[EDA] Pandas 기초: 데이터 읽기, Series와 Data Frame, 데이터 정렬/선택/추가/삭제, apply()
제로 베이스: 서울시 CCTV 현황 데이터 분석
1. pandas로 csv, excel 파일 읽기
import pandas as pd- 원하는 모듈이 설치되어 있다면 import 명령으로 사용하겠다고 선언한다.
- pandas 모듈을 부를건데, 이걸 pd라고 앞으로 부르겠다
from Module import function- Module 안에 있는 function 하나만 부르고 싶다면 위와 같이 선언한다.
CCTV_Seoul = pd.read_csv(
"../data/01. Seoul_CCTV.csv",
endoding="utf-8"
)- csv: comma separated values의 약자로, 콤마로 구분된 값들이라는 뜻!
- csv는 띄어쓰기로 통상 구분되어서 그냥 read_csv 명령으로 읽기만 해도 된다.
- 긴 파일명을 끝까지 입력하지 말고 적당한 곳에서 TAB 키를 눌러보자 (근데 colab은 TAB이 동작 안함)
- 한글은 encoding 설정이 필수!
< pandas dataframe 구조 >
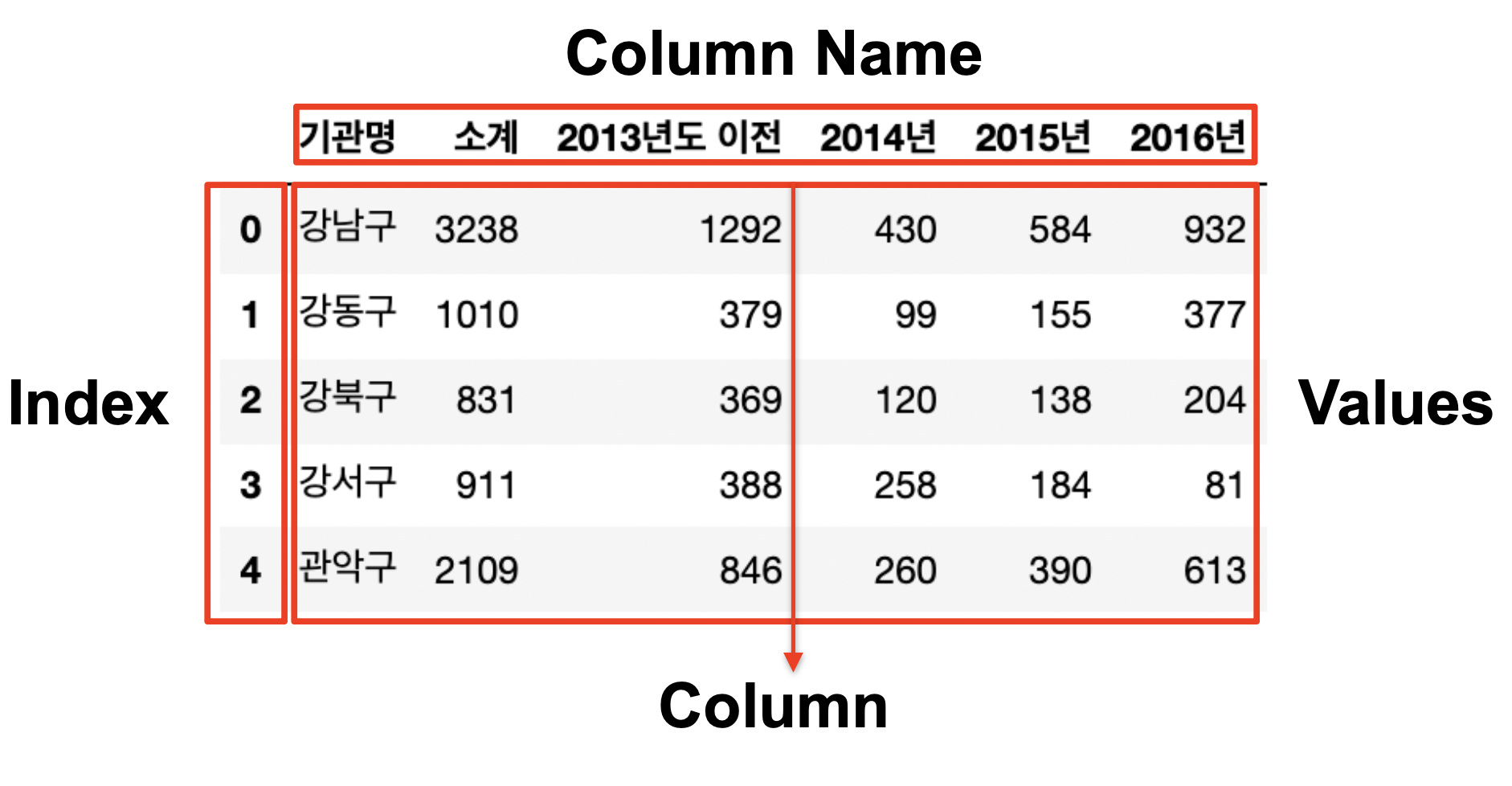
# column 이름 조회
CCTV_Seoul.columns
CCTV_Seoul.columns[0]
# df.rename: column 이름 변경하기
# inplace => 실제로 데이터의 column 이름을 바꾸겠다, default가 False임.
# header=2: 위에서 2번 줄이 header라고 명시
# usecols= : 필요한 컬럼만 선택2. Data Frame 생성하기
- Pandas의 데이터형을 구성하는 기본은 Series: index와 value로 구성
- 한가지 데이터 타입만 가질 수 있음.
- Seriese들이 여러 개 모인 것이 Data Frame!
- Series는 컬럼 한줄 한줄을 의미함
pd.Series([1,2,3,4]) #dtype: int64
pd.Series([1,2,3,4], dtype=np.float64) #dtype: float64
pd.Series([1,2,3,4], dtype=str) #dtype: object
pd.Series(np.array([1,2,3])) #dtype: int64
data = pd.Series([1,2,3,4, "5"]) #dtype: object- 날짜 데이터:
pd.date_range("날짜", periods=n)로 입력한 날짜로부터 n일 간의 날짜 생성
# 20240501부터 기준으로 6일간의 데이터가 생성됨.
dates = pd.date_range("20240501", periods=6)
dates
...
DatetimeIndex(['2024-05-01', '2024-05-02', '2024-05-03', '2024-05-04',
'2024-05-05', '2024-05-06'],
dtype='datetime64[ns]', freq='D')pd.DataFrame(): values, index, columns로 구성
import numpy as np
df = pd.DataFrame(
np.random.randn(6,4),
# numpy 내장함수로 6행 4열(총 24개)의 랜덤요소 생성
index=dates,
columns=["A", "B", "C", "D"]
)3. 데이터 훑어보기
여러 간단한 기능
df.head() #위에서부터 기본 5개, 숫자 지정도 가능
df.tail() #아래에서부터 기본 5개, 숫자 지정도 가능
df.index #index 가져오기
df.columns #columns 가져오기
df.values #values 가져오기
df.info() #데이터 프레임의 기본 정보 확인: 컬럼의 크기와 데이터 형태 확인
df.describe() #데이터 프레임의 기술 통계 정보 확인 (count, mean, std, min, max, 25%, 50%, 75%)데이터 정렬
sort_values(): 특정 컬럼(열)을 기준으로 데이터를 정렬한다.- ascending=False 이면 내림차순 (True=오름차순이 디폴트)
- inplace=Ture까지 해줘야 원본 데이터가 변경됨.
df.sort_values(by="B", ascending=False, inplace=True)데이터 선택
1) 한 개 컬럼 선택
df["A"] #index와 A컬럼의 value 출력
type(df["A"]) #pandas.core.series.Series
df.A #컬럼명이 알파벳이면 'A'로 아예 지정해서 불러올 수도 있음 (숫자X)2) 두 개 이상 컬럼 선택
# 리스트 안에 리스트로 또 담아줘야 함
df[["A", "B"]]3) offset index
[n:m]: n부터 m-1까지- 인덱스나 컬럼의 이름으로 slice하는 경우는 끝(m)을 포함함
df[0:3]
# 1번째 행부터 3번째 행까지만 불러와짐
df["2024-05-01":"2024-05-04"]
# 1번째 행부터 4번째 행까지 불러와짐. 즉 끝이라고 지정한 행까지 불러와짐.4) loc과 iloc
loc[]: location- 인덱스와 컬럼의 이름을 사용 가능
df.loc[:, ["A", "B"]]
# 인덱스는 전부 다 가져오고, 컬럼은 A,B만 가져와라
df.loc["2024-05-01":"2024-05-04", ["A", "D"]]
#1번째 행부터 4번째 행까지, A와 D 컬럼만 불러와짐.
df.loc["2024-05-01":"2024-05-04", "A":"D"]
# 컬럼에서 offset index 활용해서 A부터 D까지 불러옴. 즉, D컬럼이 포함됨!iloc[]: integer location- 특정 행/컬럼의 순서(위치)를 기반으로 인덱싱
- 컴퓨터가 인식하는 인덱스 값으로 선택
df.iloc[3] # 3번째 행의 데이터
df.iloc[3,2] #3번째 행, 2번째 컬럼의 데이터만 불러와짐
df.iloc[1:3, 1:3] # 1~2행, 1~2열만 불러와짐. 즉, 3번째 행과 3번째 열이 빠졌음.
df.iloc[:, 1:3] # 모든 행, 1~2컬럼만 불러옴.5) condition 활용
- df[condition]와 같이 사용하는 것이 일반적
df[df["A"]>0]
# 값이 0보다 큰 것만 불러오고, 0보다 작은 값의 자리에는 NaN(Not a Number, 데이터가 없다는 뜻)가 들어감.데이터 추가/수정
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
isin(): 특정 요소가 있는지 확인
df["E"] = ["one", "two", "three", "four", "five", "six"] # 컬럼 E를 추가
df[df["E"].isin(["two","five"])] #E컬럼의 값이 two, five인 데이터 불러오기특정 컬럼 제거
del삭제할 컬럼drop(삭제할 컬럼, axis=)- axix=0 가로, axis=1 세로
del df["E"] #E컬럼 삭제
df.drop(["D"], axis=1) #D컬럼 삭제apply(함수)
apply(함수)데이터에 특정 함수를 적용시킴
df["A"].apply("sum")
df["A"].apply("mean")
df["A"].apply("min"), df["A"].apply("max")
df.apply(np.sum) #전체 컬럼에 대한 sum
df["A"].apply(np.cumsum) # A컬럼의 누적 합
# 직접 함수를 만들어보고 데이터 프레임에 적용해보기
def plusminus(num):
return "plus" if num > 0 else "minus"
df["A"].apply(plusminus)
...
2024-05-01 minus
2024-05-02 minus
2024-05-03 plus
2024-05-04 minus
2024-05-05 minus
2024-05-06 plus4. 두 데이터 합치기
Pandas에서 데이터 프레임을 병합하는 방법 3가지
- pd.concat()
- pd.merge()
- pd.join()
[ pd.merge() ]
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 함
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 함
예시 데이터 프레임 만들기

# 딕셔너리 안의 리스트 형태
left = pd.DataFrame({ # 컬럼의 값을 순서대로 나열
"key": ["K0", "K4", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]
})
# 리스트 안의 딕셔너리 형태: 행의 값을 순서대로 나열
right = pd.DataFrame([
{"key": "K0", "C":"C0", "D": "D0"},
{"key": "K1", "C":"C1", "D": "D1"},
{"key": "K2", "C":"C2", "D": "D2"},
{"key": "K3", "C":"C3", "D": "D3"},
])pd.merge(left, right, on="", how="")
- on: 기준이 되는 컬럼
- how: merge하는 방법 (디폴트: inner라는 교집합)
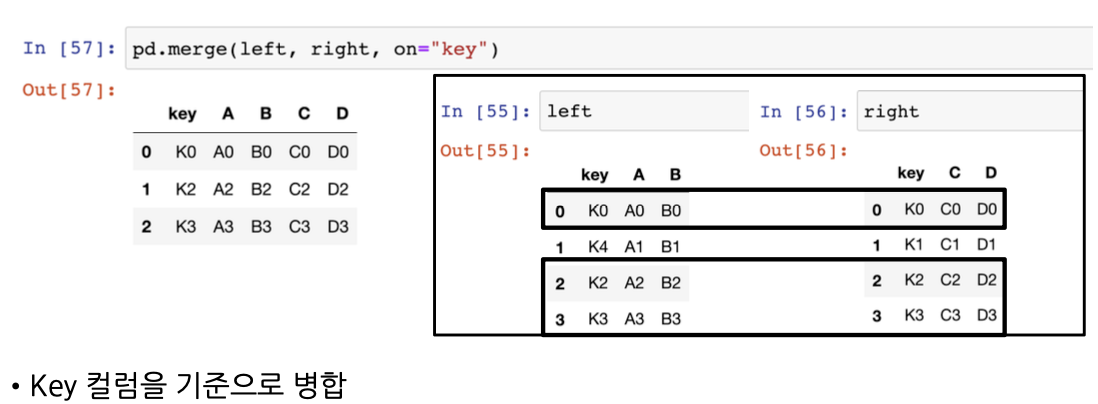
pd.merge(left, right, on="key")
# key 컬럼을 기준으로 left와 right 데이터 프레임을 합치겠다
# #how의 디폴트: inner -> key 컬럼에서 공통으로 가지고 있는 값에 대해서만 합쳐짐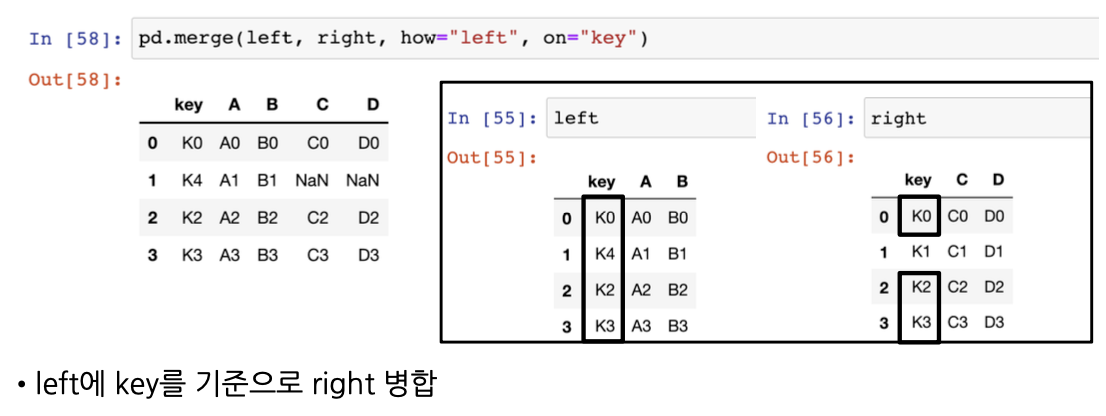
pd.merge(left, right, how="left", on="key")
# key 컬럼을 기준으로 left와 right 데이터 프레임을 합치겠다
# 하지만 left에 있는 값을 기준으로 합쳐라
# right에는 존재하지 않는 K4 행의 값이 NaN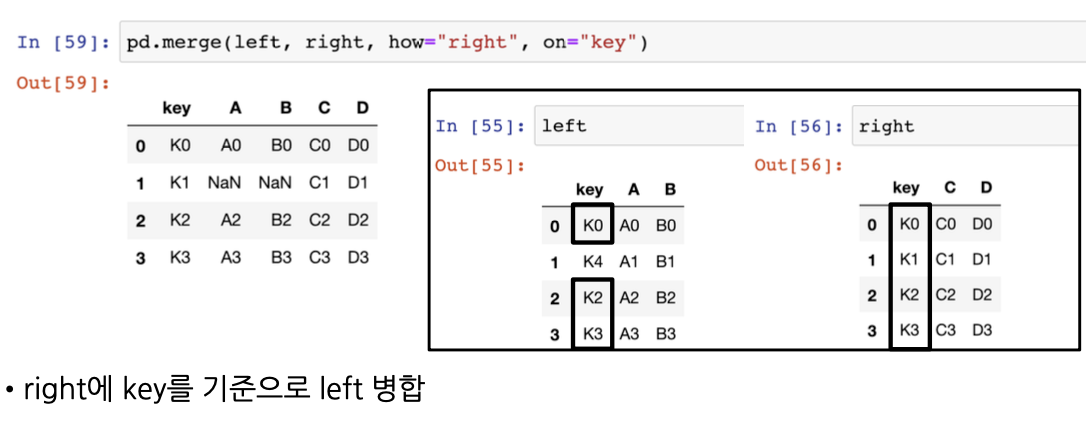
pd.merge(left, right, how="right", on="key")
# key 컬럼을 기준으로 left와 right 데이터 프레임을 합치겠다
# 하지만 right에 있는 값을 기준으로 합쳐라
# left에는 존재하지 않는 K1 행의 값이 NaN
pd.merge(left, right, how="outer", on="key")
# key 컬럼을 기준으로 left와 right 데이터 프레임을 합치겠다
# 하지만 outer인 합집합으로서, key에 있던 없던 다 합쳐라
# left에는 존재하지 않는 K1 행의 값이 NaN, right에는 존재하지 않는 K4 행의 값이 NaN인덱스 변경 set_index()
set_index(): 선택한 컬럼을 데이터 프레임의 인덱스로 지정
data_result.set_index("구별", inplace=True)
data_result.head()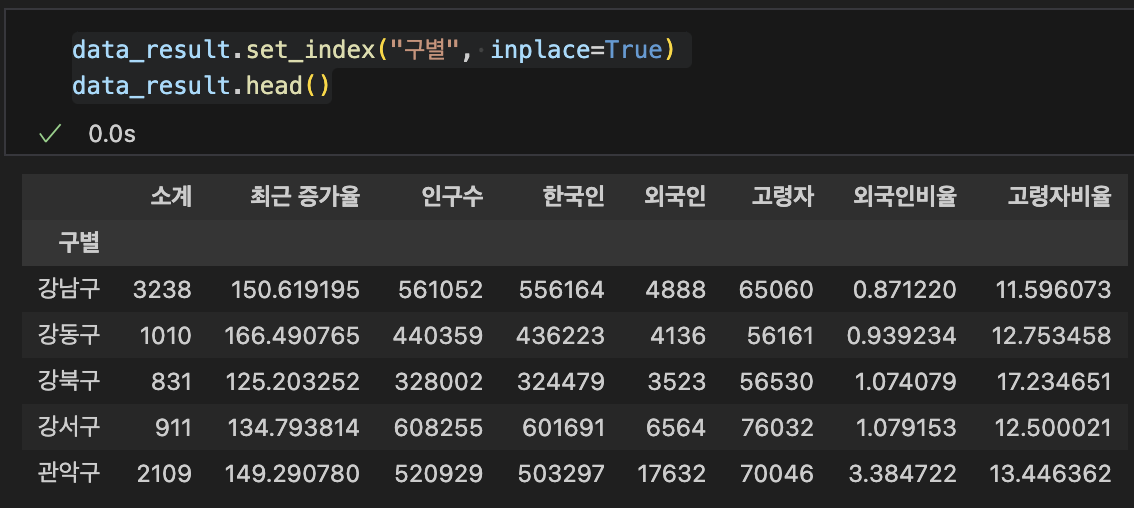
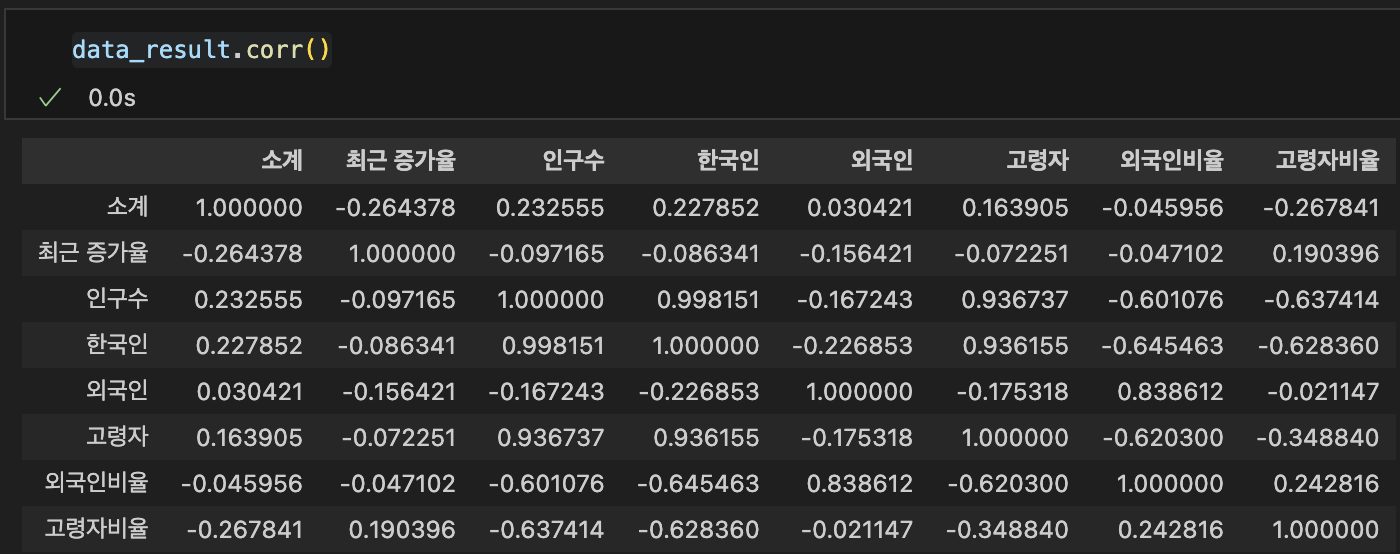
상관계수 corr()
- correlation의 약자
- 상관계수가 0.2 이상인 데이터를 비교
- int, float 타입만 사용 가능 (object X)