
Generative Deep Networks
- Discriminative deep networks를 통해 image를 분류하는 것이 아닌,
output 자체가 생성된 image로.
Encoder-Decoder Network
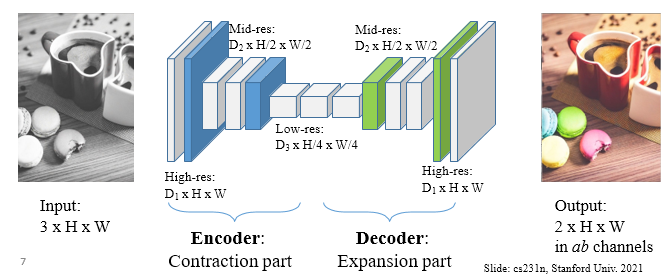
Downsampling: pooling or strided convolutionUpsampling: strided transposed convolution or simple in terpolation
Loss function for Regression
- Per-pixel regression 문제이기에 regression loss 사용
L1 loss: 내가 생성한 것과 gt와의 차이. 절댓값.L2 loss: 제곱.
Tasks
- Colorization
- Image/Video Inpainting
- Synthetic Bokeh (초점)
- Image Denoising
- Super-Resolution
Normalization and Style Transfer
Batch Normalization
- 각 feature map이 normal distribution을 따른다고 생각하며 feature map을 추정.
- Batch 단위로 분포를 강제로 조정
- 각 channel별 batch normalization을 한다.
- 모든 feature map에 대한 분포가 unique gaussian이어야 하나?
-> 이러한 조정 또한 network에 맡긴다.

- Channel별 감마를 곱한다. Scaling.
- 감바와 베타를 학습시킨다.
- 네트워크에 자유도를 준다.

- 해당 채널의 모든 feature map 평균을 구한다.
- 분산 구한다.
- 정규화
- Scale and Sihft.
효과
- Improves gradient flow through the network
- Allows higher learning rates
- Reduces the strong dependence on initialization
Style Transfer
- Style에 따라 input을 바꿔준다.
Instance Normalization
- BN보다 generative image modeling에서 효과적인 정규화 방법
- 평균과 표준편차를 구해서 each channel and each sample에 정규화를 진행
- Batch가 빠짐. Batch = 10이면, 10장 아니고 그냥 1장으로.
AdaIn
- Arbitrary style transfer in realtime with adaptive instance normalization
- AdaIn은 Contents input과 Style input이 주어졌을 때, 간단하게 content input(feature)의
평균&분산과 style input의평균&분산이 match되도록 조정한다. - 이전까지는 feature를 분석하는데만 사용. 근데 feature를 보정해서 사용하자.
어떻게 보정할까?
- AdaIn은 learnable affine parameters를 사용하지 않는다.

- 대신, 위와 같이 affine parameters를 계산한다.
- AdaIn performs style transfer in the feature space by transferring feature statistics, specifically the channel-wise mean and variance from the style image.

Übermensch