웹크롤링
1.웹 크롤링 - 1. 특정 웹 페이지 원하는 요소 스크래핑
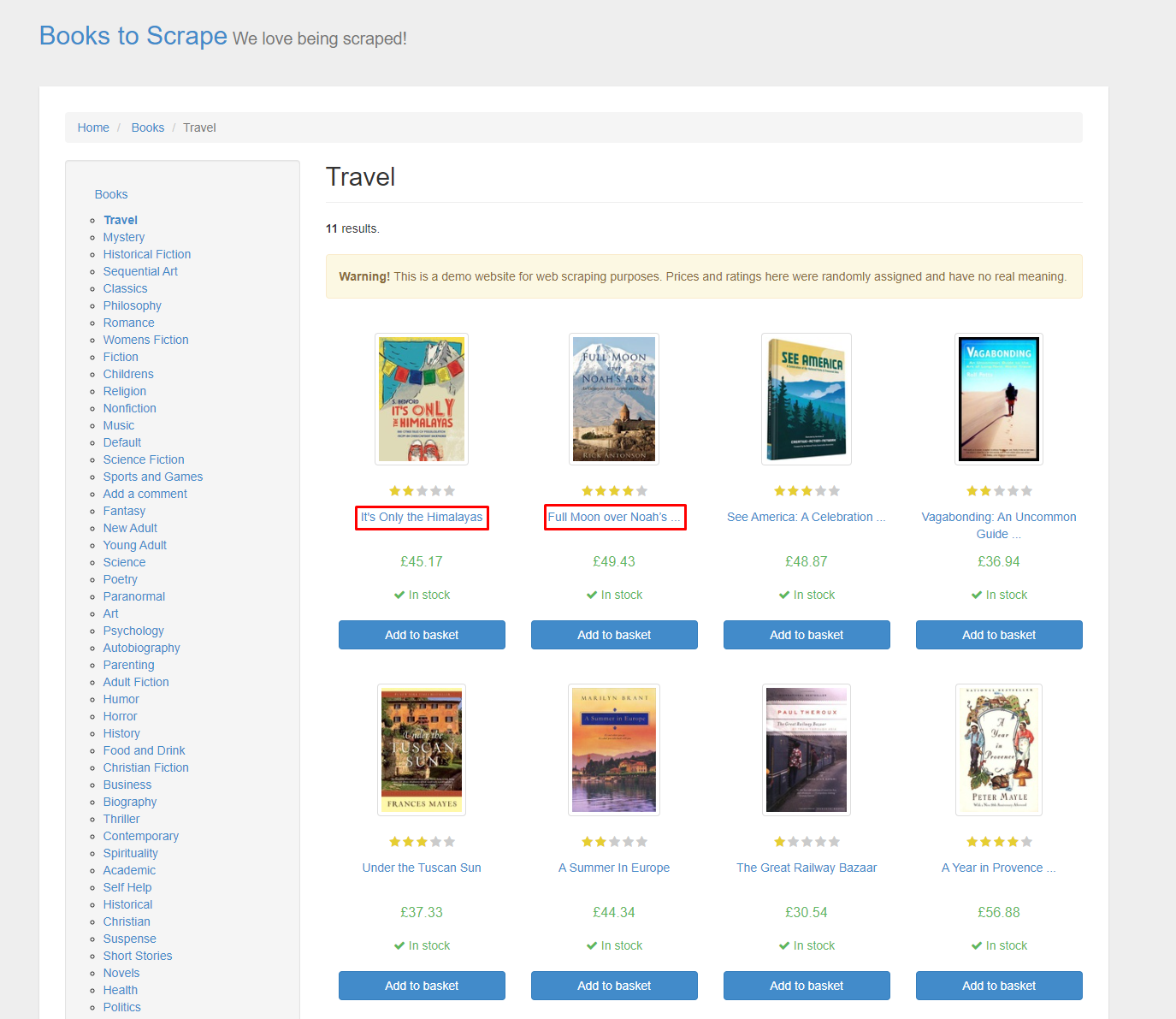
웹 페이지에서 추출할 요소의 위치를 찾는 방법은 두 가지가 있다.개발자 도구(F12)를 이용해 직접 위치를 찾기.우 클릭 후 검사 선택해서 찾아 주는 위치를 파악하기.우리가 추출할 요소는 책들의 제목이기 때문에 제목에서 우 클릭 후 검사를 눌러 주면 다음과 같이 웹 페
2.웹 크롤링 - 2. 페이지네이션 된 페이지의 원하는 요소 스크래핑

페이지네이션(Pagination)이란? 많은 정보를 인덱스로 구분하는 기법.우리가 흔히 아는 웹 페이지의 페이지 번호를 말한다.대부분의 웹 페이지들이 URL?page={i}로 URL 뒤에 Query String으로 페이지 번호를 보낸다. 해당 사이트의 질문 제목들을
3.웹 크롤링 - 3. selenium을 이용해 동적인 페이지의 XPath로 원하는 요소 스크래핑
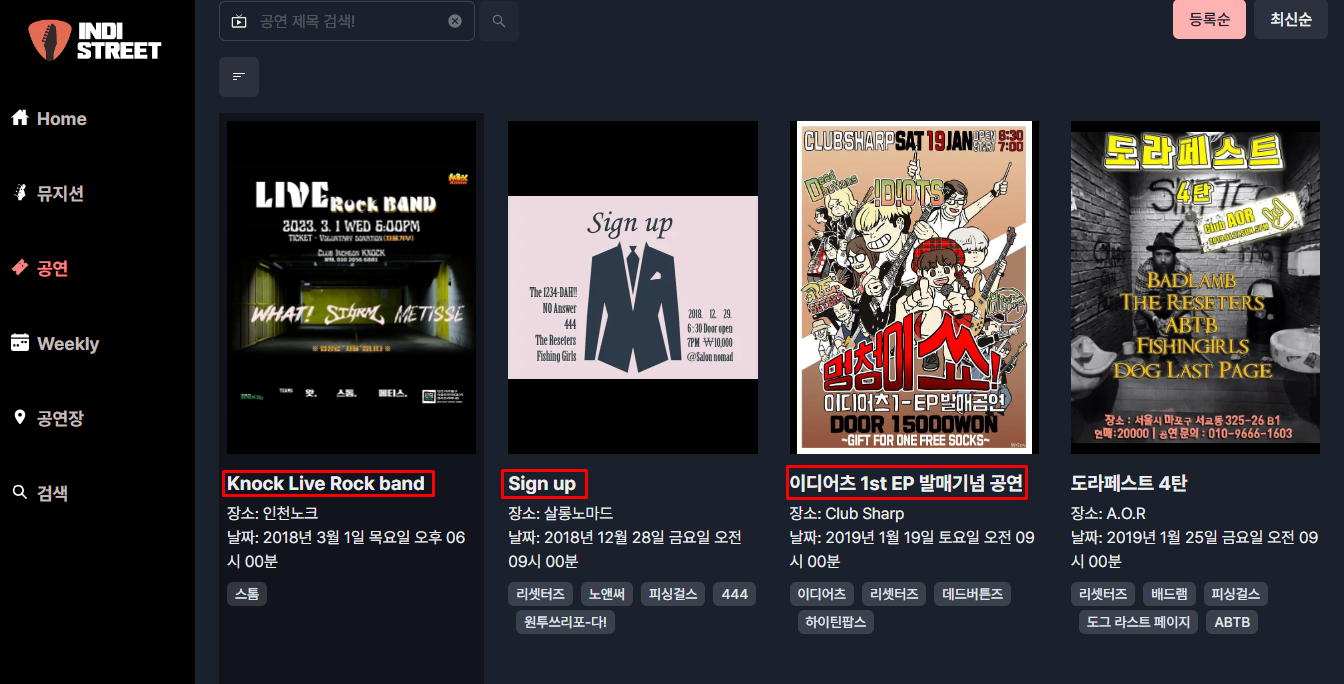
selenium은 Python을 이용해서 웹 브라우저를 조작할 수 있는 자동화 프레임워크이고, WebDriver는 웹 브라우저를 제어할 수 있는 자동화 프레임워크이다.WebDriver는 웹 브라우저와 연동을 하기 위해 필요하다.동적인 페이지를 스크래핑 하기 위해서는 s
4.웹 크롤링 - 4. selenium을 이용해 마우스, 키보드 이벤트로 특정 웹 페이지 로그인
요즈음은 간편 로그인이라는 기능을 지원하는 서비스가 많다.이때 바로 해당 링크로 접속하는 게 아니라 플랫폼에서 로그인을 해야 하는 경우가 많다.selenium을 통해 자동 로그인이 가능하게 할 수 있다.naver나 daum 같은 포털 사이트는 이렇게 해도 로그인이 되지
5.웹 크롤링 - 5. 기상청 날씨 정보 시각화
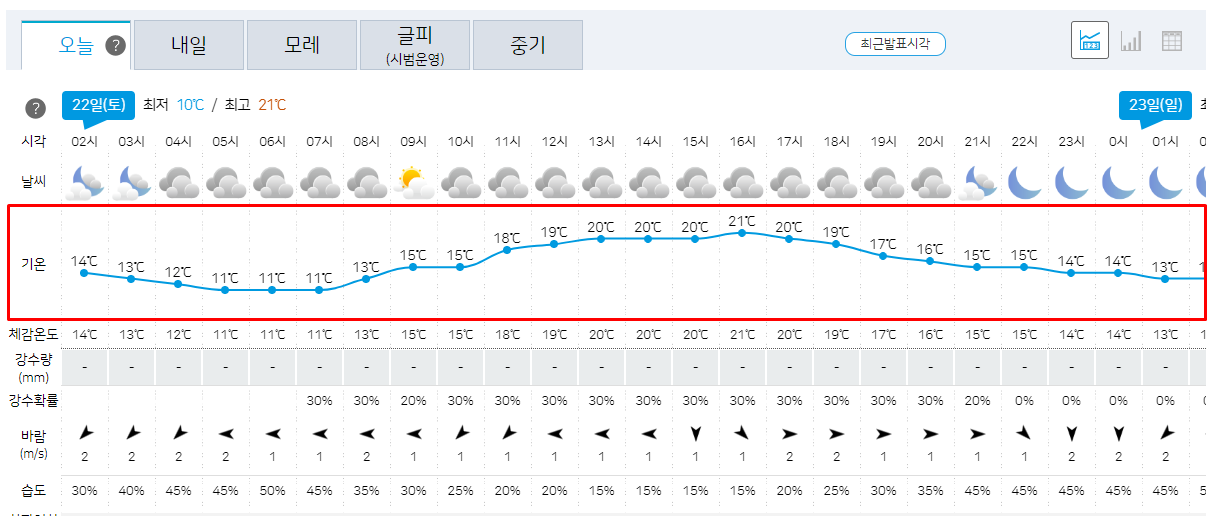
우리는 기상청 페이지에서 기온 부분의 데이터를 스크래핑할 것이기 때문에 기온 부분을 우 클릭 후 검사 버튼을 눌러 위치를 확인한다.id가 my-tchart인 저 부분이 우리가 추출해야 하는 그래프의 데이터임을 알 수 있다.이 분석 과정을 통해 driver 객체에 응답을
6.웹 크롤링 - 6. 특정 웹 페이지 태그 빈도 수 막대 그래프 시각화
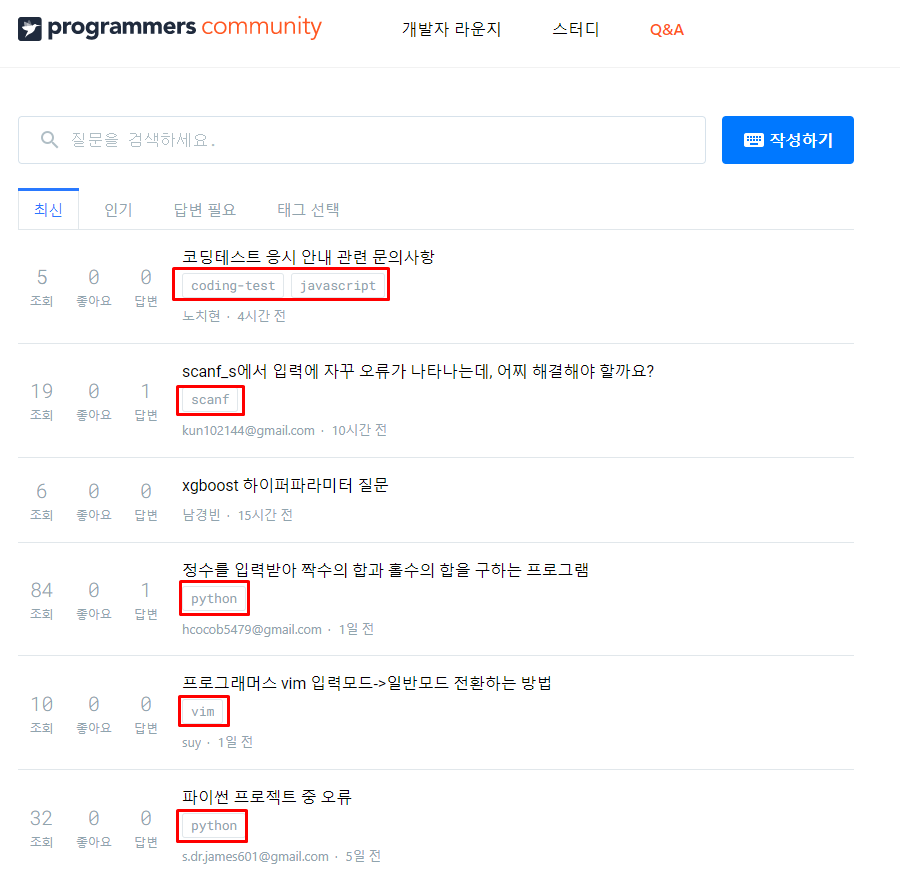
왜 빈도 수를 스크래핑 하여 시각화하는가?해당 사이트는 다양한 질문들이 올라오는 사이트이다.어떤 주제의 질문이 많이 올라오는지를 알기 위해 빈도 수를 측정해 한눈에 보기 쉬운 그래프로 시각화한다.우리는 이 웹 페이지에서 주제 태그를 추출해야 한다.그리고주제들이 각각 몇
7.웹 크롤링 - 7. 특정 웹 페이지 태그를 워드 클라우드로 시각화
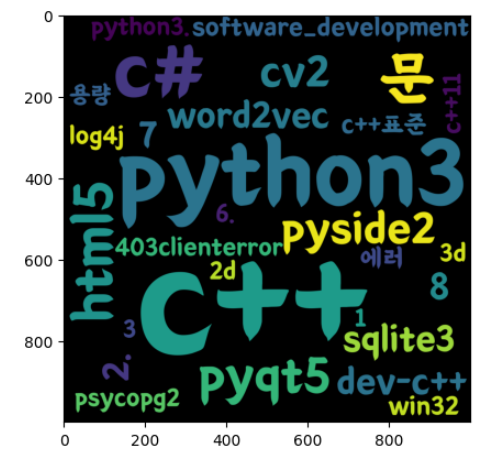
6\. 특정 웹 페이지 태그 빈도 수 막대 그래프 시각화위의 포스트에서는 상위 10개를 막대 그래프로 시각화했다면 이번에는 빈도 수가 높은 태그 이름을 모아 word cloud로 시각화할 것이다. 스크래핑 과정은 거의 동일하다.우리는 이 웹 페이지에서 주제 태그를 추출