강의 전체 흐름
- 소프트웨어 개발 프로세스
- 웹서비스 아키텍처 (다룰 내용)
- 백엔드와 프론트엔드 연동
웹 서비스 아키텍처는 웹 서비스를 제공하기 위한 구조와 구성요소를 말함
사용자에게 빠르고 안전한 서비스를 포함함
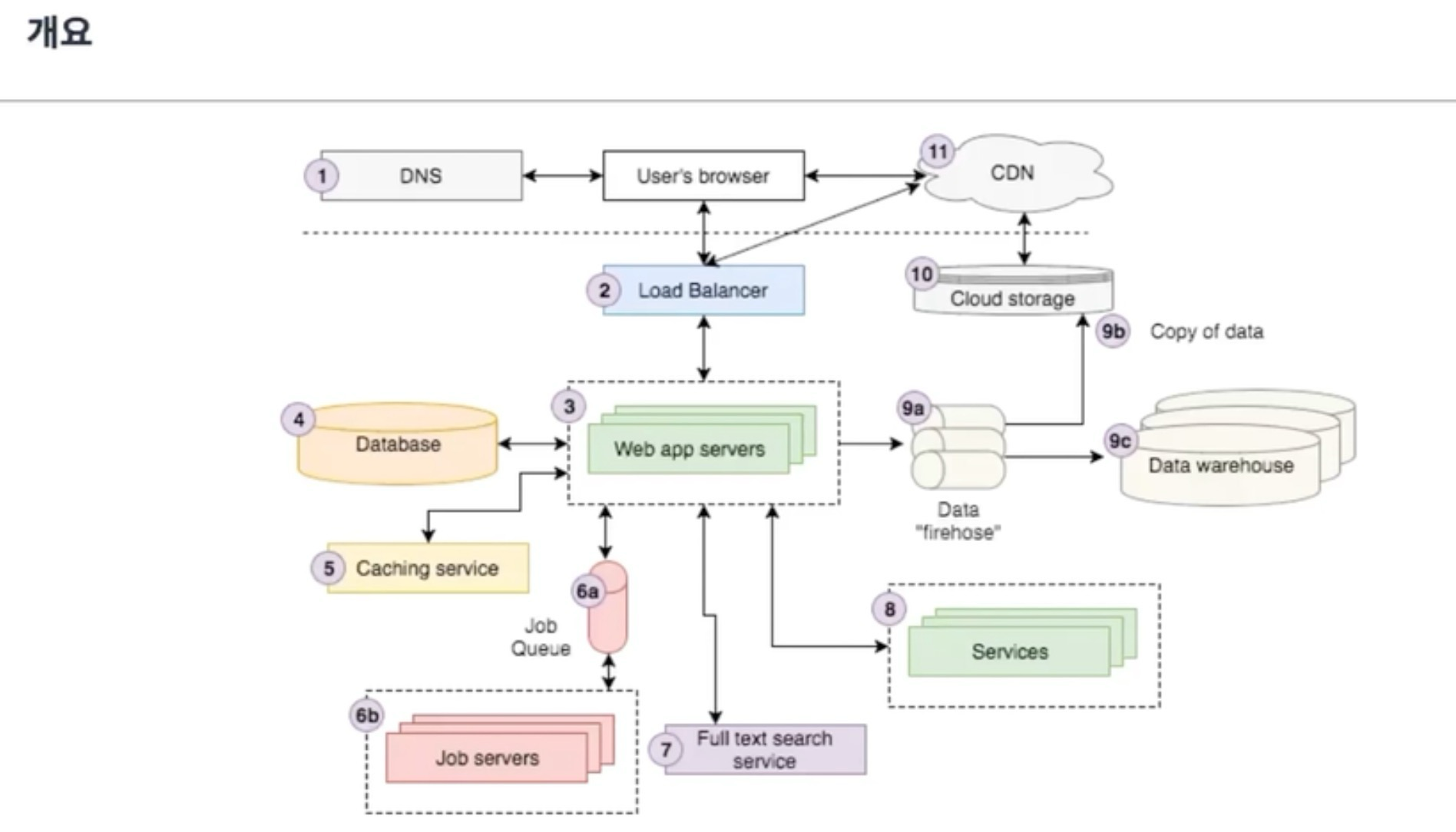
위 이미지는 일반적이 현대 웹 아키텍처 구조라고한다.
그러나 작은 규모의 프로젝트라면 (DNS, 로드밸런서, 프론트, 백엔드, 디비)만 있으면 가능한다.
가장 중요한 핵심 요소를 프론트엔드, 백엔드, 데이터베이스 입니다.
안전적이고 빠른 서비스를 위해 로드밸런서, Job servers, 캐쉬, 검색엔진, 웨어하우스, CDN 등이 있다.
프론트는 모두가 알고 있으니 생략 (UI,UX 등을 중점으로 사용자 상호작용 중심으로 개발)
백엔드는 사용자의 요청을 받아 처리, 필요한 데이터를 가져오고 저장하는 등의 역할을 해줌
보안과 안전, 성능을 고려하여 로직을 작성한다.
데이터베이스는 데이터를 저장하고 관리하는 시스템 (일반적으로 RDMBS를 사용, 최근에는 몽고DB등 NoSQL등도 사용 됨)
캐싱은 자주 사용되는 데이터나 계산결과를 매우 빠른 시간에 가져오기 위한 구성요소 (Redis 등이 많이 사용됨)
변경이 적고 조회가 자주되는 데이터 등에 자주 사용됨
Job servers 사용자요청에 직접적으로 관련없는 작업을 큐에 넣고 Job servers 순차적으로 실행
(예를 들어 회원가입 후 이메일로 가입 축하 이메일을 보내는 등의 로직)
전문 검색 서비스(Full text search service) 는 사용자가 텍스트로 검색했을때 데이터베이스에서 직접 검색하게되면 성능 저하 , 과부하가 일어날 수 있으므로 검색엔진을 사용하여 형태소 단위로 문서를 나눈 뒤 럭인덱스를 활용해
특정 문서 데이터를 빠르게 찾아 올 수 있다. (엘라스틱 서치를 많이 사용)
클라우드 스토리지 웹 애플리케이션의 데이터를 저장하고 관리하는데 사용
클라우드 서비스가 일반화되면서 S3 등의 클라우드 스토리지를 사용함 (많은 데이터량을 적재, 안전성이 뛰어남)
CDN 웹 컨텐츠를 사용자에게 빠르게 전달할 수 있음 (한국<->미국 등 대륙간에 서비스 전달을 빠르게 수신,발신 처리하는 방식)
클라이언트-서버 모델
기본 개념과 작동 원리, 각 역할과 장단점 ..
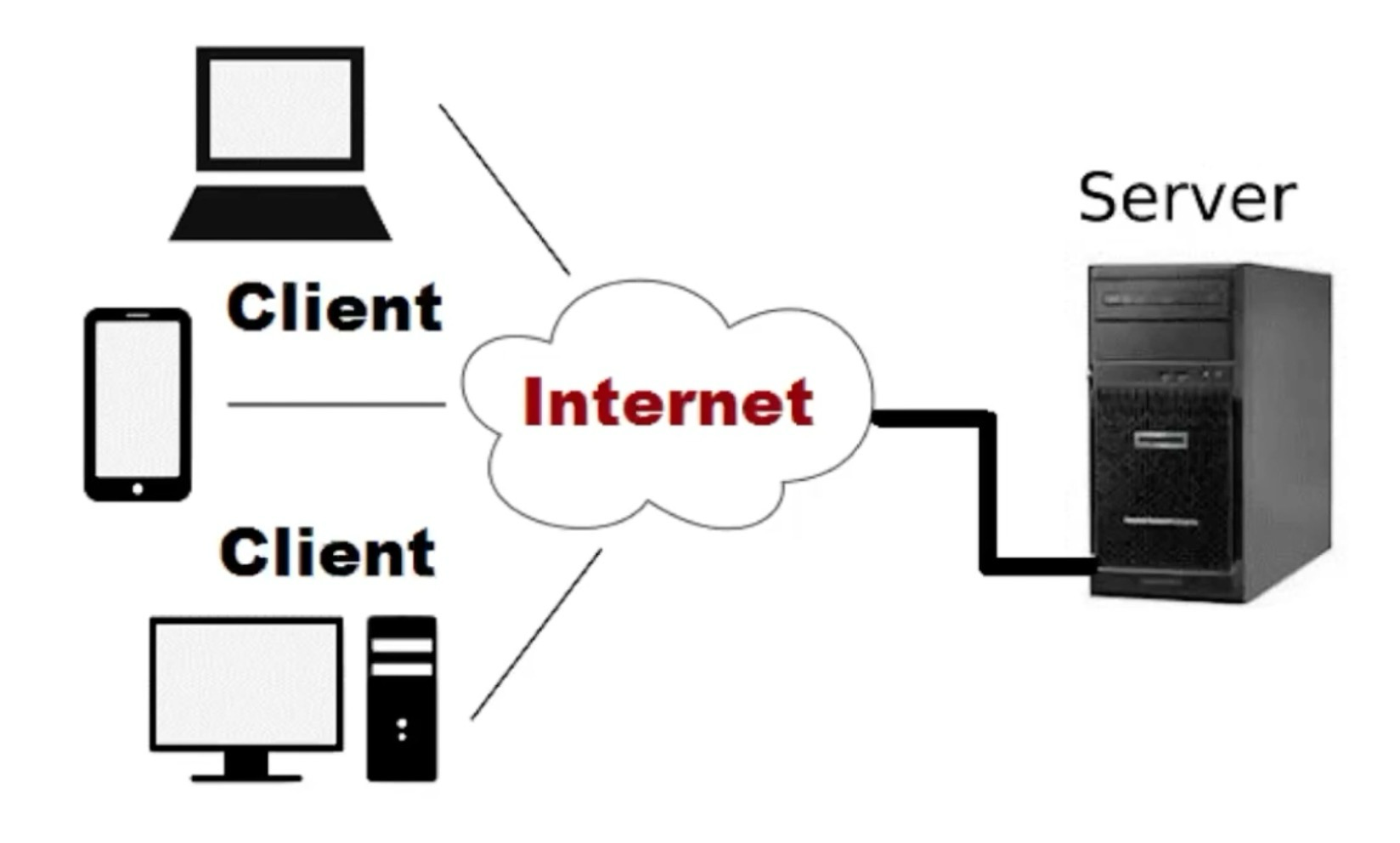
클라이언트는 서비스를 요청하는 주체 (어플리케이션, 브라우저, 앱 등이 해당됨)
서버는 네트워크를 통해 받은 요청을 처리하고 응답하는 모델
여러 클라이언트의 요청을 동시에 처리할 수 있다
작동 원리
- 클라이언트는 서버에 특정 자원이나 서비스에 대한 요청을 보내고, 서버는 요청을 처리한 뒤 필요한 데이터나 결과를 클라이언트에게 응답
- 프로토콜
- 클라이언트오 서버 간의 통신 규칙과 절차
- HTTP, SMTP, IMAP, FTP 등
클라이언트의 역할
- 서비스 요청
- 사용자 인터페이스 제공
- 입력 데이터 처리 : 사용자로부터 입력 받은 값을 처리 (유효성 검사) 단, 서버도 유효성 검사해야됨
- 왜 2번이나 유효성 검사를 하는가 .. -> 서버의 부하를 막기 위함 - 서버로부터 응답 수신 및 처리
서버의 역할
- 컨텐츠의 제공 : 요청에 따라 실시간으로 컨텐츠 생생하거나 미리 만들어둔 파일을 제공
- 데이터의 관리와 저장 : 서버에서 가장 중요한 기능
- 보안 : 네트워크 보안을 유지하고 데이터와 리소스를 관리함 (인증 및 암호화)
- 동시 요청 처리 : 여러 클라이언트로 부터 받은 요청을 효율적으로 처리해야함
- 확장성 및 안정성 제공 : 여러 트래픽으로 잘 관리해야함
장단점
장점 : 역할 분담 / 중앙 집중화 / 확장성 / 보안성 (중요한 데이터를 한곳에서 관리)
단점 : 단일 장애점 / 서버 부하 (동시에 과도하게 요청 보내게 되면..) / 관리 복잡성 (항상 유지보수가 필요함)
클라이언트-서버 모델은 웹서비스에서 가장 기본이 되는 모델이다.
프론트엔드
사용자와 직접 상호작용하는 인터페이스를 담당
웹 애플리케이션에 시각적인 부분을 담당
구성요소
HTML, CSS, JavaScript로 구성되어 있다.
HTML Semantic Elements
- 코드의 의미를 명확하게 해주는 HTML 요소
- 도입 이유
- 웹 접근성
- 검색 엔징 최적화(SEO)
- 유지 보수와 코드의 가독성 - 예시 :
header, footer, article, section, nav
CSS는 웹페이지의 레이아웃, 색상, 폰트, 간격 등을 정의한다.
웹 초기에는 CSS에 플렉서블이 없었고 테이블 태그를 사용해서 레이아웃을 구성할 수 밖에 없었으나
현대에는 다양하게 사용할 수 있다.
JavaScript
- 동적 컨텐츠 변경 : DOM을 조작하여 동적으로 조작할 수 있다.
- 사용자 이벤트 처리 : 사용자 행동을 감지하여 특정 이벤트를 처리
- 애니메이션 및 효과 : 풍부한 시각적 효과를 입힐 수 있다.
- 입력 데이터 검증 : 사용자가 폼에 입력한 데이터에 유효성을 검사할 수 있다.
- AJAX를 이용한 비동기 통신 : 페이지를 새로고침하지 않아도 서버와 데이터 통신을 할 수 있다.
프론트엔드 라이브러리
- jQuery : 한때는 웹개발에서 가장 인기있는 라이브러리 (돔 조작, 이벤트 처리, 애니메이션 기능 등)
그러나 React, Next 등이 있어서 현대에서 잘 사용되지 않음 , 그러나 문법은 쉽다고 한다. - Angular : 구글에서 개발한 TypeScript 기반과 컴포넌트 기반 프론트엔드 프레임워크
- React : facebook에서 만든 JavaScript UI 라이브러리, 컴포넌트 기반으로 재사용성이 가능한 UI 지원
버추얼 돔을 이용해서 성능이 높고, JSX를 사용해서 직관적으로 코드 작성 가능 - Vue.js : 직관적이고 유연한 반응현 UI 개발을 위한 컴포넌트 기반 프론트엔드 프레임워크
생태계가 작은편 - Bootstrap : 반응형 그리드 시스템과 재사용 가능한 컴포넌트를 제공하는 CSS프레임워크 (커스터마이징이 쉽지 않음, 디자인이 비슷함)
- Tailwind CSS : 유틸리티 중심의 CSS 프레임워크 (색상, 여백, 크기와 같은 디자인 요소들을 빠르게 스타일 지정할 수 있음)
반응형 프로그래밍 패러다임
데이터 스트림과 변경 사항 전파를 중심으로하는 선언적 프로그래밍 패러다임
즉, 명령형 프로그래밍 패러다임과 반대로 움직임
명령형 프로그래밍은 스위치가 전구의 상태를 변경할때 수동적으로 움직이지만
반응형 프로그래밍은 스위치를 감시하여 상태가 변경할때 자동적으로 변경됨
Angular, React, Vue의 경우 자동으로 변경되게 끔. 로직 수행됨
백엔드
백엔드는 웹 어플리케이션의 서버측을 담당, 데이터 처리 관리 , 로직 구현 등 핵심적인 요소를 담당
주요 역할
- 데이터의 처리 및 관리 : SQL, NoSQL등을 활용
- 비즈니스 로직 구현 : 요청에 따라 그에 맞는 비즈니스 로직 실행
- API 제공 : REST API, GraphQL 등을 사용
- 서버 관리 : 웹 어플리케이션을 호스팅하는 서버를 관리 (리소스 관리, 보안 등..)
- 보안 : 데이터 보호와 트랜잭션 관리를 위한 보안 조치를 해야함 (권한 부여, 인증, 암호화 등)
프로그래밍 언어 및 프레임워크
- Java Spring MVC : 대규모 프로젝트에 적합
- Python Django : 빠르게 확장 가능
- Node.js Express : 빠르게 구축
- Ruby on Rails : 빠르게 구축
- PHP Laravel
프로그래머스의 경우 루비온레일즈로 퓨마라는 웹 어플리케이션에서 실행함
Server Side Systems에서 Web server를 앞단에 두고 사용한다고 한다.
아파치, Nginx 같은 웹서버는 HTML,CSS,Js 같은 정적 파일을 처리하고
동적처리는 어플리케이션 서버에서 처리를 담당한다고 한다.
데이터베이스
웹 서비스는 사용자 요청에 따라 데이터를 저장, 검색하는 일을 함
데이터베이스는 그래서 매우 중요 !
관계형 데이터베이스와 비관계형 데이터베이스가 존재
- 관계형 데이터베이스 : 데이터를 테이블 형태로 저장하고 관리하는 시스템 데이터 (무결성을 위한 제약조건 설정 가능)
- Mysql, PostgreSQL, Oracle, MariaDB
- 비관계형 데이터베이스 : document, key-value, graph과 같은 다양한 데이터 저장 모델을 사용하는 시스템
- 용도 : 사용자 세션 관리, 실시간 분석 및 대용량 데이터 처리, CMS, 게임 애플리케이션
- MongoDB, Cassandra, Redis, DynamoDB (고정된 스키마가 없어 다양한 형식으로 저장가능, 분석도 쉬움)
- Redis는 매우 빠르게 조회 가능
웹 어플리케이션에서 데이터베이스를 고르는건 성능과 확장성에 영향을 끼친다.
캐싱
캐싱은 필수적이지 않지만 중요한 요소이다. (성능개선, 안전적으로 운영할 수 있게 함)
또한 검색 결과의 품질을 올려줄 수 있다.
자주 사용되는 데이터나 계산 결과를 미리 저장, 동일한 요청이 왔을 때 빠르게 응답 할 수 있도로 해줌
메모리 기반의 key-value 저장소: Redis, Memcached를 주로 사용한다.
하자만 경우에 따라 로컬파일에 캐시를 저장할 수 도 있다.
초기에는 캐쉬를 적용하면 복잡도가 올라가 적용하지 않지만
사용자가 증가하면 병목현상등이 발생하여 서버 증설하기 전에 캐싱을 사용하는 걸 고려함
캐싱 종류
- 객체 캐싱 : 데이터 베이스에서 조회한 데이터, 시간이 오래 걸리는 데이터를 캐싱함.
- 사용자 세션 : 로그인 세션 정보를 캐싱 (모든 사용자 정보 {자주 변경되지 않음}를 캐싱하여 사용)
- 뉴스 기사 : 제목,내용,발행일 등 캐싱 (왜냐? 자주 변경되지 않기 때문에)
- 장바구니 : 보통 장바구니 링크가 쇼핑사이트에 있기때문에 DB보다 캐싱해서 읽으면 빠르게 가져옴 - 페이지 캐싱 : 페이지의 일부를 캐싱
- 뉴스 메인 페이지
- 게시글 페이지 : 블로그와 같은 서비스에서 인기 있는 게시글은 본문, 제목을 캐싱하여 빠르게 반환해 줄 수 있음 - 브라우저 캐싱 : 클라이언트에서 HTTp 응답을 캐싱하는 것이라고 한다. 이후 요청할때 헤더에 담아 요청한다.
만약 헤더에 있는 캐싱 값이 변경되면 200, 변경되지 않았다면 304로 그래서 304일 경우 캐싱된 데이터로 랜더링하게 된다.
장단점
장점 : 응답 시간 단축, 서버 부하 감소, 네트워크 부하 감소
단점 : 만료된 데이터 (stale date) , 복잡성 증가
캐시 무효화 전략
- 명시적 무효화
- 데이터베이스 등의 원본 데이터가 변경되었을 때 캐시된 데이터를 업데이트하거나 제거- 로직 수정으로 복잡성이 증가하지만, 원본과 캐시 데이터가 일치하기에 보증이 됨
- 만료된 시간(TTL)기반 무효화
- 캐시된 객체에 TTL을 설정, 일정 시간이 지나면 해당 객체를 무효화 - 버전 기반 무효화
- 캐시 데이터에 버전 번호를 할당하여 무효화를 관리
로깅
서버 내에서 일어나는 일을 파악하기 위해서는
서버의 상태를 외부에 기록해야한다. (이러한게 로깅 이라고 함)
목적
- 시스템이나 애플리케이션에서 발생하는 이벤트를 저장하고 관리하는 것
- 목적 :
- 디버깅, 요청과 관련된 정보, 상태코드, 응답시간, 세션 정보 등이 포함
- 성능 모니터링, 데이터 베이스 쿼리, 쿼리 실행 시간을 남겨 모니터링을 할 수 있다.
각 요청의 시간, 랜더링 시간 등 성능에 대해서 모니터링 가능
- 보안, 비정상적인 활동, 공격을 감시 할 수 있다. (SQL 인잭션 또한 포함)
- 감사(Audit) 접근 권한등을 기록하여 감사에 대비
고려 사항
- 로그 레벨 : DEBUG, INFO, WARN, ERROR, FATAL
- DEBUG : 개발자가 진단, 변수 조건문에 실행 결과를 확인 - 로그 포맷 : 로그의 형식은 짧고 명확하고 가독성이 높게 !
- 로그 로테이션 : 로그 파일이 커지지 않게 관리, 디스크 풀 에러를 방지해야함 (오래된 로그는 삭제하거 백업)
- 로그 보안 : 로그를 남길 때, 패스워드와 같은 민감한 정보를 마스킹하거나 제외해야함
- 로그 관리 도구
- ELK 스택 (ElasticSearch, Logstash, Kibana)
- CloudWatch Logs
에러 로깅
에러가 발생한 위치나 상세 내용, 요청과 관련된 정보, 사용자 정보 등을 따로 저장하고 모니터링
- sentry, rollbar, Raygun 등
Job server
사용자 요청에 직접적인 영향이 없는 작업을 Job server에서 비동기적으로 실행된다.
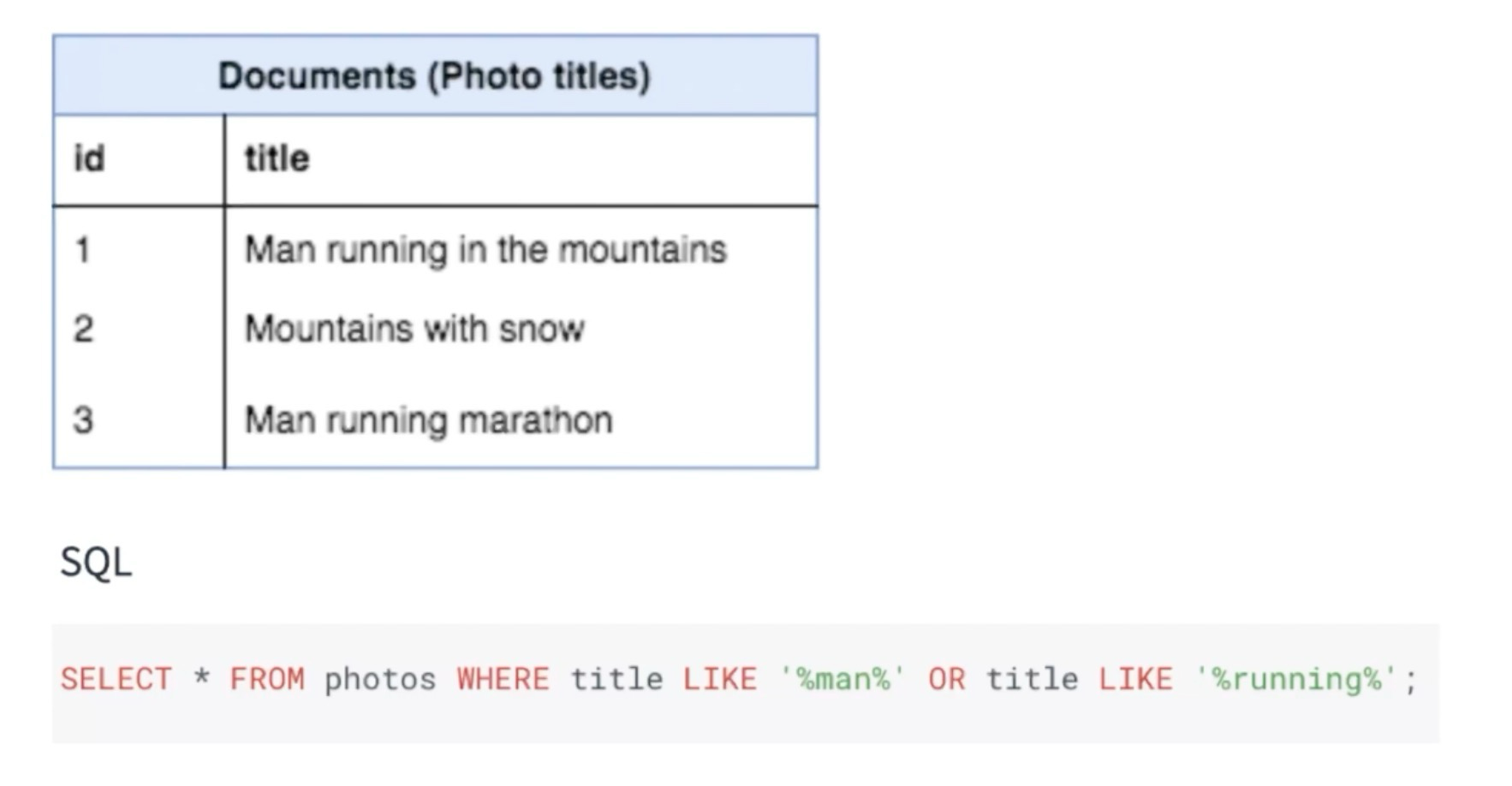
동작
- Job 생성
- Job Que에 작업 추가
- Job Server에서 작업 가져오기
- Worker에서 작업 처리
- 작업 완료 및 결과 처리
- 작업 실패 처리
작업 종류
- 이메일 발송 : 가입인사 이메일, 대량의 이메일 등을 발송할때 비동기적으로 처리하면 좋음
- 데이터 처리 및 분석 작업 : 대용량 데이터 처리, 복잡한 분석 등 오래 걸리는 작업 (사용자 추천, 로그 분석)
- 파일 변환 : 사용자가 업로드한 파일을 다른 포맷 , 썸네일 등의 작업은 서버에 부하를 줄 수 있기에 잡서버로 이동
- 외부 API 호출 : 오래 걸리는 호출, 실패할 경우 재호출해 줄 수 있으므로 (결제 , 소셜 데이터를 가져올때)
- 주기적인 작업 :
cron을 사용해서 통계 보고서를 생성하거나 데이터를 백업 받는 등 할 수 있음
장점
- 응답 속도 향상 : 오래 걸리는 작업을 분리하기에 빠른 응답 속도로 처리 가능
- 확장성 : 웹서버랑 분리되었기에 여러 워커노드로 분리해서 병렬처리 가능 (?) '이해는 안감...'
- 작업 실패 처리 및 재시도 : 자동으로 재실행되는 기능을 대부분 제공하기에 개발자가 크게 실경 쓸 필요 없음
- 대표적인 잡서버 : Sidekiq, Resque, Celery, Bull
전문 검색 서비스 (Full-Text Search Service)
원리 : 사용자가 입력한 텍스트로 검색을 하면 가장 관련성이 높은 결과를 보여주는 서비스
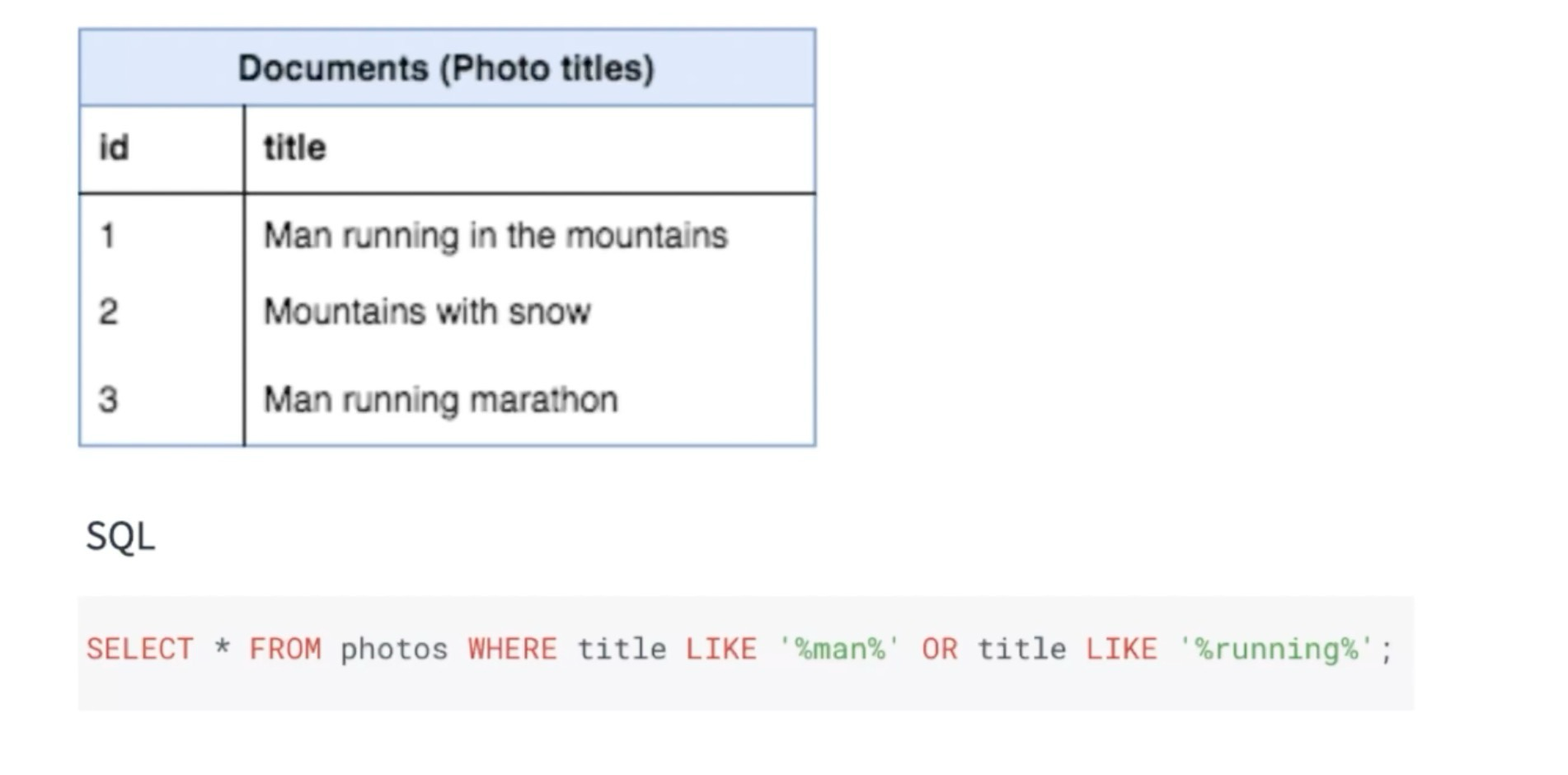
데이터베이스의 와일드 카드 기능을 이용한 LIKE 검색을 할 수 있지만
Index를 사용하지 못해서 검색 결과가 많아지면 처리 해야할 량이 많아짐
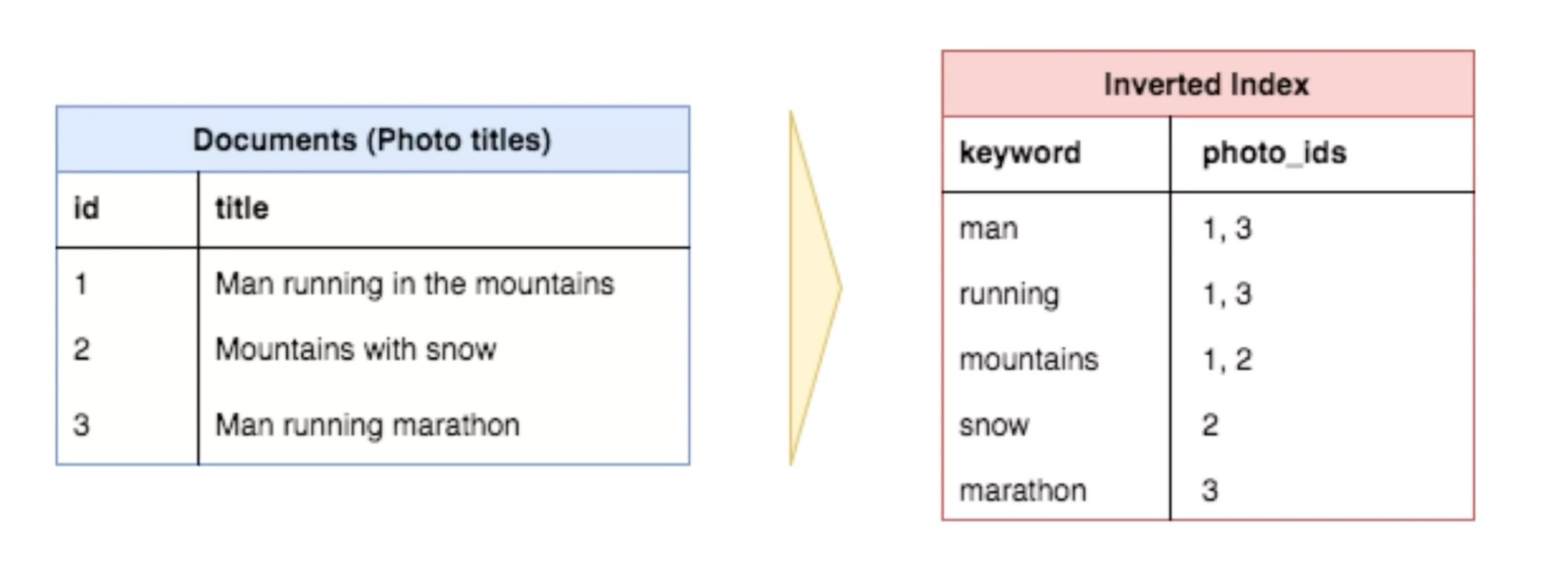
위 처럼 Full-Text Search Service를 사용하면
역으로 인덱스를 생성해서 빠르게 조회를 할 수 있게 해줌 (제목에 있는 단어를 분석해서 저장)
위와 같은 구조를 사용하면 검색어에 해당되는 결과를 쉽게 가져올 수 잇음
동작 방식 - 인덱스 생성 단계
- 텍스트 데이터 수집
- 문서의 텍스트를 추출하고 정규화 (소문자 변환 및 특수문자 제거 등) - 토큰화
- 텍스트를 토큰으로 분리
- ex) 아버지가 방에 들어가신다 -> 아버지, 가, 방, 에, 들어가, 신다
- ex) man running in the moutains -> man, running, in, the moutains - 불용어 제거 및 어근 추출
- 검색에 불필요한 단어를 제거, 단어를 기본형이나 어근으로 변환 - 인덱스 구축
- 각 토큰이 나타나는 모든 문서의 목록 작성
동작 방식 - 검새 쿼리 처리 단계
- 쿼리 분석
- 사용자가 입력한 검색 쿼리의 토큰화, 불용어 제거, 어근 추출 - 인덱스 검색
- 각 토큰에 대해 인덱스를 조회하여 토큰이 포함된 문서 검색 - 순위 매기기
- 검색 쿼리와 일치하는 문서들을 찾아서 관련성 점수 계산 - 결과 반환
- 순위가 매겨진 문서 목록을 반환
주요 검색 엔진
- ElasticSearch (가장 많이 사용됨, 오픈소스 분산형 검색 엔진)
- Apache Solr
- MySql과 PostgreSQL Full Text Search
데이터베이스에서도 기능을 제공하기는 함
단, RDS같은 클라우드 서비스를 사용시 한글 검색 지원이 불가능하다.
클라우드 기반 인프라
인프라 구성 요소
- 서버 하드웨어
- 네트워크 장비 : 라우터, 스위치, 로드밸런서 등
- 저장 장치 : 서버나 데이터베이스에 데이터를 저장하기 위한 스토리지
- 운영 체제 및 서버 소프트웨어 : 리눅스가 가장 많이 사용
- 데이터베이스 시스템
- 모니터링 시스템 : 서버를 운영하려면 시스템의 상태를 중앙에서 모니터링 해야 됨
- 보안 시스템 : 방화벽이 필요하는 경우도 있다. 특정 아이피에서 공격이 들어오는 경우도 있음
- 백업 및 재해 복구 시스템 : 데이터가 2중화, 3중화되어 있어야하고 데이터가 유실되지 않도록 시스템을 구축해야함
대기업이 아니면 대부분 클라우드 기반 인프라를 사용함 (비용이 많이 들지만 직접 고용하고 설치한다면 오히려 ㄱㅊ)
또한 클라우드 서비스를 사용하면 다양한 서비스를 유동적으로 늘리거나 줄일 수 있다.
인프라 서비스 모델
- Iaas
- 서버, 스토리지, 네트워킹과 같은 기본 컴퓨팅 인프라를 제공 (관리에 대한 지식이 필요함)
- AWS, AZURE, Goolge Cloud - Paas
- 애플리케이션을 개발하고 배포하기 위한 플랫폼
- Heroku, Google App Engine, Vercel, Netlify - Saas
- Slack, Google Workspace, Microsoft 365
보안
웹 서비스에 있어서 보안은 매우 중요, 데이터 유출 발생시 법적 책임을 질수도 있다.
네트워크 보안
- 네트워크 상에서의 침입이나 공격을 방어하는 것
- 방어 방법 :
- 방화벽 : Security Group, WAF (CloudFront, ALB)
- 침입 탐지 시스템
- SSL 프로토콜 사용 (https 사용 = SSL 프로토콜 사용), 정보를 가로채더라도 암호화된 데이터임
데이터 보안
- 데이터베이스에 저장된 데이터에 대한 보안
- 방어 방법 :
- 데이터 암호화 : 민감한 정보를 암호화하여 저장 ! (복호화 불가능하도록)
- 데이터베이스 접근 권한 권리 : 서비스용 데이터베이스는 최소한의 인원만 접근할 수 있도록 , VPN을 사용
- SQL 인잭션 방어 : 외부에서 공격하는 방법. 악의적인 SQL쿼리를 URL파라미터로 공격함
어플리케이션 보안
- 인증이나 권한 관리 시스템을 구현해서 사용자 데이터를 보호하고 무단 접근으로부터 시스템을 보호
- 방어 방법 :
- 인증 (Authentication) : 입력된 아이디와 비밀번호를 받아서 확인
최근에는 다중 인증 로그인 사용을 많이 함 (이메일, 생체인식, 전화, 문자 등)
쿠키 생성 및 응답 (세션 아이디 생성 후 쿠키에 저장해서 보냄)
- 권한 관리 (Authorization) : 인증된 사용자가 시스템내에서 수행할 수 있는 권한을 부여.
(관리자와 일반 사용자, 동일한 페이지를 다르게 랜더링 : 라이브러리, 프레임워크가 있다고함)
- CORS (Cross-Origin Resource Sharing) : 웹 페이지가 다른 도메인의 리소스에 접근할때 발생하는 보안을 제안을 해결하기 위한 메커니즘.
기본적으로 브라우저는 같은 출처 정책을 따른다.이 정책은 보안상에 이유로 웹페이지에서 다른 도메인의 리소스 접근을 차단함. 서버에선 CORS 설정 후 다른 도메인의 API를 안전하게 접근하도록 해야함.
- XSS (Cross-Site Scripting) 방어
운영 보안
- 서비스를 운영하면서 발생할 수 있는 위협에 대한 감시
- 방어 방법 :
- 로깅
- 개인 정보 조회 이력
- 보안 패치
물리적 보안
- 서버와 하드웨어가 위치한 물리적 공간으 ㅣ보안
- 방어 방법 :
- IDC 접근 통제 , 감시 시스템 , 화재나 재난 방지 시스템
웹 서비스를 개발할때 보안은 매우 중요 ! 데이터 암호화 , SSL , XSS, 인잭션 방어, CORS는 필수적으로 설정해야됨
성능 및 확장성
성능과 확장은 매우 중요한 요소
측정할 수 없는 것은 관리할 수 없다.
웹 페이지의 로딩 속도가 느려진다면 CPU, 메모리 사용량, 쿼리 등을 알아볼 수 있을 것이며
여러 방면에서 파일의 크기가 큰지.. 많은지.. 등을 고려해 봐야 한다.
성능 문제와 해결 방법
- 웹 서버의 과부하 : 사용자와 트래픽이 증가하면 웹페이지 응답 속도가 느려진다. (클라우드에서는 오토스케일링 가능)
- 병목 지점 파악, 서버 증설 - 데이터베이스 응답 지연 : 트래픽 증가에 따라 데이터베이스 요청이 많아서 응답 속도가 느려질 것이다.
- 데이터베이스 튜닝, 캐싱, 하드웨어 업그레이드 (비용이 많이 증가) 그래서 다른 방법 먼저 시도해볼 것- Shading으로 데이터베이스 테이블을 분리하기도 한다.
- 캐싱을 통해서 데이터베이스 부하도 줄이고 응답속도를 높힐 수 있다.
- 웹 브라우저의 로딩 지연 : 웹 브라우저 자체가 느려져서 로딩이 지연될 수 있다.
- 이미지 압축, 비동기 로딩, 무한 루프 - 해외 접속 지연 :
- CDN 도입
확장성
- 사용자 수의 증가나 데이터 양의 증가에 맞춰 적절히 대응할 수 있는 능력
- 확장 방법
- 수직적 확장 (Scale Up) : 하드웨어 성능을 올려 버림 (물리적 한계가 있음)
- 수평적 확장 (Scale Out) : 서버를 추가해서 처리할 서버를 늘림 (많이 복잡해 질 수 있음)
로드 밸런서를 사용해서 확장하기 용이
데이터베이스 확장
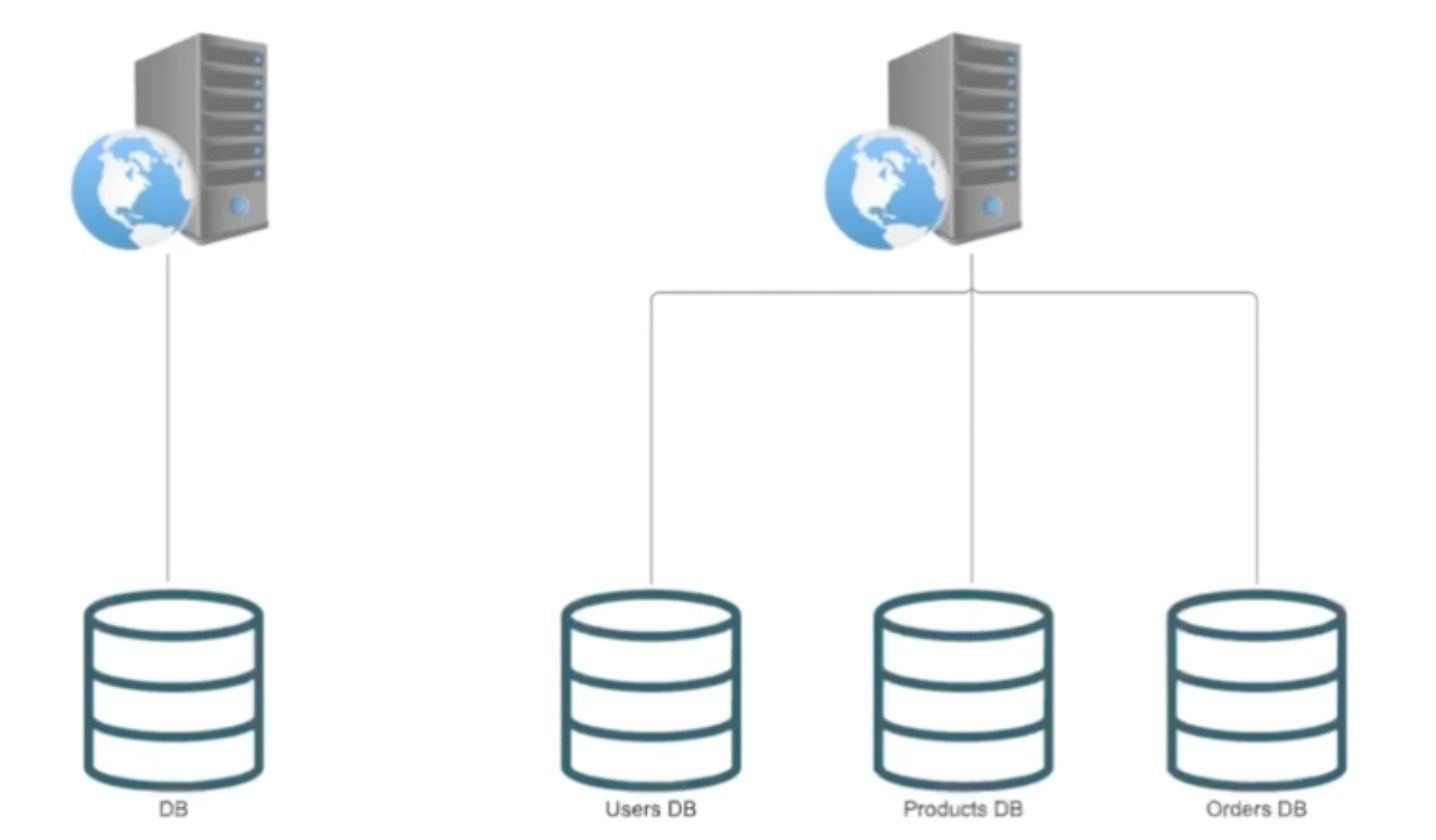
-
테이블 분산 : DB -> UsersDB, ProductsDB, OrdersDB 등으로 나눠버림
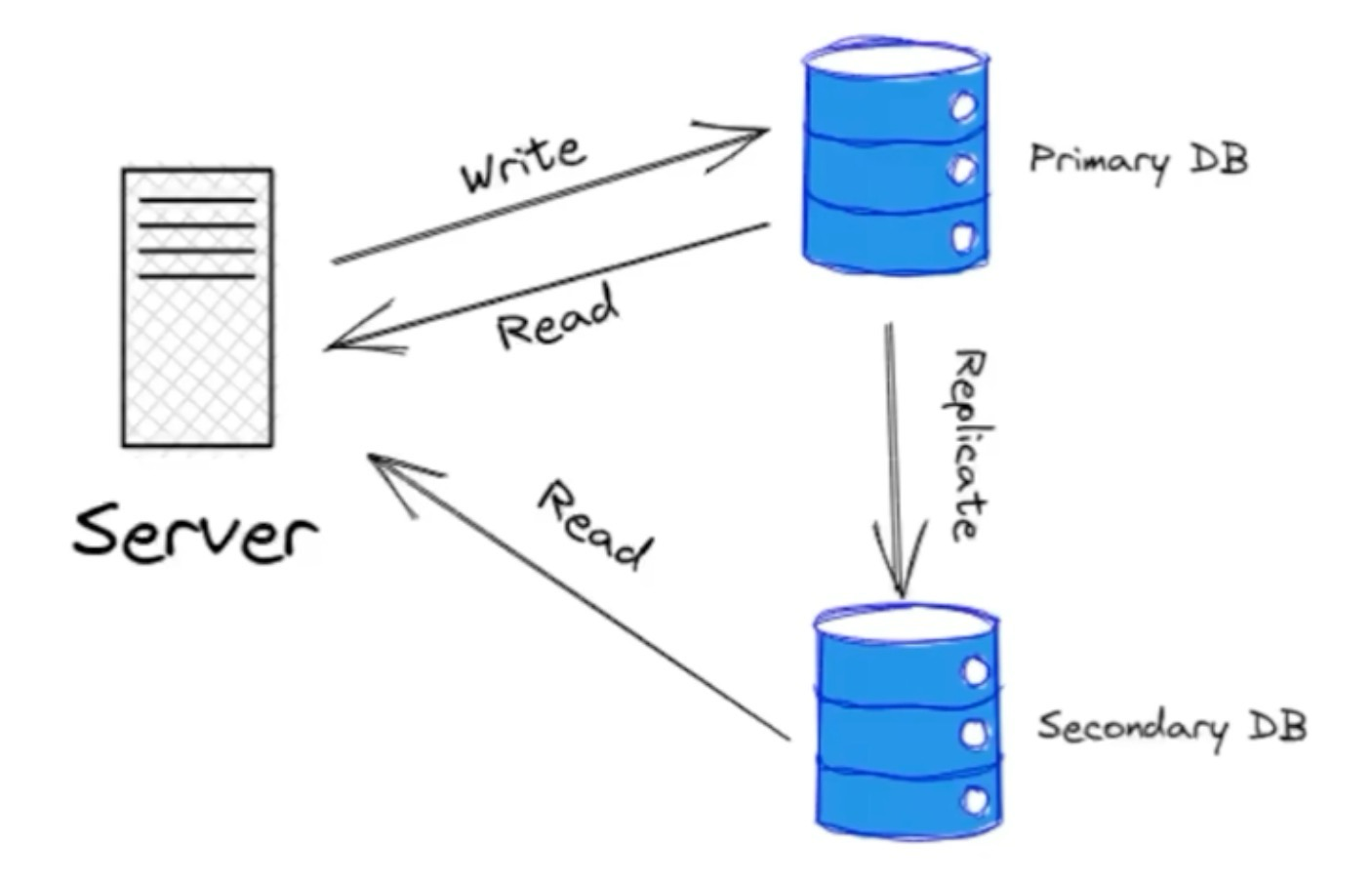
-
복제 : DB를 나눠서 쓰기와 읽기가 가능한 DB, 읽기만 가능한 DB 등으로 나눠 버림
-
샤딩 (Sharding) : 수천만, 수억건의 데이터가 있다면 Index가 있어도 처리량이 많아짐 (물론 단점도 존재)
- Key-based Sharding : 특정 컬럼값에 해시를 적용하여 shard 적용, 특정 범위 조회시 모든 Shard를 조회하게 됨
- Range-based Sharding : 특정 범위에 따라서 분할하여 저장 (가격, 지역 등 특정 기준으로 분리, 균등하게 Shard되지 않는 경우도 있음)
- Directory-based Sharding : 유연성이 높은 방식 , 단 디렉토리 자체가 병목이 될 수 있음
성능 최적화는 사용자 경험에 직접적으로 개선, 확장성은 서비스 성장과 변화에 유연하게 대응할 수 있음
