
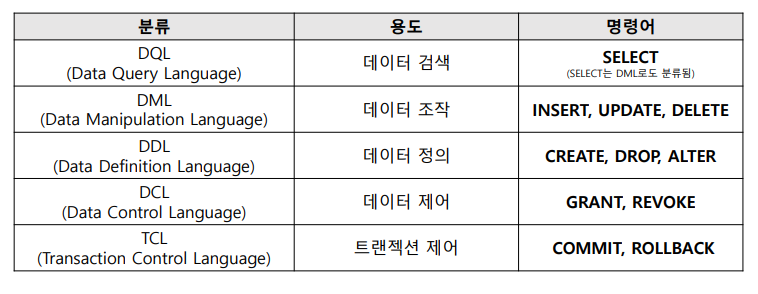
📌 SELECT (DML 또는 DQL) : 조회
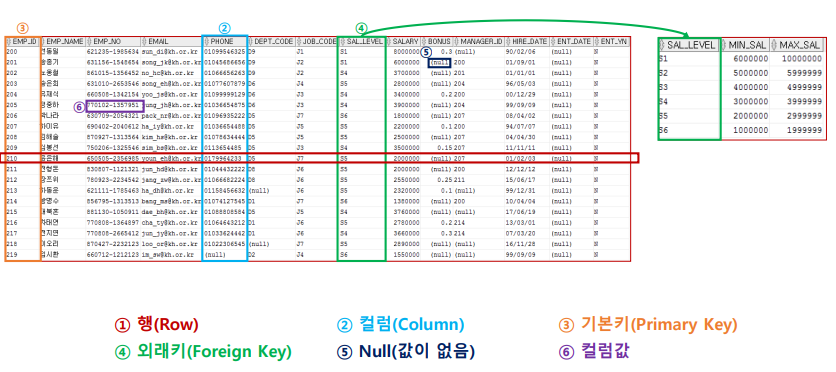
데이터 조회(SELECT)하면 조건에 맞는 행들이 조회됨. 이때, 조회된 행들의 집합을 "RESULT SET"이라고 한다.
RESULT SET 에는 0개 이상의 행이 포함될 수 있다. 왜 0개? 조건이 맞는 행이 없을 수도 없기 때문에!
🔉 [주요 용어]
'*' : ALL, 모든, 전부
[ SELECT 컬럼명 FROM 테이블명 ]
ex) EMPLOYEE 테이블에서 모든 사원의 이름만 조회
SELECT EMP_NAME FROM EMPLOYEE;
🔉 SQL(Structured Query Language)
관계형 데이터베이스에서 데이터 조회하거나 조작하기 위해 사용하는 표준 검색 언어
원하는 데이터를 찾는 방법이나 절차를 기술하는 것 아닌 조건을 기술하여 작성
EMPLOYEE 테이블에서 모든 사원의 정보를 조회
SELECT * FROM EMPLOYEE;\
📃 컬럼 값 산술 연산
컬럼 값 : 테이블의 한 칸(--한 셀)에 작성된 값(DATA)
📃 오늘 날짜 조회
- SYSDATE : 시스템상의 현재 날짜
(년,월,일,시,분,초 단위까지 표현 가능) - DUAL(DUmmy tAbLe) : 가짜 테이블(암시 테이블, 단순 조회 테이블)
📃 컬럼 별칭 지정
SELECT 조회 결과의 집합인 RESULT SET에 컬럼명을 지정
1) 컬럼명 AS 별칭 : 띄어쓰기X, 특수문자X, 문자
2) 컬럼명 별칭 : 1)번에서 AS 생략 한 것
3) 컬럼명 AS "별칭" : 띄어쓰기O, 특수문자O, 문자O
4) 컬럼명 "별칭" : 3)번에서 AS만 생략 한 것
📃 DB에서의 리터럴
임의로 지정한 값을 기존 테이블에 존재하는 값처럼 사용 -> 리터럴 표기법 '' (홑따옴표)
📃 DISTINCT
조회 시 컬럼에 포함된 중복 값을 한 번만 표시할 때 사용
💡 주의사항
1) DISTINCT는 SELECT문에 딱 한번만 작성할 수 있다.
2) DISTINCT는 SELECT문 가장 앞에 작성 되어야 한다.
📌 WHERE절 : 테이블에서 조건을 충족하는 값을 가진 행만 조회하고자 할 때 사용
📃 비교 연산자 : >,<.>=,<=,=(같다),!= , <>(같지 않다)
📃 논리 연산자 (AND, OR)
📃 컬럼명 BETWEEN A AND B : 컬럼 값이 A이상 B이하인 경우
📃 컬럼명 NOT BETWEEN A AND B : 컬럼 값이 A미만, B초과인 경우
📃 LIKE : 비교하려는 값이 특정한 패턴을 만족 시키면 조회하는 연산자
WHERE 컬럼명 LIKE '패턴'
💡 LIKE 패턴(와일드카드) : '%' (포함), '_' (글자 수)
- '%' 예시**
1) 'A%' : 문자열이 A로 시작하는 모든 컬럼 값
2) '%A' : 문자열이 A로 끝나는 모든 컬럼 값
3) '%A%' : 문자열에 A가 포함되어 있는 모든 컬럼 값
* '-' 예시
1) 'A_' : A 뒤에 아무거나 한 글자
2) '___A' : A 앞에 아무거나 세 글자 (4글자 문자열이면서 A로 끝나야 함)
❓ 문제점 : 와일드 카드 문자()와 패턴에 사용된 일반 문자()의 모양이 같아서 문제 발생
해결 방법 : ESCAPE OPTION을 이용하여 일반 문자로 처리함 '','%' 앞에 아무 특수문자나 붙임
📃 IN연산자
비교하려는 값과 목록에 작성된 값 중 일치하는 것이 있으면 조회하는 연산자
OR 연산을 연달아 작성한 효과
✍ [작성법]
컬럼명 IN (값1, 값2, 값3...)
📃 연결 연산자 (||)
-- 여러 값을 하나의 컬럼 값으로 연결하는 연산자
-- (자바의 문자열 +(이어쓰기) 효과)
📃 NULL 처리 연산자
-- JAVA 에서 NULL : 참조하는 객체가 없다.
-- DB에서 NULL : 컬럼 값이 없다.
1) IS NULL : 컬럼 값이 NULL 인 경우 조회
2) IS NOT NULL : 컬럼 값이 NULL이 아닌 경우 조회
📃 ORDER BY 절
SELECT문의 조회 결과(RESULT SET)를 정렬할 때 작성하는 구문
SELECT문 가장 마지막에 해석
✍ [작성법]
3 : SELECT 컬럼명 AS 별칭, 컬럼명, 컬럼명 ....
1 : FROM 테이블명
2 : WHERE 조건식
4 : ORDER BY 컬럼명 | 별칭 | 컬럼 순서 [정렬방식(오름/내림)][NULLS FIRST | LAST]
📃 ORDER BY + ASC : 오름차순 정렬
📃 ORDER BY + DESC : 내림차순 정렬
📃 정렬 중첩
큰 분류를 먼저 정렬하고 내부에 작은 분류를 정렬
SELECT EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
ORDER BY DEPT_CODE, SALARY DESC;
