
정적 크롤링과 동적 크롤링
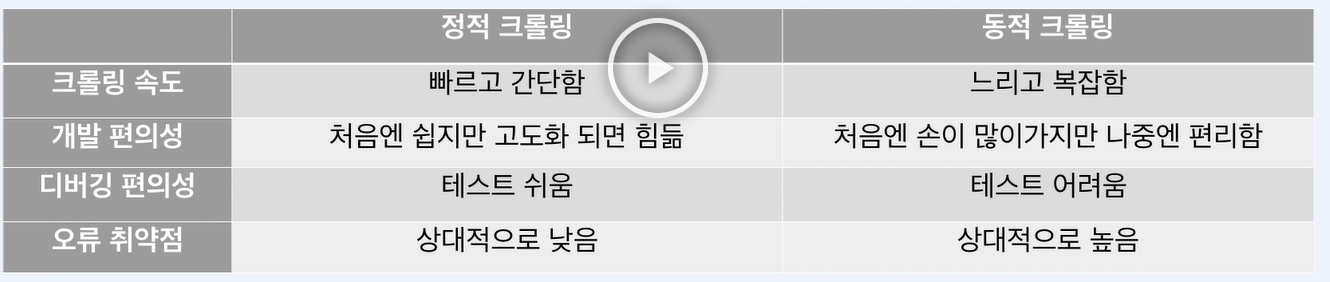
동적 크롤링에는 수많은 복병이 존재한다. 자동화함에 있어서 걸림돌이 있을 수 있다. 정적 클롤링에서 가져오지 못한 데이터들이 있다. 브라우저에서 연산이 필요한 경우가 있는데 이때는 정적 크롤링이 한계가 있다.
request 라이브러리
1)
requests 라이브러리를 pip install requests후,
import requests
res = requests.get("https://www.naver.com/")
print(res.text)
###
# GET : 요청, 값 가져오는 역할
# POST : 생성, 액션
# PUT : 수정
# DELETE : 삭제 실행시키려고 하니, modulenotfounderror가 떴다. 그래서 python3 -m pip install requests를 하니 다시 설치가 되었다.
--> 결과는, 네이버 사이트의 html 코드가 콘솔창에 나왔다.
2) ip 주소 알기
import requests as req
res = req.get("https://api.ipify.org/")
print(res.request.method) # GET
print(res.status_code) # 200
print(res.text) # 115.136.249.39-> res.text를 하면 html 문서가 나와야 하는데 ip 주소 값만 나온다. 왜? 서버가 응답해주는 값은 ip 주소 뿐인데, 브라우저가 알아서 유저에게 보여주기 위해 html 코드로 꾸미는 것이다.
환율 가져오기
requests 활용한 기초적인 파싱
find(), split() 등을 활용한 기초적인 문자열 파싱
정규식(regex)를 활용한 패턴 검색
쿼리스트링에대한 이해
beautifulsoup를 활용한 편리한 html 파싱
css selector를 활용한 손쉬운 파싱
1) split()을 활용하여 환율 정보 가져오기
import requests as req
res = req.get('https://finance.naver.com/marketindex/?tabSel=exchange#tab_section')
html = res.text
s = html.split('<span class="value">')[1].split('</span>')[0]
print(s)
👉html 코드에서 환율 정보가 든 앞/뒤 부분을 split()하여 가져온다.
✔ find()는 특정 텍스트가 들어있는지 아닌지를 확인할 때에 유용하게 사용된다.
2) 정규식을 활용하여 환율 가져오기
- 정규식
import re
s = 'hi'
# match(r'a',b) : a가 b랑 얼마나 일치하는지 확인
print(re.match(r'hi',s))
##### .은 '아무거나'의 의미로 무엇이든 일치한다. '.' 한 개당 한 글자를 의미
print(re.match(r'h.',s)) # <re.Match object; span=(0, 2), match='hi'>
print(re.match(r'..',s)) # <re.Match object; span=(0, 2), match='hi'>
print(re.match(r'.',s)) # <re.Match object; span=(0, 1), match='h'>
##### *은 자기 앞에 있는 문자가 0개 이상일 수 있다는 의미
print(re.match(r'hi1*',s)) # <re.Match object; span=(0, 2), match='hi'>
##### *은 자기 앞에 있는 문자가 1개 이상일 수 있다는 의미
print(re.match(r'hi1+',s)) # None
s2 = 'color'
##### ?은 자기 앞에 있는 문자가 없을수도 있다는 의미
print(re.match(r'colou?r',s2)) # <re.Match object; span=(0, 5), match='color'>
s3 = 'how are you?'
print(re.match(r'how are you?',s3)) # <re.Match object; span=(0, 11), match='how are you'>
###### \은 정규식에 사용되는 특수기호들을 무효화 시킨다.
print(re.match(r'how are you\?',s3)) # <re.Match object; span=(0, 12), match='how are you?'>
s4 = '이 영화는 A등급입니다.'
###### []은 그 안에 있는 것중 아무거나 다 가능하다는 의미이다.
print(re.match(r'이 영화는 [ABCF]등급입니다.',s4)) # <re.Match object; span=(0, 13), match='이 영화는 A등급입니다.'>
##### ()은 그 안에 있는 것을 캡처한다는 의미이다.
print(re.findall(r'이 영화는 (.)등급입니다.', s4)) # ['A']
print(re.findall(r'이 영화는 ([ABCF])등급입니다.', s4)) # ['A']
- 정규식을 활용해서 환율 가져오기
import requests as req
import re
url = 'https://finance.naver.com/marketindex/?tabSel=exchange#tab_section'
res = req.get(url)
body = res.text
# 정규식을 준비
# DOTALL은 줄바꿈도 포함한다는 의미
# ?가 *과 함께 쓰이면 가장 좁은 범위를 가져온다는 의미
r = re.compile(r"h_lst.*?blind\">(.*?)</span>.*?value\">(.*?)</", re.DOTALL)
captures = r.findall(body)
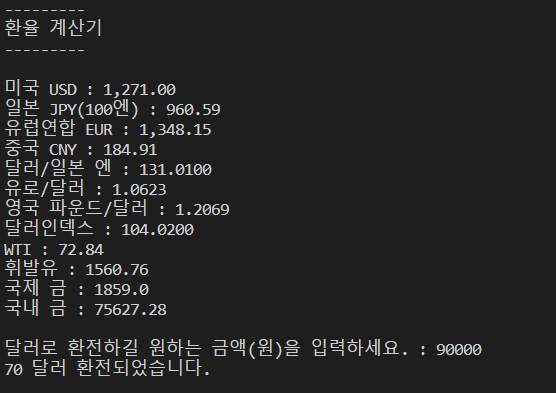
print("---------")
print("환율 계산기")
print("---------")
print("")
for c in captures:
print(f"{c[0]} : {c[1]}")
print()
usd = float(captures[0][1].replace(",",""))
won = int(input("달러로 환전하길 원하는 금액(원)을 입력하세요. : "))
dollar = int(won / usd)
print(f"{dollar} 달러 환전되었습니다.")
3) beautiful soup
- 기본 사용
from bs4 import BeautifulSoup as BS
import requests as req
url = 'http://naver.com'
res = req.get(url)
soup = BS(res.text, "html.parser")
print(soup.title) # <title>NAVER</title>
print(soup.title.string) # NAVER- 사용 예
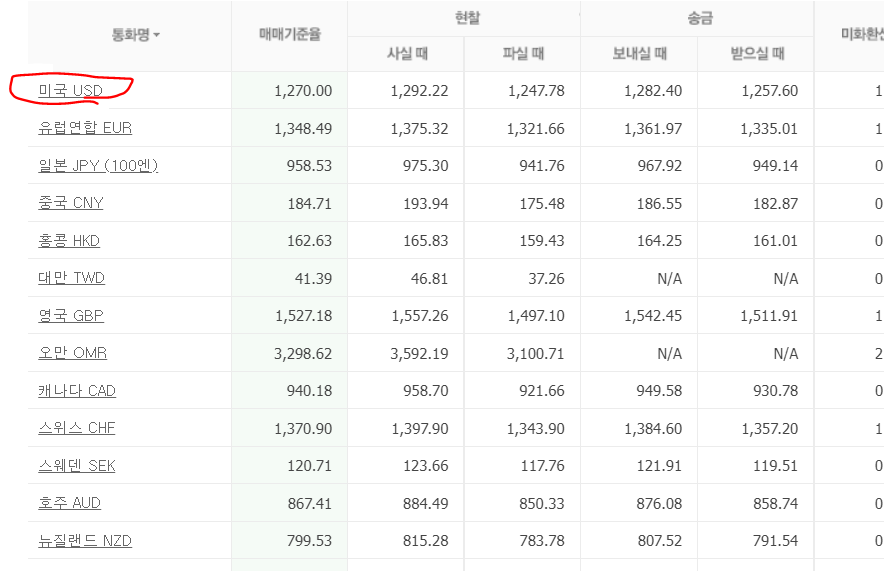
이 부분을 가져오기 위해 td 태그를 가져왔다.
from bs4 import BeautifulSoup as BS
import requests as req
url = "https://finance.naver.com/marketindex/?tabSel=exchange#tab_section"
res = req.get(url)
soup = BS(res.text, "html.parser")
tds = soup.find_all("td")
print(tds) 
👉 하지만, 원하는 부분을 가져오지 못했다. 왜? 한 페이지더라도 여러개의 html파일이 존재할 수 있다. 그래서, iframe 태그를 찾아보니 이에 대한 src를 찾아 url에 입력하였다. /marketindex/exchangeList.naver --> 이 부분은 절대경로 뒤에 붙여주면 된다.
---> https://finance.naver.com/marketindex/exchangeList.naver
from bs4 import BeautifulSoup as BS
import requests as req
url = "https://finance.naver.com/marketindex/exchangeList.naver"
res = req.get(url)
soup = BS(res.text, "html.parser")
tds = soup.find_all("td")
print(tds) - 환율 가져오기
from bs4 import BeautifulSoup as BS
import requests as req
url = "https://finance.naver.com/marketindex/exchangeList.naver"
res = req.get(url)
soup = BS(res.text, "html.parser")
tds = soup.find_all("td") # find_all은 list로 반환
names = []
for td in tds:
if len(td.find_all("a")) == 0 :
continue # 다음 td로 넘어간다.
# print(td.string) # 공백 포함
names.append(td.get_text(strip=True)) # 공백 제거
prices = []
for td in tds:
if "class" in td.attrs:
if "sale" in td.attrs["class"]:
prices.append(td.get_text(strip=True))
print(names)
print(prices)
- css selector를 이용하여 환율 가져오기
from bs4 import BeautifulSoup as BS
import requests as req
url = "https://finance.naver.com/marketindex/exchangeList.naver"
res = req.get(url)
soup = BS(res.text, "html.parser")
tds = soup.find_all("td") # find_all은 list로 반환
names = []
for td in soup.select("td.tit"):
names.append(td.get_text(strip=True))
prices = []
for td in soup.select("td.sale"):
prices.append(td.get_text(strip=True))
print(names)
print(prices)
출처 : 패스트캠퍼스 Python&Django로 시작하는 웹 프로그래밍
