
📌 팀 프로젝트 주제: 카테고리별 유튜브의 파급력 (조회 수, 좋아요 수, 구독자 수) 데이터 크롤링 및 시각화
- YouTube DATA API Search:List 참조 문서

- 해당 레퍼런스 문서에는 채널의 정보를 가지고 오는
Channels:List, 비디오의 정보를 가지고 오는Videos:List, 댓글의 정보를 가지고 오는Comments:List등 다양한 참조 문서가 있다.내가 어떤 데이터를 필요로 하는지 파악한 후필요한 부분을 참조하는 것을 추천한다. 어떤method에 어떤parameter를 보내야 하고, 어떤output를 받을 수 있는지 알 수 있게 해 주기 때문이다.
1. API KEY 연동하여 API DATA 호출
- API KEY를 발급받고 호출하는 과정은 이전 포스트에 상세하게 기록해 두었다.
📚 [유튜브 데이터 크롤링 및 시각화 프로젝트] 1. YOUTUBE API 사용 환경 설정
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from oauth2client.tools import argparser
import requests
API_KEY = '발급받은 API_KEY'
YOUTUBE_API_SERVICE_NAME = 'youtube'
YOUTUBE_API_SERVICE_VERSION = 'v3'
youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_SERVICE_VERSION, developerKey = API_KEY)2. 특정 조건으로 search()를 이용해 데이터 조회
search().list()를 통해 특정 조건을 주어 데이터를 조회해 보고, API 데이터의 구조를 파악해 보자.- 이를 통해 내가 크롤링 해야 하는 필요한 정보를 어떻게 조회해야 하는지를 알 수 있다.
search_something = youtube.search().list(
q = 'haha ha',
part = 'snippet',
order = 'relevance',
maxResults = 5,
).execute()q를 통해 일종의 문자열 형식의 검색어를 설정해 준다.order를 데이터를 어떤 기준으로 조회할 것인지를 선택할 수 있다. 나는 해당 유튜버의 채널 ID만을 필요로 했기 때문에 다음과 같이relevance를 설정하여 관련성 순으로 정렬하였다.order의 종류- date: 최근 순으로 정렬
- rating: 높은 평가 순으로 정렬
- relevance: 검색 쿼리(q)에 대한 관련성을 기준으로 정렬
- title: 제목에 따라 문자순으로 리소스 정렬
- videoCount: 업로드한 동영상이 많은 채널 내림차순 정렬
- viewCount: 리소스 조회 수가 높은 항목부터 정렬
- 이렇게 search 함수를 사용한 search_something은 이런 key-value의 조합인 JSON list가 나오게 된다.

channelId라는 key는 그 채널 정보에 대한 고유의 값으로 저channelId를 통해 채널과 관련된 정보들을 조회해 줄 수 있다.- 개인적으로
haha ha라는 고양이 유튜브 채널을 좋아해 해당 채널을 조회해 보기로 했다.
📌 나는 원래 음악 카테고리를 맡았었는데 음악이라는 카테고리가 분류가 생각보다 명확하지 않아 이후 동물 유튜버로 변경이 되었다. 음악 카테고리가 명확하지 않다고 느꼈던 이유는 몇 가지가 있다.
1. 먼저 유튜버라고 할 수 없는 음원 파일들이나 또 유명한 가수들의 채널이 카테고리에서는 음악으로 분류된다.
2. 음악을 부르는 커버곡 유튜버들도 있고, 음악을 가르쳐 주는 유튜버도 있고, playlist를 올리거나 팝송을 해석해 주는 유튜버들도 있다. 이들을 모두 음악 유튜버라고 둘 것인가에 대한 한계도 있었다.
3. 유튜브를 운영하는 모든 유튜브 채널이 음악이라고 봤다면youtube api에서 제공하는채널 카테고리로 분류하면 되는 문제였겠지만 데이터의 분석 과정에서 다른 카테고리는 유튜버들이 주류였고, 프로젝트의 목적도 각 카테고리와 유튜버들에 대한 분석이 메인 주제였기 때문에 이 부분에 대해 고민을 많이 했고, 차후 기준을 잡고 개선하더라도 조금 더 주제와 가깝고 명확한 카테고리를 선택하는 것이 좋겠다 싶어동물로 카테고리를 변경하게 되었다.
3. 내가 조회해야 할 데이터 범위 정하기
📌 사실
youtube api의 할당량은 하루에 10000까지로 사실상 할당된 부분이 많지는 않았다. 이 부분은 코드를 수정하고 할당량이 조금이라도 줄어든다면 코드를 그에 맞게 수정해 주어야 하며 여러 과정을 거쳐 최적화를 진행해야 하는 것으로 알고 있는데 프로젝트 시간이 촉박해 그 부분까지 고려하지 못한 게 아쉬웠다.
- 하루 할당량이 많지 않았기 때문에 조회를 해 오는 기준이 명확해야 했다. 그래서 조에서 정한 범위는 다음과 같았다.
- 한 카테고리별 유튜버 7~10 명
- 각 유튜브 채널별로 최근 올린 영상 200 개
-
채널의 정보를 가지고 오는
Channels:List, 비디오의 정보를 가지고 오는Videos:List, 댓글의 정보를 가지고 오는Comments:List각자 가지고 올 수 있는 정보들은 다양한데 우리 팀 프로젝트에 필요한 정보들은 다음과 같았다. -
Channels:ListChannelId: 채널 IDtitle (snippet): 채널명viewCount (statistics): 총 조회 수subscriberCount (statistics): 구독자 수thumbnails (snippet): 섬네일 (high 사용)
-
Videos:ListvideoId: 비디오 IDtitle (snippet): 비디오 제목thumbnails (snippet): 섬네일 (high 사용)viewCount (statistics): 조회 수commentCount (statistics): 댓글 수likeCount (statistics): 좋아요 수publishedAt (snippet): 개시일자
-
Comments:ListtextDisplay: 댓글의 내용authorDisplayName: 댓글 작성자publishedAt: 댓글 작성 시간likeCount: 좋아요 수
✔ 개인적으로 조금 특이했던 부분인데 youtube api는 thumbnails의 링크를 화질별로 추출할 수 있게 나눠 두었다. low(저화질), standard(보통), high(고화질)로 분류가 되어 있고, 필요한 화질에 따라 조회해 올 수 있다.
-> value가 이미지 링크로 되어 있어서 html 파일을 통해 웹에 보여 줄 때는 해당 링크를 호출해 주어야 함.
4. ChannelId를 통해 동영상 정보 가지고 오기
- 2의 단계에서 추출한
haha ha채널의ChannelId는UCOp66Vup07X0YziXaaxqs2A였다. - 나는 이걸 이용해 채널의 동영상 정보를 가지고 오는 함수를 구현해 보았다.
- 조회해 줄 수 있는
channelId와 최대 몇 개까지 조회할 것인지maxCount를 파라미터로 넘겨 주면 해당 개수만큼의 채널의 동영상이 조회될 수 있도록 하는 함수이다. - 이 과정에서
구독자 수의 경우Videos:List에는 key가 따로 존재하지 않기 때문에 따로Channels:List의subscriberCount (statistics)를 조회해야 했다. - 또한 조회 수(viewCount), 좋아요 수(likeCount), 댓글 수는 채널에 따라 비공개로 설정해 둔 곳은
None으로 나오기도 했고 진짜 없기 때문에None으로 나오는 경우도 있어 None에 대해서는 0으로 읽을 수 있도록 처리해 주었다.
#channelId
def set_video(channelId, maxCount):
#먼저 search 함수를 통해 해당 channelId의 조회 수(viewCount)가 높은 영상을 파라미터로 받아 준 maxCount만큼 조회한다.
search_response = youtube.search().list(
order = 'viewCount',
part = 'snippet',
channelId = channelId,
maxResults = maxCount,
).execute()
channel_response = youtube.channels().list(
part="statistics",
id=channelId
).execute() #채널 정보를 가지고 오면 구독자를 가지고 올 수 있다. search()가 아닌 channels()로 조회해서 채널 정보를 조회한다.
video_ids = []
for i in range(0, len(search_response['items'])):
video_ids.append((search_response['items'][i]['id']['videoId'])) #videoId의 리스트를 만들어 둔다 (videoId로 조회할 수 있게)
#추출할 정보의 list들과 그 모든 정보를 key-value로 저장할 딕셔너리 변수를 하나 생성한다.
channel_video_id = []
channel_video_title = []
channel_rating_view = []
channel_rating_comments = []
channel_rating_good = []
channel_published_date = []
channel_subscriber_count = []
channel_thumbnails_url = []
data_dicts = { }
# 영상이름, 조회수 , 좋아요수 등 정보 등 추출
for k in range(0, len(search_response['items'])):
video_ids_lists = youtube.videos().list(
part='snippet, statistics',
id=video_ids[k],
).execute()
#print(video_ids_lists)
str_video_id = video_ids_lists['items'][0]['id']
str_thumbnails_url = str(video_ids_lists['items'][0]['snippet']['thumbnails']['high'].get('url'))
str_video_title = video_ids_lists['items'][0]['snippet'].get('title')
str_view_count = video_ids_lists['items'][0]['statistics'].get('viewCount')
if str_view_count is None:
str_view_count = "0"
str_comment_count = video_ids_lists['items'][0]['statistics']['commentCount']
if str_comment_count is None:
str_comment_count = "0"
str_like_count = video_ids_lists['items'][0]['statistics'].get('likeCount')
if str_like_count is None:
str_like_count = "0"
str_published_date = str(video_ids_lists['items'][0]['snippet'].get('publishedAt'))
str_subscriber_count = channel_response['items'][0]['statistics']['subscriberCount']
if str_subscriber_count is None:
str_subscriber_count = "0"
# 비디오 ID
channel_video_id.append(str_video_id)
# 비디오 제목
channel_video_title.append(str_video_title)
# 조회수
channel_rating_view.append(str_view_count)
# 댓글수
channel_rating_comments.append(str_comment_count)
# 좋아요
channel_rating_good.append(str_like_count)
# 게시일
channel_published_date.append(str_published_date)
# 구독자 수
channel_subscriber_count.append(str_subscriber_count)
channel_thumbnails_url.append(str_thumbnails_url)
data_dicts['id'] = channel_video_id
data_dicts['title'] = channel_video_title
data_dicts['viewCount'] = channel_rating_view
data_dicts['commentCount'] = channel_rating_comments
data_dicts['likeCount'] = channel_rating_good
data_dicts['publishedDate'] = channel_published_date
data_dicts['subsciberCount'] = channel_subscriber_count
data_dicts['thumbnail'] = channel_thumbnails_url
return data_dicts - 이렇게 만들어진 함수를 직접 파라미터를 넘겨 주어 호출한다.
- 나는 제대로 된 데이터가 들어오는지 보기 위해 상위 15 개를 먼저 조회해 주도록 하였다.
from googleapiclient.discovery import build
youtuber = set_video('UCOp66Vup07X0YziXaaxqs2A', '15') - 이후 youtuber를 호출하면 다음과 같이 haha ha 채널의 유튜브 동영상 정보가 담긴 딕셔너리가 생성된 것을 확인할 수 있다.

- 그렇지만 이렇게 보기는 힘들기 때문에 데이터를 확인해 주기 위해
pandas를 사용해 목록화를 해 보자.
5. 동영상 정보 pandas를 통해 목록화
pandas의dataframe을 사용해 주면 된다.dataframe을 생성할 때는 각각의 리스트들을 다시 리스트들로 엮어 주어야 한다.- 이건 목록을 추출하면서 겪었던 문제 중 하나였는데 만약 목록에 넣어 준 값들이
컬럼이 되기를 원한다면 꼭 뒤에.T를 붙여 주어야 한다.
df = pd.DataFrame([youtuber['id'], youtuber['title'], youtuber['viewCount'], youtuber['commentCount'], youtuber['likeCount'], youtuber['publishedDate'],youtuber['subsciberCount'],youtuber['thumbnail']]) - 위의 코드를 통해
DataFrame을 생성했다고 생각하면 T를 붙여 주지 않았을 때는 지금 나열한 값들이 다음과 같이 나오게 된다.
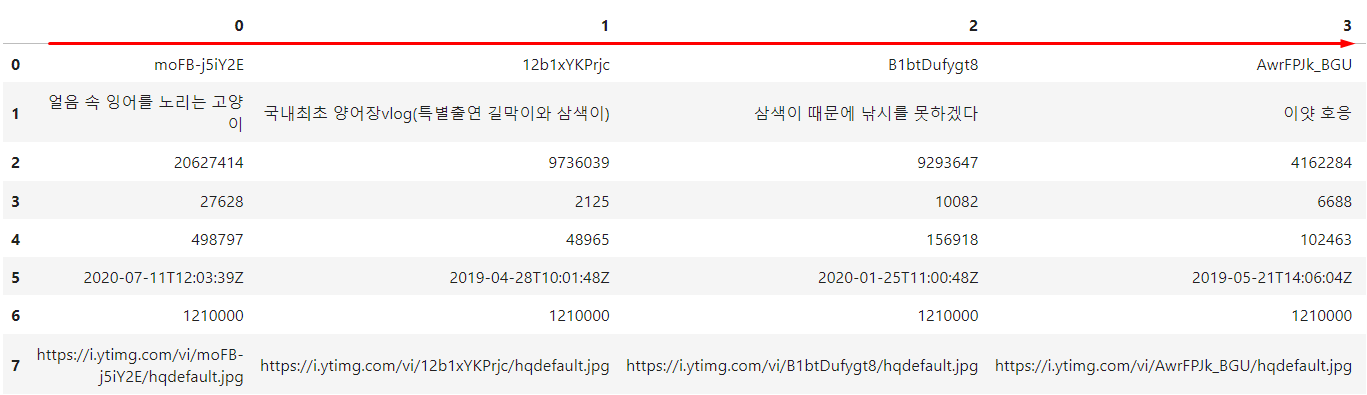
- 그런데 우리가 보고 싶은 목록은 이게 아니라 한 컬럼은
id가 한 컬럼은title이 한 컬럼은viewCount가 들어가기를 원하는 것이기 때문에.T를 붙여 준다..T는로우와컬럼의 위치를 바꿔 준다.
import pandas as pd
df = pd.DataFrame([youtuber['id'], youtuber['title'], youtuber['viewCount'], youtuber['commentCount'], youtuber['likeCount'], youtuber['publishedDate'],youtuber['subsciberCount'],youtuber['thumbnail']]).T
# 좀 더 보기 편하게 각각 컬럼명을 설정해 주자
df.columns = ["영상ID","제목", "조회수", "댓글수", "좋아요수", "게시일", "구독자수", "섬네일"] 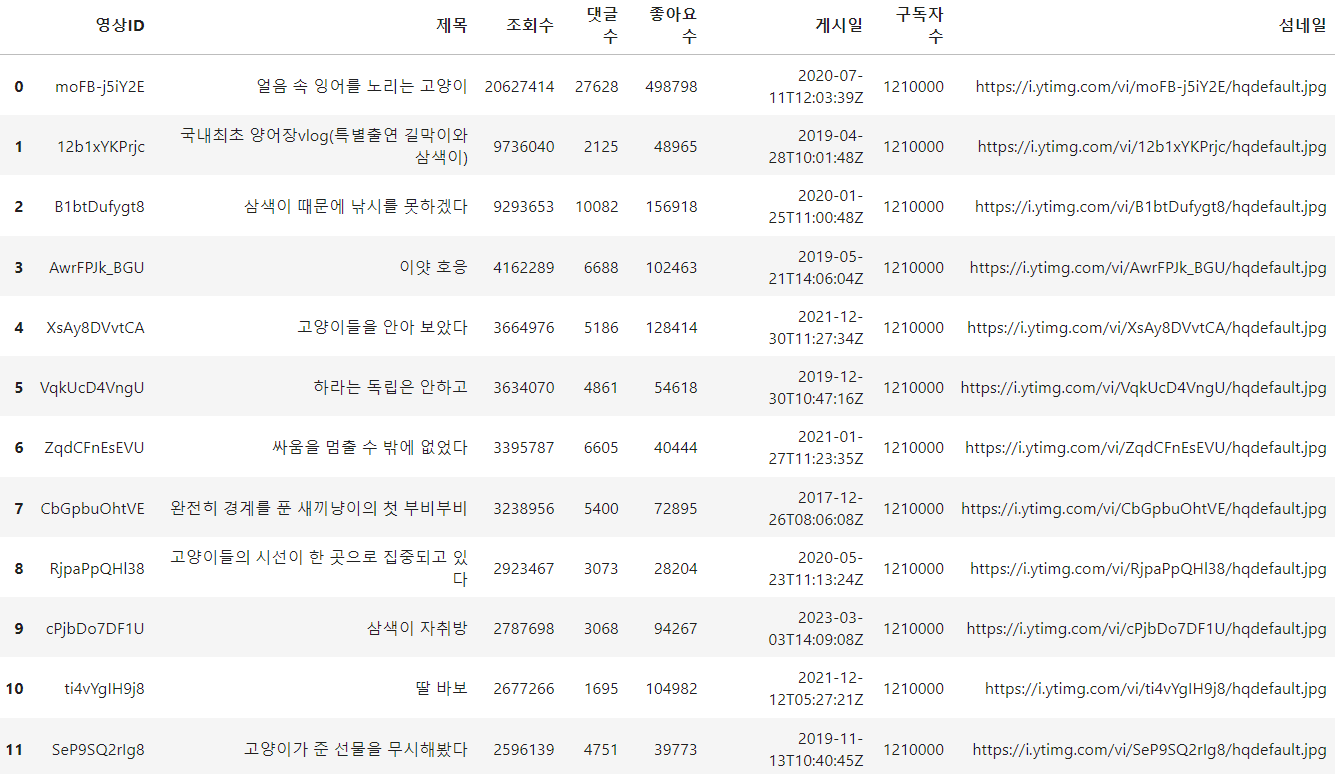
- 그러면 다음과 같이 원하는 대로 검색한 채널의 조회 수가 높은 유튜브 영상들의 정보가 뜨게 된다.

유튜브 API를 처음 활용해 보게되어 막막했는데, 정말 많은 도움이 되었습니다.
감사합니다!