📚 데이터 파이프라인을 설계하고 구축할 때 일반적으로 ETL과 ELT가 사용되게 되는데 ETL과 ELT의 개념에 대해 정리하고 실제 데이터 웨어하우스에서 데이터를 로드하는 과정과 데이터 레이크가 포함되었을 때 ETL과 ELT의 과정이 어떻게 되는지를 정리해 보았다.
먼저 ETL과 ELT에 대한 설명에 들어가기에 앞서 각각 E, T, L의 개념을 정리해 보자.
Extract: 외부의 데이터 소스에서 데이터를 추출하는 단계Transform: 데이터 포맷을 원하는 형태로 변환Load: 변환된 데이터를 최종적으로 데이터 웨어하우스에 적재- 이 하나의 과정을 데이터 파이프라인이라고 부르기도 한다.
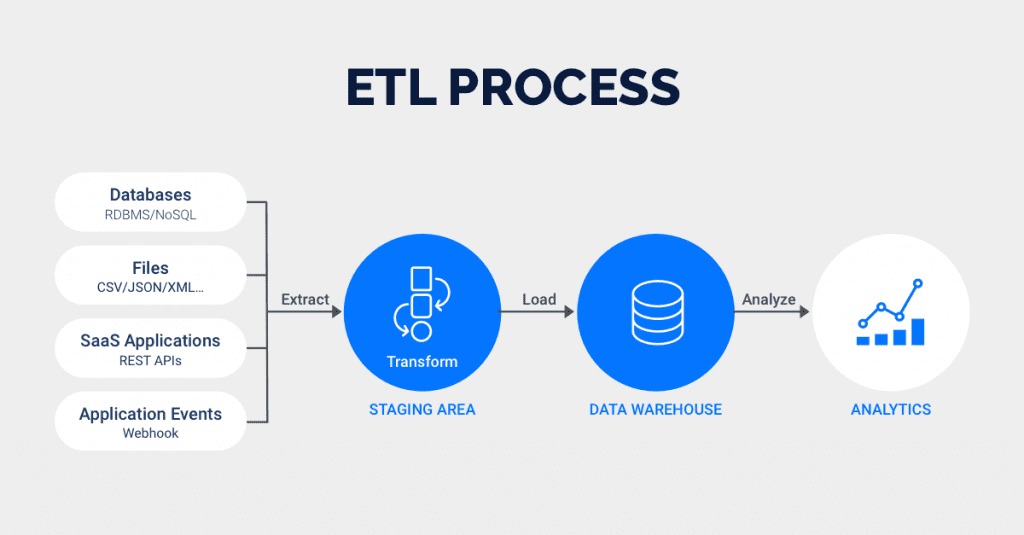
1. ETL (Extract, Transform, Load)
(사진 출처: https://rivery.io/blog/etl-vs-elt/)
-
외부에 있는 데이터를 가져다 데이터 웨어하우스에 로드하는 작업
-
일반적인 단계는
- 외부의 데이터를 스테이징 영역에 추출해 준 후(Extract)
- 해당 데이터를 변환해(Transform)
- 데이터 웨어하우스에 로드(Load)
-
ETL의 수는 회사의 성장에 따라 쉽게 100+ 개 이상으로 발전 -
중요한 데이터를 다루는
ETL이 실패했다면 빨리 수정해 다시 실행하는 것이 중요하다. -
ETL을 적절하게 스케줄하고 관리하는 것이 중요해지면서ETL 스케줄러혹은프레임워크가 필요해진다. -
가장 많이 사용되는 프레임워크는
AirflowAirflow는 오픈 소스 프로젝트Python 3기반AWS와구글 클라우드에서도 지원
-
ETL관련 SaaS(Software as a Service)도 출현하기 시작
- 아직까지 기능이 강력하지 않음
- FiveTran, Stitch Data 등
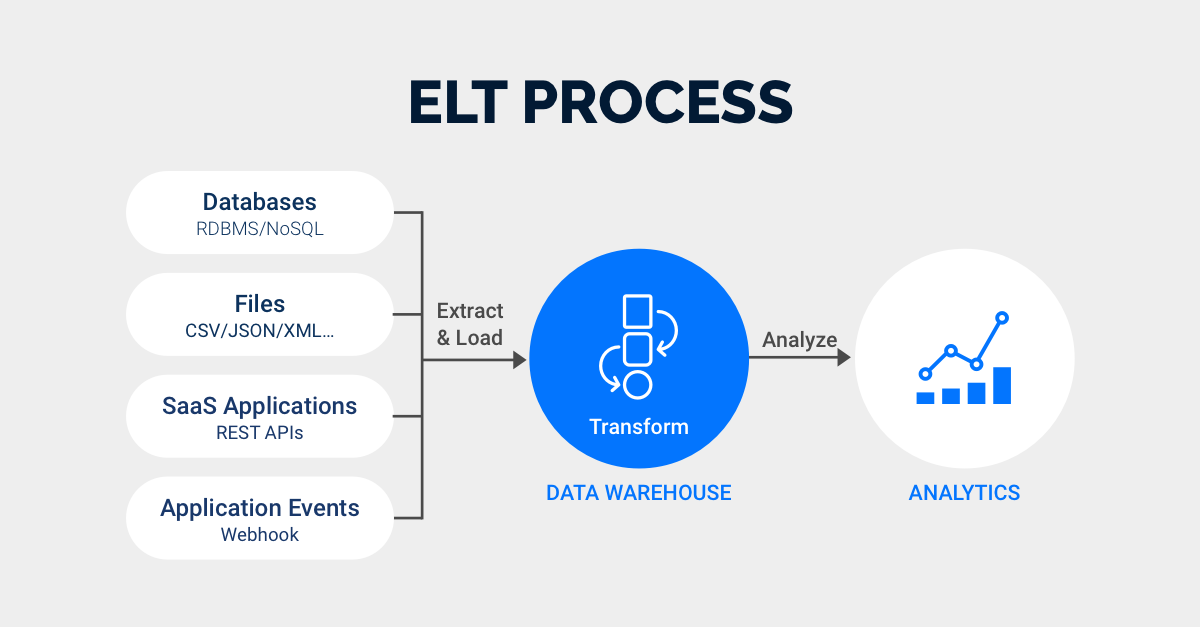
2. ELT (Extract, Load, Transform)
(사진 출처: https://rivery.io/blog/etl-vs-elt/)
-
데이터 웨어하우스 내부 데이터를 조작해 보통은 조금 더 추상화되고 요약된 새로운 데이터를 만드는 프로세스를 말한다.
-
일반적인 단계는
- 외부의 데이터를 스테이징 영역에 추출해 준 후(Extract)
- 데이터 웨어하우스에 로드(Load)
- 해당 데이터를 변환해(Transform) 다시
데이터 웨어하우스에 저장하거나 분석에 사용
-
ELT의 과정은 왜 필요해지는가?ETL은 다양한 데이터 소스를 읽어오는 일을 수행하지만 이를 모두 이해해 조인해 사용하는 것은 데이터가 다양해지고 커지면 불가능해진다.- 그렇기 때문에 주로 요약 데이터를 만들어 사용하는 것이 더 효율적인데 이때 사용하는 기술이
DBT가 되며, 이를ELT라고 부른다.
-
Airflow를 통해 스케줄링은 하지만 새로운 데이터를 만들 때는DBT라는 툴을 많이 쓴다. -
보통
데이터 분석가들이 수행한다. -
상황에 따라 데이터 파일이 로그 파일이라면
데이터 레이크를 사용하기도 한다.
📌 특정 ETL, ELT가 실패했을 때 나중에 그 원인을 분석하고 재실행해 주어야 하는 것을 Backfill이라고 부름. (데이터 엔지니어에게는 악몽) -> Backfill을 좀 더 쉽게 해결할 수 있도록 도와주는 것이 Airflow
3. 데이터 웨어하우스의 일반적인 데이터 파이프라인

-
다음과 같이 다양한 외부 데이터들을
ETL을 통해데이터 웨어하우스로 적재해 준다. -
이후
Airflow를 통해ELT과정으로 요약 테이블을 만들어 다시데이터 웨어 하우스에 요약 데이터를 적재해 준다. -
이때 외부 데이터에
로그 파일이 있는 경우에는데이터 레이크를 파이프라인에 추가해 주어야 한다.
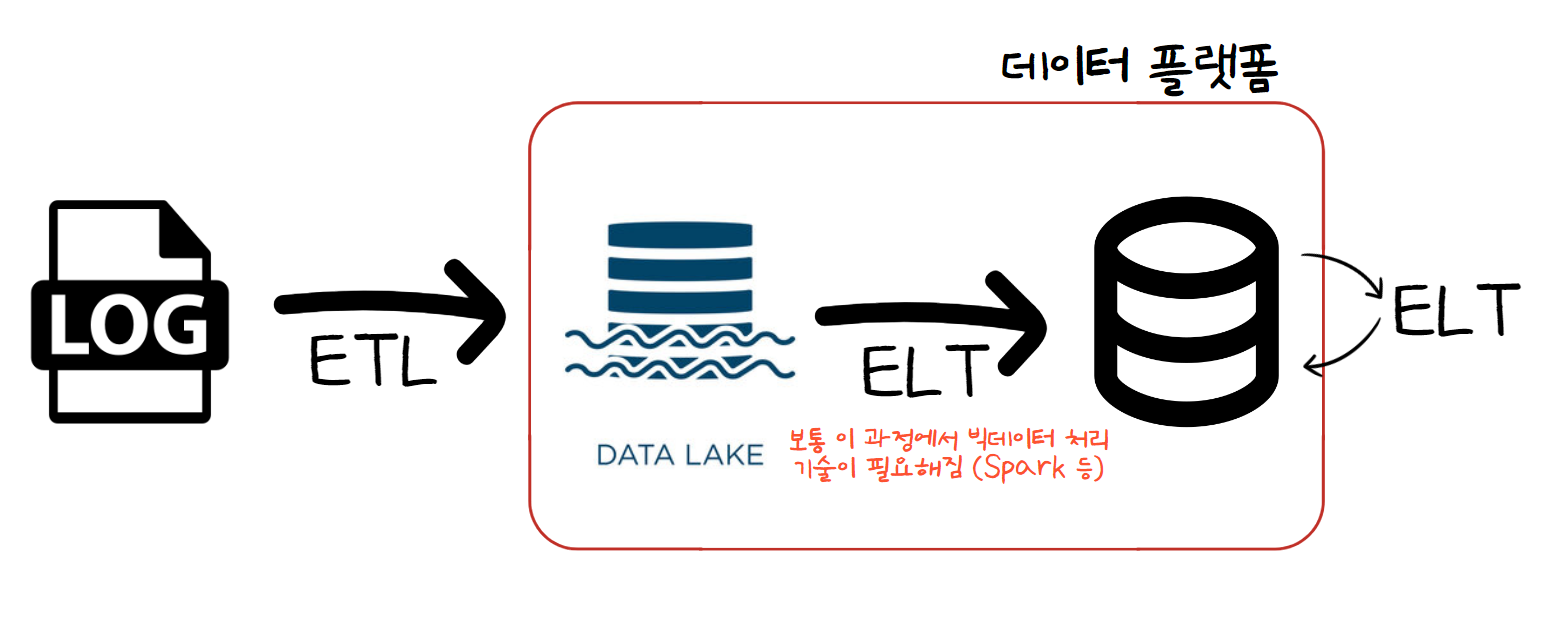
4. 데이터 레이크가 포함된 데이터 플랫폼 아키텍처
-
로그 파일은 크기가 크고 비구조화된 데이터기 때문에 다음과 같이 스토리지에 가까운 데이터 레이크를 두고, 하루에 한 번 혹은 한 시간에 한 번씩 데이터를 ETL해 두는 게 일반적이다. -
그리고 이 데이터를 사용하기 쉽게 요약하여
데이터 웨어하우스에 적재하거나데이터 웨어하우스의 데이터를 다시 요약하여 적재하기도 한다. 이 과정이 ELT이다. -
데이터 레이크에 굉장히 큰 로그 파일들이 적재되게 되면데이터 레이크에서데이터 웨어하우스로 ELT 해 줄 때Python만으로 프로세싱이 되지 않는 경우가 많다. 시간이 오래 걸리거나 메모리 초과가 되거나 이슈들이 발생할 수 있다. -
이런 로그 파일을 처리하기 위해 빅데이터 처리 프레임워크들이 필요하게 된다. 대표적인 것으로는 Spark가 있다.
-
하지만 ETL, ELT를 처리해 주는 프레임워크로는
Airflow를 사용해 준다.
📌 빅데이터 처리 프레임워크
- 분산 환경 기반 (1 대 혹은 그 이상의 서버로 구성)
- 분산 파일 시스템(큰 데이터를 저장할 수 있는 방법 필요)과 *분산 컴퓨팅 시스템(큰 데이터를 읽어서 프로세싱하고 새로운 데이터를 쓰는 기술 필요)이 필요하다.
- Fault Tolerance: 소수의 서버가 고장이 나더라도 동작되어야 한다.
- Replication Factor: 데이터가 있다면 한 서버에만 저장하는 게 아니라 비상 상황에 대비해 여러 서버에 저장하게 된다.
- Replication Factor는 보통 3으로 구성되어 있다.
- 확장이 용이해야 한다. 이를 Scale Out이라고 부르며 용량을 증대하기 위해서는 서버 추가를 해 주어야 한다.
- Scale Up은 서버의 사양을 높이는 것을 말한다. Scale Up + Scale Out을 병행하기도 한다.
📌 대표적 빅데이터 처리 프레임워크
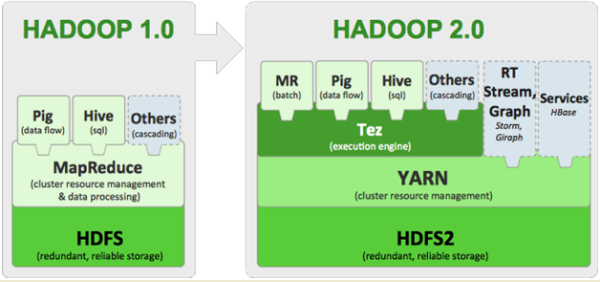
- 1 세대 -> 하둡 기반의 Mapreduce, Hive/Presto (SQL 기반) 하둡에서는 분산 파일 시스템을
HDFS을 사용- 2 세대 -> Spark (SQL, DataFrame, Streaming, ML, Graph) 하둡에서
HDFS, AWS에서는S3사용

This web site definitely has all of the information and facts I needed concerning this subject and didn’t know who to ask.
https://infocampus.co.in/ui-development-training-in-bangalore.html
https://infocampus.co.in/web-development-training-in-bangalore.html
https://infocampus.co.in/mern-stack-training-in-bangalore.html
https://infocampus.co.in/reactjs-training-in-marathahalli-bangalore.html
https://infocampus.co.in/javascript-jquery-training-in-bangalore.html
https://infocampus.co.in/data-structure-algorithms-training-in-bangalore.html
https://infocampus.co.in/angularjs-training-in-bangalore.html
https://infocampus.co.in/
https://infocampus.co.in/web-designing-training-in-bangalore.html
https://infocampus.co.in/front-end-development-course-in-bangalore.html