[자료 구조] 리스트: for/while 반복문, enumerate(), append, insert, pop, del, remove, extend, sort, reverse, slice, index, count
0
자료 구조
- 자료구조란? 여러 개의 데이터가 묶여있는 자료형을 컨테이너 자료형이라고 하고, 이러한 컨테이너 자료형의 데이터 구조를 자료구조라고 한다.
- 리스트(List): 데이터를 언제든지 바꿀 수 있음. 중복된 데이터가 존재할 수 있음.
- students = ['홍길동', '박찬호', '이용규', '박찬호']
- 튜플(Tuple): 한번 정해진 데이터는 변경할 수 없음. 중복된 데이터가 존재할 수 있음.
- jobs = ('의사', '속기사', 전기기사, ' 속기사')
- 딕셔너리(Dic): key-value 쌍으로 이루어짐.
- scores = {'kor':88, 'eng':91, 'math':95}
- 셋트(Set): 중복된 데이터가 허용되지 않음.
- allSales = {100, 150, 90, 110}
리스트(List)
- 배열과 같이 여러 개의 데이터를 나열한 자료 구조
- []를 이용해서 선언하며, 데이터(=아이템) 구분은 ','를 이용한다.
- 아이템(요소)로 구성되어 있다.
- 숫자, 문자열, 논리형 등 모든 기본 데이터를 같이 저장할 수 있다.
- strs = [3.14, '십', 20, 'one']
- 리스트에 또 다른 컨테이너 자료형 데이터를 저장할 수도 있다.
- datas = [10, 20, 30, [40, 50]]
- 인덱스: 아이템에 자동으로 부여되는 번호표
- 무조건 0번째부터 시작하며, 인덱스를 사용해 데이터를 변경할 수 있다.
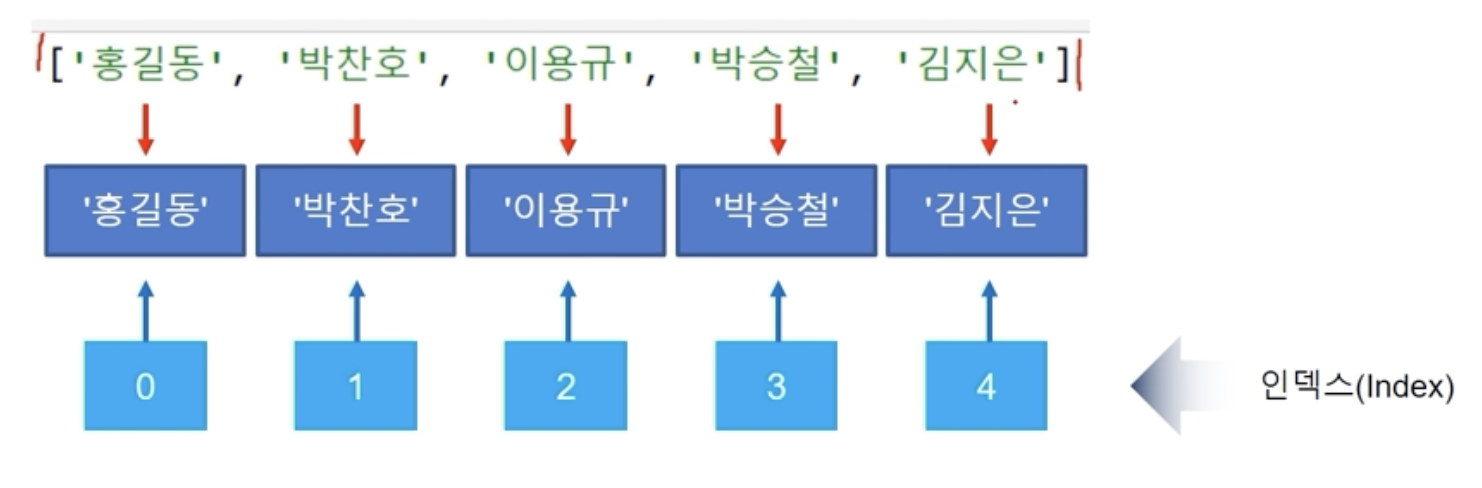
- 무조건 0번째부터 시작하며, 인덱스를 사용해 데이터를 변경할 수 있다.
- 리스트의 아이템은 인덱스를 이용해 조회할 수 있다.
- students[0] 과 같이 조회해서 아이템을 불러올 수 있다.
- students[5] 와 같이 인덱스 범위 밖에 있는 데이터를 불러오려고 하면 에러가 발생한다: IndexError: list index out of range
- 리스트 길이: 리스트에 저장된 아이템 개수 -> len()으로 조회
- students = ['홍길동', '박찬호', '이용규', '박찬호', '김지은']
- students 리스트 길이: len(students) = 5
- len('Hello python!!') 과 같이 문자열의 길이도 조회할 수 있다.
- for문을 이용해 리스트의 아이템을 자동으로 참조할 수 있다.
students = ['홍길동', '박찬호', '이용규', '박찬호', '김지은']
for i in range(len(students)):
print(students[i])
for student in students:
print(student)
for i in range(len(studentCnts)):
print(f'{studentCnts[i][0]}학급 학생수: {studentCnts[i][1]}')
# => 이 방법은 코드 쓰기도 불편하고 가독성이 떨어짐
studentCnts = [[1, 19], [2, 20], [3,22]]
for classNo, cnt in studentCnts:
print(f'{classNo}학급 학생수: {cnt}')
<Output>
1학급 학생수: 19
2학급 학생수: 20
3학급 학생수: 22< 파이썬 실습>
minScore = 75
scores = [['kor', 50], ['eng', 100], ['math',70]]
for subject, score in scores:
if score < minScore:
print(f'{subject} 과목 {score}점으로 점수 미달, 과락되었습니다. ')
for subject, score in scores:
if score >= minScore: continue
print(f'{subject} 과목 {score}점으로 점수 미달, 과락되었습니다. ')
for item in scores:
if item[1] < minScore:
print(f'{item[0]} 과목 {item[1]}점으로 점수 미달, 과락되었습니다. ')
<Output>
kor 과목 50점으로 점수 미달, 과락되었습니다.
math 과목 70점으로 점수 미달, 과락되었습니다. - while문을 이용하면 다양한 방법으로 아이템 조회가 가능하다.
students = ['홍길동', '박찬호', '이용규', '박찬호', '김지은']
n = 0
while n < len(students):
print(students[n])
n += 1
n = 0
flag = True
while flag:
print(students[n])
n += 1
if n == len(students):
flag = False
n=0
while True:
print(students[n])
n += 1
if n ==len(students):
break
<Output>
홍길동
박찬호
이용규
박찬호
김지은
minScore = 75
scores = [['kor', 50], ['eng', 100], ['math',70]]
n=0
while n < len(scores):
if scores[n][1] < minScore:
print(f'{scores[n][0]} 과목 {scores[n][1]}점으로 점수 미달, 과락되었습니다. ')
n += 1
n=0
while True:
if scores[n][1] < minScore:
print(f'{scores[n][0]} 과목 {scores[n][1]}점으로 점수 미달, 과락되었습니다. ')
n += 1
if n == len(scores):
break
<Output>
kor 과목 50점으로 점수 미달, 과락되었습니다.
math 과목 70점으로 점수 미달, 과락되었습니다. enumerate() 함수
- enumerate() 함수: 아이템 열거하는 기능이며, 문자열에도 적용 가능
str = 'Hello'
for idx, value in enumerate(str):
print(f'{idx+1}번째 문자열: {value}')
sports = ['농구', '배구', '축구', '야구']
for idx, value in enumerate(sports):
print(f'{idx+1}번째 스포츠: {value}')
<Output>
1번째 문자열: H
2번째 문자열: e
3번째 문자열: l
4번째 문자열: l
5번째 문자열: o
1번째 스포츠: 농구
2번째 스포츠: 배구
3번째 스포츠: 축구
4번째 스포츠: 야구
# 실습: 사용자가 입력한 문자열에서 공백의 개수를 출력해보자.
str = input('문자열 입력: ')
n = 0
for idx, value in enumerate(str):
if value == ' ':
n += 1
print(f'{idx+1}번째 값은 공백')
print(f'<{str}>에서 공백은 총 {n}개입니다.')
<Output>
문자열 입력: 안 녕 하 세 요? 만나서 반갑습니다.
2번째 값은 공백
4번째 값은 공백
6번째 값은 공백
8번째 값은 공백
11번째 값은 공백
15번째 값은 공백
<안 녕 하 세 요? 만나서 반갑습니다.>에서 공백은 총 6개입니다.- 리스트의 마지막 인덱스에 아이템 추가: append(아이템)
- 리스트의 특정 위치(인덱스)에 아이템 추가: insert(인덱스, 아이템)
- append와 insert에서 넣는 값이 리스트형태이면, 리스트 형태로 들어감. extend에서 넣는 값이 리스트형태이면, 리스트가 아니라 그 안의 요소 그대로 들어감.
# 오름차순으로 정렬되어 있는 숫자들에 사용자가 입력한 정수를 추가하는 프로그램 만들기 (추가 후에도 오름차순 정렬은 유지되어야 함)
numbers = [1, 3, 8, 10, 25, 39, 42, 50]
inputNumber = int(input('숫자 입력: '))
insertIdx = 0
for idx, value in enumerate(numbers):
if insertIdx == 0 and inputNumber < value:
insertIdx = idx
numbers.insert(insertIdx, inputNumber)
print(numbers)
<Output>
숫자 입력: 14
[1, 3, 8, 10, 14, 25, 39, 42, 50]- 리스트의 마지막 인덱스의 아이템 삭제: pop() -> 인자 없이 사용
- 리스트의 특정 위치의 아이템 삭제: pop(idx)
sports = ['농구', '배구', '축구', '야구']
print(f'sports: {sports}')
sportsPop = sports.pop() #삭제한 아이템이 담김
print(f'sportsPop: {sportsPop}')
print(f'pop(): {sports}')
sports = ['농구', '배구', '축구', '야구']
sportsPop1 = sports.pop(1) #삭제한 아이템이 담김
print(f'sportsPop1: {sportsPop}')
print(f'pop(1): {sports}')
--------------------------------------------------
<Output>
sports: ['농구', '배구', '축구', '야구']
sportsPop: 야구
pop(): ['농구', '배구', '축구']
sportsPop1: 야구
pop(1): ['농구', '축구', '야구']- 리스트의 특정 아이템 삭제: remove()
- 한 개의 아이템만 삭제 가능. 2개 이상 아이템 삭제할 때는 while문 사용.
sports = ['농구', '배구', '축구', '야구']
sports.remove('축구')
print(f'sports.remove(\'축구\'): {sports}')
<Output>
sports.remove('축구'): ['농구', '배구', '야구']
--------------------------------------------------
sports = ['농구', '배구', '축구', '야구', '축구']
while '축구' in sports:
sports.remove('축구')
print(f'sports에서 모든 \'축구\' 삭제: {sports}')
<Output>
sports에서 모든 '축구' 삭제: ['농구', '배구', '야구']- 리스트에 또 다른 리스트 연결(확장)하는 방법
- extend(): A리스트에 B리스트가 추가되어 A리스트가 확장되는 방식
- 덧셈 연산자 이용: A리스트+B리스트를 합치면 C리스트라는 새로운 리스트가 생성됨
group1 = ['유재석', '하하', '박명수']
group2 = ['장원영', '차은우']
print(f'group1: {group1}')
print(f'group2: {group2}')
group1.extend(group2)
print(f'extend 후 group1: {group1}')
print(f'extend 후 group2: {group2}')
group1 = ['유재석', '하하', '박명수']
group2 = ['장원영', '차은우']
result = group1 + group2
print(f'덧셈 후 group1: {group1}')
print(f'덧셈 후 group2: {group2}')
print(f'덧셈한 result: {result}')
<Output>
group1: ['유재석', '하하', '박명수']
group2: ['장원영', '차은우']
extend 후 group1: ['유재석', '하하', '박명수', '장원영', '차은우']
extend 후 group2: ['장원영', '차은우']
덧셈 후 group1: ['유재석', '하하', '박명수']
덧셈 후 group2: ['장원영', '차은우']
덧셈한 result: ['유재석', '하하', '박명수', '장원영', '차은우']- 리스트의 아이템 정렬: sort()
- sort(): 오름차순 정렬
- sort(reverse=True): 내림차순 정렬
group = ['유재석', '하하', '박명수', '장원영', '차은우']
group.sort()
print(f'group.sort(): {group}')
group.sort(reverse=True)
print(f'group.sort(reverse=True): {group}')
<Output>
group.sort(): ['박명수', '유재석', '장원영', '차은우', '하하']
group.sort(reverse=True): ['하하', '차은우', '장원영', '유재석', '박명수']- 리스트의 아이템 순서를 뒤집기: reverse()
group = ['유재석', '하하', '박명수', '장원영', '차은우']
group.reverse()
print(f'group.reverse: {group}')
<Output>
group.reverse: ['차은우', '장원영', '박명수', '하하', '유재석']- 리스트 슬라이싱:
- [n:m] 인덱스 활용해 n보다 크거나 같고 m보다 작은 아이템 불러오기
- 숫자, 문자열 자체도 슬라이싱할 수 있다.
- 값을 변경할 수도 있다. 갯수가 맞지 않으면 기존 데이터가 삭제될 수도 있다.
- slice(시작idx, 끝idx)
- [n:m] 인덱스 활용해 n보다 크거나 같고 m보다 작은 아이템 불러오기
group = ['유재석', '하하', '박명수', '장원영', '차은우', '이제훈']
print(f'group: {group}')
print(f'group[1:3]: {group[1:3]}')
print(f'group[:2]: {group[:2]}')
print(f'group[2:]: {group[2:]}')
print(f'group[2:-2]: {group[2:-2]}') #-1: 이제훈, -2: 차은우 이기 때문에 -3:장원영까지임.
print(f'group[-5:-2]: {group[-5:-2]}') #-5:하하 ~ -3: 장원영
<Output>
group: ['유재석', '하하', '박명수', '장원영', '차은우', '이제훈']
group[1:3]: ['하하', '박명수']
group[:2]: ['유재석', '하하']
group[2:]: ['박명수', '장원영', '차은우', '이제훈']
group[2:-2]: ['박명수', '장원영']
group[-5:-2]: ['하하', '박명수', '장원영']
--------------------------------------------------
numbers = [0,1,2,3,4,5,6,7,8,9]
print(f'numbers: {numbers}')
print(f'numbers[2:-2]: {numbers[2:-2]}')
print(f'numbers[2:-2:3]: {numbers[2:-2:3]}') #세번쨰 인자인 3은 처음 아이템부터 3번째 아이템 간격으로 추출
print(f'numbers[:-2:2]: {numbers[:-2:2]}') # 처음 아이템부터 -3까지 추출하는데 2개 간격으로 추출
print(f'numbers[::2]: {numbers[::2]}') #모든 아이템 추출하는데 2개 간격으로 추출
<Output>
numbers: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
numbers[2:-2]: [2, 3, 4, 5, 6, 7]
numbers[2:-2:3]: [2, 5]
numbers[:-2:2]: [0, 2, 4, 6]
numbers[::2]: [0, 2, 4, 6, 8]
--------------------------------------------------
numbers[1:4] = [10, 20, 30]
print(f'numbers 1:4 변경한 결과: {numbers}')
<Output>
numbers 1:4 변경한 결과: [0, 10, 20, 30, 4, 5, 6, 7, 8, 9]
----------------slice() 사용하기-------------------------------
numbers = [0,1,2,3,4,5,6,7,8,9]
print(f'numbers: {numbers}')
print(f'numbers[slice(2,4)]: {numbers[slice(2,4)]}')
print(f'numbers[slice(4)]: {numbers[slice(4)]}')
print(f'numbers[slice(2, len(numbers)-2)]: {numbers[slice(2, len(numbers)-2)]}')
print(f'numbers[slice(len(numbers)-5, len(numbers)-2)]: {numbers[slice(len(numbers)-5, len(numbers)-2)]}')
<Output>
numbers: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
numbers[slice(2,4)]: [2, 3]
numbers[slice(4)]: [0, 1, 2, 3]
numbers[slice(2, len(numbers)-2)]: [2, 3, 4, 5, 6, 7]
numbers[slice(len(numbers)-5, len(numbers)-2)]: [5, 6, 7]- 리스트의 곱셈 연산: 아이템이 반복됨
numbers = [0,1,2,3,4,5]
print(f'numbers: {numbers}')
print(f'numbers: {numbers*3}')
<Output>
numbers: [0, 1, 2, 3, 4, 5]
numbers: [0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5]- index(item) 함수로 아이템의 인덱스를 알아낼 수 있다
group = ['유재석', '차은우', '하하', '박명수', '장원영', '차은우']
print(group.index('차은우'))
print(group.index('차은우', 2, len(group))) #2부터 끝까지 중에 '차은우'의 위치는 어디있느냐
<Output>
1
5- 특정 아이템의 개수: count(아이템)
group = ['유재석', '차은우', '하하', '박명수', '장원영', '차은우']
print(f'group.count(\'차은우\'): {group.count('차은우')}')
print(f'group.count(\'안유진\'): {group.count('안유진')}')
<Output>
group.count('차은우'): 2
group.count('안유진'): 0- 특정 아이템 삭제: del 키워드
group = ['유재석', '차은우', '하하', '박명수', '장원영', '차은우']
print(f'group: {group}')
del group[1]
print(f'del group[1]: {group}')
del group[1:4]
print(f'del group[1:4]: {group}')
<Output>
group: ['유재석', '차은우', '하하', '박명수', '장원영', '차은우']
del group[1]: ['유재석', '하하', '박명수', '장원영', '차은우']
del group[1:4]: ['유재석', '차은우']- isinstance: 자료형이 list인지 확인
isinstance(리스트형변수, list)
...
True