
📚 오늘 공부한 내용
1. Spark 데이터 처리
1) spark 데이터 시스템 아키텍처
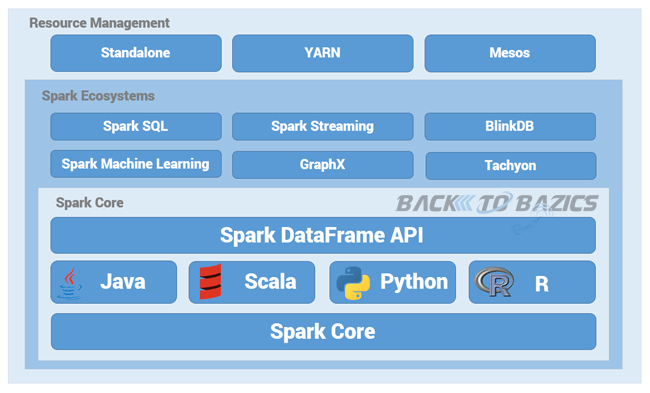
- 외부 데이터에 대해서는 어떻게 작업을 할 것인가.
- 주기적인 ETL을 통해 HDFS(내부 데이터)로 읽어오게 한다.
- 혹은 spark에서 필요할 때마다 읽어오게 한다. (배치, Spark SQL 혹은 Spark Streaming)
📌 데이터 병렬 처리가 가능하려면?
- 데이터가 먼저 분산되어야 한다. 하둡 맵의 데이터 처리 단위는 디스크에 있는 데이터 블록 (128 MB)이고, Spark에서는 이를 파티션(Partition)이라고 부른다.
- 환경 변수의 이름은 spark.sql.files.maxPartitionBytes인데 이는 HDFS 등에 있는 파일을 읽어올 때만 적용된다.
- 나눠진 데이터를 각각 따로 동시 처리하게 된다.
- 데이터 블록이 한 서버에서 다른 서버로 굳이 이동되지 않고 처리될 수 있도록 N 개의 데이터 블록으로 구성된 파일 처리 시 N 개의 Map 태스크가 실행된다.
- Spark에서는 파티션 단위로 메모리로 로드되어 executor가 배정된다. 즉, 한 executor에 여러 개의 파티션을 처리할 수 있다.
2) 병렬 처리
- 처리하려는 데이터 파일을 먼저 파티셔닝한다.
- 파티셔닝 방법은 데이터 소스에 따라 달라진다.
- 이때 각 파티션이 spark에 의해 executor 상에서 태스크가 되어 실행이 된다. 이때 배정되는 태스크들을 RDD, DataSet, DataFrame이라고 한다.
3) Spark 데이터 처리 흐름
- 데이터 프레임은 작은 파티션들로 구성된다. 이때 데이터 프레임은 한 번 만들어지면 수정이 불가하다.
- 입력 데이터 프레임을 원하는 결과 도출까지 다른 데이터 프레임으로 계속 변환한다.
- 이렇게 보면 굉장히 빠를 것 같지만 Group By하거나 Sorting 하면 데이터 이동이 이루어져야 하고 이 경우를 셔플링이라고 하는데 이 과정에서 Data Skew가 발생할 수 있다.
- 셔플링이 발생하는 경우는?
- 명시적 파티션을 새롭게 하는 경우.
- 시스템에 의해 이루어지는 셔플링.
- 셔플링이 발생할 때 네트워크를 타고 데이터가 이동하게 된다.
- 기본 값은 200이며 이는 최대 파티션 수이다. spark.sql.shuffle.partitions이 결정하게 된다.
- 오퍼레이션에 따라 파티션 수가 결정된다. (random, hashing, partition, range partition 등)
- sorting의 경우 range partition을 사용한다.
4) Data Skewness
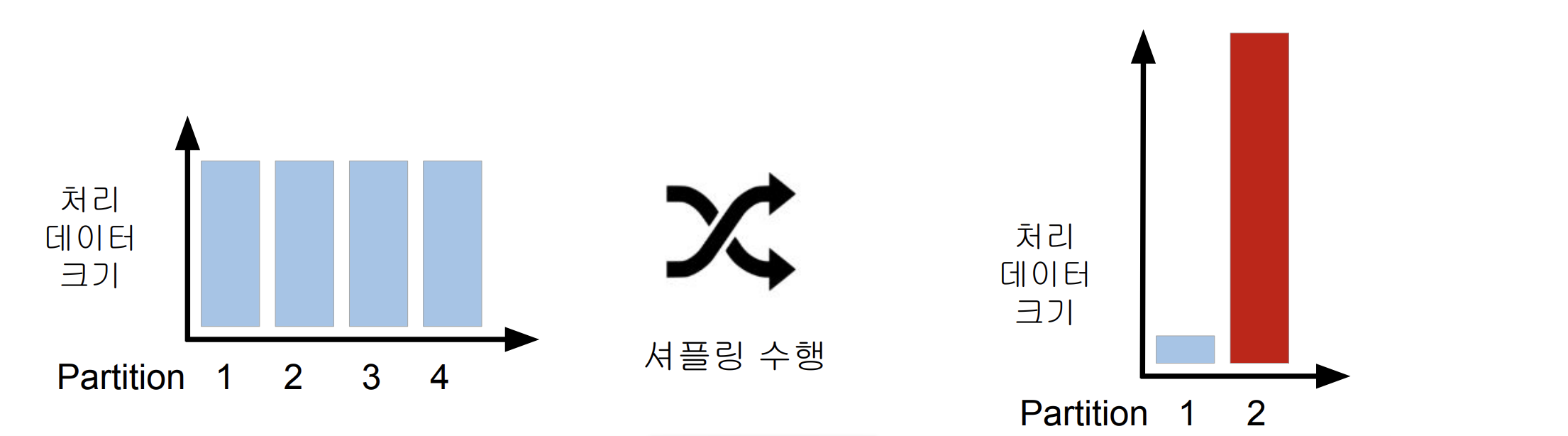
- Data Partitioning은 데이터 처리에 병렬성을 주지만 단점도 존재하게 된다.
- 이는 데이터가 균등하게 분포하지 않는 경우 발생하게 된다.
- 셔플링을 최소화하는 것도 중요하고 파티션을 최적화하는 것도 중요하다.
2. Spark 데이터 구조
1) RDD (Resilient Distributed Dataset)
- RDD는 가장 low level 데이터 구조로 비구조화된 데이터와 구조화된 데이터의 분산된 집합이다.
- RDD보다 상위 레벨로 DataFrame과 Dataset이 존재한다.
- 레코드별로 존재하지만 스키마가 존재하지 않는다.
- RDD의 데이터 구조
- 변경이 불가능한 분산 저장된 데이터
- low level의 함수형 변환을 지원
- 일반 파이썬 데이터는 parallelize 함수로 RDD로 전환
- 반대로 collect로 파이썬 데이터로 변환 가능
2) DataFrame, Dataset
- 이때 DataFrame은 record에 필드가 존재한다. 하지만 꼭 타입이 있지는 않다.
- Dataset은 타입이 존재하고, 타입 체크를 한다. 하지만 지금은 DataFrame과 Dataset은 동일한 구조이다.
- DataFrame과 Dataset은 모두 SparkSQL 엔진 위에서 돌아간다.
- Dataset은 컴파일 언어 Scala/Java에서 사용 가능하다.
- DataFrame 데이터 구조
- 변경이 불가능한 분산 저장된 데이터- RDD와는 다르게 관계형 데이터베이스 테이블처럼 컬럼을 나누어 저장
3. Spark Session
from pyspark.sql import SparkSession- Spark SQL Engine이 중심으로 돌아가기 때문에 다음과 같이 import 해 주어야 한다.
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.getOrCreate()- Driver 안에 Spark Session을 생성하면서 Cluster와 소통하게 된다.
1) 환경 변수
- 환경 설정
- executor별 메모리: spark.executor.memory (기본값: 1g)
- executor별 CPU 수: spark.executor.cores(YARN에서는 기본 값 1)
- driver 메모리: spark.driver.memory (기본값: 1g)
- Shuffle후 Partition의 수: spark.sql.shuffle.partitions (기본값: 최대 200)
2) 환경 설정 방법 4 가지
- 충돌 시 우선 순위는 아래일수록 높아진다.
- 환경 변수
- $SPARK_HOME/conf/spark_defaults.conf
- spark-submit 명령의 command line 파라미터
- SparkSession 만들 때 따로 지정 (SparkConf)
4. Local Standalone Spark
- Spark Cluster Manager로 local[n]을 지정한다.
- local이면 하나의 쓰레드만 생성되고, local[*]는 CPU 수만큼의 쓰레드를 생성한다. 또한 local[n]이면 n 개의 쓰레드를 생성한다.
- 한 executor를 쓰지만 다음과 같이 쓰레드 수를 정해 줄 수 있다.
5. DataFrame의 컬럼 지칭하는 방법
- "컬럼명"
- col("컬럼명")
- column("컬럼명")
- 테이블명.컬럼명
from pyspark.sql.functions import col, column
stationTemps = minTemps.select(
"stationID",
col("stationID"),
column("stationID"),
minTemps.stationID
)🔎 어려웠던 내용 & 새로 알게 된 내용
📌 JAVA_HOME 환경 변수 설정
/usr/libexec/java_home
- 이 명령어를 통해 JAVA_HOME으로 설정할 환경 변수 위치를 파악해 준다.
export JAVA_HOME="/Library/Internet Plug-Ins/JavaAppletPlugin.plugin/Contents/Home"- 그렇게 나온 위치를
export JAVA_HOME=뒤에 추가해 준다.
echo $JAVA_HOME
- 해당 명령어를 통해 제대로 설정이 되었는지 확인해 준다.
- shell에서 이 환경을 이용해 주기 위해
vi ~/.zshrc를 해 준 후 다음과 같이export JAVA_HOME="/Library/Internet Plug-Ins/JavaAppletPlugin.plugin/Contents/Home"이 내용을 추가해 준다.
- 이렇게 환경 설정 파일(.zshrc)를 수정한 경우 source 명령어를 통해 재실행해 주어야 한다.
source ~/.zshrc


📌 spark 설치 (scala)
tar xvf spark_tgz파일명
- 이렇게 하면 spark의 설치가 완료되며 SPARK_HOME 환경 변수를 설정해 주어야 한다.
/spark 저장 위치/spark-3.4.1-bin-hadoop3- vi ~/.zshrc로 환경 설정에 들어가 JAVA_HOME을 추가한 것처럼 SPARK_HOME을 해당 위치로 추가해 준다.
- 이후
export PATH=$PATH:$SPARK_HOME/bin이 내용까지 추가해 주어야 한다.- 이 과정이 끝나면 source 명령을 통해 zsh 환경을 재실행해 준다.
- 이후
spark-shell명령을 이용하면 spark shell을 사용할 수 있다.
- shell이 실행될 때 기본적으로 웹 UI 주소가 발급되는데 그 주소로 접속해 보면 다음과 같은 Spark Web UI를 볼 수 있다.
- shell 종료 명령어는
:quit이다.
📌 spark shell 사용 (python)
pip install py4j
- 먼저 py4j를 설치해 준다.
pyspark- 명령어를 사용하면 python을 통해 spark shell을 이용할 수 있도록 shell이 실행된다.
- csv 파일을 dataframe을 사용해 처리해 주면 Web UI에 해당 작업 내용이 뜨는 것을 볼 수 있다.

✍ 회고
- spark 과정이 들어가니 속도가 더뎌진 것 같다. 학습 곡선 생각하면서 열심히 하는 중이다. 곧 팀에서 하는 개인 프로젝트가 들어갈 예정인데 spark와 kafka를 사용해 보고 싶기 때문에.

송의 개발 LOG