
모니터링의 중요성
어? 이거 왜 이래?
서비스를 개발하며 운영하다보면 잘되던 서버가 갑자기 오늘 내일 하는 일이 생기곤한다. 물론 아무 이유도 없이 문제가 생긴 건 아닐 것이다. 하지만 아무런 대비를 해두지 않은 상태라면 원인을 찾고 조치를 취하기 위해 많은 리소스를 들어야 할 것이다. 그렇기 때문에 모니터링이 중요한 것이다.
-
서버가 쓰러지기 전, 비틀비틀 할 때 알림을 받을 수 있다면?
-
최소한 무슨 이유로 장애가 발생한건지 알람을 받을 수 있다면?
모니터링/경보 시스템이 갖춰져 있다면 대비책이 없는 것보다 훨씬 빠르게 원인을 찾고 문제 수정을 할 수 있다.
현재 회사의 서비스는 에러가 발생시 해당 에러의 내용을 웹훅을 이용해 Slack으로 알람을 보내도록 되어있다.
이 기능도 아주 좋은 기능이지만 이것만으로는 이미 장애 생긴 뒤에야 대응을 할 수 있다는 단점이 있다. 만약 장애가 생기기 직전에 미리 알 수 있는 방법이 있다면 서버가 죽기 전에 조치를 취해서 문제가 아예 생기지 않도록 할 수도 있겠지.
무엇을 이용해 모니터링 할까?
Spring Actuator
Spring Boot에는 Actuator라는 기가 막힌 기능이 있다.
애플리케이션의 운영에 필요한 다양한 정보를 제공하는 엔드포인트(endpoint)와 메트릭(metric)을 모아둔 모듈로 Actuator를 사용하면 다음과 같은 정보를 얻을 수 있다.
- 애플리케이션의 상태 정보(health)
- 환경 변수(environment)
- 빈(bean) 정보
- HTTP 요청 로그
- 메모리 사용량
- CPU 사용량 등의 시스템 정보
이러한 정보를 이용하여, 운영 중인 애플리케이션의 상태를 파악하고 성능을 분석하여 개선할 수 있다. 또한, Actuator의 엔드포인트를 이용하여 모니터링 도구와 연동하여 모니터링 정보를 수집할 수도 있다.
주문량이나 취소량 같은 비지니스 로직의 커스텀 메트릭을 추가할 수도 있는데 이 글에서는 다루지 않을 것이다.
Actuator는 간단하게 사용할 수 있는데, Gradle 기준으로 다음과 같은 의존성을 추가해주면 된다.
implementation 'org.springframework.boot:spring-boot-starter-actuator'하지만 Actuator의 엔드포인트들은 기본적으로 숨겨져있는 것들이 많다.
노출되면 않되는 애플리케이션의 민감한 정보를 보여주는 엔드포인트도 많고, 호출하는 것만으로 서버를 내려버리는 shut down 엔드포인트도 존재하기 때문이다.
그래서 Actuator의 엔드포인트는 안전하게 사용할 수 있도록 관리해야 한다.
우형 테크 블로그에 Actuator의 보안 이슈사항에 대한 좋은 글이 있으니 참고해서 설정하자!
[우아한 형제들 기술 블로그] Actuator 안전하게 사용하기
위 블로그 글에서 강조하는 부분을 살펴보면 이렇다.
- Actuator의 엔드포인트는 모두 비활성화 하고 필요한 것만 골라서 include하여 화이트리스트 형태로 운영해야 한다.
- shutdown 엔드포인트는 활성화 하지 않는다.
- JMX 형태로 Actuator를 사용하지 않을 경우 반드시 비활성화 하자.
- Actuator는 서비스 운영에 사용되는 포트와 다른 포트를 사용하자
- Actuator의 default 경로를 사용하지 않고 변경하여 운영한다.
- 인증 권한이 있는 사용자만이 접근 가능하도록 제어한다.
이점을 유의하면서 application.yml에 엔드포인트 옵션을 설정해주면 된다.
server:
port: 8080 # 애플리케이션의 포트
tomcat:
mbeanregistry:
enabled: true # tomcat의 엔트포인트를 활성화 시키는 옵션
...
# Actuator
management:
info: # info 옵션은 꼭 management 바로 아래에 붙여줘야 한다!
java:
enabled: true # JAVA 엔드포인트 활성화
os:
enabled: true # OS 엔드포인트 활성화
env:
enabled: true # env 엔드 포인트 활성화
endpoint:
health:
show-components: always # health check 관련 컨포넌트 정보 엔드포인트 활성화
endpoints:
web:
exposure:
include: "*" # 원래는 필요 옵션만 화이트리스트 방식으로 운영해야 하는데 본 post에선 편의를 위해 와일드카드로 표시하겠다. 실제 사용할 때에는 이렇게 사용하는 것은 권장하지 않는다!
base-path: /monitor # Actuator의 기본 path는 '/actuator/**'이다. 이것은 너무 잘 알려져 있는 정보이므로 보안을 위해서 path는 나만의 path로 커스텀 해서 사용하자.
jmx:
exposure:
exclude: "*" # 나는 JMX 방식으로 메트릭 정보를 확인하지 않을 것이므로 모두 비활성
include: info, health # 하지만 혹시 모르니 info와 health는 열어두었다:)
server:
port: 9097 # Actuator의 포트. 운영 포트와 다르게 설정하자.
# info 엔드포인트에서 보여질 정보들(info 엔드포인트를 사용하지 않을 거라면 필요없다. 필요시 설정)
info:
app:
name: my-back
company: my-company이렇게 활성화한 엔드포인트들는 '[내 서비스 도메인]:9097/monitor'로 가면 확인할 수 있다. 물론 back-end 컨테이너에 Actuator 포트도 열고 맵핑 해줘야 확인할 수 있다.
회사 서비스는 docker-compose를 사용해서 컨테이너를 관리하고 있으므로 compose 설정에 Actuator 포트를 추가해주었다.
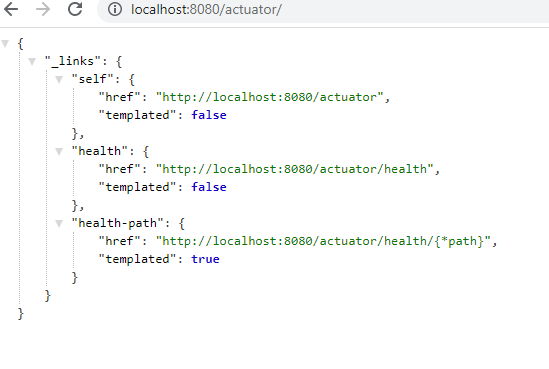
엔드포인트들은 json 형식으로 되어있다.
이런 정보는 한눈에 보기도 힘들고, 애플리케이션을 재실행하면 사라져버리는 일시적인 정보일 뿐이다.
그래서 이러한 엔드포인트의 메트릭 정보를 주기적으로 수집해서 저장해두는 일종의 크롤링+DB저장 기능이 필요할 것이다.
이러한 역할을 해주는 툴이 바로 Prometheus이다.
Prometheus
Prometheus는 Actuator가 제공하는 메트릭 정보를 수집하고 저장하고 보여줄 수 있는 기능을 제공하지만 아무 형태나 모두 읽을 수 있는 것은 아니다.
Prometheus가 읽을 수 있는 메트릭 형태가 따로 존재하기 때문에 Actuator에서 이 형태로 메트릭 데이터를 반환해줘야겠지?
마이크로미터
이러한 역할을 하는 것이 마이크로미터 라이브러리이다.
마이크로미터는 여러 메트릭 표현 표준으로 표현할 수 있도록 제공을 해주는데 구현체를 갈아끼워 해당 표준에 맞게 반환할 수 있다. 로그를 추상화하는 SLF4J와 비슷하다 생각하면 될 것이다.
우리는 prometheus를 사용할 것이므로 prometheus의 구현체를 사용할 것이니 다음 의존성을 추가해주자.
implementation 'io.micrometer:micrometer-registry-prometheus'이제 Actuator의 엔드포인트에 '[내 Actuator url]/prometheus'라는 것이 생겼을 것이다.
이 엔드포인트를 확인해보면
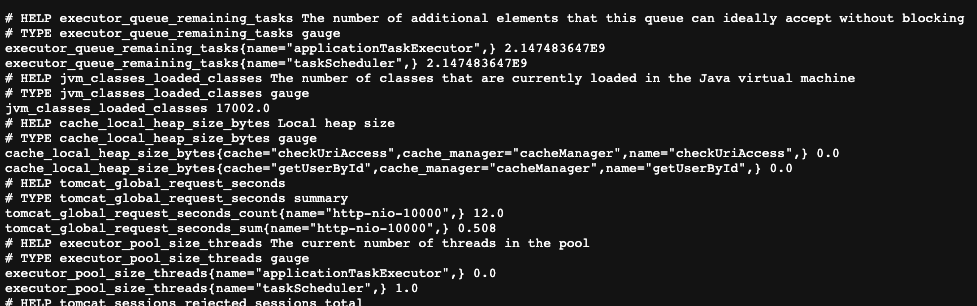
다음과 같은 포맷의 메트릭 데이터가 반환되는 것을 확인할 수 있다. 이것을 prometheus가 수집하게 하면 된다.
그냥 서버에 prometheus를 설치해서 작동시켜도 되지만 우리 회사는 컨테이너 방식을 사용하니 docker 컨테이너로 작동시킬 것이다.
prometheus 컨테이너 설정
sudo docker pull prom/prometheus서버에 위 명령어를 사용해 prometheus 이미지를 받아온다.
그리고 나서 prometheus의 설정을 위해 yaml 파일을 작성해줘야 한다.
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
# 위는 기본 prometheus.yml에 있는 코드.
# 아래 부분을 추가해서 우리 애플리케이션의 Actuator 메트릭을 수집할 수 있도록 해야 한다.
- job_name: "script-actuator" # job 이름은 알아서 설정~
metrics_path: '/monitor/prometheus' # prometheus가 읽을 수 있는 메트릭 정보 엔드포인트
scrape_interval: 10s # 얼마의 텀으로 메트릭 정보를 가져올 것인지. 운영 서버라면 보통은 10초~1분을 추천한다. 너무 자주하면 성능에 영향을 주겠지?
scheme: https # https 사용
static_configs:
- targets: ['[내 서비스 도메인]:9097'] # 메트릭을 가져올 타겟 ip와 포트
tls_config: # tls 설정 구성
insecure_skip_verify: true # SSL 인증서 검증 skip이제 해당 prometheus.yml을 가져가서 실행하도록 하면 된다.
sudo docker run \
--name prometheus -d \
--restart=unless-stopped \
-p 9098:9090 \
-v [서버에 prometheus.yml이 있는 경로]/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheusprometheus는 디폴트 포트가 9090이다. 하지만 현재 회사의 서비스에서 9090포트가 사용중이라 9098포트를 컨테이너의 9090포트에 맵핑해서 접근할 수 있게 했다.
물론 이 과정에서 prometheus가 Actuator를 잘 물고 있는지 확인하려면 AWS의 인바운드 규칙을 풀어서 확인해봐야 한다. 확인이 끝나면 외부에서 접근할 필요 없이 서버 내부 통신만 하면 되므로 인바운드 규칙을 수정해주자.
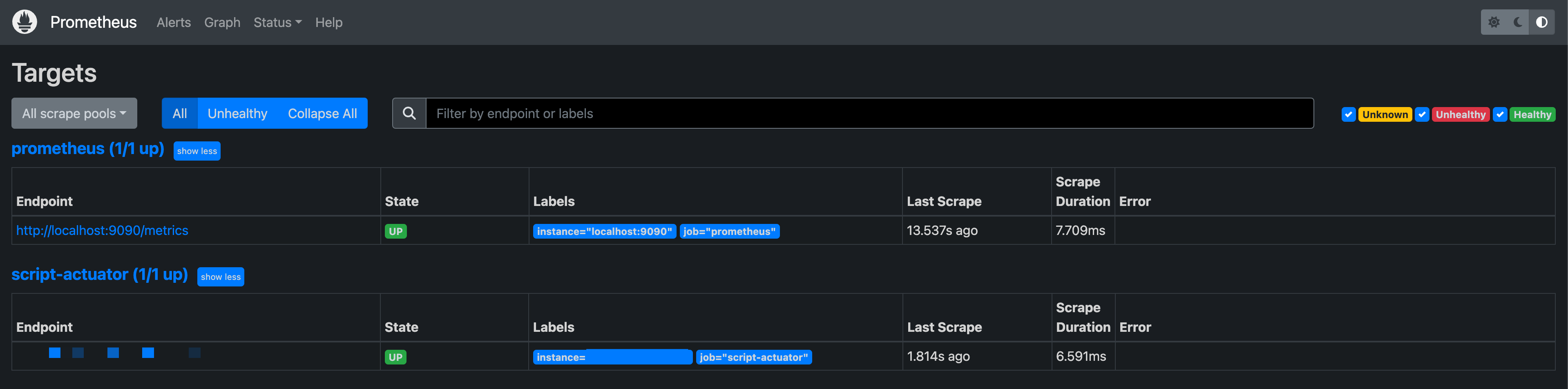
이제 prometheus로 애플리케이션의 메트릭 정보를 수집하고 조회할 수 있게 됬지만 여전히 한눈에 알아보기 힘든 형식인 것은 마찬가지이다. 이 데이터를 표와 그래프로 보기 쉽게 표시하도록 해보자.
Grafana
Grafana는 오픈소스 데이터 시각화 및 대시보드 툴이다. 데이터 소스로부터 데이터를 쉽게 가져와 대시보드를 만들 수 있으며, 그래프, 테이블, 알림 등 다양한 시각화 도구를 제공한다.
시간 범위 선택, 그래프 타입 선택, 템플릿 변수 설정 등이 가능합니다. 또한, 대시보드에서 발생하는 이벤트에 대한 알림을 설정할 수 있다. 예를 들어 CPU 사용률이 일정 이상 올라갈 경우 메일이나 슬랙으로 알림을 받을 수 있다는 것이다!
즉, 서버 모니터링에 적합한 툴인 것이지.
Grafana도 prometheus와 마찬가지로 docker 컨테이너로 올릴 것이므로 이미지를 받아오자.
sudo docker pull grafana/grafana그리고 컨테이너 실행.
sudo docker run \
--name grafana -d \
--restart=unless-stopped \
-p 9099:3000 \
grafana/grafanaGrafana의 디폴트 포트는 3000번이다. 컨테이너의 3000포트를 서버의 9099포트와 맵핑시켜 9099로 접근할 수 있도록 하겠다.
AWS의 인바운드 규칙에서 Grafana 대시보드를 볼 수 있도록 9099포트를 열어주면 되는데, 위에 Actuator 보안에서 언급했듯이 Actuator의 엔드포인트는 함부로 접근할 수 있게 하면 안되기 때문에 회사 내부 ip로만 접속할 수 있도록 설정하는 것이 좋다.
인바운드 규칙을 정리하면
- 9097 : 애플리케이션 Actuator 포트. 서버 내부에서 Prometheus 컨테이너만 접근할 수 있도록 설정한다.
- 9098 : Prometheus 포트. 서버 내부에서 Grafana 컨테이너만 접근할 수 있도록 설정한다.
- 9099 : Grafana 포트. 회사 내부 ip로만 접근할 수 있도록 설정한다.
'[인스턴스 ip]:9099'로 Grafana에 접근해보면 로그인 화면이 나오게 된다.
디폴트 계정은 admin/admin이다. 디폴트 계정을 사용하는 것도 보안에 좋지 않으므로 계정 정보는 알아서 바꿔주자.
Grafana 대시보드 설정하기
-
로그인을 하게되면 좌측 하단에 설정 버튼을 누르고 Configuration으로 이동한다.
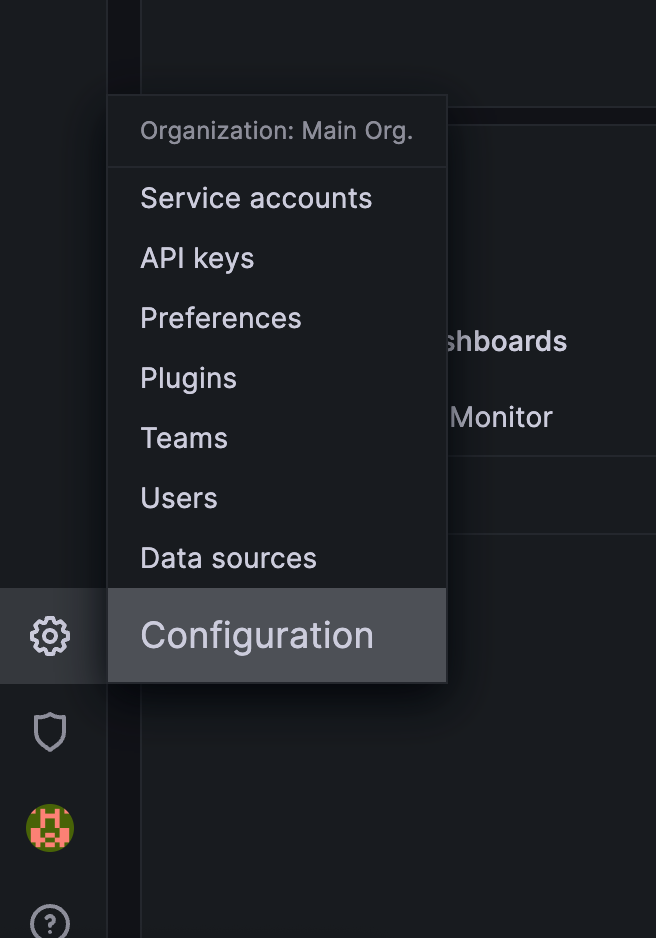
-
prometheus datasource를 설정하는 탭이 보일텐데 선택을 해서 들어가면 URL을 입력하는 칸이 있다. 이곳에 prometheus의 URL을 입력해주고 저장하면 된다.
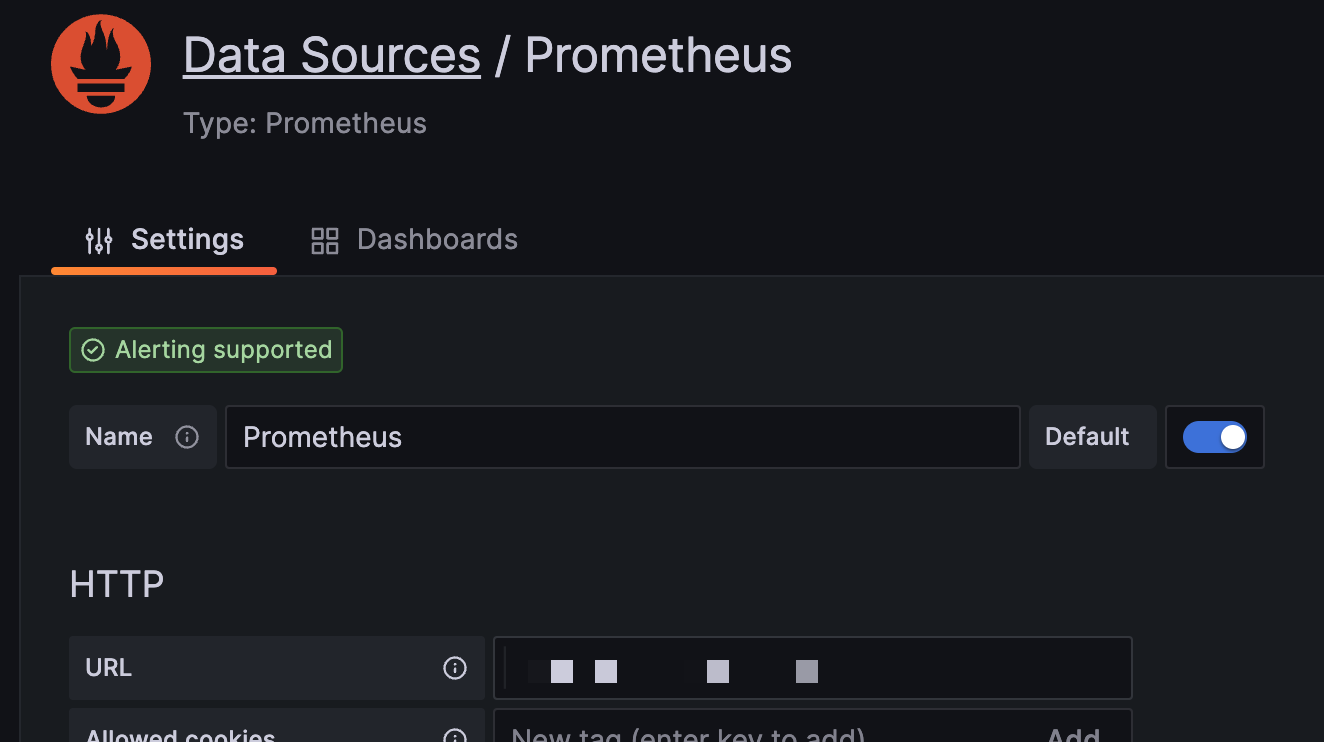
-
좌측 상단에 그리드 모양 버튼을 누르고 Dashboard로 이동한다.
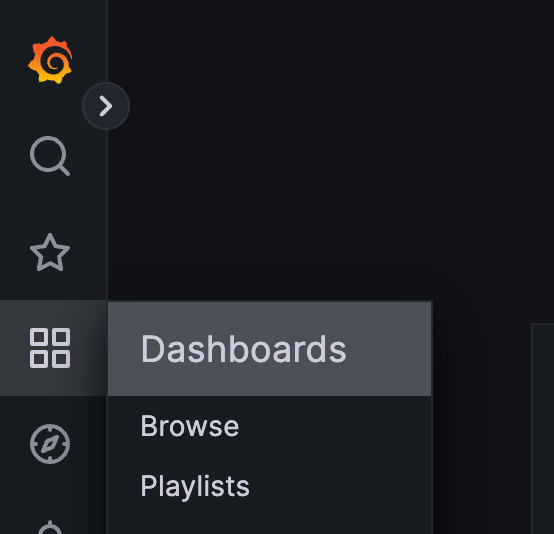
-
Grafana는 대시보드를 직접 만들어서 사용해도 되지만, 이미 만들어져 있는 템플릿을 가져와서 사용할 수도 있다. Spring용 대시보드는 잘 만들어진게 많으므로 가져와 사용해봐도 좋다. 오른쪽에 new 버튼을 누르고 import를 선택하자.
- Grafana Labs - Dashboards 이곳에 있는 여러 대시보드를 가져올 수 있는데 마음에 드는 대시보드의 id를 카피해서 넣어주고 datasource로 우리 prometheus를 선택해준다.
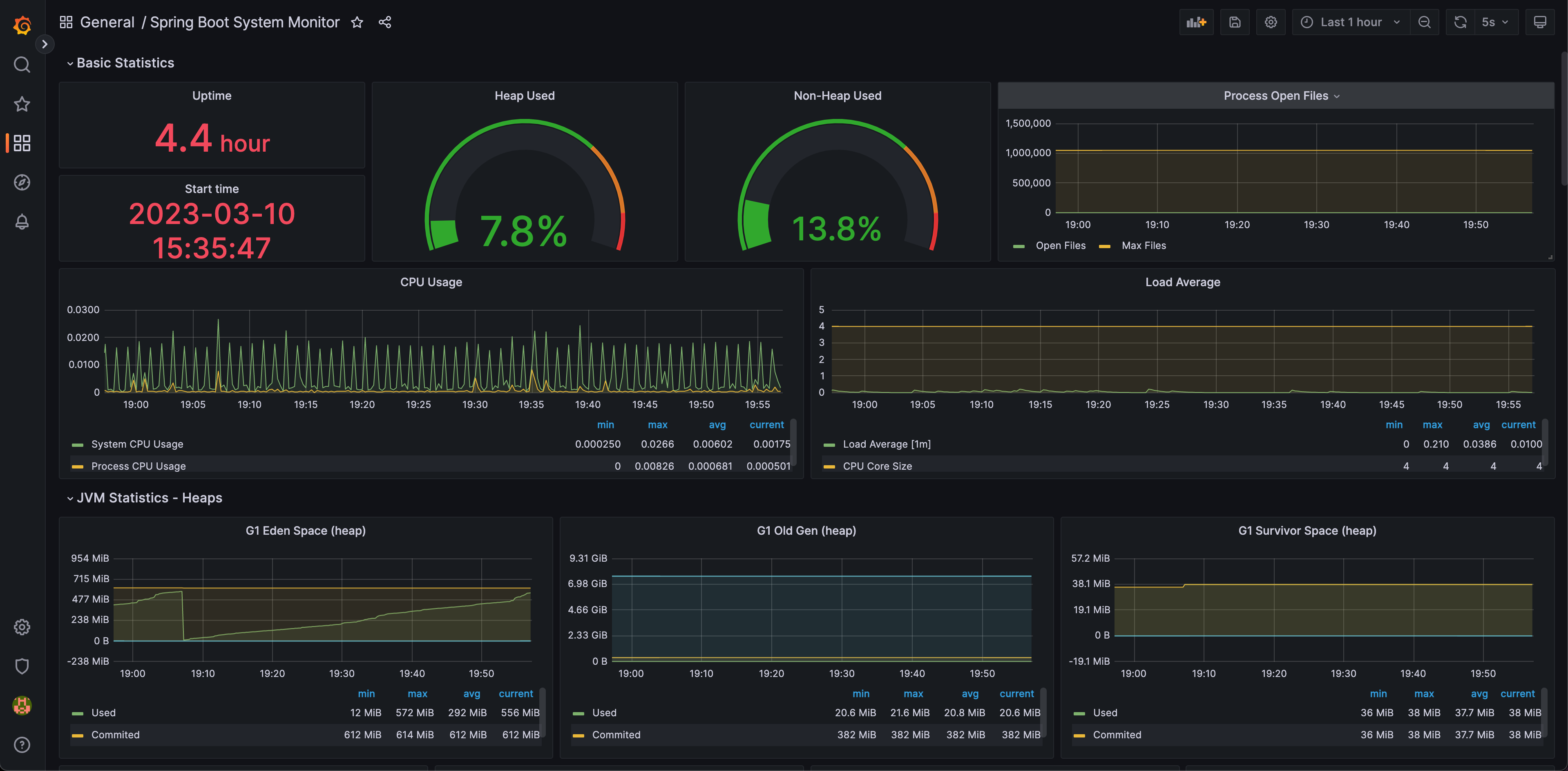
스프링 모니터링 대시보드 완성!
prometheus 쿼리와 grafana 대시보드 사용법을 공부하면 나만의 메트릭을 확인할 수 있는 보드도 만들 수 있다.
이제 이 애플리케이션 대시보드를 확인하면 서버 장애 징후를 확인할 수도 있고, 장애가 난 후 확인을 하더라도 어느 부분에서 장애가 났는지 더 짐작하기 쉬울 것이다.
하지만 하루종일 대시보드만 모니터링 할 수는 없는 일...
게다가 업무시간 이외에도 내가 퇴근했을 때, 휴일에도 장애 징후는 나타날 수 있다.
그래서 다음 Grafana 게시글에는 중요 메트릭 정보가 특정 지점을 초과했을 때 알람을 보내는 기능을 다뤄볼 것이다!
