- 위의 사이트에서 SQL문 예제를 실행해 볼 수 있다.
SQL?
Structured Query Language를 의미한다.
데이터베이스에 접근하고 데이터베이스를 다루는 데에 쓰인다.
데이터베이스에서 쿼리를 실행하고, 데이터베이스로부터 데이터를 가져오고, 데이터베이스에 정보를 삽입하고/업데이트하고/삭제하고/생성할 수 있다. 또한 새 데이터베이스를 만들거나 데이터베이스에 새 테이블을 만들 수 있다. 데이터베이스에 저장된 프로시저를 생성하거나 데이터베이스에서 뷰를 생성하고 테이블, 프로시저, 뷰에 접근 허용을 설정할 수도 있다.
다양한 버전이 존재하고 버전마다 특성이 존재하지만 가장 중요한 명령(SELECT, UPDATE, DELETE, INSERT, WHEHE)은 유사하다.
RDBMS란 Relational Datebase Management System을 의미하며 SQL과 모든 현대 데이터베이스 시스템의 기초이다. RDBMS의 데이터는 테이블이라고 불리는 데이터베이스 객체에 저장된다. 테이블은 서로 관계된 데이터의 모음이고 열과 행으로 구성된다. 테이블은 필드라고 불리는 더 작은 구성요소로 나누어진다. 이는 테이블의 각각의 열이며 테이블에 존재하는 모든 레코드의 특정 정보를 유지하기 위해 만들어졌다. 한 행을 이루는 레코드는 테이블에 존재하는 각각의 요소이다.
SQL Syntax
데이터베이스는 하나 이상의 테이블을 가지는데, 각각의 테이블은 이름을 통해 식별된다. 테이블은 데이터가 있는 레코드(행)을 가진다. 데이터베이스에서 수행할 행동들의 대부분은 SQL문으로 이루어진다. 예를 들면 다음과 같다.
SELECT * FROM Customers; 하나의 SQL문이 끝나면
;을 붙인다. SQL문은 가독성을 위해서 여러 줄에 걸쳐서 작성되는 경우가 많은데;을 각각의 줄마다 쓰지 않도록 주의하자.
SQL SELECT Statement
SELECT문은 데이터베이스에서 데이터를 선택하기 위해 사용된다. 반환된 데이터는 result-set이라고 불리는 결과 테이블에 저장된다.
SELECT column1, column2, ...
FROM TABLE_NAME;column1, column2 등은 데이터를 선택하길 원하는 필드의 이름이다. 모든 필드를 가져올 수도 있다.
SELECT * FROM tanle_name;SQL SELECT DISTINCT Statement
SELECT DISTINCT문은 다른 값만을 반환하기 위해 사용된다. 테이블 안의 열에는 많은 중복된 값이 존재할 때가 많은데, 이때 서로 다른 값만을 가져오고 싶다면 SELECT DISTINCT문을 사용한다.
SELECT DISTINCT column1, column2, ...
FROM table_name;SQL WHERE Clause
WHERE절은 레코드를 필터링하기 위해 사용된다. 이 절은 특정 조건을 만족하는 레코드만 추출한다.
WEHRE절은SELECT문뿐만 아니라 앞으로 등장할 다른 문장에서도 쓰인다.
SELECT column1, column2, ...
FROM table_name
WHEHE condition;SQL은 텍스트 값에 ' (single quote)를 써야 하지만 숫자로 이루어진 필드는 사용하지 않아야 한다.
SELECT * FROM Customers
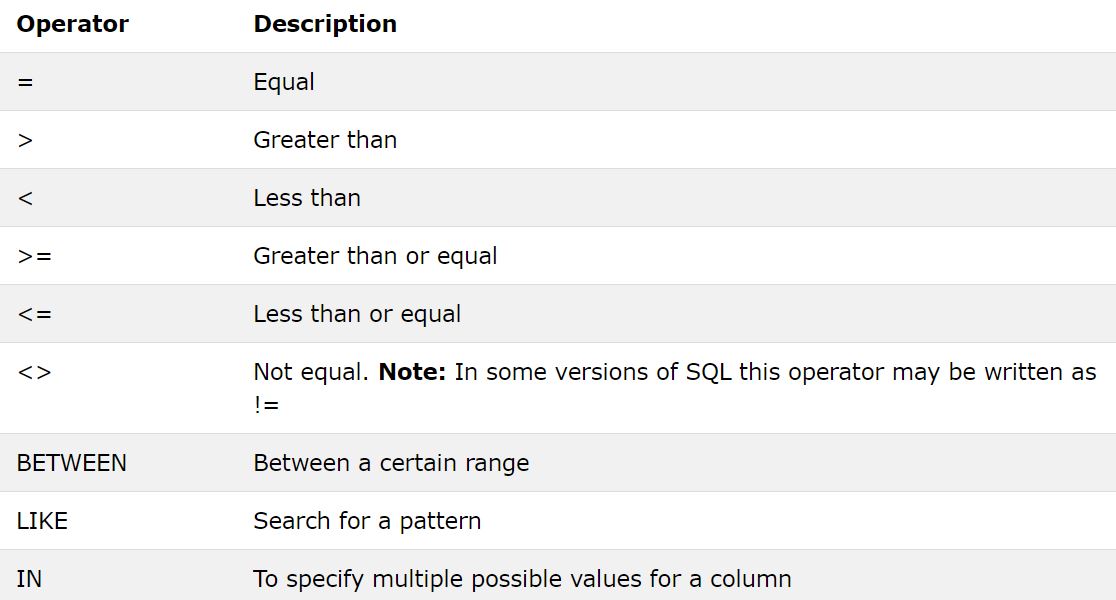
WHERE CustomerID=1;다음의 연산자들이 WHERE절에서 쓰일 수 있다. BETWEEN, LIKE, IN은 이후 살펴볼 것이다.
SQL AND, OR and NOT Operators
WHERE절은 AND, OR, NOT 연산자와 함께 쓰일 수 있다. AND와 OR 연산자는 하나 이상의 조건에 기반해 레코드를 필터링한다. NOT 연산자는 조건을 만족하지 않는 레코드를 보여 준다. 이 연산자들은 함께 쓰일 수 있다. 이때는 의미를 명확히 하기 위해 괄호를 쓰도록 한다.
SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 AND condition3 ...;SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR condition3 ...;SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;SELECT * FROM Customers
WHERE Country = 'Germany' AND (City = 'Berlin' OR City = 'Munchen');SQL ORDER BY Keyword
ORDER BY 키워드는 result-set을 내림차순이나 오름차순으로 정렬하기 위해 사용된다. 기본값은 오름차순이고, 내림차순으로 정렬하기 위해서는 DESC라는 키워드를 사용한다.
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;SQL INSERT INTO Statement
INSERT INTO문은 테이블에 새로운 레코드를 삽입하기 위해 사용된다.
열의 이름과 삽입될 값 둘 다 명시하는 방법으로 삽입할 수 있다.
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);또는 만약 모든 열에 값을 추가하는 경우, 열의 이름을 따로 명시하지 않고 삽입할 수 있다. 이 경우에 테이블에 있는 열의 순서와 삽입할 값이 같은 순서로 되어 있어야 한다.
INSERT INTO table_name
VALUES (value1, value2, value3, ...);SQL NULL Values
NULL값이란 무엇일까? NULL 값으로 이루어진 필드는 값이 없는 필드이다. 만약 테이블에 있는 어떤 필드에 값이 있어도 되고 없어도 되는 경우라면, 이 필드에 값을 넣지 않고 레코드를 업데이트하거나 새로운 레코드를 삽입할 수 있다. 그러면 그 필드는 NULL 값으로 저장된다.
주의: NULL 값은 0 값이나 스페이스로 이루어진 필드와는 다르다! NULL 값으로 된 필드는 레코드 생성 동안 빈칸으로 남겨진 것이다.
=, >, < 같은 비교 연산자로 NULL 값을 테스트하는 것은 불가능하다. 대신 IS NULL과 IS NOT NULL 연산자를 이용해야 한다.
SELECT column_names
FROM table_name
WHERE column_name IS NULL|IS NOT NULL;SQL UPDATE Statement
UPDATE문은 테이블에 존재하는 데이터를 변경하기 위해 사용된다.
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;SQL DELETE Statement
DELETE문은 테이블에 존재하는 데이터를 삭제하기 위해 사용된다.
DELETE FROM table_name WHERE condition;테이블을 지우지 않고 모든 행을 지우는 것도 가능하다. 테이블 구조, 속성, 그리고 인덱스는 유지된다.
DELETE FROM table_name;SQL TOP, LIMIT or ROWNUM Clause
SELECT TOP절은 반환할 레코드의 숫자를 명시하기 위해 사용된다. 이는 큰 테이블에서 유용하다. 많은 수의 레코드를 반환하는 건 성능에 영향을 미칠 수 있다.
주의: 모든 데이터베이스 시스템이
SELECT TOP절을 지원하지는 않는다. 비슷한 기능을 하는 다른 명령어를 사용할 수도 있다. (e.g. MySQL - LIMIT, Oracle - ROWNUM)
- SQL Server / MS Acess Syntax:
SELECT TOP number|percent column_name(s)
FROM table_name
WHERE condition;- MySQL Syntax:
SELECT column_name(s)
FROM table_name
WHERE condition
LIMIT number;- Oracle Syntax:
SELECT column_name(s)
FROM table_name
WHERE ROWNUM <= number;SQL MIN() and MAX() Functions
MIN() 함수는 선택된 열에서 가장 작은 값을 반환한다.
MAX() 함수는 선택된 열에서 가장 큰 값을 반환한다.
SELECT MIN(column_name)
FROM table_name
WHERE condition;SELECT MAX(column_name)
FROM table_name
WHERE condition;SQL Count(), AVG(), and SUM() Functions
COUNT() 함수는 특정 기준을 만족하는 행의 수를 반환한다.
AVG 함수는 숫자로 이루어진 열의 평균값을 반환한다.
SUM() 함수는 숫자로 이루어진 열의 전체 합을 반환한다.
SELECT COUNT(column_name)
FROM table_name
WHERE condition;SELECT AVG(column_name)
FROM table_name
WHERE condition;SELECT SUM(column_name)
FROM table_name
WHERE condition;SQL LIKE Operator
LIKE 연산자는 열에서 특정 패턴을 찾기 위해 WHERE절에서 사용된다. LIKE 연산자와 함께 사용되는 두 가지 와일드카드가 있다.
- % - 0개, 1개, 혹은 여러 개의 글자들을 의미한다.
- _ - 하나의 글자를 의미한다.
SELECT column1, column2, ...
FROM table_name
WHERE columnN LIKE pattern;가령, 다음과 같은 문장은 CustomerName이 a로 시작하는 모든 행을 반환한다.
SELECT * FROM Customers
WHERE CustomerName LIKE 'a%';데이터베이스 시스템마다 사용되는 와일드카드에 차이가 있으므로 확인해 보도록 하자.
SQL IN Operator
IN 연산자는 WHERE절에서 여러 개의 값을 명시할 수 있도록 해 준다. IN 연산자는 여러 개의 OR 연산자를 줄인 것으로 볼 수 있다.
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);SELECT column_name(s)
FROM table_name
WHERE column_name IN (SELECT STATEMENT);SQL BETWEEN Operator
BETWEEN 연산자는 주어진 범위에서 값을 선택한다. 값은 숫자, 텍스트, 날짜가 될 수 있다. 시작값과 끝값을 포함한다.
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;SQL Aliases
SQL aliase는 주어진 테이블이나 열에 일시적인 이름을 주기 위해 사용된다. 열의 이름의 가독성을 높일 수 있다. 쿼리가 동작하는 동안만 존재한다.
SELECT column_name AS alias_name
FROM table_name;SELECT column_name(s)
FROM table_name AS alias_name;SQL JOIN & INNER JOIN Keyword
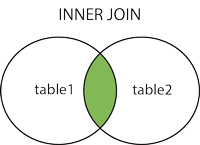
JOIN절은 두 개 이상의 테이블에서 그들 사이에 관계된 열에 기반해서 행을 합치기 위해 사용된다. 예를 들어 주문 테이블과 손님 테이블이 존재할 때, 주문 테이블에서 (손님 테이블과 주문 테이블에 둘 다 존재하는 열인) 손님ID와 일치하는 주문만을 가져오는 문장을 작성할 수 있다.
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;JOIN을 사용해서 문장을 작성할 때에는 table_name.column_name과 같은 형식으로 테이블 이름과 열의 이름을 분명히 명시해 줘야 한다. 다양한 종류의 JOIN이 존재하는데, 차차 살펴보도록 한다.
위의 예시와 같이 두 테이블 둘 다에서 일치하는 값을 가진 레코드를 반환하는 JOIN은 (INNER) JOIN이라고 한다.
INNER JOIN 키워드는 두 테이블 모두에서 일치하는 값을 가진 레코드를 반환한다. 세 테이블에서도 가능한데, 이 경우 두 테이블에서 먼저 INNER JOIN을 수행한 뒤 남은 테이블에 한 번 더 INNER JOIN을 수행한다.
sql
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;
#### SQL LEFT JOIN Keyword
`LEFT JOIN`은 왼쪽 테이블에서 모든 레코드를 반환하고, 오른쪽 테이블에서 매치된 레코드를 반환한다. 만약 오른쪽에서 매치된 것이 없다면 결과값은 NULL이 된다.
> `LETT OUTER JOIN`과 동일한 의미이다.
```sql
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;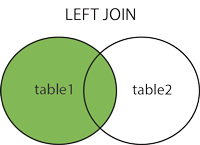
SQL RIGHT JOIN Keyword
RIGHT JOIN은 오른쪽 테이블에서 모든 레코드를 반환하고, 왼쪽 테이블에서 매치된 레코드를 반환한다. 만약 왼쪽에서 매치된 것이 없다면 결과값은 NULL이 된다.
RIGHT OUTER JOIN과 동일한 의미이다.
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;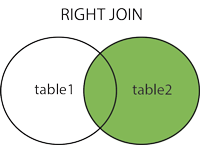
SQL FULL OUTER JOIN Keyword
FULL OUTER JOIN은 왼쪽이나 오른쪽 테이블에서 매치된 모든 레코드를 반환한다.
주의:
FULL OUTER JOIN은 아주 큰 result-set을 반환할 수 있다.
FULL JOIN과 동일하다.
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name = table2.column_name;
WHERE condition;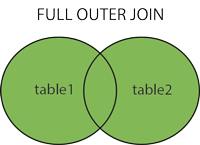
SQL Self JOIN
self JOIN은 보통 JOIN과 같지만 테이블이 자기 자신과 JOIN을 수행한다.
SELECT column_name(s)
FROM table1 T1, table1 T2
WHERE condition;T1과 T2는 동일한 테이블의 다른 별명이다.
다음의 SQL문은 같은 도시에서 온 (다른) 손님들을 매치한다.
SELECT A.CustomerName AS CustomerName1, B.CustomerName AS CustomerName2, A.City
FROM Customers A, Customers B
WHERE A.CustomerID <> B.CustomerID
AND A.City = B.City
ORDER BY A.City;SQL UNION Operator
UNION 연산자는 두 개 이상의 SELECT문의 result-set을 합치기 위해 사용된다.
UNION안의 각각의SELECT문은 같은 수의 열을 가져야 한다.- 열들은 비슷한 데이터 타입을 가져야 한다.
- 각각의
SELECT문의 열들은 같은 순서여야 한다.
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;UNION 연산자는 기본적으로 다른 값만을 선택한다. 중복을 허용하려면 UNION_ALL을 사용한다.
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;주의: result-set의 열의 이름은 보통
UNION문의 첫 번째SELECT문의 열의 이름과 같다.
SELECT City FROM Customers
UNION
SELECT City FROM Suppliers
ORDER BY City;각각의 SELECT문 안에서 WHERE절을 사용할 수도 있다.
SELECT City, Country FROM Customers
WHERE Country='Germany'
UNION
SELECT City, Country FROM Suppliers
WHERE Country='Germany'
ORDER BY City;다음 예시를 보자. AS Type은 별명이다. SQL Aliases는 테이블이나 열에 일시적인 이름을 주기 위해 사용된다. 이들은 쿼리가 동작하는 동안만 존재한다. 그래서, 'Type'이라는 이름의 일시적인 열을 생성하면 선택된 사람을 'Customer'나 'Supplier'로 결과에 출력한다.
SELECT 'Customer' As Type, ContactName, City, Country
FROM Customers
UNION
SELECT 'Supplier', ContactName, City, Country
FROM Suppliers;SQL GROUP BY Statement
GROUP BY문은 같은 값을 가진 행들을 요약 행에서 그룹 짓도록 한다. 하나 이상의 열의 result-set을 그룹 짓도록 해서 주로 집계 함수(COUNT, MAX, MIN, SUM, AVG)와 같이 쓰인다.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;SQL HAVING Clause
HAVING절은 WHERE이 집계 함수와 같이 쓰일 수 없기 때문에 추가되었다. WHERE절과 같은 역할을 한다.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 5;SQL EXISTS Operator
EXISTS연산자는 서브쿼리에 어떤 레코드가 존재하는지 확인하기 위해 사용된다.
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);다음의 SQL문은 TRUE를 반환하고 product price가 20보다 작은 supplier들을 나열한다.
SELECT SupplierName
FROM Suppliers
WHERE EXISTS (SELECT ProductName FROM Products WHERE Products.SupplierID = Suppliers.supplierID AND Price < 20);
오늘도 좋은 설명 감사합니다 덕분에 도움이 많이 됐어요