
*[서울 ICT이노베이션스퀘어] 인공지능 고급 시각지능 프로젝트 개발
0. Introduction
0.1 세계 인공지능 시장규모
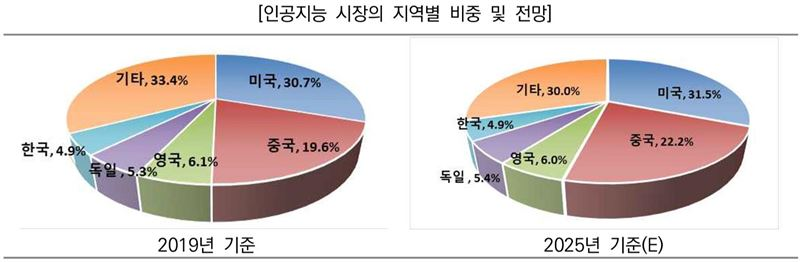
전 세계적으로 인공지능의 규모는 점점 커져가고 있는데 그 중에서도 이 시장을 주도하는 것은 미국과 중국이다. 이러한 차이가 날 수 밖에 없는 이유는 데이터의 양 때문이다. 인공지능의 경우 데이터가 가장 중요한데 미국과 중국은 데이터 중에서도 쓸만한, 가치있는 데이터가 많기 때문이다.
0.2 인공지능 분야별 시장규모
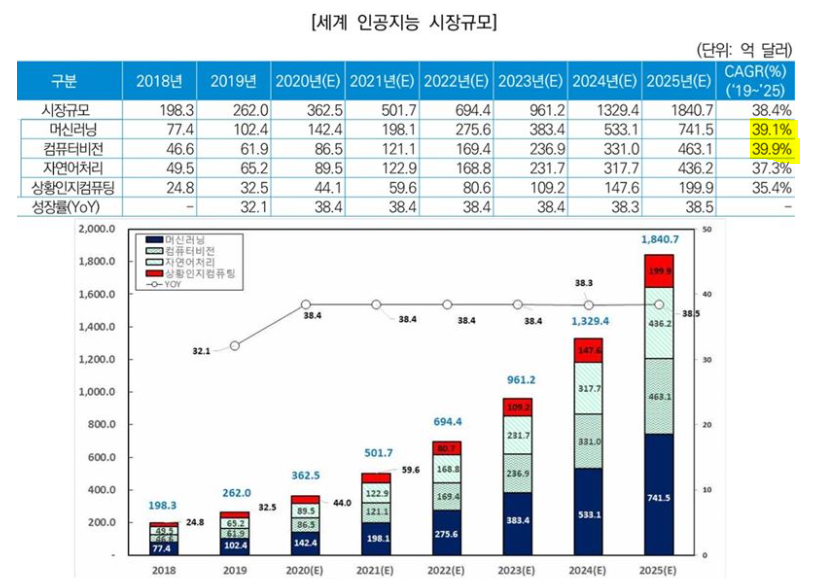
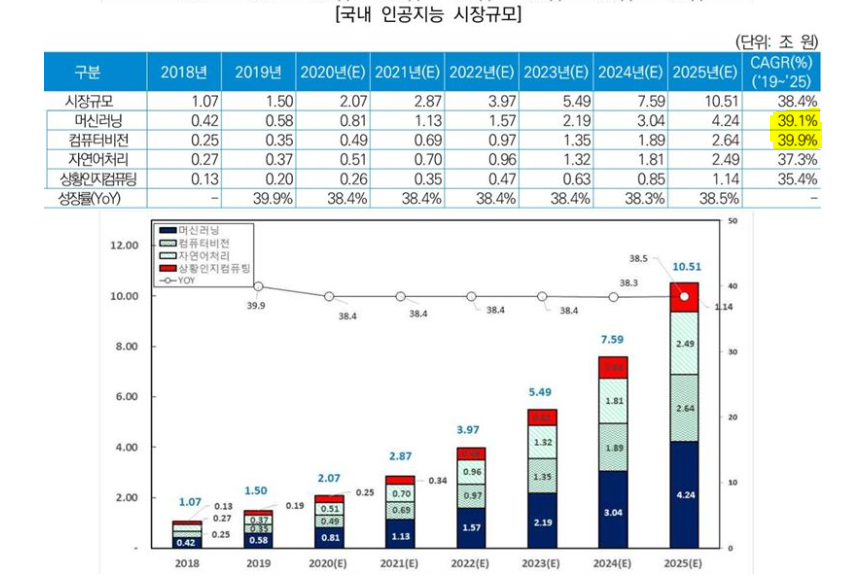
위 표의 CAGR(연평균 성장률)을 보았을 때 성장성이 가장 높은 인공지능 분야는 컴퓨터비전이다. 여기서 주목해야할 점은 컴퓨터비전과 자연어처리의 성장률 차이다. 컴퓨터비전의 경우 이미지와 같은 시각적인 부분을 처리하는 분야이고 자연어처리의 경우 사람들이 일상적으로 쓰는 언어, 자연적으로 발생된 언어를 처리하는 분야이다. 이 둘의 차이점은 지역적 제약의 유무이다. 컴퓨터비전이 처리하는 이미지나 영상의 경우 전세계적으로 지역적인 제약이 존재하지 않는다. 따라서 해당 데이터에 전세계적으로 동일한 알고리즘과 아키텍처를 적용하는 것이 가능하다. 그러나 자연어처리가 다루는 언어의 경우 알파벳과 한국어의 경우만 보아도 받침의 유무부터 다르다. 이는 전세계적으로 공통된 알고리즘과 아키텍처를 적용하는 것이 불가하다는 의미이자 각 지역별 알고리즘과 아키텍처를 구성해야 한다는 의미이다. 컴퓨터비전이 자연어처리보다 우세하다라는 말이 아니라 둘의 성장 속도가 다를 수 밖에 없다는 것이다.
1. 컴퓨터 비전(Computer Vision)
- 인간의 시각 기능을 컴퓨터 기술로 구현할 수 있는 모든 것
- 종류
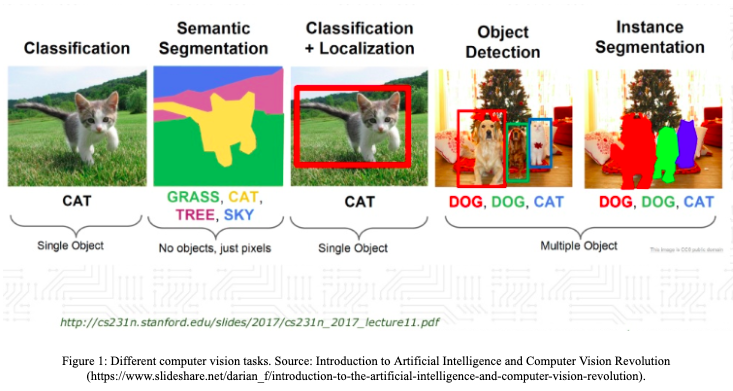
- Classification
- Object
- 해당 객체가 무엇인지 분류
- 알고리즘 : CNN
- Semantic Segmentation
- Pixel
- 객체 구분 없이 오직 모든 픽셀에 카테고리만 부여
(각 픽셀이 어느 클래스에 속하는지 아닌지 여부를 알 수 있다.) - 알고리즘 : FCN
- Object Detection = Classification + Localization
- Object + Position
- 해당 객체의 위치를 bounding box로 찾아내는 것
- 알고리즘 : YOLO
- Segmentation
- Object + Outline
- 객체의 경계 표시
- 알고리즘 : FCN, UNET, DeepLab
- 대표적인 예로 암의 위치를 파악하는 데에 쓰인다.
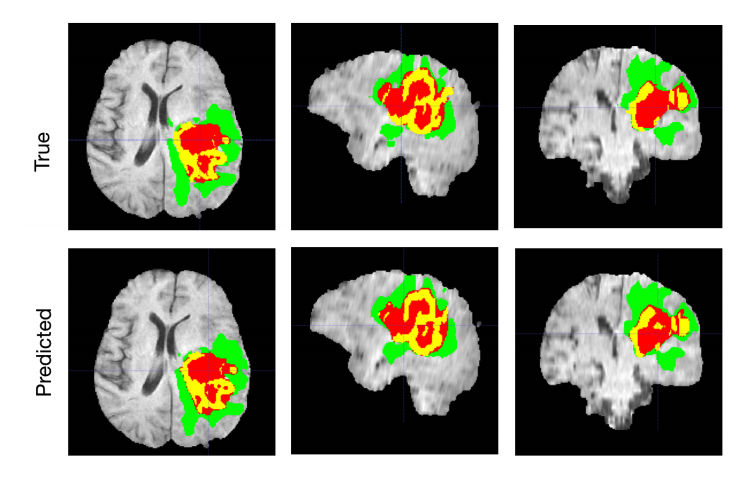
- Classification
2. AI/ML/DL
2.1 인공지능(AI, Artificial Intelligence)
- 인공적으로 만들어진 지능
- 사람이 생각하고 학습하는 것을 기계가 대신하는 모든 것
2.2 머신러닝(ML, Machine Learning)
- 수학적 알고리즘/공식을 이용해 데이터의 명확히 정리되지 않은 특성과 패턴을 학습하여, 그 결과를 바탕으로 미지의 데이터에 대한 미래 결과(값, 분포)를 예측하는 것
- Data + Learning + Prediction
데이터 마이닝 vs 머신러닝
- 데이터 마이닝 : 현재 데이터 상태가 어떤 상관관계를 가지고 있는지 파악
- 머신러닝 : 데이터를 분석해 미래의 값을 예측
-
종류
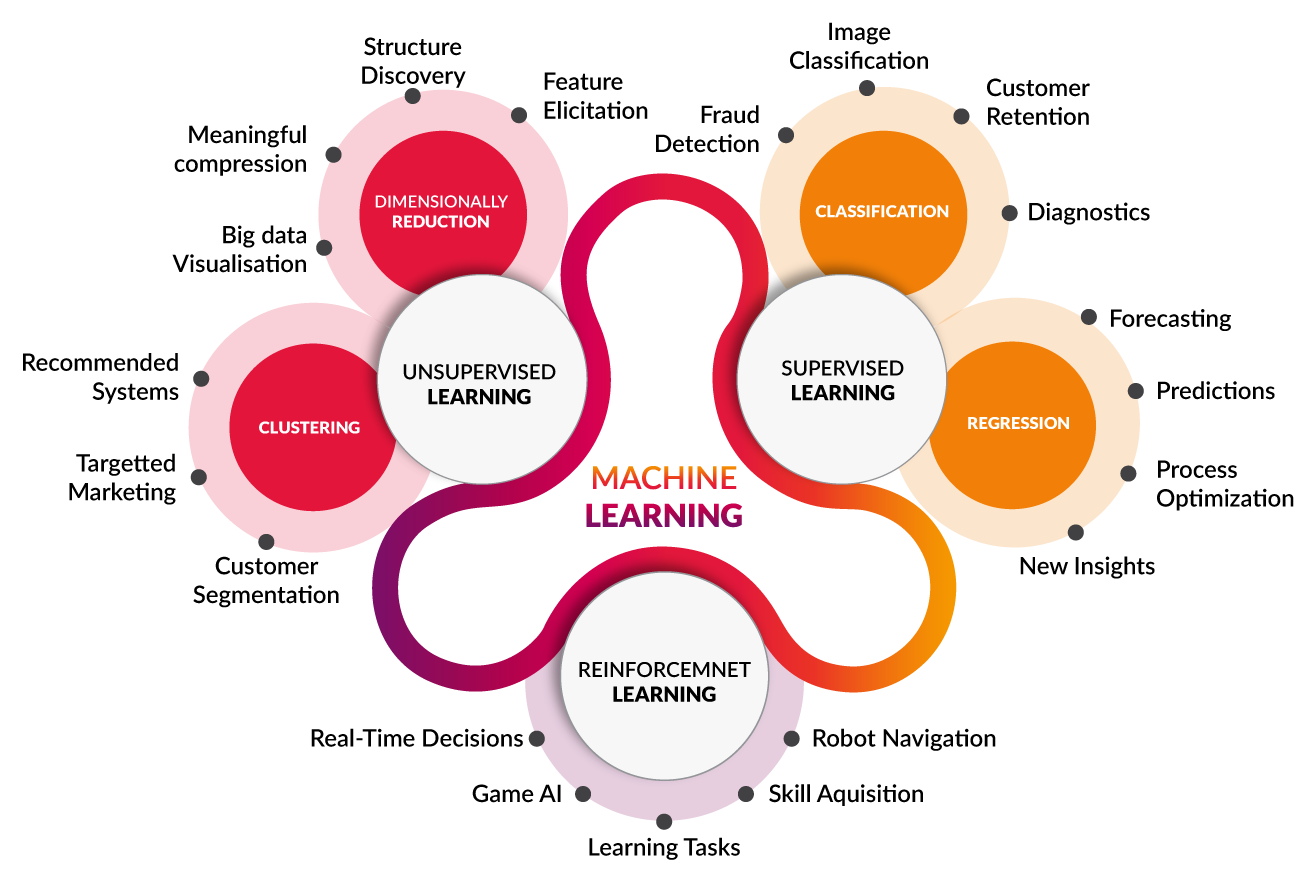
-
지도학습 (Supervised)
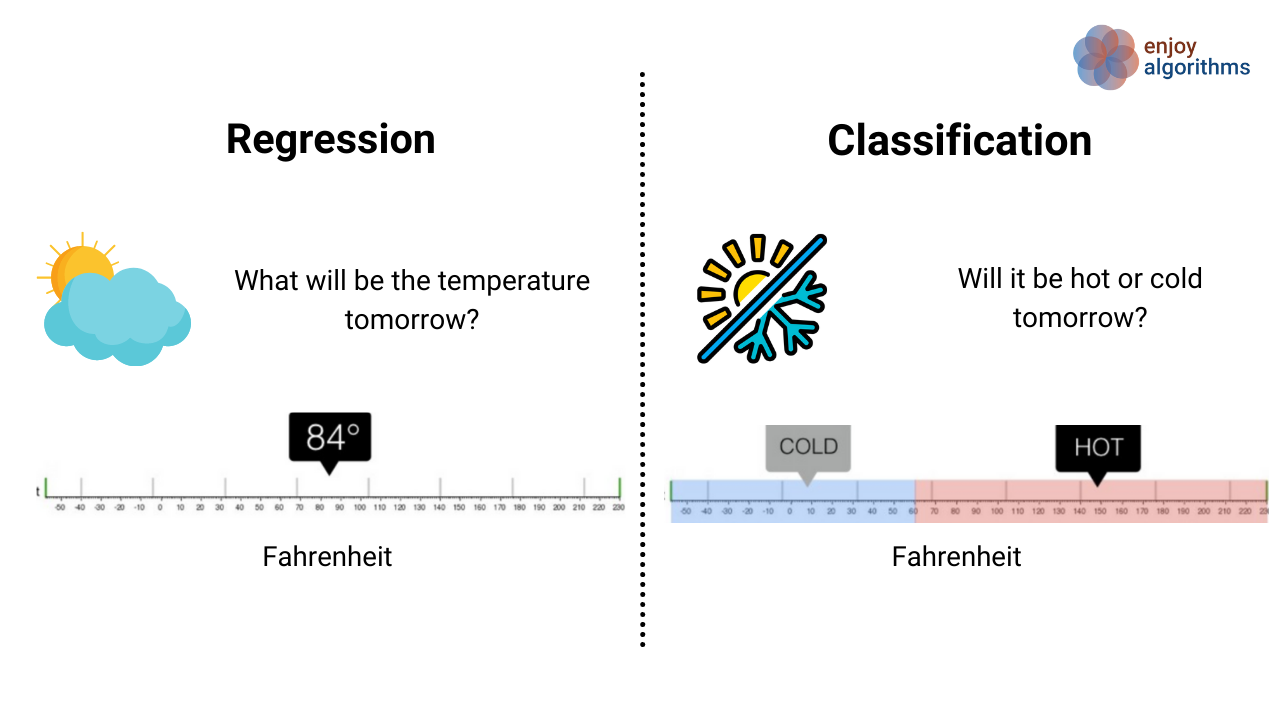
- 정답/레이블이 있는 데이터로 컴퓨터를 학습(머신러닝)하는 방법
- 미지의 데이터에 대한 미래 결과(값, 분포) 예측
- train data = input + label
- 종류
- 회귀(Regression) : 연속적인(Continuous) 숫자값 예측
- 분류(Classification) : 이산적인(Discrete)값 예측 → Computer Vision
구분법
- 정답 데이터(label) 형태가 어떠한가?
- 미래의 무엇을 예측하는가?
-
비지도학습 (Unsupervised)
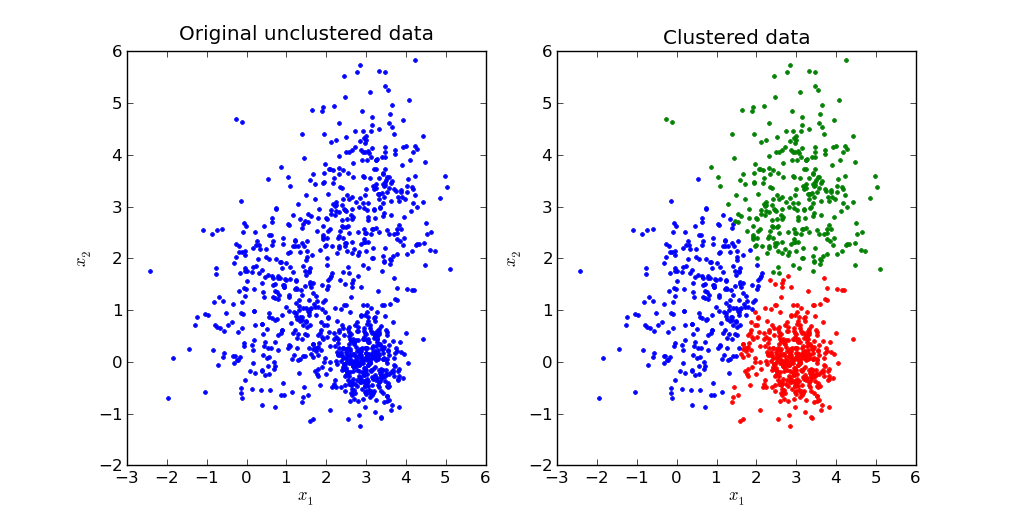
- 정답/레이블이 없는 데이터로 컴퓨터를 학습(머신러닝)하는 방법
- 데이터의 숨겨진 구성 or 특징 발견 목적
- train data = input
- 종류
- 군집화(Clustering)
- 차원축소(Dimensionally Reduction)
-
강화학습 (Reinforcemnt)
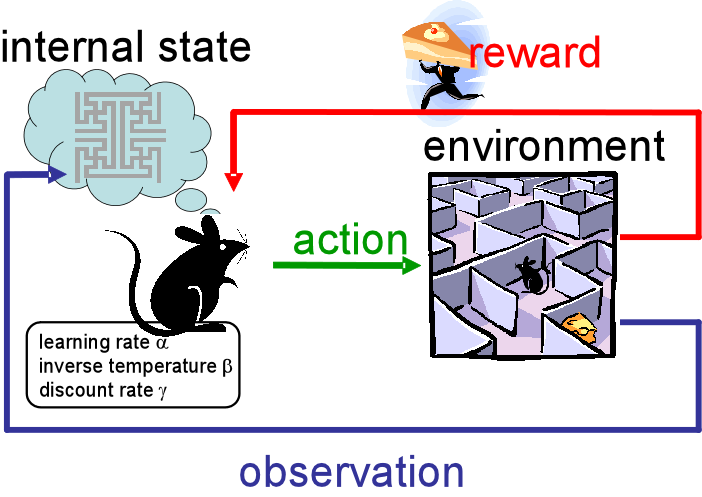
- 보상 시스템으로 다양한 데이터(input, label, parameter)를 무한대로 생성해 최적의 정답을 찾아내는 방법
- (자전거를 배울 때처럼) 사람이 시행착오를 겪으며 배우듯 시행착오 과정에서 컴퓨터 스스로 학습하게 하려는 분야
- 소프트웨어 에이전트(agent)가 환경(environment) 내에서 보상(reward)이 최대화되는 방향으로 행동(action)을 수행하도록 학습하는 기법
- 자율주행자동차
- 벽돌깨기 게임
- action : 이동 막대(bar) 왼쪽, 오른쪽, 발사(처음 공을 띄울때)
- reward : 벽돌을 하나씩 깰 때마다 벽돌은 사라지고 점수 즉 보상(reward)을 얻음
- 보상 시스템으로 다양한 데이터(input, label, parameter)를 무한대로 생성해 최적의 정답을 찾아내는 방법
-
머신러닝에서 지도학습이 약 80%, 분류가 약 90%를 차지하는 이유
- 비지도학습의 경우 결과 판별에 사람의 개입이 들어간다.
- 분류가 인간에게 더 직관적이다.
- decision making의 어려움을 느끼는 인간의 특성 : 51%암 vs 1기 암
2.3 딥러닝(Deep Learning)
- 인간의 신경망을 이용해 학습하는 알고리즘 집합
3. ML, DL 기본
3.1 기본 수학
행렬(matrix)의 필요성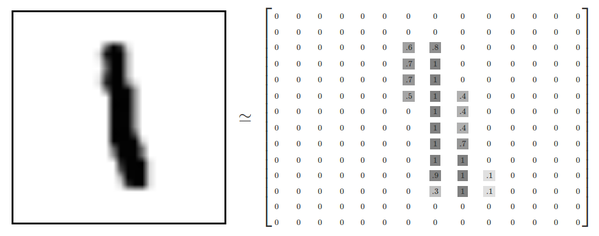
- 행렬은 세상의 거의 모든 것(Text + Image)을 표현할 수 있다.
- 파이썬은 행렬 라이브러리 numpy로 행렬(Tensor)을 표현할 수 있다.
더하기/곱하기/행렬곱의 인사이트
- 더하기
- 각각의 항은 독립적
- 각각의 항에 평균 내포
- 곱하기
- 데이터에 변화를 주는 것
- 행렬곱
- 입력데이터 각각의 항에 변화를 준 것의 평균
- 입력데이터를 평균적으로 변화시키는 행위
### 미분 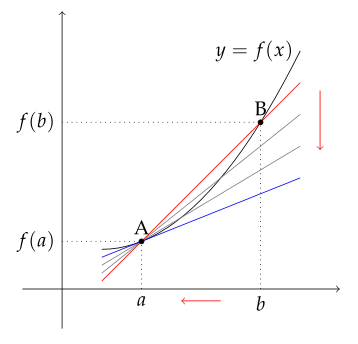 - 입력을 미세하게 바꿀때 이에 대응되는 출력이 어떻게 변하는지 알고자 하는 것 - ${∂loss\over∂W}$ : $W$를 미세하게 바꿀때 $loss$가 얼마나 변하는가! - ${∂loss\over∂b}$ : $b$를 미세하게 바꿀때 $loss$가 얼마나 변하는가
편미분
- 다변수 함수(입력변수 하나 이상)에서, 미분하고자 하는 변수 하나를 제외한 나머지 변수들은 상수로 취급해 변수를 미분하는 것
- 체중(야식, 운동)이라는 다변수 함수에서 편미분을 이용하면 각 변수(체중, 야식)에 따른 체중 변화량을 구할 수 있다.
- : 야식의 양을 조금 변화시키면 체중은 얼마나 변하는가?
- : 운동량을 조금 변화시키면 체중은 얼마나 변하는가?
3.2 ML, DL 기본 아키텍처
W(가중치)와 b(편향)를 바꾸면서 loss가 얼마나 변하는지 관찰
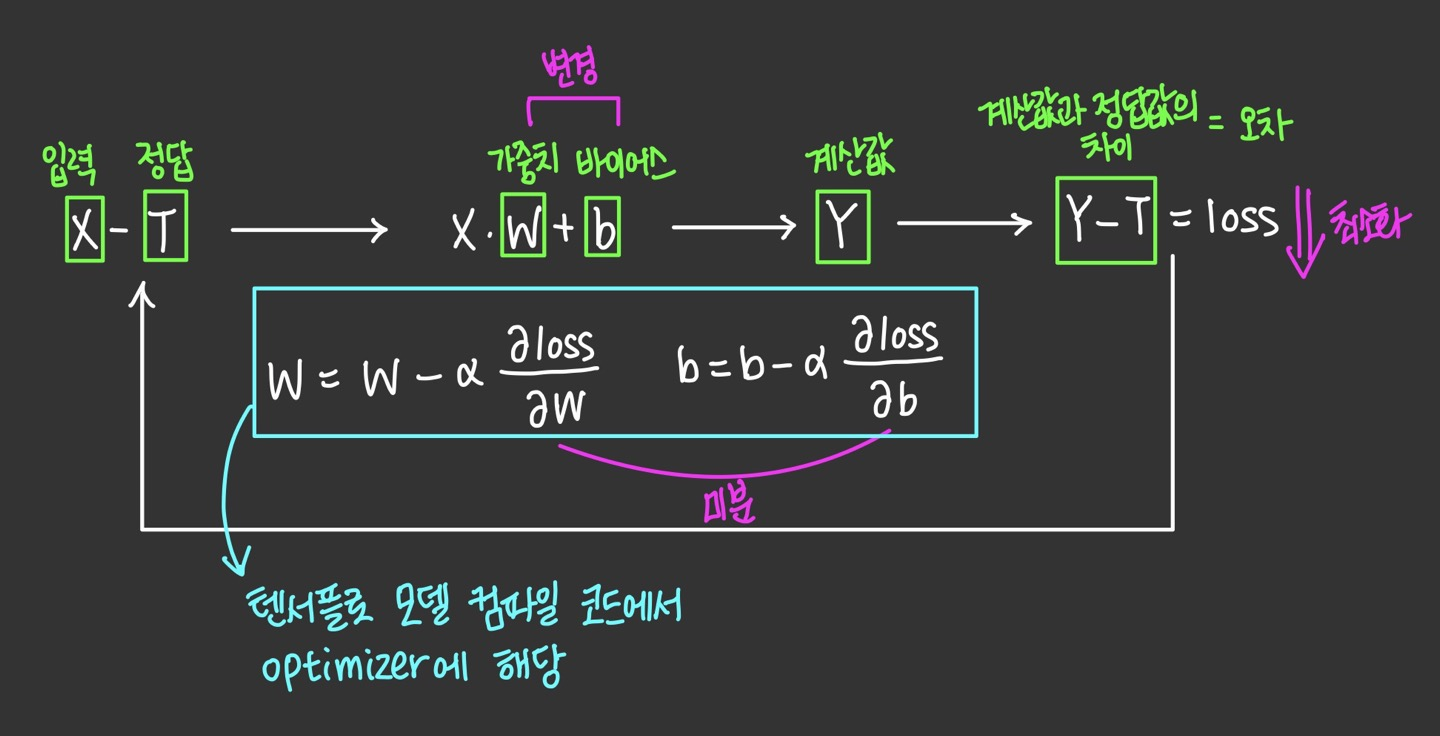
- ML/DL에서 입력데이터에 평균적으로 변화를 주어 Y값에 변화를 주고 loss에 변화(최종 목표)를 주는 것
- 변화 속도가 느린 미분에 accelerating 효과를 주는 것 (정답에 더 빨리 가기 위한 방법)
- 경사하강법(Gradient Descent)
- 위 이미지의 과정을 반복하며 비용함수를 최소화하는 과정
- 머신러닝, 딥러닝의 목적
- 주어진 데이터에 대해 가중치와 바이어스를 최적화시키는 것
- loss가 최소가 되는 W와 b를 찾는 것
(W와 b를 제외하고 모두 고정값이므로 변동값인 W와 b의 값을 바꾸어야 함) - 정확도(accuracy)는 위 과정의 결과물
- 손실함수
- 손실함수의 공통점
- 정답과 계산값 차이
- 평균값
- 손실함수는 정말 많지만 머신러닝에서 이 중 어떤 것을 써도 상관없다. 다만 해당 아키텍처를 제일 잘 반영할수록 정확해진다.
- 손실함수의 공통점
3.3 ML, DL 일반적 개발 프로세스
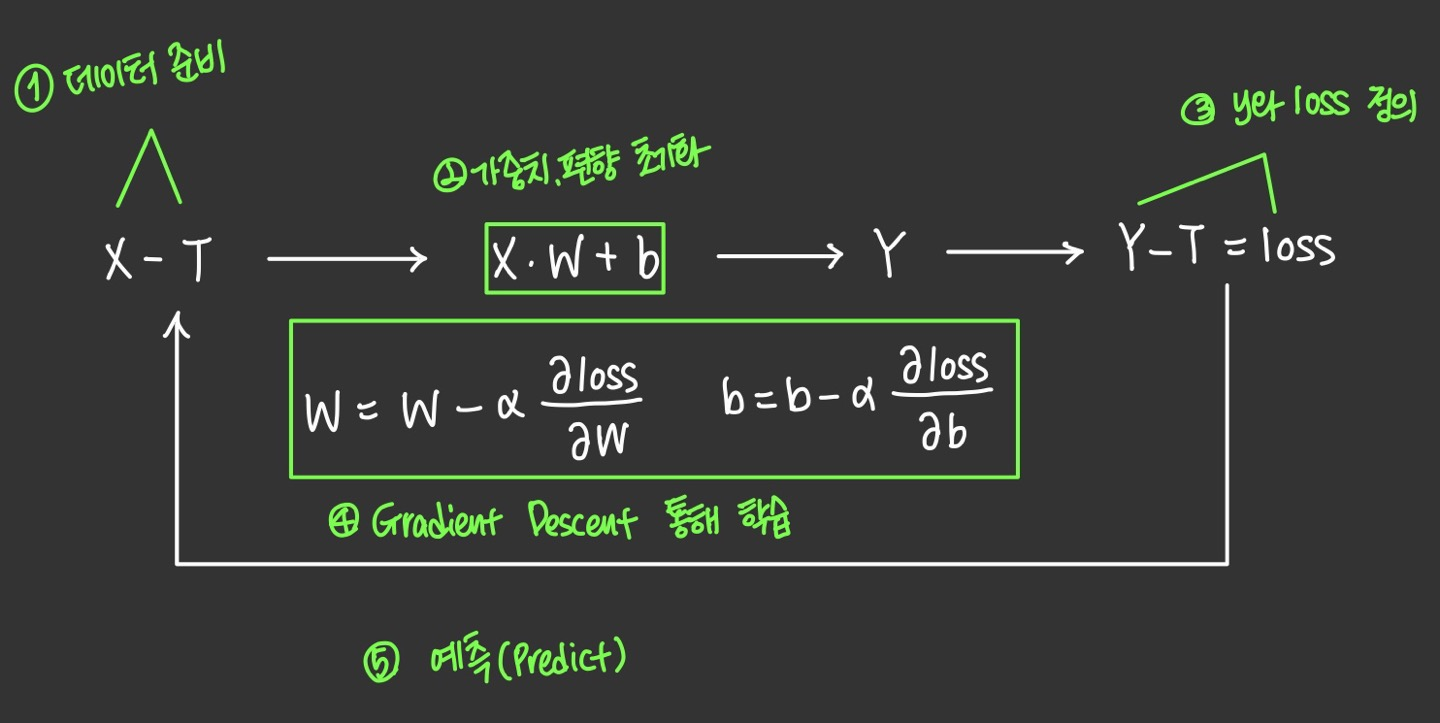
- 데이터 준비(Data Preparation)
1.1 데이터 전처리 (Data Preprocess) - 가중치, 편향 초기화(Initialize weights and bias)
- 비용 함수, 결과물 y 정의 (define loss function and output y)
- 학습 (learning)
- epochs, steps
- 평가 및 예측 (evaluate and predict)
※ 텐서플로, 케라스와 같은 라이브러리는 위의 5단계를 API를 통해 묶은 딥러닝 프레임워크
