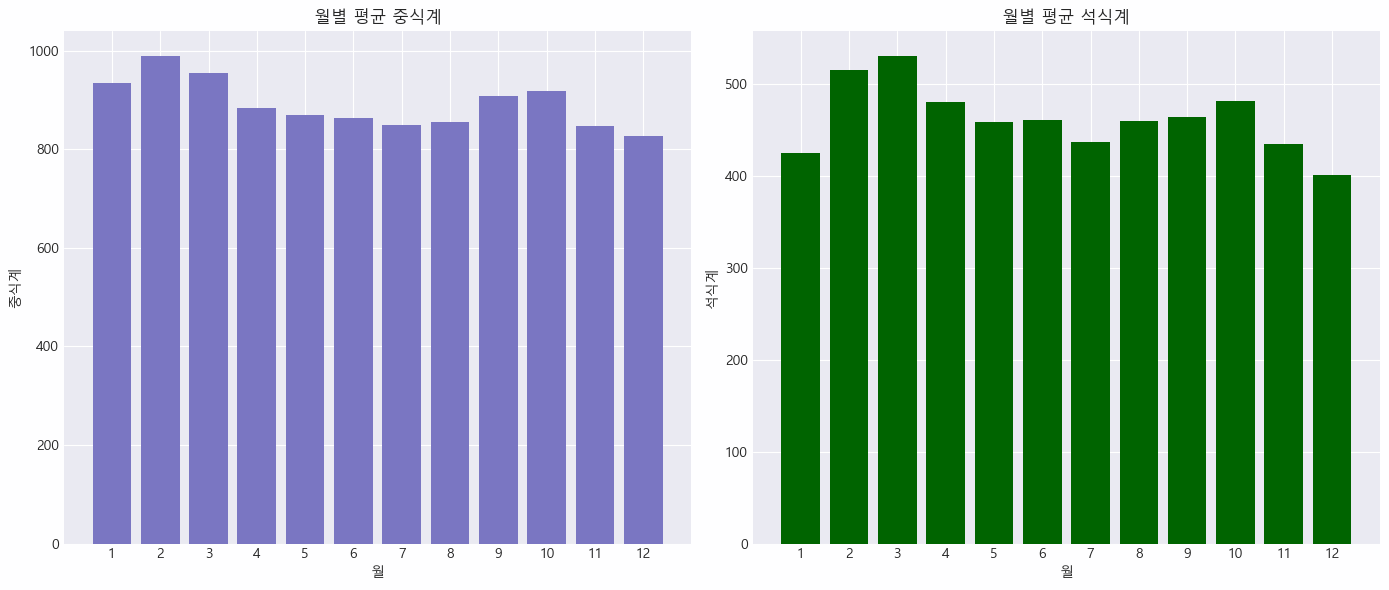
✔️ 2월과 3월의 높은 식수
→ 2월과 3월에는 중식계와 석식계 모두 평균 식수가 높은 경향을 보임
→ 2월과 3월에 새해와 관련된 행사나 신입 직원의 입사로 인해 식수량이 증가할 가능성이 있음
✔️ 4월부터 8월까지의 낮은 식수
→ 봄과 여름철에는 평균 식수가 다소 감소하는 경향을 보임
→ 휴가철이나 외부 활동이 증가하여 직장인들의 식사가 줄어드는 경향이 반영된 듯 함
✔️ 9월 이후의 식수 증가
→ 가을부터 다시 식수가 증가하는 경향이 있음
→ 휴가철이 끝나고 직원들이 다시 일상 업무에 집중하는 시기와 맞물릴 수 있다고 보임
✔️ 간단한 빈도수 별 분석 결과를 바탕으로, 월별 식수 변동 패턴을 고려하여 재고를 조절함으로써 재고 관리 손실을 최소화할 수 있음
→ 예를 들어, 2월과 3월에는 재고를 더 많이 준비하고, 4월부터 8월까지는 재고를 줄이는 전략을 채택해볼 수 있음
- 기본적 데이터 전처리
# 메뉴 데이터가 공백(' ')으로 분리되어 있음을 확인하였고,
# 공백으로 나눠져는 있으나, 2칸과 1칸으로 비균일하게 나뉘어져 있음
print(df["조식메뉴"][0].replace(' ', '*'))
# 메뉴를 분리하기 전 명확한 기준 지정을 위해 공백2를 공백1로 변경
df['조식메뉴']= df['조식메뉴'].str.replace(' ', ' ')
df['중식메뉴']= df['중식메뉴'].str.replace(' ', ' ')
df['석식메뉴']= df['석식메뉴'].str.replace(' ', ' ')
print(df["조식메뉴"][0].replace(' ', '*'))
# 공백을 기준으로 split
df['조식메뉴'] = df['조식메뉴'].str.split(' ')
df['중식메뉴'] = df['중식메뉴'].str.split(' ')
df['석식메뉴'] = df['석식메뉴'].str.split(' ')'모닝롤/찐빵**우유/두유/주스*계란후라이**호두죽/쌀밥*(쌀:국내산)*된장찌개**쥐어채무침**포기김치*(배추,고추가루:국내산)*' '모닝롤/찐빵*우유/두유/주스*계란후라이*호두죽/쌀밥*(쌀:국내산)*된장찌개*쥐어채무침*포기김치*(배추,고추가루:국내산)*'
4. TF-IDF를 통한 메인 메뉴 탐색
- 공백 기준으로 나눈 메뉴를 봤을 때, 방문 혼잡도에 가장 영향을 많이 미칠 것 같은 요소는 메인 메뉴라고 판단됨
- TF-IDF를 활용해보자
- 문서 내 단어의 빈도와 전체 문서에서의 희귀성을 반영한 가중치를 계산한 것
- 추가로 메인 메뉴를 선정하기에 있어서 불필요한 정보인 원산지 정보도 제거해보자
import re
# 텍스트 데이터 벡터화 도구이긴 하나, 빈도수에 기반한 중요도도 활용해볼 수 있음
from sklearn.feature_extraction.text import TfidfVectorizer
# 리스트를 문자열로 변환하여 저장
df['조식메뉴'] = df['조식메뉴'].apply(lambda x: ' '.join(x))
df['중식메뉴'] = df['중식메뉴'].apply(lambda x: ' '.join(x))
df['석식메뉴'] = df['석식메뉴'].apply(lambda x: ' '.join(x))
# 원산지 정보 제거 함수 정의
def remove_parentheses(text):
# 문자열에서 괄호 안에 있는 텍스트를 제거
return re.sub(r'\([^)]*\)', '', text)
# 원산지 정보 제거
df['조식메뉴_정제'] = df['조식메뉴'].apply(remove_parentheses)
df['중식메뉴_정제'] = df['중식메뉴'].apply(remove_parentheses)
df['석식메뉴_정제'] = df['석식메뉴'].apply(remove_parentheses)- TF-IDF를 통한 가중치 계산 후 메인 메뉴 탐색
vectorizer = TfidfVectorizer()
# 조식, 중식, 석식 메뉴별 TF-IDF 스코어 변환
X = vectorizer.fit_transform(df['중식메뉴_정제'])
# TF-IDF 스코어를 데이터 프레임으로 변환
tfidf_df = pd.DataFrame(
X.toarray(),
columns=vectorizer.get_feature_names_out()
)
tfidf_df.head()d오리엔탈d la갈비구이 가래떡구이 가래떡돼지갈비찜 가래떡츄러스 가자미무조림 가자미양념찜 가자미엿장구이 가자미엿장조림 가자미유린기 ... 훈제오리구이 훈제오리냉채 훈제오리단호박볶음 훈제오리마늘볶음 훈제오리볶음 흑미밥 흑임자d 흑임자드레싱 흑임자연근샐러드 히레카츠 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 3 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 4 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 5 rows × 1612 columns
- TF-IDF를 통해 추출된 메인 메뉴 확인
# 각 메뉴별로 TF-IDF 점수가 가장 높은 1개의 단어의 인덱스 추출
top_n_idx = tfidf_df.iloc[0].argmax()
# 해당 인덱스로 메뉴 인덱싱 확인
tfidf_df.columns[top_n_idx]
# 프린트 결과 : '오징어찌개'
# TF-IDF를 통한 가중치 계산 함수 정의
def extract_main_dishes(menu_series):
vectorizer = TfidfVectorizer()
# 조식, 중식, 석식 메뉴별 TF-IDF 점수 변환
X = vectorizer.fit_transform(menu_series)
# TF-IDF 점수를 데이터프레임으로 변환
tfidf_df = pd.DataFrame(
X.toarray(),
columns=vectorizer.get_feature_names_out()
)
# 각 메뉴별로 TF-IDF 점수가 가장 높은 단어 추출
def top_tfidf_word(row):
top_idx = row.argmax()
return tfidf_df.columns[top_idx]
# tfidf_df에 대한 lambda 식 적용
main_dishes = tfidf_df.apply(lambda row: top_tfidf_word(row), axis=1)
return main_dishes
df['조식메뉴_Main'] = extract_main_dishes(df['조식메뉴_정제'])
df['중식메뉴_Main'] = extract_main_dishes(df['중식메뉴_정제'])
df['석식메뉴_Main'] = extract_main_dishes(df['석식메뉴_정제'])
df[['조식메뉴_Main', '중식메뉴_Main', '석식메뉴_Main']]조식메뉴_Main 중식메뉴_Main 석식메뉴_Main 0 쥐어채무침 오징어찌개 건파래무침 1 단호박샌드 김치찌개 콩나물밥 2 느타리호박볶음 견과류조림 새송이버섯볶음 3 근대국 부추전 미니김밥 4 방풍나물 돈육씨앗강정 감자소세지볶음 ... ... ... ... 1200 마늘종숙회 견과류마카로니범벅 맛살튀김 1201 생크림단팥빵 버섯숙회 비엔나채소볶음 1202 바지락살국 계란파국 수제맛쵸킹탕수육 1203 분홍소세지구이 양념김 생강채 1204 애호박새우젓볶음 교촌간장치킨 수제고기육전
5. 메뉴 데이터 EDA
- 메인 메뉴 가지수 파악
display(df['조식메뉴_Main'].value_counts().head(10))
print()
display(df['중식메뉴_Main'].value_counts().head(10))
print()
display(df['석식메뉴_Main'].value_counts().head(10))김잔파무침 9 도라지나물 9 북어국 9 연두부탕 8 문어꽈리초조림 8 쑥갓두부무침 8 두부쑥갓무침 8 느타리볶음 8 조랭이떡국 7 꽈리고추찜 7 Name: 조식메뉴_Main, dtype: int64 견과류조림 6 유자청돈육볶음 5 두부새싹구이 4 냉이된장찌개 4 사과고구마그라탕 4 참나물땅콩무침 4 치즈함박스테이크 4 해파리겨자채 4 차돌된장찌개 4 청경채생채 4 Name: 중식메뉴_Main, dtype: int64 가래떡오븐구이 28 자기계발의날 7 자기개발의날 6 애호박나물 5 군만두 5 닭살겨자냉채 5 모듬튀김 4 또띠아견과칩 4 상추파무침 4 군고구마 4 Name: 석식메뉴_Main, dtype: int64
- 메인 메뉴별 중식계, 석식계 식수 인원 확인
# 식수가 큰 메뉴들
df_lunch = pd.DataFrame(df.groupby('중식메뉴_Main')['중식계'].mean())
df_lunch10 = df_lunch.sort_values(by = ['중식계'], ascending = False).head(10)
df_dinner = pd.DataFrame(df.groupby('석식메뉴_Main')['석식계'].mean())
df_dinner10 = df_dinner.sort_values(by = ['석식계'], ascending = True).head(10)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
df_lunch10.plot(kind="barh", ax=axes[0])
df_dinner10.plot(kind = "barh", ax=axes[1], color = "darkgreen")
axes[0].set_title('메인메뉴별 중식계 식수 인원')
axes[0].set_xlabel('인원')
axes[0].set_ylabel('중식 메인 메뉴')
axes[1].set_title('메인메뉴별 석식계 식수 인원')
axes[1].set_xlabel('인원')
axes[1].set_ylabel('석식 메인 메뉴')
plt.tight_layout()
plt.show()
# 식수가 작은 메뉴들
df_lunch_b10 = df_lunch.sort_values(by = ['중식계'], ascending = False).head(10)
df_dinner_b10 = df_dinner.sort_values(by = ['석식계'], ascending = True).head(10)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
df_lunch10.plot(kind="barh", ax=axes[0])
df_dinner10.plot(kind = "barh", ax=axes[1], color = "darkgreen")
axes[0].set_title('메인메뉴별 중식계 식수 인원')
axes[0].set_xlabel('인원')
axes[0].set_ylabel('중식 메인 메뉴')
axes[1].set_title('메인메뉴별 석식계 식수 인원')
axes[1].set_xlabel('인원')
axes[1].set_ylabel('석식 메인 메뉴')
plt.tight_layout()
plt.show()
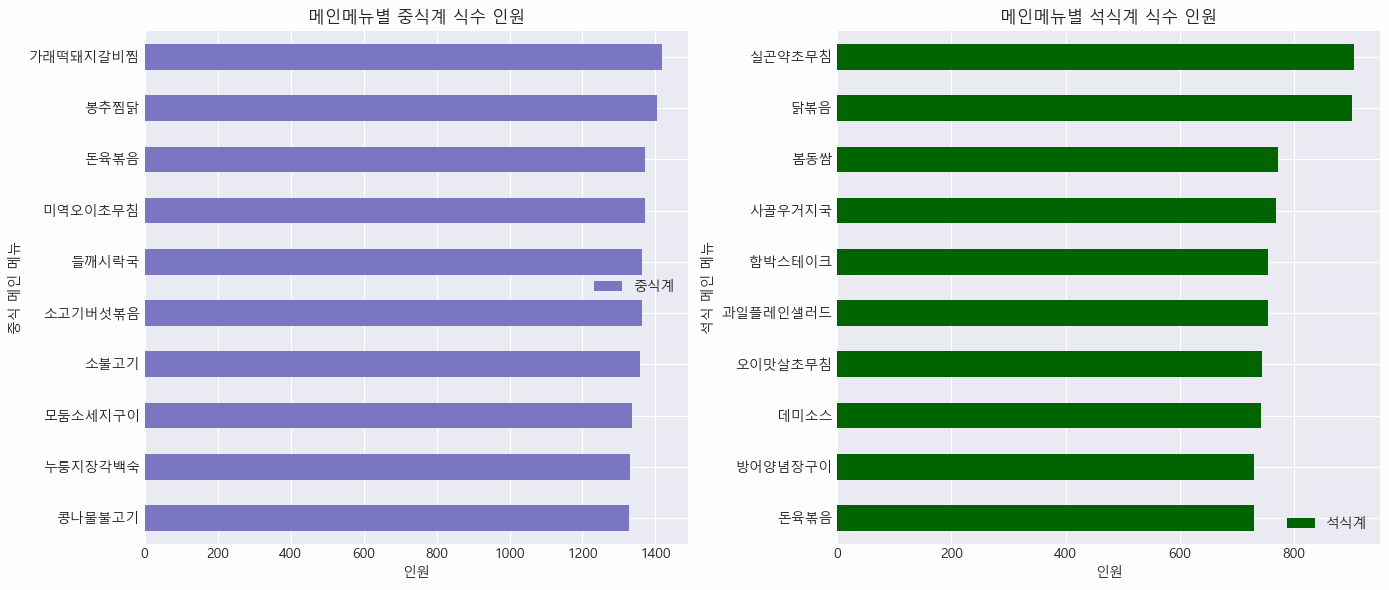
✔️ 중식 메인 메뉴를 보면, 가래떡 돼지갈비찜부터 맛있어 보이는 메뉴들이 중식계 식수가 높음
✔️ 중식계 평균 식수 만큼은 아니지만, 석식 메인 메뉴 중에서는 닭볶음, 실곤약초무침이 식수가 높음
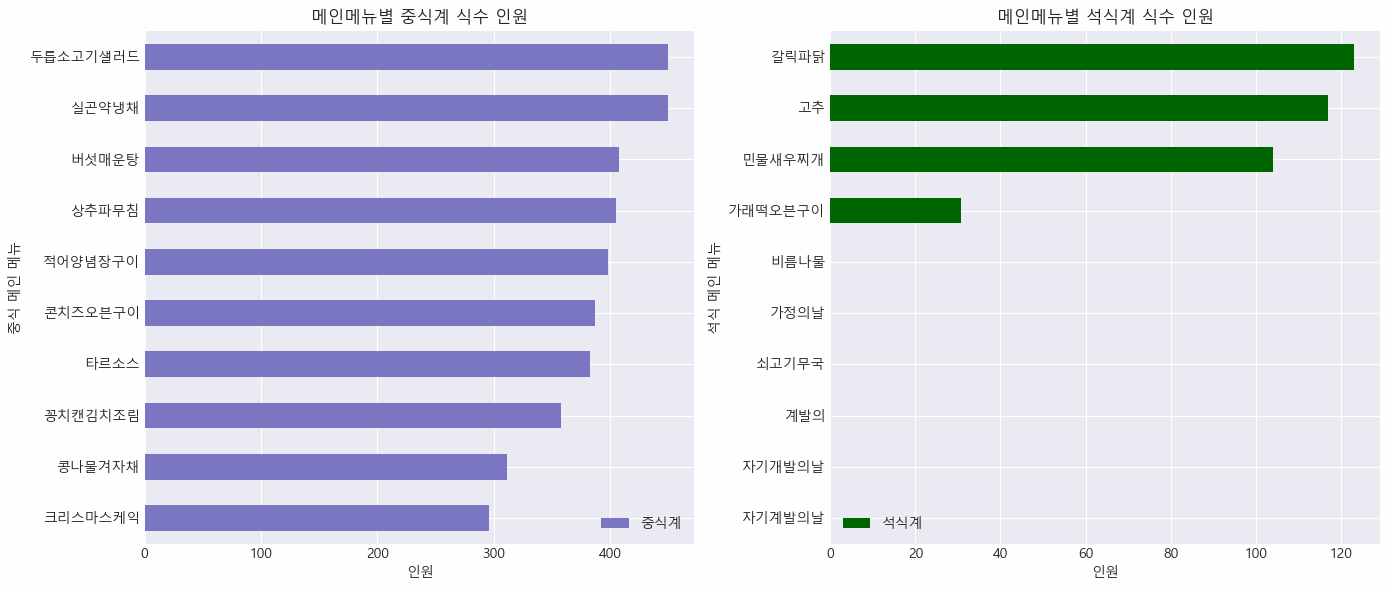
✔️ 중식 메인 메뉴 중 크리스마스 케익이 가장 인기가 없음을 확인
✔️ 석식 메인 메뉴 중 인기 없는 것들에는 가정의 날, 자기 개발, 계발의 날 같이 음식이 아닌 것들도 있음
✔️ 석식 메인 메뉴 중 식수가 0인 데이터도 있음
✔️ 인기가 적은 메인 메뉴들에 대한 보완책들을 고려해보거나, 인기가 많은 메인 메뉴일 때는, 사용자 만족을 위해 재고를 좀 더 준비해볼 수 있음
# 석식계가 0인 행을 삭제하기
df = df[df['석식계'] != 0]6. 모델링을 위한 데이터 준비
- 수치형 데이터 스케일링 수행
- 분석에 적용할 K means clustering은 거리 기반 알고리즘이므로, 모든 피처가 동일한 스케일을 갖도록 스케일링 수행
- 범주형 데이터 인코딩 (요일, 메인메뉴 등)
# 불필요한 컬럼 삭제
# 일자 : 클러스터링에 직접적으로 사용되지 않음, 이미 month 추출함
# 조식메뉴 외 컬럼 : 이미 메인 메뉴 추출함
df.drop(columns = ['일자', '조식메뉴', '중식메뉴', '석식메뉴',
'조식메뉴_정제', '중식메뉴_정제', '석식메뉴_정제'],
inplace = True)
print(df.columns)
print(df.info())Index(['요일', '본사정원수', '본사휴가자수', '본사출장자수', '본사시간외근무명령서승인건수', '현본사소속재택근무자수', '중식계', '석식계', 'month', '조식메뉴_Main', '중식메뉴_Main', '석식메뉴_Main'], dtype='object') <class 'pandas.core.frame.DataFrame'> RangeIndex: 1205 entries, 0 to 1204 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 요일 1205 non-null object 1 본사정원수 1205 non-null int64 2 본사휴가자수 1205 non-null int64 3 본사출장자수 1205 non-null int64 4 본사시간외근무명령서승인건수 1205 non-null int64 5 현본사소속재택근무자수 1205 non-null float64 6 중식계 1205 non-null float64 7 석식계 1205 non-null float64 8 month 1205 non-null int32 9 조식메뉴_Main 1205 non-null object 10 중식메뉴_Main 1205 non-null object 11 석식메뉴_Main 1205 non-null object dtypes: float64(3), int32(1), int64(4), object(4) memory usage: 108.4+ KB
- 수치형 변수, 범주형 변수 나누기
numeric_list = []
categorical_list = []
for i in df.columns :
if df[i].dtypes == 'O' :
categorical_list.append(i)
else :
numeric_list.append(i)
print("categoical_list :", categorical_list)
print("numeric_list :", numeric_list)categoical_list : ['요일', '조식메뉴_Main', '중식메뉴_Main', '석식메뉴_Main'] numeric_list : ['본사정원수', '본사휴가자수', '본사출장자수', '본사시간외근무명령서승인건수', '현본사소속재택근무자수', '중식계', '석식계', 'month']
- 수치형 데이터 분포 확인
df[numeric_list].hist(bins=30, figsize=(15, 10))
plt.suptitle('Numeric Feature Distribution')
plt.show()
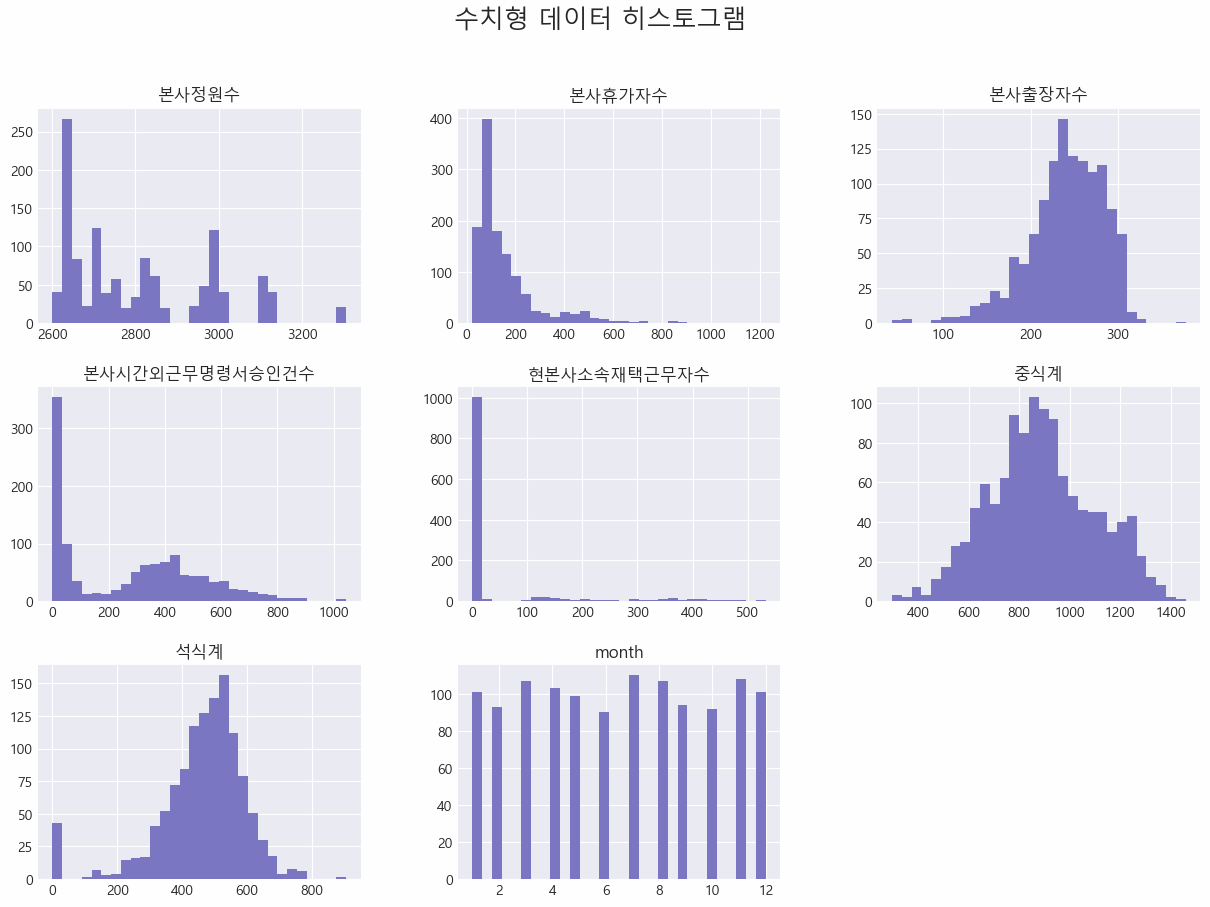
| 항목 | 분포 형태 | 설명 |
|---|---|---|
| 본사정원수 | 다중 피크를 가진 비정규 분포 | 특정 구간에서 집중되는 경향이 있으며, 전체 범위가 비교적 넓음 |
| 본사휴가자수 | 왼쪽으로 치우친 비대칭 분포 | 대부분의 값이 0에서 200 사이에 집중되어 있으며, 일부 높은 값들이 존재함 |
| 본사출장자수 | 정규분포에 가까움 | 값이 평균을 중심으로 어느 정도 고르게 분포되어 있음 |
| 본사시간외근무명령서승인건수 | 왼쪽으로 치우친 비대칭 분포 | 대부분의 값이 0에서 400 사이에 집중되어 있으며, 일부 높은 값들이 존재 |
| 현본사소속재택근무자수 | 매우 왼쪽으로 치우친 비대칭 분포 | 대부분의 값이 0에 매우 가깝게 집중되어 있음 |
| 중식계 | 정규분포에 가까움 | 값이 평균을 중심으로 고르게 분포되어 있음 |
| 석식계 | 정규분포에 가까움 | 값이 평균을 중심으로 고르게 분포되어 있음 |
| month | 균등 분포 | 각 월이 조금씩 차이가 있으나, 균등하게 분포되어 있음 |
- 수치형 데이터에 스케일링 적용
MinMaxScaler() 사용 -> 로그 변환이랑 정규화도 좋아보이는데?
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df_scaled = df.copy()
df_scaled[numeric_list] = scaler.fit_transform(df[numeric_list])- 수치형 데이터 상관관계 분석
import seaborn as sns
plt.rcParams['axes.unicode_minus'] = False
# 상관관계 히트맵 그리기
plt.figure(figsize=(12, 8))
correlation_matrix = df_scaled.corr() # 데이터프레임 df_scaled의 상관행렬 계산
# 히트맵 그리기
sns.heatmap(
correlation_matrix,
annot=True,
cmap='coolwarm',
linewidths=0.5
)
plt.title('Correlation Matrix')
plt.show()
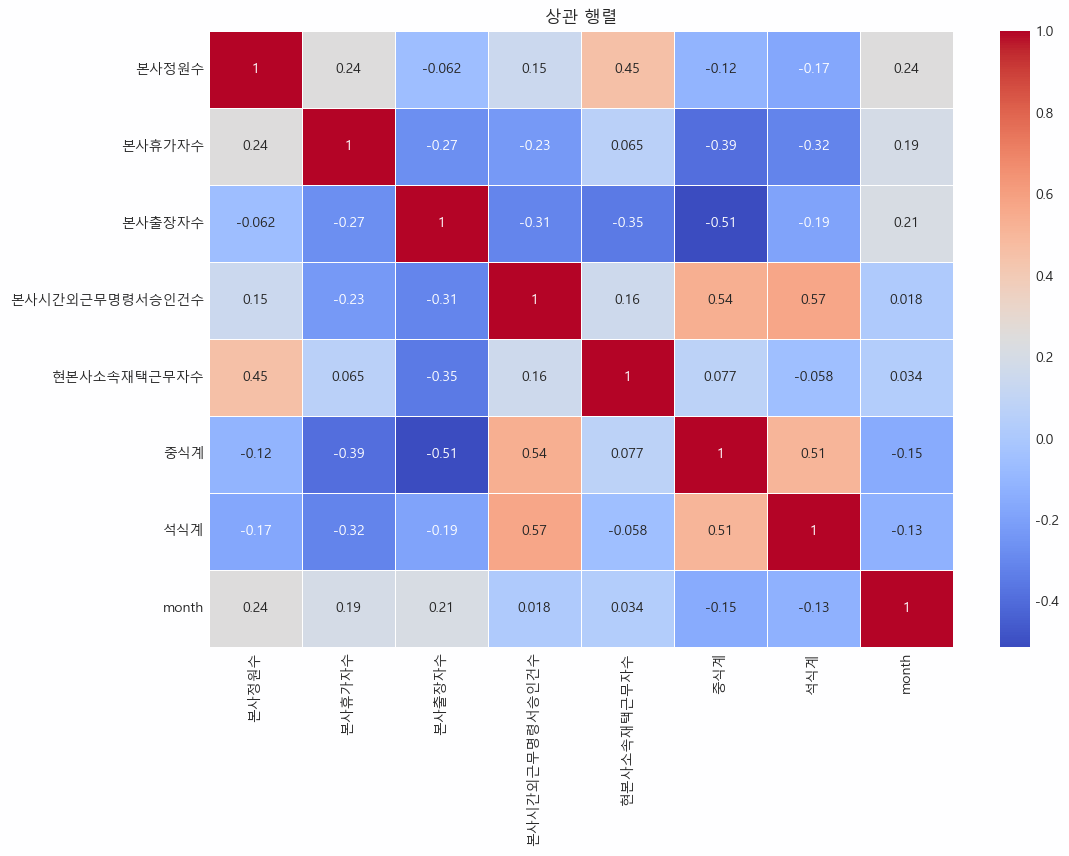
| 항목 | 특정 상관관계 | 설명 |
|---|---|---|
| 중식계 | 석식계 (0.64) | 중식과 석식을 함께 먹는 경향이 있을 수 있음을 나타냄 |
| 본사시간외근무명령서승인건수 | 중식계 (0.55), 석식계 (0.58) | 시간외 근무가 많은 날에는 식사 인원도 많다는 것을 의미할 수 있음 |
| 본사정원수 | 현본사소속재택근무자수 (0.46) | 재택 근무자 수가 본사 정원 수와 비례하여 증가하는 경향을 나타낼 수 있음 |
| 본사휴가자수 | 석식계 (-0.44) | 휴가자가 많을수록 석식 인원이 줄어드는 경향을 나타낼 수 있음 |
| 본사출장자수 | 본사시간외근무명령서승인건수 (-0.31), 중식계 (-0.39) | 출장이 많을수록 중식 인원이 줄어드는 경향을 나타낼 수 있음 |
| month | 대부분의 피처들과 약한 상관관계 | 시간에 따른 변화가 크게 영향을 미치지 않음을 나타냄 |
- 범주형 데이터에 인코딩 적용
고유값이 많지 않은 요일 컬럼에 one-hot encoding 적용
df_scaled = pd.get_dummies(df_scaled, columns = ['요일'])고유값이 너무 다양한 메뉴_main 컬럼에 frequency encoding 적용
→ 군집 분석에서 메뉴의 빈도가 식수에 어떤 영향을 미치는지 분석하는데 도움되는 인코딩
→ 고유값들의 빈도가 동일할 때 구분이 어려워진다는 단점이 있음
for column in categorical_list[1:] :
freq_map = df_scaled[column].value_counts().to_dict()
df_scaled[f"{column}_encoded"] = df_scaled[column].map(freq_map)
df_scaled[['조식메뉴_Main', '중식메뉴_Main', '석식메뉴_Main']]조식메뉴_Main 중식메뉴_Main 석식메뉴_Main 0 쥐어채무침 오징어찌개 건파래무침 1 단호박샌드 김치찌개 콩나물밥 2 느타리호박볶음 견과류조림 새송이버섯볶음 3 근대국 부추전 미니김밥 4 방풍나물 돈육씨앗강정 감자소세지볶음 ... ... ... ... 1200 마늘종숙회 견과류마카로니범벅 맛살튀김 1201 생크림단팥빵 버섯숙회 비엔나채소볶음 1202 바지락살국 계란파국 수제맛쵸킹탕수육 1203 분홍소세지구이 양념김 생강채 1204 애호박새우젓볶음 교촌간장치킨 수제고기육전 1205 rows × 3 columns
- Main 컬럼 삭제 (사용하지 않을 컬럼)
df_encoded = df_scaled.drop(columns = ['조식메뉴_Main',
'중식메뉴_Main',
'석식메뉴_Main'])7.요일별 방문자 수 패턴 기반 재고 관리 전략 수립 (K means clustering)
- K means clustering 적용하기
from sklearn.cluster import KMeans
# 모델 초기화
model = KMeans(
n_clusters=3,
algorithm='lloyd', # K-mean 알고리즘 설정(기본값)
n_init=10, # 초기 중심점을 무작위로 선택하는 횟수를 설정
random_state=2024
)
model.fit(df_encoded)
model.predict(df_encoded)- 엘보우 기법으로 최적의 클러스터 개수 확인
# 클러스터 개수 범위 설정
ks = range(1, 10)
# 각 클러스터 개수에 대해 KMeans 모델을 훈련하고 SSE를 계산
kmeans_per_k = [KMeans(n_init=10, n_clusters=k, random_state=2024).fit(df_encoded)
for k in ks]
inertias = [model.inertia_ for model in kmeans_per_k]
# 군집 개수에 따른 SSE 시각화
plt.figure(figsize=(8, 3.5))
# x축: 클러스터 개수, y축: SSE
plt.plot(ks, inertias, "bo-")
# plt.xlabel('군집 개수, k')
# plt.ylabel('SSE')
# Elbow 포인트에 화살표 추가
plt.annotate(
"",
xy=(3, inertias[2]), # 화살표 머리 위치
xytext=(3.45, 5400), # 화살표 꼬리 위치
arrowprops=dict(facecolor='black', shrink=0.1)
)
plt.text(
3.75, 5400,
"Elbow",
horizontalalignment="center"
)
plt.xlabel('클러스터 개수')
plt.ylabel('SSE')
plt.xticks(ks)
plt.grid()
plt.show()
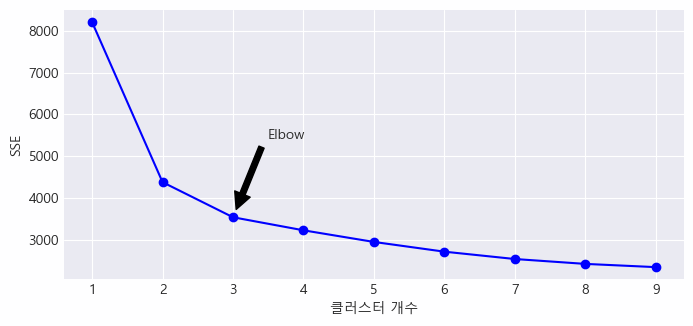
✔️ 클러스터 개수가 3일 때 SSE가 크게 감소한 것으로 나타남
→ 실루엣 계수를 통해, 클러스터가 효율적으로 형성되었는지 확인해보자
from sklearn.metrics import silhouette_score
silhouette_score(df_encoded, kmeans_per_k[2].labels_) # kmeans_per_k[2] = 클러스터가 3개인 모델0.29610377253257636
# 각 클러스터 개수에 대한 실루엣 점수 계산
silhouette_scores = [silhouette_score(df_encoded, model.labels_)
for model in kmeans_per_k[1:]]
# k = 2부터 시작 (k=1은 의미가 없음)
plt.figure(figsize=(8, 3))
plt.plot(range(2, 10), silhouette_scores, "bo-")
plt.xlabel('군집 개수, k')
plt.ylabel("실루엣 스코어")
plt.grid()
plt.show()
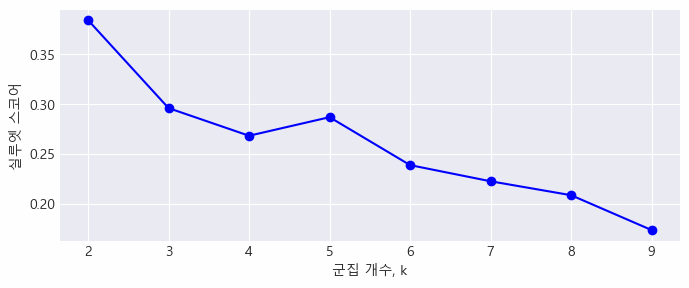
✔️ 실루엣 스코어를 보았을 때, 최적의 클러스터 개수는 2개가 적절해 보임 (실루엣 스코어 높을수록 좋음)
- 덴드로그램을 이용한 시각화
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(12, 8))
dendrogram = shc.dendrogram(shc.linkage(df_encoded, method='ward'))
plt.title('k means 클러스터링 덴드로그램')
plt.xlabel('Samples')
plt.ylabel('유클리디안 거리')
plt.show()
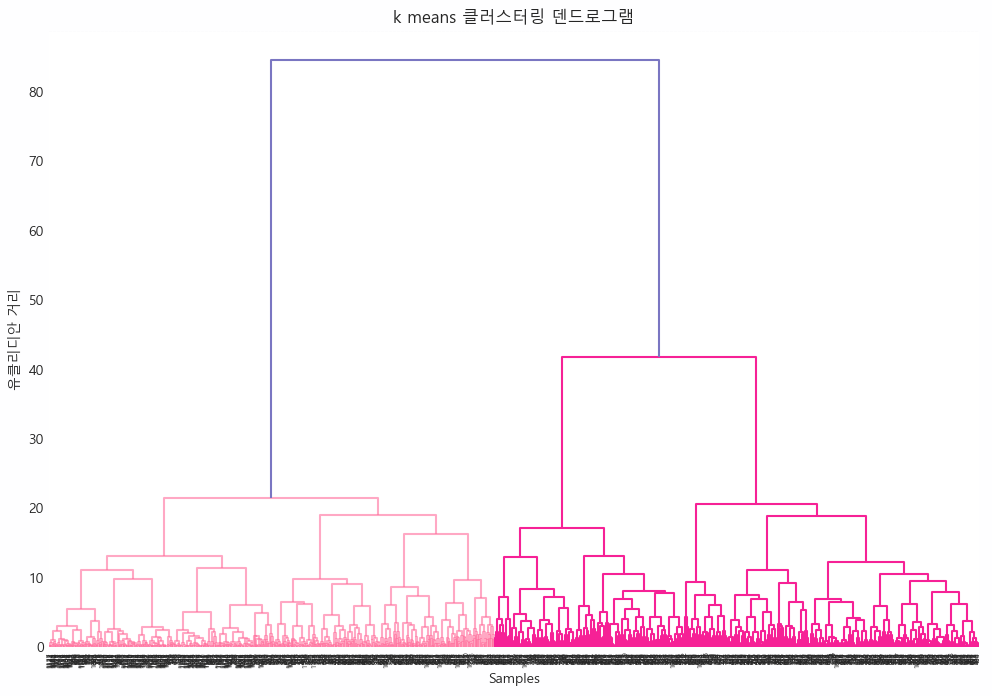
✔️ Inertia 그래프와 실루엣 스코어 그래프, 덴드로그램을 확인한 결과, 클러스터 개수는 2-3개가 적절해 보임
✔️ 우선 클러스터 개수는 3개로 고정해보기로 함
- 각 클러스터에 속한 데이터 포인트의 주요 변수(중식계, 석식계)에 대한 평균값 계산하기
k = 3
model = KMeans(n_clusters=k, n_init=10, random_state=2024)
df_encoded['cluster'] = model.fit_predict(df_encoded)
cluster_means = df_encoded.groupby('cluster').mean()
cluster_means본사정원수 본사휴가자수 본사출장자수 본사시간외근무명령서승인건수 현본사소속재택근무자수 중식계 석식계 month 요일_금 요일_목 요일_수 요일_월 요일_화 조식메뉴_Main_encoded 중식메뉴_Main_encoded 석식메뉴_Main_encoded cluster 0 0.226352 0.108921 0.602374 0.260137 0.011829 0.518017 0.484643 0.495185 0.205508 0.213983 0.154661 0.226695 0.199153 3.961864 1.707627 1.644068 1 0.381224 0.122245 0.574668 0.285863 0.185848 0.504596 0.443723 0.522449 0.206122 0.218367 0.187755 0.189796 0.197959 1.302041 1.412245 1.416327 2 0.243054 0.100425 0.613323 0.267155 0.004916 0.516023 0.488146 0.461364 0.205000 0.180000 0.170000 0.205000 0.240000 6.790000 1.870000 1.740000
✔️ 조식메뉴_Main_encoded에서는 클러스터 2가 다른 클러스터에 비해 훨씬 높은 값을 보임
- 클러스터별 조식메뉴_Main_encoded 평균값 비교
cluster_means[['조식메뉴_Main_encoded', '중식계', '석식계']]조식메뉴_Main_encoded 중식계 석식계 cluster 0 3.961864 0.518017 0.484643 1 1.302041 0.504596 0.443723 2 6.790000 0.516023 0.488146
✔️ 클러스터 2의 조식메뉴_Main_encoded 값이 높음을 확인
- 클러스터별 조식 메뉴 분포 확인
cluster_2_breakfast = df_encoded[df_encoded['cluster'] == 2]['조식메뉴_Main_encoded']
cluster_2_breakfast.value_counts()조식메뉴_Main_encoded 6 102 7 56 8 24 9 18 Name: count, dtype: int64
- 조식 메뉴 6개 선정 후, 이에 대해 중식계 및 석식계 평균값 비교
breakfast_6 = cluster_2_breakfast.value_counts().index
for menu in breakfast_6:
subset = df_encoded[(df_encoded['cluster'] == 2) & (df_encoded['조식메뉴_Main_encoded'] == menu)]
print(f"Menu: {menu}")
print(f" 중식계 평균 방문: {subset['중식계'].mean()}")
print(f" 석식계 평균 방문: {subset['석식계'].mean()}")
print("\n")Menu: 6 중식계 평균 방문: 0.5185456813851939 석식계 평균 방문: 0.4875645639029645 Menu: 7 중식계 평균 방문: 0.488330671907628 석식계 평균 방문: 0.48035937221330477 Menu: 8 중식계 평균 방문: 0.5260819719117226 석식계 평균 방문: 0.49942779858510206 Menu: 9 중식계 평균 방문: 0.5744721505684532 석식계 평균 방문: 0.5006242197253434
✔️ 시간대에 따라 방문 횟수 차이가 발생하는 메뉴들이 있음 (메뉴 7 제외)
✔️ 메뉴 9가 중식, 석식 각각 방문 횟수가 가장 많은 것으로 나타남
- 클러스터별 요일별 평균 방문자 수
df_encoded["요일"] = df["요일"]
cluster_day_means = df_encoded.groupby(['cluster', '요일']).mean()[['중식계', '석식계']].unstack()
cluster_day_means중식계 석식계 요일 금 목 수 월 화 금 목 수 월 화 cluster 0 0.332140 0.458910 0.537804 0.721764 0.526042 0.411663 0.492058 0.432798 0.543129 0.525673 1 0.288755 0.449627 0.525319 0.736943 0.547553 0.336040 0.445028 0.395443 0.537420 0.510367 2 0.292893 0.453162 0.515553 0.732420 0.569253 0.413294 0.481759 0.431813 0.555251 0.539456
✔️ 월요일 : 모든 클러스터에서 중식계와 석식계 방문자 수가 가장 많은 요일
→ 월요일이 식재료 재고 관리에서 중요한 날이라고 생각할 수 있음
✔️ 금요일 : 모든 클러스터에서 중식계와 석식계 방문자 수가 가장 낮은 요일
→ 금요일에 재고를 적게 준비할 필요가 있음을 시사
✔️ 화요일, 수요일, 목요일은 클러스터별로 다소 차이가 있지만, 대체로 중간 수준의 방문자 수를 나타냄
→ 클러스터 2에서는 화요일의 방문자 수가 상대적으로 높음.
요일별 방문자 수 패턴을 이해한 후, 요일별로 식재료 재고 관리 전략 수립하기
- 중식계와 석식계 방문자 수 분포 시각화 후 임계값 찾기
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
axes[0].hist(df_encoded['중식계'], bins=30, alpha=0.7)
axes[0].axvline(0.5, color='red', linestyle='dashed', linewidth=1)
axes[0].set_title('중식계 방문자 수 분포')
axes[0].set_xlabel('인원')
axes[0].set_ylabel('빈도')
axes[1].hist(df_encoded['석식계'], bins=30, color='darkgreen', alpha=0.7)
axes[1].axvline(0.5, color='red', linestyle='dashed', linewidth=1)
axes[1].set_title('석식계 방문자 수 분포')
axes[1].set_xlabel('인원')
axes[1].set_ylabel('빈도')
plt.tight_layout()
plt.show()
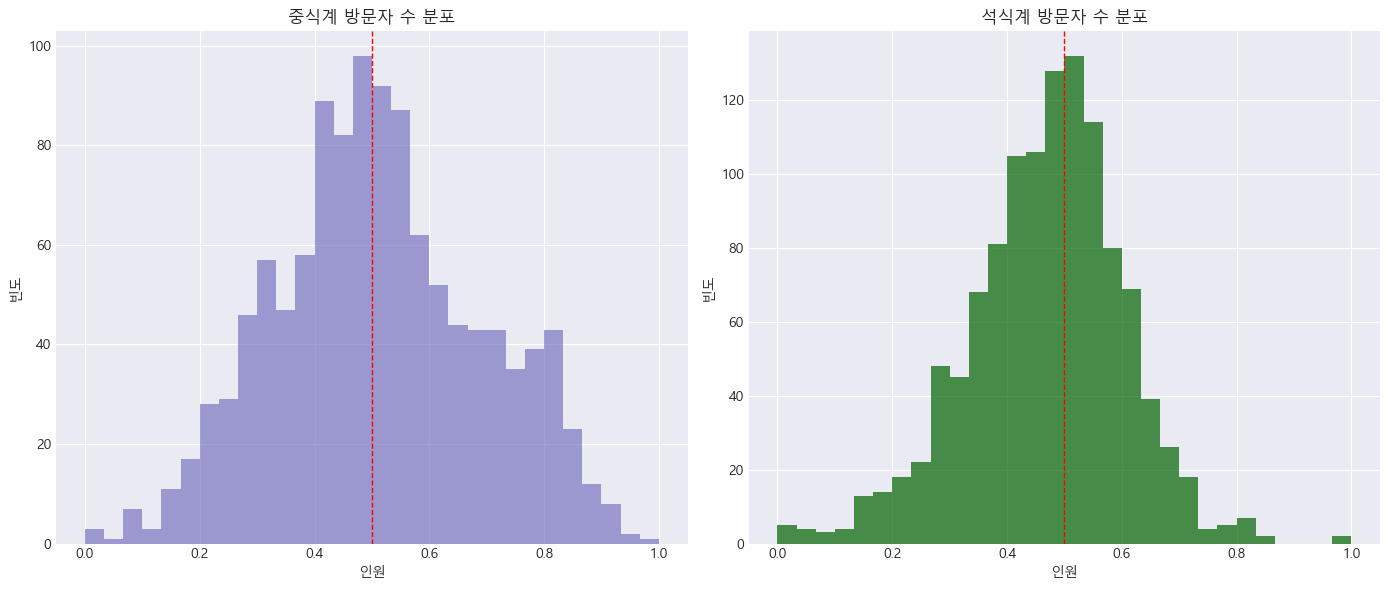
- 요일별 재고 관리 전략 수립
평균 방문자 수가 0.5를 넘으면 식재료 재고 증가 전략 제안
for day in df_encoded['요일'].unique():
# 특정 요일에 해당하는 클러스터별 중식계 및 석식계 평균값 선택
day_means = cluster_day_means.loc[:, (slice(None), day)]
print(f"요일: {day}")
for cluster in day_means.index:
print(f" 클러스터 {cluster}:")
print(f" 중식계 평균 방문자 수: {day_means[('중식계', day)][cluster]}")
print(f" 석식계 평균 방문자 수: {day_means[('석식계', day)][cluster]}")
# 중식계 평균 방문자 수가 0.5보다 큰 경우, 중식 재고 증가 전략 제안
if day_means[('중식계', day)][cluster] > 0.5:
print(" 전략: 중식 재고 증가.")
# 석식계 평균 방문자 수가 0.5보다 큰 경우, 석식 재고 증가 전략 제안
if day_means[('석식계', day)][cluster] > 0.5:
print(" 전략: 석식 재고 증가.")
print("\n")| 요일 | 중식계 평균 방문자 수 > 0.5 | 석식계 평균 방문자 수 > 0.5 | 전략 |
|---|---|---|---|
| 월요일 | 클러스터 0, 1, 2 | 클러스터 0, 1, 2 | 중식 및 석식 재고 모두 증가 |
| 화요일 | 클러스터 0, 1, 2 | 클러스터 0, 1, 2 | 중식 및 석식 재고 모두 증가 |
| 수요일 | 클러스터 0, 1, 2 | 해당 없음 | 중식 재고 증가 |
| 목요일 | 해당 없음 | 해당 없음 | 재고 증가 전략 없음 |
| 금요일 | 해당 없음 | 해당 없음 | 재고 증가 전략 없음 |
8. 클러스터별 식재료 재고 관리 자동화 전략 수립 (DBSCAN, XGBoost)
K means 클러스터의 실루엣 스코어는 0.3으로 낮았는데, 데이터의 이상치때문일 수도 있고, 거리기반 알고리즘이 해당 데이터에 적절하지 않은 것일 수도 있다.
그래서 이번에는밀도 기반 알고리즘인 DBSCAN을 통해 식재료 재고 관리 전략을 수립해보자.
# DBSCAN 학습 및 새롭게 군집화를 위해 컬럼 삭제
df_encoded.drop(columns=["요일","cluster"], inplace=True)
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=5)
df_encoded['dbscan_cluster'] = dbscan.fit_predict(df_encoded)
df_encoded['dbscan_cluster'].value_counts() # -1은 노이즈로 간주하고 있는 데이터 포인트dbscan_cluster -1 732 3 45 7 44 17 44 14 42 32 34 0 13 18 10 9 10 12 9 2 9 6 9 10 9 24 9 15 8 16 8 27 8 1 8 25 7 22 7 31 7 29 7 8 7 19 6 20 6 23 6 5 6 26 6 21 6 30 5 34 5 35 5 13 5 11 5 33 5 28 5 4 5 Name: count, dtype: int64
✔️ 약 732개의 데이터 포인트가 노이즈로 분류되었음
✔️ 나머지는 0~35의 클러스터로 분류되었음
- DBSCAN에서의 적절한 파라미터 값 찾기
min_samples(minPts): 클러스터 형성하기 위해 필요로 하는 최소 이웃 포인트 수eps: 두 포인트 사이의 최대 거리로, 이 거리 내에 있는 포인트들은 서로 이웃이라고 간주됨
✅ 일반적으로, min_samples(minPts)는 다음과 같이 구해짐
৹ 데이터 포인트 수 n을 기반으로 사용
৹ 2차원 데이터의 경우, min_samples가 4 또는 5
৹ 다차원 데이터의 경우, min_samples는 2 * dim
✅ 일반적으로 eps는 다음과 같이 구해짐
৹ sorted k-dist plot 사용해 결정
৹ min_samples를 k로 설정하고, 각 데이터 포인트와 k번째 가장 가까운 이웃 사이의 거리 계산
৹ 계산된 k-dist 값을 오름차순으로 정렬
৹ k-dist plot을 그려 엘보우 지점이 eps 값
min_samples결정
import math
n = len(df_encoded) # 데이터 포인트 수
min_samples = math.ceil(np.log(n)) # 전체 데이터 포인트 수의 자연로그 값으로 결정
min_samples # 프린트 결과 8✔️ 적절한 min_samples는 8인 것으로 드러남
- sorted k-dist plot 그리기
from sklearn.neighbors import NearestNeighbors
X = df_encoded.drop(columns=['dbscan_cluster'])
neighbors = NearestNeighbors(n_neighbors=min_samples)
neighbors_fit = neighbors.fit(X)
distances, indices = neighbors_fit.kneighbors(X)
distances[0] # 첫번째 데이터 포인트와 그 이웃들 사이의 거리array([0. , 0.70789141, 0.90719828, 1.14906258, 1.20843148, 1.45024658, 1.53264353, 1.54248651])
indices[0] # 첫 번째 데이터 포인트의 가장 가까운 이웃들의 인덱스array([ 0, 552, 594, 97, 775, 1097, 120, 734], dtype=int64)
# 행 방향으로 각 데이터 포인트별로 접근 후, 모든 이웃과의 거리를 오름차순으로 정렬
distances = np.sort(distances, axis=0)
# 배열에서 각 데이터 포인트의 8번째로 가까운 이웃과의 거리 추출
distances = distances[:, min_samples-1]
distancesarray([0.24004167, 0.2551981 , 0.26140239, ..., 2.74150986, 2.7782563 , 2.83008945])
데이터 포인트 중 8번째로 가까운 이웃과의 거리를 나타낸 어레이인데,
첫번째 값 0.24004167은 그 중 가장 가까운 거리의 값이며
마지막 값 2.83008945는 그 중 가장 먼 거리의 값을 나타냄.
plt.figure(figsize=(12, 8))
plt.plot(distances)
plt.title(f'sorted k-dist plot (k={min_samples})', fontsize=18)
plt.xlabel('데이터 포인트', fontsize=12)
plt.ylabel('거리', fontsize=12)
plt.show()
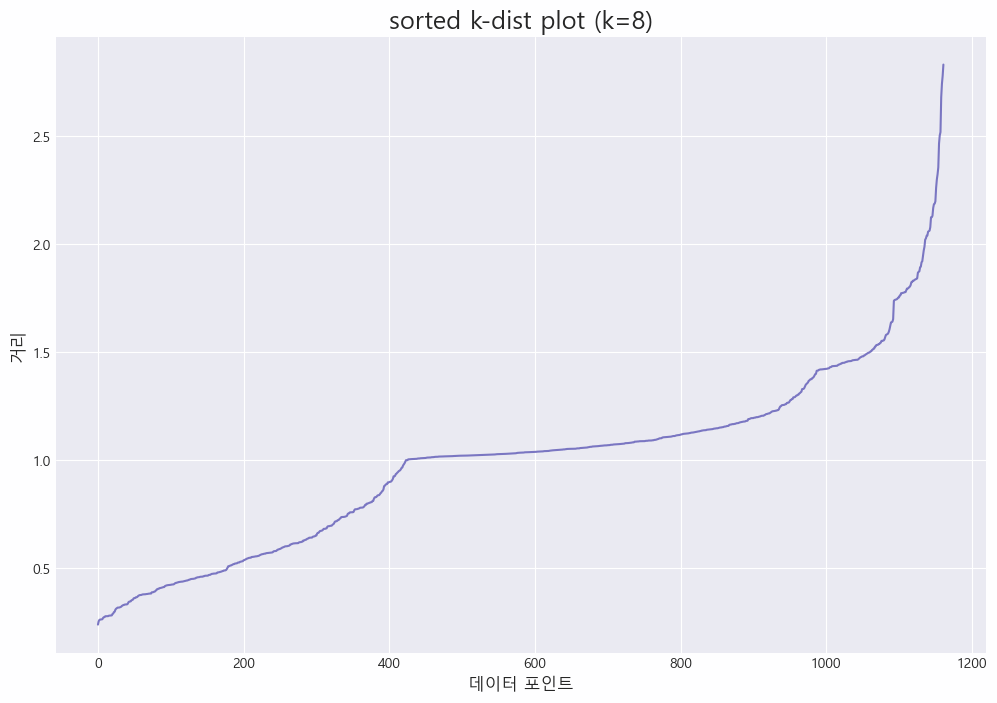
거리가 1.0, 1.4, 1.7일 때(데이터 포인트는 각각 400 내외, 1000 내외, 1100 내외 부근) 그래프에서 급격한 변화가 일어난 것을 알 수 있음
- sorted k-dist plot 결과를 기반으로 eps 선택하고 결과 확인하기
# eps = 1.0
dbscan = DBSCAN(eps=1.0, min_samples = min_samples)
# 업데이트 후 확인
df_encoded['dbscan_cluster'] = dbscan.fit_predict(df_encoded)
df_encoded['dbscan_cluster'].value_counts().sort_index(ascending=True)dbscan_cluster -1 742 0 15 1 8 2 9 3 12 4 45 5 8 6 9 7 44 8 8 9 10 10 9 11 9 12 42 13 9 14 8 15 8 16 44 17 10 18 12 19 9 20 9 21 9 22 8 23 8 24 8 25 34 26 8 27 8 Name: count, dtype: int64
# eps = 1.4
dbscan = DBSCAN(eps=1.4, min_samples = min_samples)
# 업데이트 후 확인
df_encoded['dbscan_cluster'] = dbscan.fit_predict(df_encoded)
df_encoded['dbscan_cluster'].value_counts().sort_index(ascending=True)dbscan_cluster -1 821 0 15 1 8 2 9 3 12 4 45 5 9 6 44 7 8 8 10 9 9 10 9 11 42 12 8 13 8 14 44 15 10 16 9 17 34 18 8 Name: count, dtype: int64
# eps = 1.7
dbscan = DBSCAN(eps=1.7, min_samples = min_samples)
# 업데이트 후 확인
df_encoded['dbscan_cluster'] = dbscan.fit_predict(df_encoded)
df_encoded['dbscan_cluster'].value_counts().sort_index(ascending=True)dbscan_cluster -1 75 0 136 1 132 2 15 3 8 4 100 5 9 6 12 7 159 8 45 9 8 10 140 11 17 12 44 13 8 14 8 15 10 16 9 17 9 18 42 19 9 20 8 21 8 22 44 ... 27 17 28 9 29 34 30 8 Name: count, dtype: int64
eps = 1.0에서는 클러스터링되지 않는 포인트가 많이 발생하고, 1.7에서는 클러스터가 너무 커질 수 있으므로 중간값인 1.4를 선택함
print(df_encoded['dbscan_cluster'].unique())
len(df_encoded['dbscan_cluster'].unique())array([ 7, 3, -1, 0, 1, 2, 4, 5, 6, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23], dtype=int64) 25이상치(-1)를 제외한 24개의 군집 사용
- 이상치 확인
노이즈 데이터와 클러스터 데이터의 주요 변수 분표를 비교해보자.
노이즈 데이터가 클러스터 데이터와 어떻게 다른지 확인하고, 크게 다를 경우에는 노이즈 데이터를 제거하거나 조정해야 한다.
noise_data = df_encoded[df_encoded['dbscan_cluster'] == -1]
# 중식계, 석식계 노이즈 분포 확인
plt.figure(figsize=(12, 8))
sns.boxplot(data = noise_data[['중식계', '석식계']])
plt.title('중식계와 석식계 노이즈 분포')
plt.show()
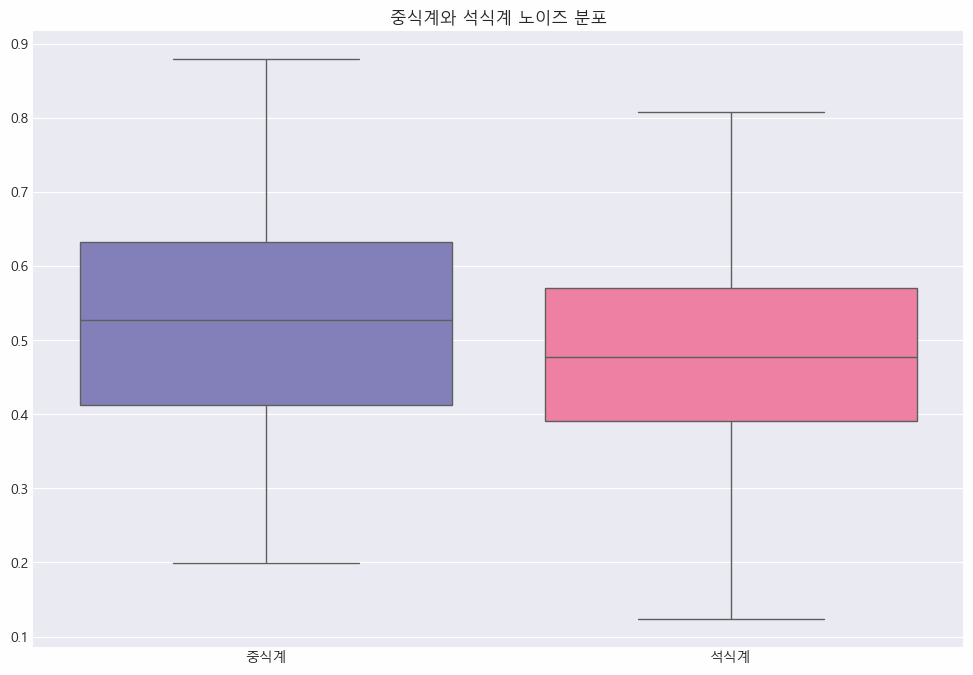
✔️ 중식계 분포는 상대적으로 중앙값이 더 높고 IQR도 넓어, 전반적으로 중식 방문자 수가 더 많은 경향을 보임
✔️ 석식계는 중앙값이 더 낮고 방문자 수가 더 작은 경향을 보임
- 노이즈 제외 클러스터 데이터 추출
# 클러스터 데이터 추출 (노이즈 제외)
cluster_data = df_encoded[df_encoded['dbscan_cluster'] != -1]
fig, axes = plt.subplots(1, 2, figsize=(16, 8), sharey=True)
# 중식계 박스플롯
sns.boxplot(data=[noise_data['중식계'], cluster_data['중식계']], notch=True, palette="Set2", ax=axes[0])
axes[0].set_title('중식계 분포 : Noise vs Cluster')
axes[0].set_xticklabels(['Noise', 'Cluster'])
# 석식계 박스플롯
sns.boxplot(data=[noise_data['석식계'], cluster_data['석식계']], notch=True, palette="Set2", ax=axes[1])
axes[1].set_title('석식계 분포 : Noise vs Cluster')
axes[1].set_xticklabels(['Noise', 'Cluster'])
plt.show()
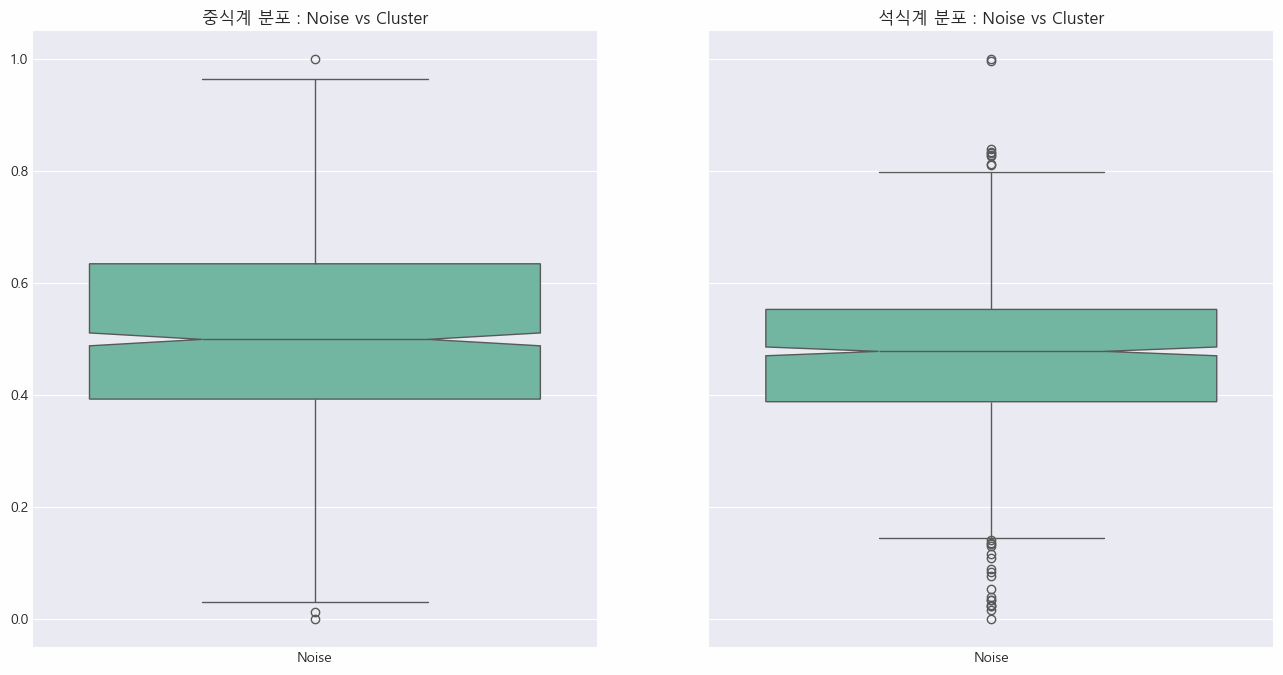
✔️ 노이즈 데이터와 클러스터 데이터의 분포에는 큰 차이가 있음
→ 클러스터 데이터의 경우, 특히 석식계에서 많은 이상치가 관찰될었으며, 중식계와 석식계 모두 분포의 변화가 나타남
- 클러스터별 평균값 확인
cluster_means = cluster_data.groupby('dbscan_cluster').mean()
cluster_means[['중식계', '석식계']].plot(kind='bar', figsize=(12, 6))
plt.title('Cluster-wise Average Lunch and Dinner Visitors')
plt.ylabel('Average Number of Visitors')
plt.show()
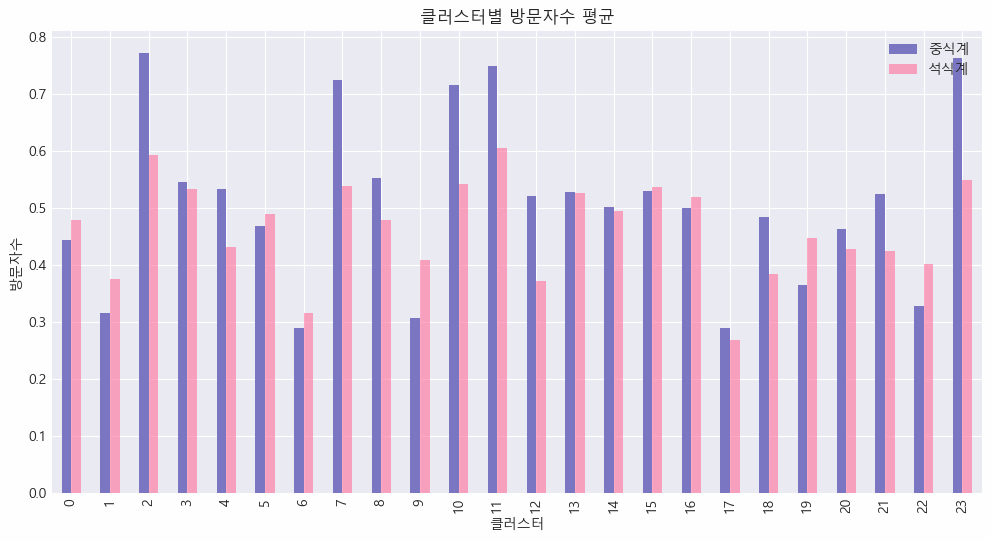
✔️ 클러스터별로 중식계와 석식계 방문자 수가 크게 다르다는 것을 알 수 있음
✔️ 클러스터 2, 7, 10, 11, 23은 식당 방문자 수가 상대적으로 많은 반면, 클러스터 1, 6, 17 등은 차이가 작음
✔️ 클러스터 2, 7, 10, 11, 23은 중식계와 석식계 방문자 수 차이가 상대적으로 큰 반면, 클러스터 5, 6, 13, 14 등은 차이가 작음
✔️ 이러한 차이는 특정 요인(예: 특정 요일, 메뉴 등)에 의해 영향을 받을 가능성이 있어보임
✔️ 추후에 각 클러스터별 분포나 시각화를 통해 분석을 더 수행하여, 더 많은 인사이트를 도출해내볼 수 있겠음
- 식재료 재고 관리 전략 자동화
방문자 수가 많은 클러스터에서는 식재료 재고를 늘려야 하며, 방문자 수가 적은 클러스터에서는 재고를 줄이는 게 효율적일 것으로 예상한다.
이를 통해 식재료 낭비를 줄이고, 고객 만족도를 높일 수 있다.
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
X = cluster_data.drop(columns=['dbscan_cluster'])
y = cluster_data['dbscan_cluster']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2024)
xgb_model = xgb.XGBClassifier(n_estimators=100, random_state=2024)
xgb_model.fit(X_train, y_train)
y_pred = xgb_model.predict(X_test)
print(classification_report(y_test, y_pred))precision recall f1-score support 0 0.90 1.00 0.95 27 1 1.00 0.89 0.94 18 2 0.00 0.00 0.00 1 3 0.90 0.96 0.93 28 4 1.00 1.00 1.00 28 5 1.00 0.20 0.33 5 6 0.87 1.00 0.93 26 7 0.86 0.86 0.86 7 8 1.00 1.00 1.00 6 9 0.00 0.00 0.00 2 10 1.00 1.00 1.00 7 11 0.50 0.50 0.50 2 12 1.00 0.67 0.80 3 13 1.00 0.67 0.80 3 14 0.00 0.00 0.00 0 15 0.80 1.00 0.89 8 16 1.00 1.00 1.00 1 17 1.00 1.00 1.00 1 18 1.00 1.00 1.00 10 19 1.00 1.00 1.00 2 21 1.00 0.89 0.94 9 accuracy 0.92 194 macro avg 0.80 0.74 0.76 194 weighted avg 0.92 0.92 0.91 194
✔️ 대부분의 클래스에서 precision, recall, f1 score가 높지만, 일부 클래스는 샘플 수가 매우 적어서 모델이 해당 클래스를 제대로 학습하지 못 한 것으로 보임
- SMOTE를 사용한 오버샘플링
KNN을 통해 소수 클래스의 각 샘플에 대한 K개의 최근접 이웃을 찾고,
각 소수 클래스 샘플과 그 이웃 사이 선형 간격을 따라 샘플을 생성하기
k_neighbors값은 클러스터 최소 샘플 수 보다 작아야 하므로 1을 하는 게 좋음
그러나 k_neighbors 값이 1일 경우 SMOTE는 정상작동하지 않으므로 2로 하자
smote = SMOTE(random_state=2024, k_neighbors=2)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)- 하이퍼 파라미터 튜닝
param_grid = {
'n_estimators': [100, 200, 300],
'learning_rate': [0.01, 0.1, 0.2],
'max_depth': [3, 4, 5]
}
grid_search = GridSearchCV(
xgb.XGBClassifier(random_state=2024),
param_grid,
cv=3,
scoring='accuracy')
grid_search.fit(X_resampled, y_resampled)
grid_search.best_params_ # {'learning_rate': 0.2, 'max_depth': 4, 'n_estimators': 300}- 최적의 하이퍼 파라미터 조합으로 재훈련, 예측, 평가
best_model = grid_search.best_estimator_
best_model.fit(X_train, y_train)
y_pred = best_model.predict(X_test)
print(classification_report(y_test, y_pred))precision recall f1-score support 0 1.00 0.97 0.98 33 1 1.00 1.00 1.00 6 2 1.00 0.50 0.67 2 3 1.00 0.94 0.97 32 4 0.86 0.96 0.91 26 5 0.00 0.00 0.00 0 6 1.00 1.00 1.00 1 7 0.92 1.00 0.96 36 8 0.80 1.00 0.89 8 9 0.97 0.97 0.97 34 10 0.00 0.00 0.00 1 11 1.00 0.50 0.67 2 12 1.00 0.89 0.94 9 13 1.00 1.00 1.00 1 16 1.00 1.00 1.00 1 17 1.00 1.00 1.00 5 18 1.00 0.33 0.50 3 20 1.00 1.00 1.00 11 21 0.67 0.67 0.67 3 22 0.00 0.00 0.00 1 23 1.00 1.00 1.00 2 accuracy 0.94 217 macro avg 0.82 0.75 0.77 217 weighted avg 0.94 0.94 0.94 217
✔️ SMOTE를 통해 일부 클러스터는 성능이 개선되었으나 일부는 아직 낮은 재현율을 보임
✔️ 추후 샘플링 기법, 모델 수정을 통해 분류 성능 보완 가능함
