Machine Learning
1.Machine Learning의 종류
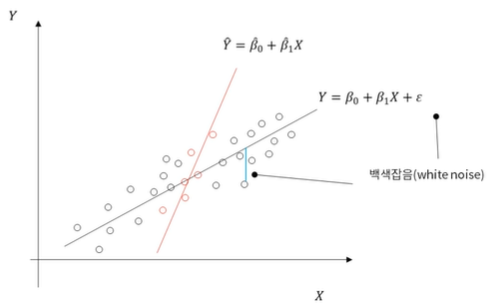
독립 변수와 종속 변수가 선형적인 관계까 있다는 가정 하에 분석직선을 통해 종속 변수를 예측하기 때문에 독립변수의 중요도와 영향력을 파악하기 쉬움독립변수 조건에 따라 종속변수 분리이해하기 쉬우나 overfitting 잘일어남새로 들어온 데이터의 주변 k개의 데이터의 c
2.[ML] 과적합(Overfitting)과 규제(Regularization)
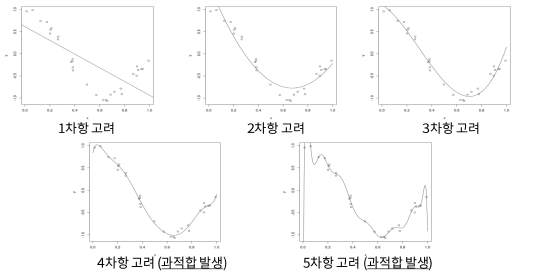
\-모델이 train 데이터에 지나치게 적응되어 그 외 데이터에는 대응하지 못하는 상태.EX) 아래와 같은 회귀 문제에서, 두번째 모델이 최적의 모델이다1\. 첫번쨰 모델 : 과소적합(Underfitting), 주어진 데이터를 아직 제대로 반영하지 못함.2\. 두번쨰
3.[ML] K-NN (K-최근접 이웃)알고리즘
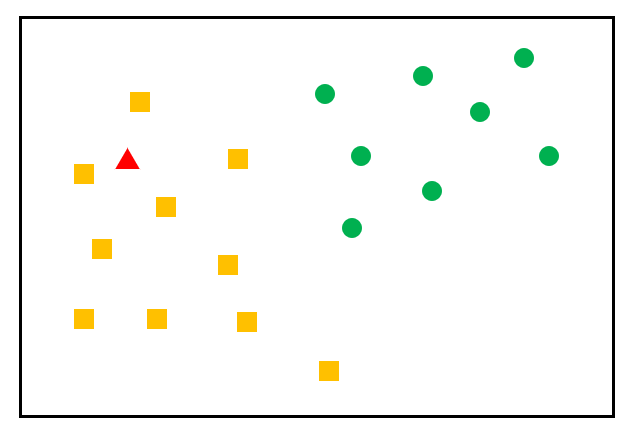
K-최근접 이웃 (K-NN, K-Nearest Neighbot) 알고리즘분류 (Classification)지도학습비슷한 특성을 가진 데이터는 비슷한 범주에 속하는 경향이 있다는 가정주변의 가장 가까운 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘가장 가까
4.[ML] 주성분 분석(PCA)에 대한 이해

1. 차원 축소 밑의 데이터는 외출 활동이 좋은지 아닌지 분류하는 모델을 만들고자 할때, 날씨 데이터의 Feature가 101가지로 들어온 데이터다. 이는 101차원의 데이터와 같은 의미다. 
Feature selection은 모델링 시 raw data의 모든 feature를 사용하는 것은 computing power와 memory 측면에서 매우 비효율적이기 때문에일부 필요한 feature만 선택하는 방법ㅣ다.유사하지만 다른 표현의 3가지 feature 처리
6.[ML] 머신러닝에서의 다중공선성 문제 (작성중)
다중공선성 문제 독립 변수 간 상관관계가 매우 높을 때, 하나의 독립변수의 변화가 다른 독립변수에 영향을 미쳐 모델이 불안정해지는 것을 의미한다. Reference https://velog.io/@jkl133/%EB%8B%A4%EC%A4%91%EA%B3%B5%EC%8