이 글은 건국대학교 2024년 1학기 운영체제 수업과 『Operating Systems: Three Easy Pieces』 를 참고하여 작성되었습니다.
『Operating Systems: Three Easy Pieces』
10장. Multiprocessor Scheduling
지금까지는 1개의 CPU와 1개의 core만 있다는 가정 하에 작동 방식을 살펴봤다면, 이제부턴 multi core CPU에서의 스케줄링에 대해서 살펴보겠습니다.
Multiprocessor Scheduling
멀티코어 CPU에서는 각 코어마다 갖고 있는 level 1 캐시와 CPU 내의 모든 코어들이 공유하는 level 2 / level 3 캐시가 있습니다.
multiprocessor architecture
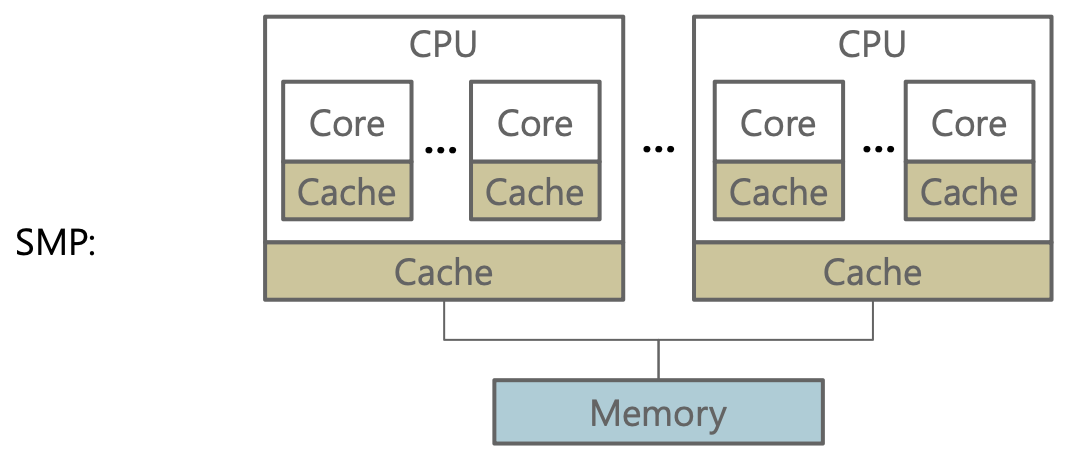
- SMP 구조
여러 프로세서와 하나의 공유 메인 메모리가 존재합니다. 모든 CPU와 메모리 간의 거리는 동일합니다. CPU는 메모리 버스를 통해 메모리에 접근합니다. 이 때, 여러 CPU가 하나의 메모리에 접근하기 때문에 병목현상이 발생할 수 있습니다.
- NUMA 아키텍처
메모리가 각각의 CPU 패키지에 직접적으로 연결되도록 구성되어 있습니다. CPU들은 다른 패키지에 연결되어 있는 메모리도 사용할 수 있습니다. 이 구조는 SMP에서 한 곳으로 몰리던 메모리 버스를 여러 곳으로 분산시켜 줌으로써 병목현상을 막고 메모리 접근성을 향상시킵니다.
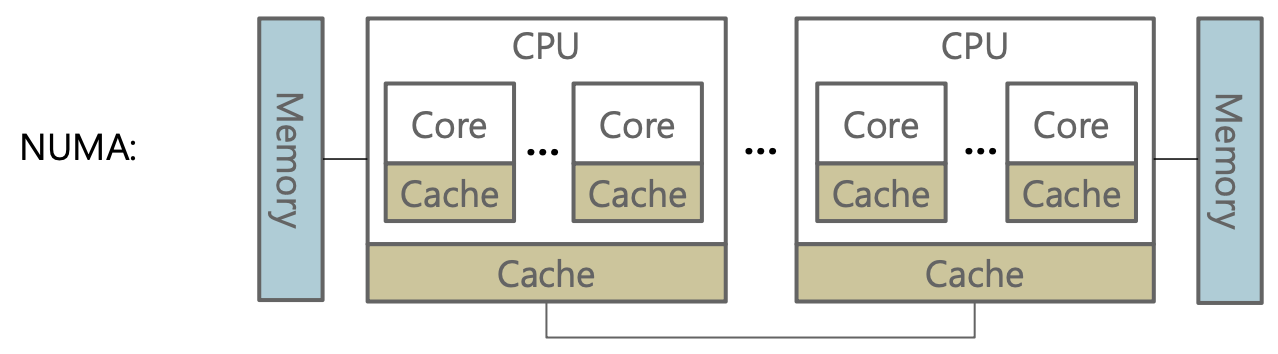
이 때, 캐시 데이터는 메인 메모리에 있는 데이터의 복사본입니다.
데이터의 변경일 일어날 때, CPU는 메모리에 존재하는 값을 캐시로 복사해온 뒤 우선 캐시의 데이터를 먼저 갱신합니다. 이는 메인 메모리에 나중에 반영됩니다. 그 사이에 다른 CPU에서 동일한 메모리 주소에 접근하면 갱신 이전의 값을 참조하게 됩니다. 이로 인해 캐시 일관성 문제가 발생합니다.
CPU scheduling algorithm
1. SQMS
: Single-Queue Multiprocessor Scheduling
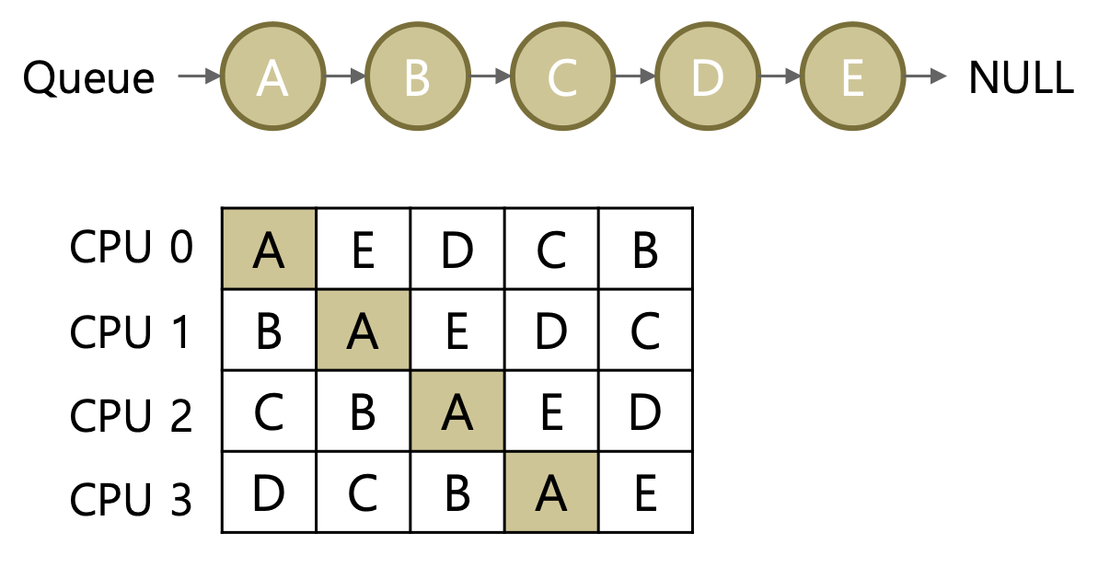
여러 프로세서가 하나의 레디큐에서 작업(job)들을 꺼내 실행하는 방식입니다.
모든 프로세서가 단일 큐를 공유하므로 경쟁 상태(race condition)가 발생할 수 있습니다. 이를 해결하기 위해, 레디 큐에 lock을 설정하여 한 CPU가 작업을 가져가는 동안 다른 CPU가 큐에 접근하지 못하도록 합니다. 이 방식은 synchronization 오버헤드가 발생하므로 코어의 수가 늘어남에 따라 확장성(scalability)이 저하됩니다.
또한, 이 방식은 캐시 친화성(cache affinity) 문제도 포함하고 있습니다. SQMS 방식을 사용할 경우, 하나의 작업이 항상 동일한 프로세서에서 처리된다는 것을 보장할 수 없습니다. 예를 들어, 작업 A가 처음에 CPU 0에서 실행되어 메인 메모리로부터 데이터를 복사하여 저장했다고 가정합시다. 이후 A가 blocked 상태가 됐다가 다시 ready 상태가 되어 CPU 1에서 실행되면, CPU 1은 CPU 0의 캐시를 사용할 수 없기 때문에 메모리에서 다시 데이터를 복사해 캐시에 저장해야 합니다. 이는 캐시 친화성을 저하시키며, 실행되는 프로세서가 변경될 때 메모리 접근 지역성도 떨어지게 만듭니다.
2. MQMS
: Multi-Queue Multiprocessor Scheduling
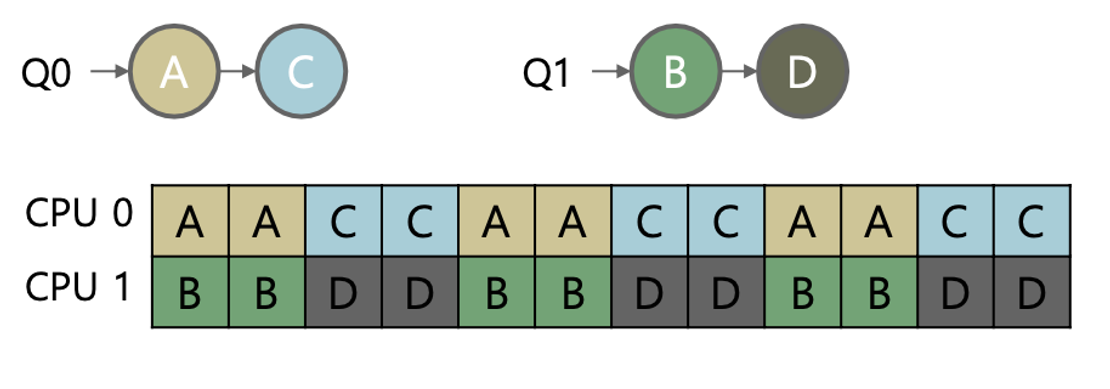
MQMS는 각 CPU마다 별도의 레디큐를 가집니다. 하나의 작업(job)은 여러 큐에 동시에 존재할 수 없습니다. 각 CPU는 오직 자신의 큐에만 접근하여 독립적으로 작업을 스케줄링하고 실행합니다. 이 방식을 사용하면 동기화(synchronization)을 할 필요가 없어지며, 하나의 작업은 동일한 CPU에서만 동작하는 것이 보장되어 캐시 친화성도 유지됩니다.
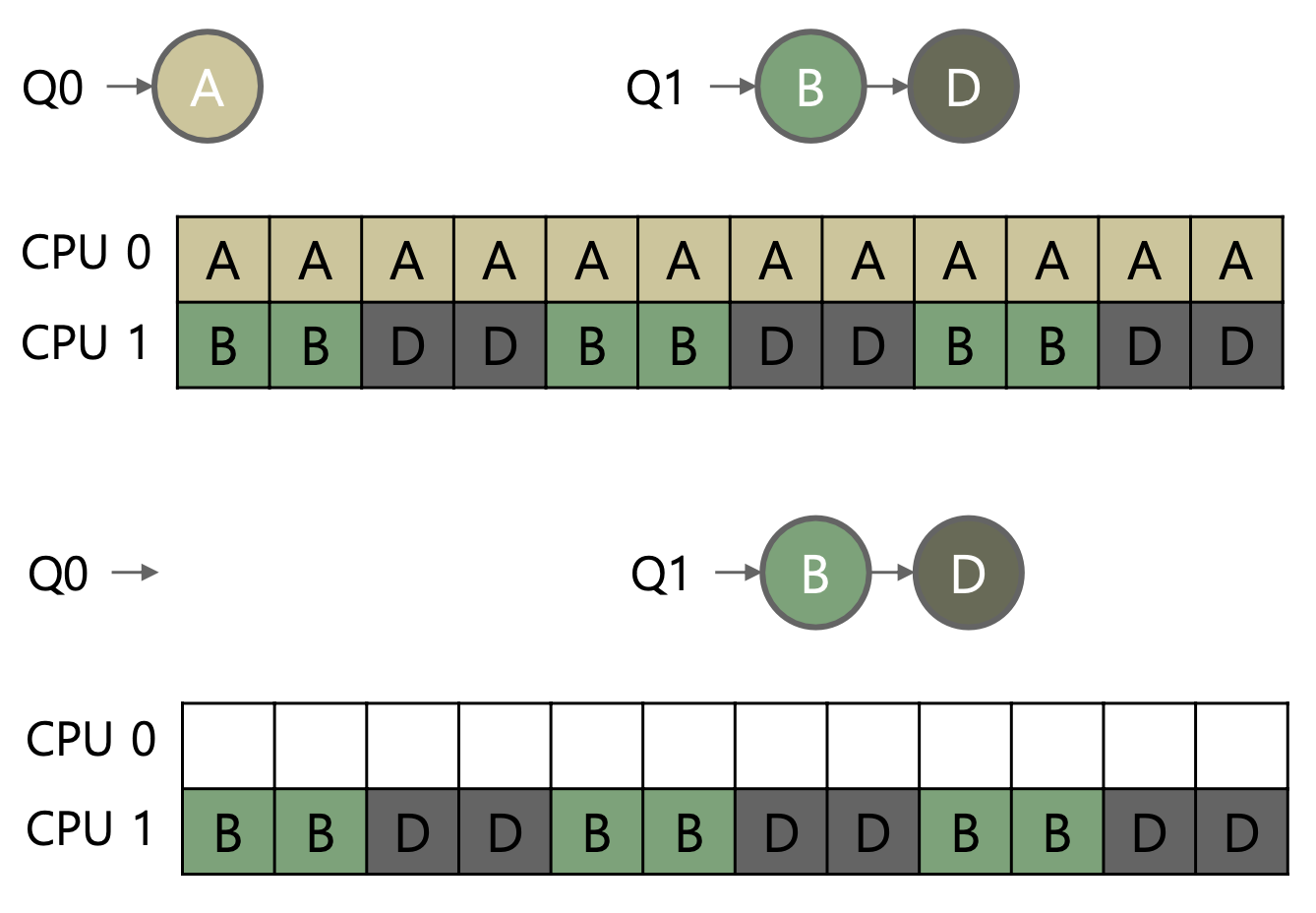
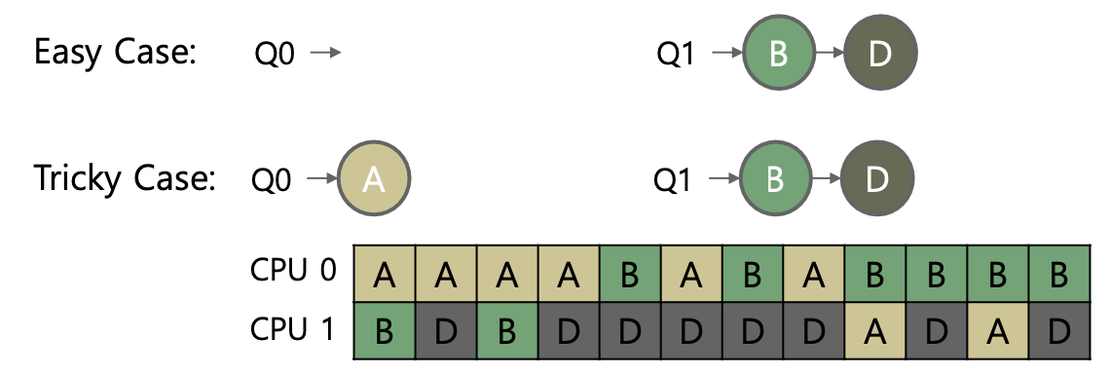
하지만 각 CPU가 자신만의 큐를 독립적으로 관리하면 부하 불균형(load imbalance) 문제가 발생할 수 있습니다. 운영체제가 작업 할당 시 더 짧은 큐를 선택하는 방식을 사용하더라도, 모든 작업의 실행시간이 동일하지 않기 때문에 이 문제를 해결하지 못합니다. 이 문제를 해결하기 위한 2가지 주요 방법은 migration 과 work stealing 입니다. migration은 작업이 몰려 바쁜 CPU가 여유 있는 CPU에게 작업을 넘기는 반면, work stealing은 여유 있는 CPU가 바쁜 CPU의 작업을 직접 가져오는 방식입니다. 이러한 접근은 부하를 효과적으로 분산시키며, memory-unbound 작업을 선택하여 메모리 접근 지역성 감소를 방지합니다.
예를 들어, CPU0의 큐(Q0)에 2개의 작업이, CPU1의 큐(Q1)에는 하나의 작업만 남아 있는 경우, Q1이 작업을 가져와도 부하 불균형은 여전히 유지됩니다. (핑퐁 현상) 이러한 상황을 해결하기 위해 두 CPU가 하나의 작업을 동시에 수행할 수 있으나, 이 방법은 다른 CPU에서 작업을 실행할 때 캐시 친화성 문제를 야기할 수 있습니다. 따라서, 성능 저하를 방지하기 위해 적당한 불균형을 허용하는 것이 필요합니다.
Linux CPU Schedulers
리눅스 환경에서 CPU 스케줄러가 어떻게 구현되어 있는지 알아봅시다!
리눅스 환경에서의 우선순위에는 ~~~가 있습니다.
- CFS는 우선순위가 ~~인 작업을 스케줄링 할 때 사용되고, 2/3은 CFS가 처리하ㅡㄴ
2, 3번 스케줄러는 root 권한이 있어야만 사용 가능합니다.
처리하는 작업의 우선순위 : (가장 높음) Deadline Scheduler > RealTime Sceduler > CFS (가장 낮음)
1. Deadline Scheduler
리눅스 내에서 SCHED_DEADLINE 으로 정의되어 있습니다. 이 스케줄러는 deadline이 얼마 남지 않은 작업부터 먼저 실행시킵니다. (EDF : earliest deadline first)
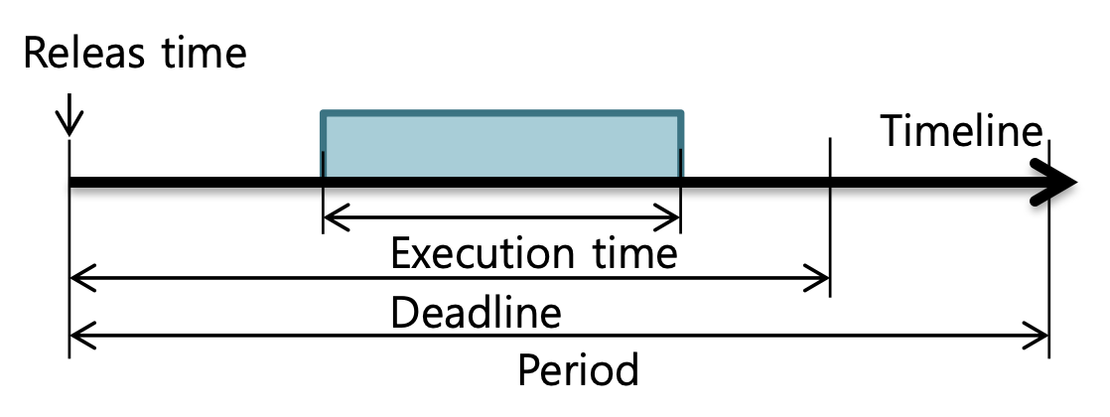
응용 프로그램은 한 주기마다 정해진 실행 시간만큼 동작하도록 되어 있고, 정해진 deadline 이전에 한 주기의 작업을 모두 마쳐야 합니다. 이 때, 주기, 실행 시간, deadline은 각 응용 프로그램이 직접 등록합니다.
이 스케줄러에서도 root 권한으로sched_setattr() 시스템콜을 사용해서 우선순위를 직접 변경할 수 있습니다.
2. Real-Time Scheduler
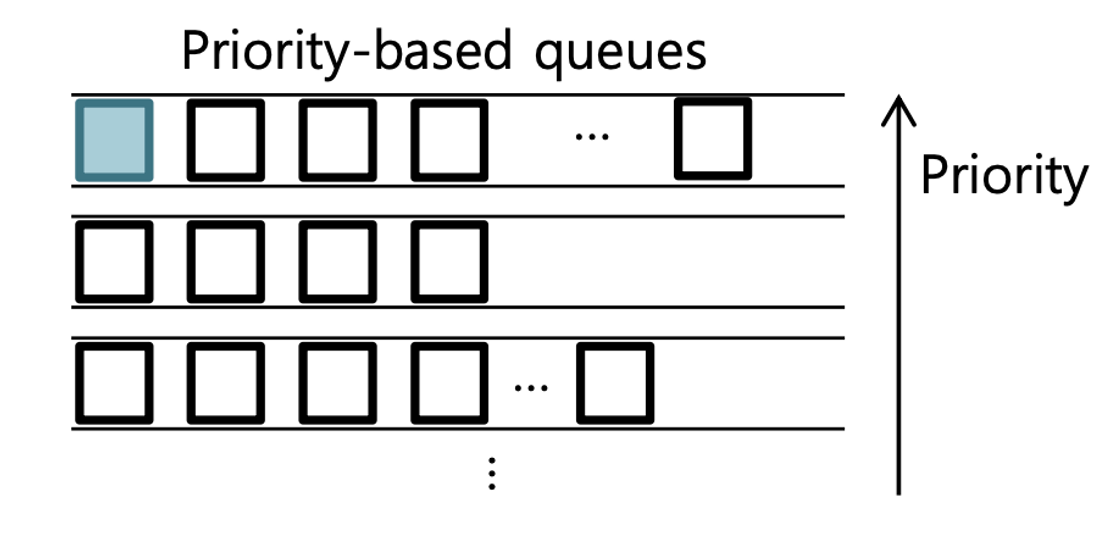
리눅스 내에서 SCHED_FIFO 와 SCHED_RR로 정의되어 있습니다. FIFO와 RR은 우선순위가 동일한 작업을 어떠한 방식으로 처리할지에 대한 방식만 다릅니다. MLFQ (Multi-Level Feedback Queue)와 자료구조는 비슷하지만, 작업들의 우선순위가 시간이 지남에 따라 바뀌지 않고 고정되어 있다는 차이점이 있습니다. 작업들의 우선순위는 sched_setattr() 시스템콜을 사용해서 직접 바꿀 수 있지만 root권한이 있어야만 사용 가능합니다. 시스템콜로 우선순위를 직접 바꿔주기 전까지는 이전의 우선순위가 유지됩니다.
3. CFS
(Completely Fair Scheduler)
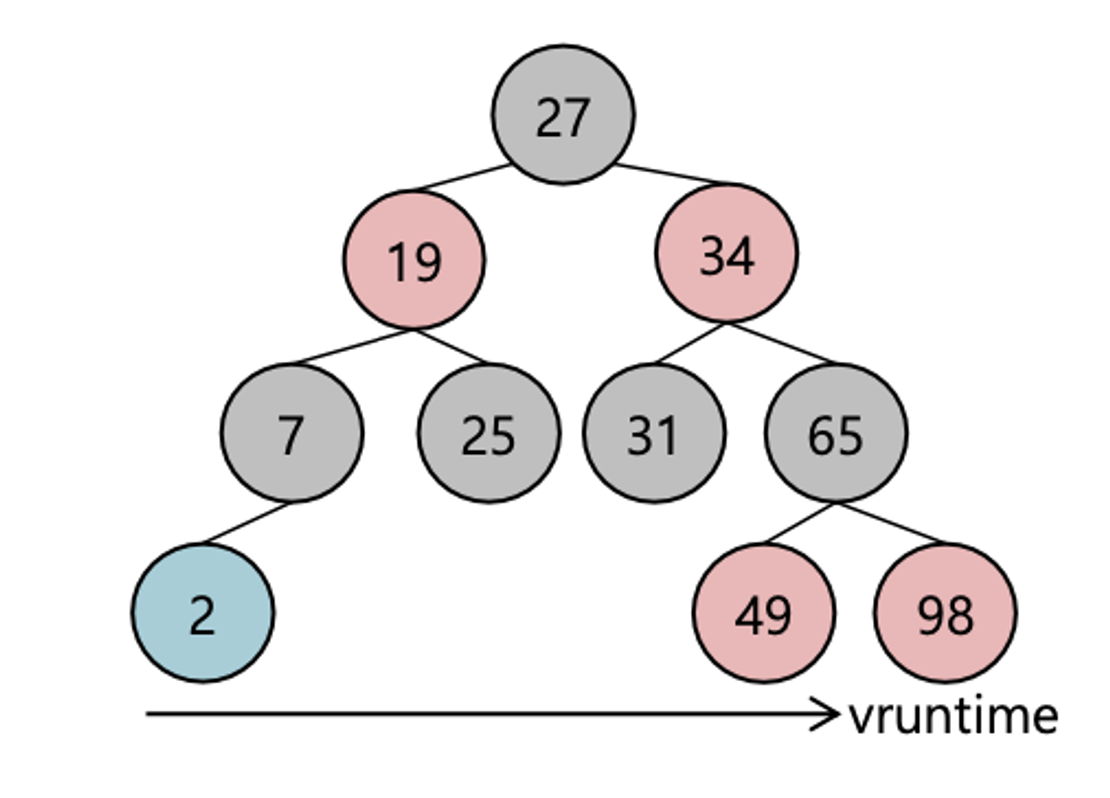
CFS는 nice value에 따라 가중치를 조정하며 CPU 사용 시간이 배분됩니다.
CFS에서는 레디 큐가 레드-블랙 트리(balanced tree)로 구현되어 있습니다. 트리 정렬 시 key로는 을 사용합니다. 은 CPU 자원 사용 시간의 누적값으로, 아래의 식처럼 가중치를 반영하여 계산합니다.
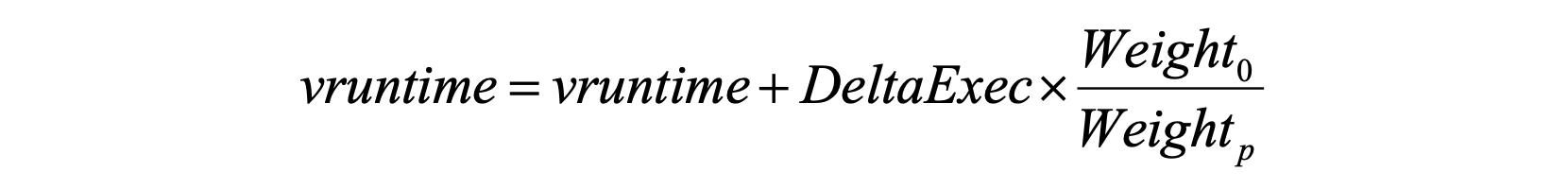
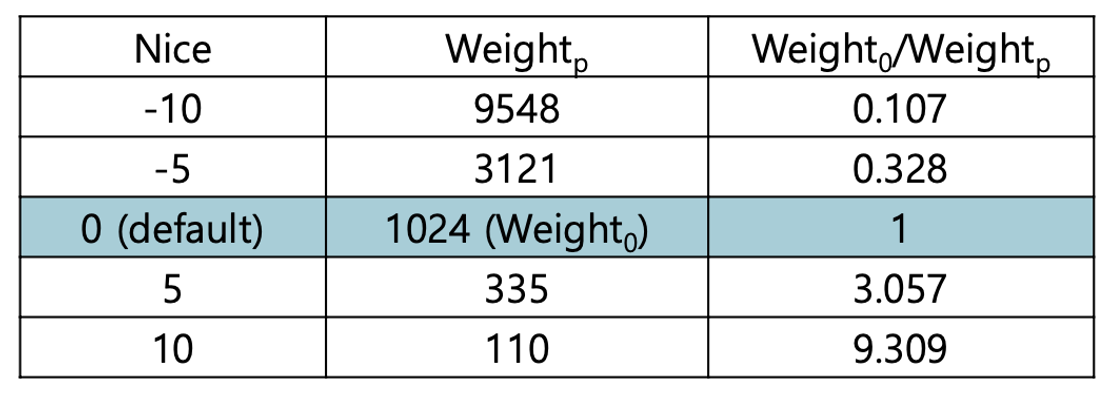
이전까지의 vruntime에 새로 추가된 CPU 사용 시간(DeltaExec)을 가중치를 반영하여 더합니다. 기본 가중치 은 1024이며, 각 작업의 nice value에 따라 다른 가중치 를 적용합니다.(아래의 표를 통해 nice value에 대응되는 를 구할 수 있습니다.) nice value는 -20에서 19 사이의 값을 가지며, 이 값은 작업에게 할당된 CPU 사용 시간보다 덜 사용했을 때 높아집니다. nice value가 클수록 작업이 자신의 실제 실행 시간(DeltaExec)을 크게(중요시) 여김을 의미하며, 이에 따라 1 이상의 가중치를 곱하여 을 계산합니다. 결과적으로 이 더 크게 증가하여 해당 작업의 다음 CPU 사용 시간이 줄어들게 됩니다. 반대로, nice value가 작은 경우 실제 실행 시간보다 더 적은 시간이 에 더해지므로, 다음에는 CPU를 더 오래 사용할 수 있게 됩니다.
가장 적은 시간동안 실행된 작업이 트리의 가장 왼쪽 아래에 위치합니다. OS는 모든 작업의 CPU 사용시간 균형을 최대한 맞추고자 합니다.
