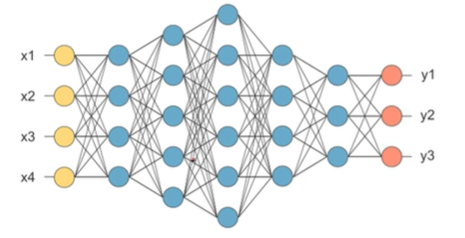
Neural Network
- 입력,은닉,출력층으로 구성된 모형
- 각 층을 연결하는 노드의 가중치를 업데이터하며 학습
- overfitting이 심하게 일어나고, 학습 시간이 매우 오래 걸림
Deep Learning
- 다층의 layer 통해 복잡한 데이터 학습이 가능토록 함
- 알고리즘 및 GPU의 발전이 deep learning의 부흥을 이끔
- 다양한 형태로 발전 (CNN,RNN,AutoEncoder 등)
- AutoEncoder : x를 갖고 x를 예측해서 새로운 변수(특징) 추출 (unsupervised learning)
- 다양한 분야로 발전
- image Resolution(해상도 복원)
- style transfer (스타일 전환)
- colorization (색 변환) 등)
- object detection(객체 판별)
- 네트워크 구조의 발전
- ResNET- DenseNET
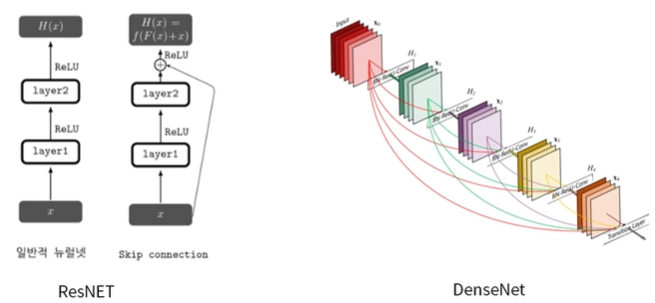
- DenseNET
- 네트워크 초기화 기법
- Xavier- he initialization
- 다양한 activaion function (ReLu, ELU, SeLU, Leaky ReLU 등)
- Generalization, overfitting 문제
- Semi-supervised learning, Unsupervised learning
GAN (Generative Adversarial Network)
-
Data를 만들어내는 Generator와 만들어진 data를 평가하는 Discriminator가 서로 대립(Adversarial)적으로 학습해가며 성능을 점차 개선해 나가자는 개념
-
생성 모델
-
Discriminator를 학습시킬 때에는 D(x):진짜데이터 가 1이 되고 D(G(z)):가짜데이터 가 0이 되도록 학습시킴
(진짜 데이터를 진짜로 판별하고, 가짜 데이터를 가짜로 판별할 수 있도록) -
Generator를 학습시킬때에는 D(G(z))가 1이 되도록 학습시킴
(가짜 데이터를 discriminator가 구분 못하도록 학습, discriminator를 헷갈리게 하도록)
=> 서로 대립적으로 학습하며 성능이 개선되며, Generator는 결국 진짜 같은 가짜 데이터를 만들어 discriminator가 분류할 수 없도록 만듬
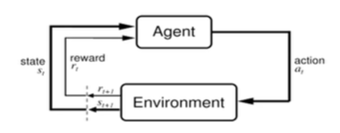
강화학습 (Reinforcement Learning)
-
현재 상태에서 먼 미래까지 어떤 액션을 취해야 큰 보상을 받을 수 있을까
-
Q-learning
: 현재 상태에서부터 먼 미래까지 가장 큰 보상을 얻을 수 있는 행동을 학습하게 하는 것.
-
Q-learning + Deep learning : DQN (Deep Reinforcement Learning) : 잘안씀
-
더 효율적으로 빠르게 학습 할 수 있는 강화학습 모델 연구 ing
-
Action이 continuous한 경우 (실수값) 어떻게 해야 학습이 잘되는가?
-
Reward가 매우 sparse(희박)한 경우
-
Multi agent 강화학습 모델의 경우

[Data Science] 차근차근 쌓아나가는