
📚 오늘 공부한 내용
1. 구글 시트 및 슬랙 연동
1) docker-compose.yaml 설정
-
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.5.1/docker-compose.yaml'해당 명령어를 사용해 주면 docker-compose.yaml의 기본 파일을 끌고 올 수 있다. -
_PIP_ADDITIONAL_REQUIREMENTSenvironment구성 중_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- }를 수정해 준다.-뒤에 docker 실행 시 다운로드 받을 모듈들을 입력해 준다.-는_PIP_ADDITIONAL_REQUIREMENTS가 존재한다면 이 환경 변수의 내용을 사용해 주고 이 환경 변수의 내용이 존재하지 않는다면 Container가 실행될 때-뒤에 있는 모듈들을 환경 변수로 사용하라는 뜻이다._PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- yfinanace pandas numpy oauth2client gspread}
-
volumes- 볼륨을 추가해 주기 위해서
- ${AIRFLOW_PROJ_DIR:-.}/data:/opt/airflow/data해당 내용을 추가해 준다. - 기본 볼륨이 있지만 추가해 주고 싶다면 호스트 폴더에서 임시 데이터를 저장할 한 폴더를 만들고 해당 폴더 위치로 볼륨을 지정해 주면 된다.
- 이때
airflow-init부분도 수정이 되어야 하는데data부분을 추가해 주어야 한다.mkdir -p /sources/logs /sources/dags /sources/plugins/sources/datachown -R "${AIRFLOW_UID}:0" /sources/{logs,dags,plugins, data}
- 볼륨을 추가해 주기 위해서
2) docker-compose 실행
docker compose up -d-d옵션 사용 시 detach 모드로 실행된다.- detach 모드로 실행되면 바로 command line으로 빠져나오면서 docker와 관련된 내용이 백그라운드에서 실행된다.
- 만약 docker compose 말고 다른 이름을 사용했다면
-f로 지정해 주어야 한다.
3) Airflow 사용
- http://localhost:8080 웹 UI로 로그인을 한다.
- 이때 airflow:airflow 계정을 사용한다.
- DATA_DIR라는 변수는 Variables에서는 보이지 않는다.
- 환경 변수로 설정한 것은 Web UI에서는 확인할 수 없지만 프로그램에서는 사용 가능하다.
docker exec -it airflow_scheduler_container_name airflow variables get DATA_DIR- /opt/airflow/data (앞서 설정한 것을 확인할 수 있다.)
4) 어느 Workspace의 어느 Channel로 보낼 것인지 설정
- prgms-de라는 Workspace 밑에 DataAlert이라는 APP을 생성한다.
- 이 APP이 #data-alert이라는 채널에 메시지를 보낼 수 있게 설정한다.
- Incoming Webhooks App 설정
Webhooks을 생성하면 Sample Url이 나오게 된다.curl -X POST -H 'Content-type: application/json' --data '{"text":"Hello, World!"}' https://hooks.slack.com/services/slack_link_endpoint
5) WebHook 연결
WebHook생성 시 나온 Endpoint 주소를slack_url이라는 Variable로 저장한다.- slack에 에러 메시지를 보내는 별도 모듈로 개발한다. (slack.py)
- DAG 인스턴스를 만들 때 에러 콜백을 지정해 준다.
on_failure_callback에 slack 호출을 해 준다.
dag = DAG(
dag_id = 'name_gender_v4',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
'on_failure_callback': slack.on_failure_callback, #slack_callback 호출
}
)2. Airflow 실행 환경 관리 방안
- 기타 환경 설정 값 (Variables, Connections 등)을 어떻게 관리 및 배포할까?
- 보통
docker-compose.yml파일 아래서 정의된다. docker-compose.yml이 어디에 저장되느냐에 따라 관리 포인트가 달라지게 된다.- 다른 방법으로는 별도 credentials 전용 Secrets 백엔드라는 것을 사용하기도 한다.
- 보통
- 어디까지 Airflow 이미지로 관리하고 무엇을 docker-compose.yml에서 관리할지.
- 회사마다 조금씩 다르다.
- Airflow 자체 이미지를 만들고 거기에 넣을지. 이런 경우 환경 변수를 자체 이미지에 넣고 이를 docker-compose.yaml 파일에서 사용한다.
image: ${AIRFLOW_IMAGE_NAME:-}
- DAG 코드를 어떻게 관리할 것인가?
- Airflow image로 DAG 코드를 복사하여 만드는 것이 더 깔끔하다.
- 하지만 개발 및 테스트 용으로는 docker-compose에서 host volume 형태로 설정하는 게 더 적합하다.
3. .airflowignore
- Airflow의 DAG 스캔 패턴은
dags_folder가 가리키는 폴더를 서브 폴더들까지 다 스캔해서 DAG 모듈이 포함된 모든 파이썬 스크립트를 실행해 새로운 DAG를 찾게 되며 이로 인해 가끔 사고가 일어난다. Airflow에서 무시해야 하는 것들을DAG_FOLDER의 디렉터리 혹은 파일 지정한다.- 패턴은
정규식 패턴으로 지정하며 매칭되는 파일들은 무시된다.
4. Summary 테이블 구현
1) CTAS 부분을 아예 별도의 환경 설정 파일로 떼어낸다면?
-
환경 설정 중심의 접근 방식으로 config 폴더를 생성하고, 그 안에 summary 테이블별로 하나의 환경 설정 파일을 생성한다.
-
다양한 테스트를 추가할 수 있고 비개발자들이 사용할 때 어려움을 덜 느낄 수 있다.
-
input_check: sql 구문을 돌렸을 때 count보다 큰지 작은지 확인하는 것 -
output_check: sql 구문을 돌렸을 때 count보다 크거나 같은지 확인 (크거나 같으면
#config/nps_summary.py
{
'table': 'nps_summary',
'schema': 'ssong_ji_hy',
'main_sql': """
SELECT LEFT(created_at, 10) AS date,
ROUND(SUM(CASE
WHEN score >= 9 THEN 1
WHEN score <= 6 THEN -1 END)::float*100/COUNT(1), 2)
FROM ssong_ji_hy.nps
GROUP BY 1
ORDER BY 1;""",
'input_check':
[
{
'sql': 'SELECT COUNT(1) FROM ssong_ji_hy.nps',
'count': 150000
},
],
'output_check':
[
{
'sql': 'SELECT COUNT(1) FROM {schema}.temp_{table}',
'count': 12
}
],
}✔ 특강 - AB 테스트
1) A/B 테스트란?

- AB 테스트는 가설이 있어야 하고, 성공과 실패의 지표를 테스트 전부터 명확하게 해야 한다.
- 예를 들어 새로운 추천 방식이 기존 추천 방식보다 매출을 증대시키는가?
- 어떤 지표에서 어느 정도의 임팩트가 예상되는가? (가설)
- 가설을 나중에 결과를 비교하면서 생각하지 못했던 다양한 배움이 생긴다.
- 가설을 세우지 않으면 테스트 결과에 따라 유리한 쪽으로 바꿀 위험이 있다.
- 객관적으로 새로운 기능이나 변경을 측정/비교하는 방식으로 진행해야 한다.
- 큰 위험 없이 새로운 기능을 테스트하고 빠르게 배우는 방법이다.
- 내가 생각하는 것과 실제 사용자들의 관점은 다른 경우가 많다. 이걸 AB 테스트를 통해 깨달을 수 있다.
- 보통 프로덕션 환경에서 2 개 혹은 그 이상의 버전을 비교한다.
control: 현재 버전test: 새 버전
- 다른 영역을 테스트하는 A/B TEST들은 독립적이라 생각하고 다수의 AB TEST를 동시에 실행하는 게 일반적이지만 그 과정에서 상호작용이 발생할 수 있다.
2) A/B TEST를 하면 안 되는 경우?
- 결과를 확인할 수 있는 기간이 길어지는 경우 빠르게 다음 단계로 넘어가는 게 더 중요하다.
- 버그 수정 (버그 수정은 A/B TEST를 하면 안 된다. 빠르게 수정해야 하는 사항.)
- 아직 구체적이지 않은 아이디어는 안 된다. 일부 실제 사용자에게 노출이 되는 것이기 때문에 아이디어가 개발되고 명확해야 한다.
- 구체적이지 않으면
Fake Door Testing
- 구체적이지 않으면
- 가설 없이 굉장히 랜덤한 아이디어
- 비교 대상이 없는 새로운 기능
3) 왜 A/B TEST는 애자일 해야 하는가?
- A/B TEST로 인해 속도가 느려지면 프로그램 구현 속도가 느려지게 된다.
- 그렇기 때문에 A/B TEST가 얼마나 걸리는지가 매우 중요하다.
- 애자일한 AB TEST가 가능하면 애자일한 Product 향상을 이루고, 애자일한 회사가 된다.
4) A/B 테스트 분석을 위해 필요한 정보
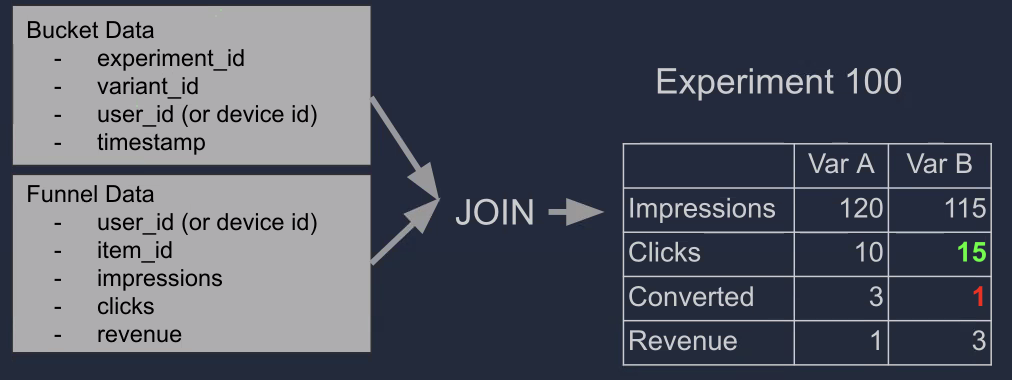
- 사용자별 A/B 버킷 정보
- 누가 A에 들어갔고 B에 들어갔는지
- 사용자별 행동 정보(Funnel Data) (이를 통해 앞단에 어떤 문제가 있는지도 알 수 있음)
- 어떤 아이템을 보았고
- 어떤 아이템을 클릭했고
- 어떤 아이템을 구매했는지
-> 해당 정보는 크기 때문에 보통 Data Lake에 저장한다.
-> 이것을 통해 A와 B로 그룹핑해서 그룹 간 통계 정보 계산 (매출액 등), 1과 2의 정보를 조인
5) BI 대시보드에서의 A/B TEST 분석
Impressions의 수를 줄이는 영향이 있는 게 아니라면 통계적으로 동일해야 하는데 이 부분이 다르다면 실험 자체에 문제가 있는지 의심해 보아야 한다.User size에서는 보통 둘의 크기가 통계적으로 동일하기를 바라며 그게 아니면 테스트 설정에 무엇인가 잘못된 게 있음을 확인할 수 있다.
6) A/B TEST 시 발생한 문제
- 가설 없이 혹은 대충 쓴 가설로 A/B TEST를 하는 경우
- 분석에 필요한 데이터 품질이 낮은 경우
- 데이터가 너무 작은 경우
- 대상이 되는 사람의 경향이 너무 다른 경우
- 대상이 되는 사람의 수가 너무 다른 경우
- 결과를 선입견 없이 객관적으로 분석하지 못하는 경우
- Interactions (상호 작용)
- 데이터 인프라 비용
- 비교 대상이 하나가 아닌 경우
- 비교 대상이 여러 개가 되면 결과가 어떻게 나와도 어떤 것으로 인해 결과가 이렇게 나온 건지에 대한 원인 분석이 명확하게 되지 않음.
- 얼마나 지켜보고 결정을 내릴 것인지
7) Outlier가 A/B 테스트에 미치는 영향
- 어느 서비스나 매출 등에 있어 소비를 많이 하는 소비자들이 존재한다.
- 이런 소비자들은 어느 버킷에 들어가느냐에 따라 분석에 큰 영향을 미친다.
- 그렇기 때문에 소비자를 제외하지 않으면 편차가 심한 결과가 나오기 때문에 A/B TEST 시 제외해야 한다.
- A/B TEST가 아니더라도 이 소비자들의 retention/churn rate를 살펴 볼 필요가 있다.
- 봇 유저 (scraper bot)이 한쪽으로 몰리는 경우
- session/impression 등에 큰 영향을 줄 수 있다.
- 대략 40 % 트래픽까지 봇 트래픽일 수도 있다.
- 항상 A/B 테스트 결과는 다양한 관점에서 바라봐야 한다.
8) A/B TEST 전체 과정
-
총 10 개월 (타임라인)
-
먼저 A/B TEST 시스템 구축
-
다음으로 A/A 테스트 수행 (검증 용도)
-
총 20 번의 A/B 테스트를 통해 ML 기반 추천 엔진 론치
-
A/B TEST의 성격에 따라 USER_ID(로그인을 한 사용자)를 사용할지 DEVICE_ID(모든 사용자, 브라우저에 쿠키를 심음)를 사용할지 결정해야 한다.
-
주어진 트래픽을 A 혹은 B로 나눈다. 이때 트래픽을 임의의 숫자로 표현해서 숫자 나머지 연산을 수행해서 나눌 수도 있고
🔎 어려웠던 내용 & 새로 알게 된 내용
✍ 회고
- airflow에서 문제가 발생했을 때 Slack과 연동하는 실습을 해 보았는데 alert을 주는 게 중요한 부분이라고 생각했기 때문에 프로젝트를 시작하면 이 부분은 꼭 구현해야 되겠다고 생각했다.

송의 개발 LOG