이 글은 건국대학교 2024년 1학기 운영체제 수업과 『Operating Systems: Three Easy Pieces』 를 참고하여 작성되었습니다.
『Operating Systems: Three Easy Pieces』
19장. Paging: Faster Translations (TLBs)
앞선 글에서 다뤘던 페이징 기법은 주소공간의 정보로부터 실제 주소를 구하는 데 추가적인 메모리 접근이 발생하기 때문에 성능 저하를 유발합니다. 이러한 문제점을 극복하기 위해서 하드웨어가 제공하는 TLB (Translation-Lookaside Buffer)를 사용합니다.
TLB
1. TLB란?
: address translation cache
TLB는 PTE를 저장하는 하드웨어 캐시로, CPU의 MMU에 저장됩니다.
(MMU는 memory management unit으로 CPU의 메모리 관리부 라고도 합니다. paging 기법을 지원하기 위해 CPU에 정의해 놓은 모든 것들을 의미합니다.)
TLB는 메모리 접근 없이 빠른 속도로 주소 변환을 가능하게 합니다.
2. TLB 알고리즘 (작동원리)
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // TLB hit : 엔트리가 TLB에 존재
if (CanAccess(TlbEntry.ProtectBits) == True)
offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // TLB miss : 엔트리가 TLB에 없음
PTEAddr = PTBR + (VPN * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()- 가상주소를 통해 VPN 구하기
TLB_Lookup(VPN): TLB에 해당 VPN에 해당하는 엔트리가 있는지 검색
case1) TLB hit : 엔트리가 TLB에 존재
- 해당 엔트리가 유효한지 확인 후, PFN과 offset 구하기
- 구한 물리주소(PFN|offset)를 사용하여 메모리에 접근한다.
case2) TLB miss : 엔트리가 TLB에 존재하지 않음
- PTBR을 사용하여 PTE의 주소 구하기
PTE = AccessMemory(PTEAddr): 메모리에 있는 page table에 접근하여 PTE를 가져온다.- 가져온 PTE가 유효한지 확인 후, TLB에 저장한다.
RetryInstruction(): TLB hit 조건부가 다시 실행되도록 한다.
메모리 접근은 다른 CPU 연산에 비해 시간이 매우 오래 걸립니다. TLB 미스가 많이 발생하면 메모리 접근 횟수가 많아집니다. 따라서 TLB 미스가 최소화되도록 TLB 관리 전략을 세워야 합니다.
예제

위의 그림과 같이 8-bit addressing & 16-byte page 인 가상 주소 공간에서 100번지부터 10개의 4바이트 크기 정수 배열이 존재합니다. 이 배열에 0번째 인덱스부터 9번째 인덱스까지 차례대로 접근한다고 가정해봅시다.
int sum = 0;
for (int i=0;i<9;i++) {
sum += a[i];
}(같은 page에 위치하면 VPN이 같고 같은 PTE를 사용하므로)
이 경우 새로운 페이지에 처음 접근하는 경우인 a[0], a[3], a[7] 에서만 TLB miss가 발생하여 메모리에 접근해서 가져온 엔트리를 TLB에 저장하고, 이후 같은 페이지에 접근할 땐 TLB hit가 발생하여 메모리가 아닌 TLB에만 접근하므로 빠른 속도로 주소 변환이 가능합니다. (hit rate : 70%)
이처럼 같은 페이지를 연속해서 접근하도록 작성되어 있어 있는 코드는 TLB의 사용 효과를 톡톡히 누릴 수 있습니다.
+ 캐싱에 대해서
: 캐시는 지역성을 활용하여 성능을 개선하는 기술이다.
- 시간 지역성 : 최근에 접근된 명령어 또는 데이터는 곧 다시 접근될 확률이 높다.
- 공간 지역성 : 메모리 주소 x를 읽거나 쓰면, x와 인접한 메모리 주소를 접근할 확률이 높다.
빠른 캐시를 원한다면 캐시의 크기는 작아야 한다. 캐시의 크기가 커지면 느려질 수밖에 없다. → 작은 캐시를 어떻게 잘 사용할지 고민해야 한다.
3. TLB miss 처리 방법
1. CPU가 처리
- CISC (Complex-Instruction Set Computers, 복잡 명령어 컴퓨터) : 복잡한 명령어들로 구성된 컴퓨터 구조
과거 CISC 처럼 하드웨어가 TLB miss를 직접 처리하도록 설계했습니다. 이를 위해서는 CPU가 PTBR을 통해서 메모리에 있는 page table에 직접 접근할 수 있어야 했습니다.
TLB 알고리즘 (작동원리) 에서 살펴본 코드가 바로 CISC에서 CPU의 TLB miss 처리 과정입니다.
2. OS가 처리
- RISC (Reduced instruction set computing, 축소 명령어 컴퓨터) : 소프트웨어 관리 TLB를 사용하는 컴퓨터 구조
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // TLB hit : 엔트리가 TLB에 존재
if (CanAccess(TlbEntry.ProtectBits) == True)
offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // TLB miss : 엔트리가 TLB에 없음
RaiseException(TLB_MISS)이 방식에서는 TLB miss가 발생하면 RaiseException(TLB_MISS) 예외를 발생시켜 OS에게 책임을 넘깁니다. 예외를 처리하기 위해 실행 모드가 커널 모드로 변경되고, 커널 코드(트랩 핸들러)가 실행됩니다. 이때 실행되는 트랩 핸들러는 TLB miss 처리를 담당하는 운영체제 코드로 시스템 콜 호출시 실행되는 트랩 핸들러와 차이가 있습니다. 시스템 콜 호출의 경우, 트랩 핸들러 리턴 후 시스템 콜 호출 명령어의 다음 명령어를 실행합니다. 하지만 TLB miss 처리의 경우, 트랩에서 리턴 후 트랩을 발생시킨 명령어를 다시 실행해야 하며, 재실행 시에 TLB hit가 발생합니다.
→ 두 경우에서 저장되는 Program Counter 값이 다르다.
OS가 TLB miss를 처리하는 방식은 유연성이라는 장점을 갖습니다. OS는 하드웨어 변경 없이 페이블 구조를 자유로이 변경할 수 있습니다. 즉, multi-level page table과 linear page table 중 원하는 것을 구현하여 사용할 수 있습니다. 또한 하드웨어는 예외만 일으키고 운영체제가 나머지 일을 처리하므로, TLB miss 시 하드웨어가 하는 일이 별로 없어 단순하다는 장점도 있습니다.
4. TLB의 구성
TLB 구성 : 무엇이 있나?
일반적으로 TLB는 32 or 64 or 128개의 엔트리를 가지며 fully associative 방식으로 설계됩니다. fully associative 방식은 변환 정보(엔트리)가 TLB 내에 어디든 위치할 수 있으며, 원하는 변환 정보를 찾는 검색은 TLB 전체에서 병렬적으로 수행됩니다.
TLB 구조 : VPN | PFN | other bits
context switch 시 TLB 관리 방법
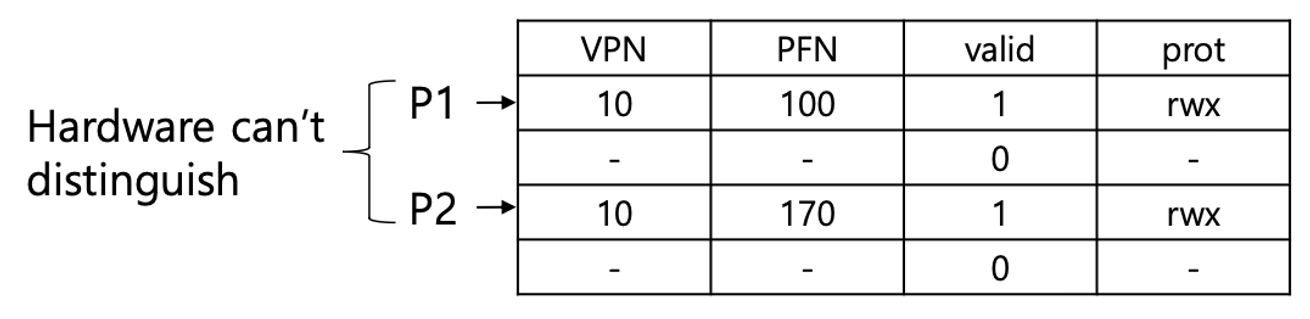
위의 경우 처럼 P1과 P2가 동일한 VPN을 가지고 있으면 하드웨어는 이를 구분할 수 없습니다. 이러한 문제를 해결하기 위해 context switch 발생 시 기존 TLB의 모든 엔트리의 valid bit를 0으로 설정하는 방법이 있습니다. (TLB flush)
하지만 이러한 방법을 사용하면 context switch가 일어날 때마다 TLB miss가 발생하므로 TLB를 사용함으로써 얻는 이점을 잃을 수 있습니다. 또한 발생 시마다 invalid 처리를 하는 것 역시 큰 오버헤드를 수반합니다.

이 부담을 개선하기 위해 도입한 필드가 ASID (address space ID, 프로세스 식별자) 입니다. 이를 통해 context switch가 일어나도 TLB의 내용을 보존할 수 있습니다.
하지만 ASID의 비트 수가 PID의 비트 수보다 적어서 발생하는 문제가 있습니다. 이 문제의 해결 방안으로는 크게 3가지가 존재합니다.
1. ASID 만큼 프로세스의 개수를 제한
2. ASID 만큼 프로세스를 사용한 후, 그 이후에 발생하는 context switch에선 프로세스를 모두 flush 처리한다. (TLB에 저장하지 않고 버린다) 이 때부턴 새로운 프로세스가 등장할 때마다 메모리에 접근하므로 context switch의 오버헤드가 커진다.
3. ASID와 PID를 일대일 매핑시키지 않고 동적으로 매핑한다.
주로 3번 방안을 많이 사용합니다.
실제 TLB 구성 예시
ex) MIPS R4000의 실제 TLB entry

VPN: 20bit의 VPN 중 1bit는 전역 비트G이다.G: 프로세스들이 공유하고 있는 페이지를 나타낸다. 공유 중인 페이지는 ASID가 무시된다. (공유 중인 페이지는 주고 kernel space를 의미한다. 이를 통해 한 프로세스의 주소공간 4GB 중 절반은 user space, 나머지 절반은 kernel space가 배정되는 것을 알 수 있다.)ASID(address space ID) : context switch 발생 시 프로세스를 식별한다.PFN: 24bit가 할당되어 있다. 실제 물리 메모리를 64GB 까지 장착할 수 있는 시스템이다.C(coherence bit): 캐시 일관성, 캐시 정책 등 페이지가 하드웨어에 어떻게 캐시되어 있는지를 판별한다.D(dirty bit): 페이지가 갱신되었는지 여부를 판별한다. write가 발생 여부V(valid bit): 해당 항목이 유효한 변환 정보를 갖고 있는지 여부를 나타낸다.- protection bit : 해당 항목이 읽기, 쓰기, 실행, 사용자/커널 모드 접근 권한 중 어떤 권한을 가지고 있는지를 나타낸다.
5. TLB에서의 캐시 교체 정책
어떤 항목을 제거해야 TLB miss rate를 최소화할 수 있을지 고민해야 합니다.
가장 흔한 방법으로는 LRU (Least Recently Used) 항목을 교체하는 것입니다. 이 메모리 참조 패턴에서의 지역성을 최대한 활용하는 방식입니다.
이 방식은 TLB의 크기가 작은 상황에서 배열을 행이 아닌 열 별로 접근하는 상황에서 예상치 못한 예외를 발생시키여 최악의 TLB miss rate를 생성합니다.
다른 일반적인 방법은 random 정책입니다. 이 방식에서는 교체 대상을 무작위로 정합니다. 구현이 간단하고 예상치 못한 예외를 피할 수 있다는 장점이 있습니다. 하지만 공간 지역성과 시간 지역성이 높은 코드에서는 LRU 정책에 비해 TLB miss rate이 높다는 단점이 있습니다.
