
📜문제 설명
일차원 좌표상의 점 N개와 선분 M개가 주어진다. 이때, 각각의 선분 위에 입력으로 주어진 점이 몇 개 있는지 구하는 프로그램을 작성하시오.
📍입력
첫째 줄에 점의 개수 N과 선분의 개수 M이 주어진다. (1 ≤ N, M ≤ 100,000) 둘째 줄에는 점의 좌표가 주어진다. 두 점이 같은 좌표를 가지는 경우는 없다. 셋째 줄부터 M개의 줄에는 선분의 시작점과 끝점이 주어진다. 입력으로 주어지는 모든 좌표는 1,000,000,000보다 작거나 같은 자연수이다.
5 5
1 3 10 20 30
1 10
20 60
3 30
2 15
4 8📍출력
입력으로 주어진 각각의 선분 마다, 선분 위에 입력으로 주어진 점이 몇 개 있는지 출력한다.
3
2
4
2
0📄문제 해결
📝내가 푼 코드
❎ 1차 시도
# 입력 데이터 저장
n, m = map(int, input().split(' '))
dots = list(map(int, input().split(' ')))
lines = [list(map(int, input().split(' '))) for _ in range(m)]
for line in lines:
a, b = line
# a가 dot[-1] 보다 큰 경우
# b가 dot[0] 보다 작은 경우
if a > dots[-1] or b < dots[0]:
print(0)
continue
for i in range(n):
if a <= dots[i]:
break
for j in range(n-1, -1, -1):
if b >= dots[j]:
break
print(j-i+1)문제를 보았을 때, 주어진 점의 좌표 리스트에 대해서 선분의 시작점보다 크거나 같은 좌표와 끝점보다 작거나 같은 좌표를 찾아야 한다는 생각이 들었다.
문제를 보고 어렴풋이 탐색하는 문제라는 생각은 들었으나, 머릿 속에서 연관되어 로직이 떠오르지 않아 결국 대강 생각나는 대로 조건에 맞춰서 선형탐색하듯 코드를 작성하였다. 선분이 좌표 범위에 아예 벗어나는 경우도 대비하는 것도 추가하였으나, 결국 더이상 반례를 찾지 못해 틀린 결과를 낳게 되었다.
✅ 2차 시도 -> 성공
도무지 반례를 찾을 수 없었던 나는 문제와 나의 코드를 chatGPT에 입력했다. 그랬더니 이진탐색으로 찾을 수 있다는 답변을 받았는데, 도무지 해결 방법이 떠오르지 않아 제시받은 코드를 탐색하고 그 원리를 공부해 내 것으로 만들기로 했다.
def find_left(target, arr):
lower, upper = 0, len(arr)
while lower < upper:
middle = (lower + upper) // 2
if arr[middle] < target:
lower = middle + 1
else:
upper = middle
return lower
def find_right(target, arr):
lower, upper = 0, len(arr)
while lower < upper:
middle = (lower + upper) // 2
if arr[middle] <= target :
lower = middle + 1
else:
upper = middle
return lower - 1
# 입력 데이터 저장
n, m = map(int, input().split(' '))
dots = sorted(map(int, input().split(' ')))
lines = [list(map(int, input().split(' '))) for _ in range(m)]
for a, b in lines:
left = find_left(a, dots)
right = find_right(b, dots)
if left <= right:
print(right - left + 1)
else:
print(0)나는 이진탐색을 사용한다면 탐색하는 반복문을 탈출하는 조건을 꼭 설정해야 한다고 생각했다. 1부터 100까지의 숫자 중에서 타겟이 되는 숫자가 중앙값과 매칭되면 break 문으로 탈출하는 것처럼 말이다. 하지만, 우리에게 필요한 것은 시작점보다 크거나 같은 좌표, 그리고 끝점보다 작거나 같은 좌표라는 점이 가장 중요한 키 포인트였다!
이진탐색으로 시작점, 즉 주어진 배열에서 타겟을 찾기 위한 이진탐색을 진행하면 최종적으로 설정되는 lower가 타겟보다 크거나 같은 값이 된다. 그 값을 찾기 위한 함수가 바로 find_left()이다.
이때 중요한 부분은 lower와 upper의 값 중 무엇을 움직일지 결정하는 조건문, if arr[middle] < target이다. 이때 비교연산자를 <을 사용하느냐, 혹은 <=을 사용하느냐에 따라서 결과는 타겟에 대해 크거나 같은 값 중 최솟값(시작점)을 구하거나, 작거나 같은 값 중 최댓값(끝점)을 구하게 된다. 그 차이에 따른 실제 동작 과정은 아래 그림에서 확인할 수 있다.
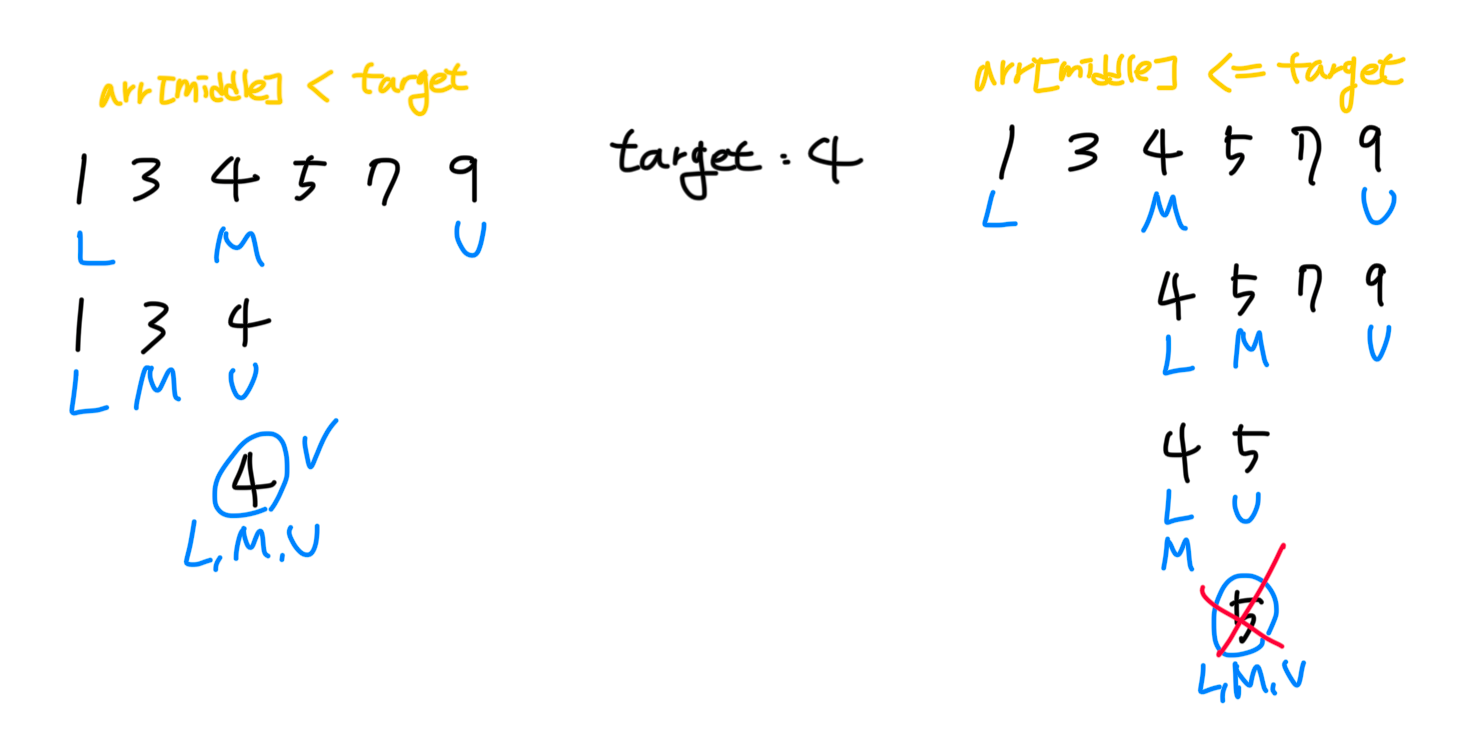
위 그림은 배열 [1, 3, 4, 5, 6, 7] 에 대해서 타겟을 4로 잡고 있다.
4가 시작점이라고 할 때, 비교 연산자를 < 로 사용한다면 우리가 원하는 시작점 4 이상인 값 중 최솟값인 4가 올바르게 도출된다. 반면, 비교 연산자 <= 를 사용해 middle의 값과 타겟 값이 같은 경우에도 lower를 움직이도록 한다면 4가 아니라 4보다 큰 값이 도출되게 되면서 4가 시작점인 경우 올바르지 않은 결과가 도출된다.
하지만 4가 끝점이라면 항상 타겟 값보다 큰 결과가 도출되므로, 도출된 값에서 1을 빼주면 우리가 원하는 값을 얻을 수 있게 된다.
따라서, find_left() 함수에서는 비교 연산자를 <로, find_right() 함수에서는 비교 연산자를 <=로 사용하였기에 탐색이 끝난 후의 lower가 우리가 찾던 바로 그 값이 도출되도록 할 수 있는 것이다!
이 과정을 통해 필요한 시작점과 끝점에 관한 값 left, right를 구하고 조건에 따라 정답을 도출하였다. left가 right보다 작거나 정상적인 경우를 제외하고는 모두 0으로 도출하는 것도 중요한 점 중 하나였다.
또한, 입력 받은 좌표 목록은 정렬되어 제공되기 않기에, 오름차순으로 정렬하는 과정이 필수적이었다.
🤔느낀점
아직 문제를 보고 어떤 알고리즘을 적용해야 하는지 생각하는 능력이 부족함을 느낄 수 있었다. 또한, 이진 탐색이라는 개념을 알고 있었음에도 불구하고 gpt의 코드를 보고도 바로 이해하지 못했던 것으로 보아, 알고리즘의 원리를 이해하는 것만으로는 부족하고 필요한 방식으로 그 원리를 적용해야 하는 능력을 길러야겠다는 생각을 했다.
