
Kafka란?
카프카는 Pub-Sub 모델의 메시지 큐 형태로 동작한다.
메시지/이벤트 브로커와 메시지 큐
메시지 큐(MQ)란?
메시지 지향 미들웨어(MOM)를 구현한 시스템으로 프로그램(프로세스)간의 데이터를 교환할 때 사용되는 기술이다.
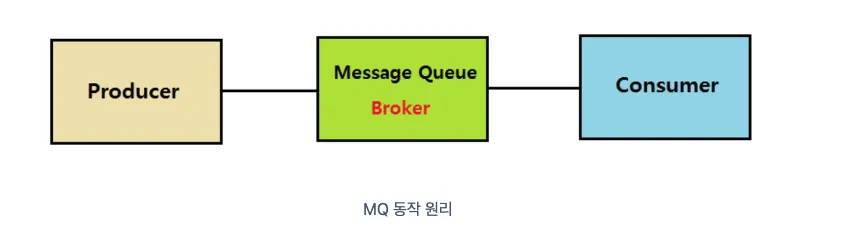
Producer: 정보를 제공하는 주체
Consumer: 정보를 제공 받아서 사용하려는 주체
Queue: Producer의 데이터를 임시 저장 및 Consumer에 제공하는 곳
MQ에서 메시지는 end point 간에 직접적으로 통신하지 않고 중간의 Queue를 통해 중개된다.
MQ의 장점
- 비동기: Queue라는 임시 저장소가 있기 때문에 나중에 처리 가능
- 낮은 결합도: 애플리케이션과 분리
- 확장성: Producer or Consumer 서비스를 원하는대로 확장할 수 있음
- 탄력성: Consumer 서비스가 다운되더라도 애플리케이션이 중단 되는 것은 아니며 메시지는 지속하여 MQ에 남아있다.
- 보장성: MQ에 들어간다면 결국 모든 메시지가 Consumer 서비스에 전달된다는 보장 제공
메시지 브로커
Publisher가 생산한 메시지를 메시지 큐에 저장하고 저장된 데이터를 Consumer가 가져갈 수 있도록 중간 다리 역할을 해준다.
서로 다른 시스템 사이에서 데이터를 비동기 형태로 처리하기 위해 사용한다. (미들웨어로서의 기능)
이러한 구조를 Pub/Sub라고 하며 대표적으로 Redis, RabbitMQ 소프트웨어가 있고, GCP의 pubsub, AWS의 SQS 같은 서비스가 있다.
메시지 브로커들은 consumer가 큐에서 데이터를 가져가게 되면 즉시 혹은 짧은 시간 내에 큐에서 데이터가 삭제되는 특징들이 있다.
이벤트 브로커
메시지 브로커의 큐 기능을 가지고 있어 메시지 브로커의 역할도 할 수 있다.
그렇다면 메시지 브로커와 이벤트 브로커의 차이점은?
이벤트 브로커는 Publisher가 생산한 이벤트를 이벤트 처리 후에 바로 삭제하지 않고 저장하여, 이벤트 시점이 저장되어 있어서 Consumer가 특정 시점부터 이벤트를 다시 consume 할 수 있는 장점이 있다. (예를 들어 장애가 일어난 시점부터 그 이후의 이벤트 다시 처리)
또한 대용량 처리에 있어 메시지 브로커보다 더 많은 양의 데이터를 처리 할 수 있다.
이벤트 브로커에는 Kafka, AWS의 kinesis 등의 서비스가 있다.
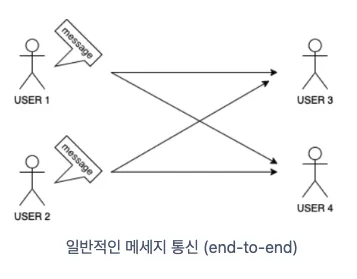
Kafka를 사용하지 않는 일반적인 네트워크 통신
각 개체가 직접 연결하며 통신하게 된다. 전송 속도가 빠르고 전송 결과를 신속하게 알 수 있다는 장점이 있다. 하지만 특정 개체에 장애가 발생한 경우 메시지를 보내는 쪽에서 대기 처리 등을 개별적으로 해주지 않으면 장애가 발생할 수 있고, 참여하는 개체가 많아질 수록 각 개체를 연결해줘야한다. (의존성이 높아져 확장성 측면에서 좋지 않다)
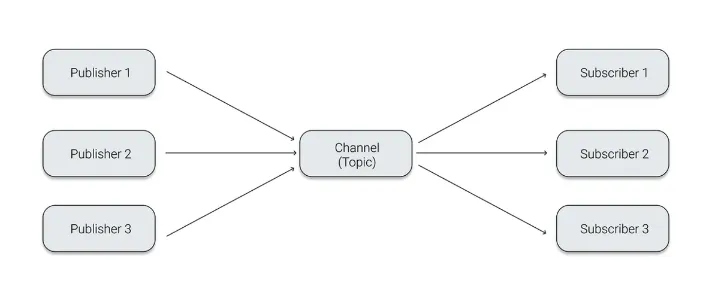
Pub/Sub 모델은 비동기 메시지 전송 방식으로, 발신자의 메시지에는 수신자가 정해져 있지 않은 상태로 Publish 한다. 그리고 이를 Subscribe 한 수신자가 정해진 메시지를 받을 수 있다. 발신자 정보가 없어도 원하는 메시지만 수신할 수 있으며, 따라서 높은 확장성을 확보할 수 있다.
ELK
ELK 스택은 Elasticsearch, Logstash, Kibana 세 가지 프로젝트로 구성된 스택이다. ELK는 사용자에게 모든 시스템과 애플리케이션에서 로그를 집계하고 이를 분석하여 애플리케이션과 인프라 모니터링 시각화를 생성한다.
Elasticsearch
Apache Lucene에 구축되어 배포된 검색 및 분석 엔진이다. 다양한 언어를 지원하고 고성능에 스키마가 없는 JSON 문서로 Elasticsearch는 다양한 로그 분석과 검색 사용 사례에 사용할 수 있다.
Logstash
다양한 소스로부터 데이터를 수집하고 전환하여 원하는 대상에 전송할 수 있도록 하는 오픈 소스 데이터 수집 도구이다. 데이터 소스나 유형에 관계없이 데이터를 쉽게 수집할 수 있도록 도와준다.
다양ㅇ한 소스로부터 데이터를 수집하고 곧바로 전환하여 원하는 대상에 전송할 수 있도록 하는 경랑의 오픈 소스 서버측 데이터 처리 파이프라인이다. 오픈소스 분석 및 검색 엔진인 Elasticsearch의 데이터 파이프라인으로 자주 사용된다. Elasticsearch와 긴밀한 통합, 강력한 로그 처리 능력, 사전 구축된 200개 이상의 오픈 소스 플러그인을 통해 데이터 인덱싱을 돕는 Elasticsearch에 데이터를 로드할 때 많이 사용된다.
- 비정형 데이터를 쉽게 로드
Logstash를 사용하면 시스템 로그, 웹 사이트 로그, 애플리케이션 서버 로그 등 다양한 데이터 소스에서 비정형 데이터를 쉽게 수집할 수 있다.
- 사전 구축된 필터
Logstash가 제공하는 사전 구축 필터로, 사용자는 일반 데이터 유형을 쉽게 전환하고 이를 Elasticsearch에 인덱싱하며, 사용자 지정 데이터 전환 파이프라인을 구축하지 않고도 쿼리를 시작할 수 있다.
- 유연한 플러그인 아키텍처
GitHub에 이미 사용할 수 있는 200개 이상의 플러그인이 있어, 데이터 파이프라인을 사용자 지정하는 데 필요한 플러그인이 이미 구축되어 있을 수 있습니다. 하지만 자신의 요구 사항에 맞는 것이 없는 경우 직접 쉽게 만들 수 있다.
Kibana
로그와 시계열 분석, 애플리케이션 모니터링, 운영 인텔리전스 사용 사례에 사용되는 데이터 시각화 및 탐색 도구이다. 히스토그램, 선형 그래프, 원형 차트, 열 지도, 내장 지리 공간적 지원과 같은 강력하고 사용하기 쉬운 기능을 제공한다. 또한 Elasticsearch와 긴밀하게 통합되어 Kibana는 Elasticsearch에 저장된 데이터를 시각화할 때 기본 선택 사항이 된다.
- 대화형 차트
Kibana는 사용자가 대량의 로그 데이터를 대화형으로 탐색하는 데에 사용할 수 있는 이니셔티브 차트와 보고서를 제공한다. 시간 창을 동적으로 드래그하고 특정 데이터 하위 집합을 확대하거나 축소하며 데이터에서 실천 가능한 인사이트를 추출하기 위해 보고서를 드릴다운할 수 있다.
- 매핑 지원
Kibana는 강력한 지리 공간적 기능이 포함되어 있어 사용자는 데이터의 지리적 정보를 제일 위에 두고 결과를 지도에 시각화하는 계층화 작업을 원활하게 수행할 수 있다.
- 사전 구축된 집계 및 필터
Kibana의 사전 구축된 집계 및 필터를 사용하면 몇 단계만으로 히스토그램, 상위 N개 쿼리, 추세와 같은 다양한 분석을 실행할 수 있다.
- 쉽게 액세스 가능한 대시보드
대시보드와 보고서를 쉽게 설정하고 다른 사람에게 공유할 수 있다. 확인하고 데이터를 탐색할 브라우저만 있으면 된다.
정리
Logstash → 데이터 수집 및 변환, 올바른 대상으로 전송
Elasticsearch → 수집된 데이터 인덱싱, 분석, 검색
Kibana → 분석 결과 시각화
참고: [Apache Kafka] 카프카란 무엇인가?, ELK 스택이란 무엇인가요? - Elasticsearch, Logstash, Kibana 스택 설명 - AWS
