
원래 알던 인덱스를 제외하고 새로운 인덱스를 알아보고자 한다.
R-Tree 인덱스
R-Tree 인덱스는 2차원의 데이터를 저장하는 인덱스이다. R-Tree 인덱스를 구성하는 컬럼의 값은 2차원의 공간 개념 값으로 MySQL 공간 인덱스에 이용된다. 공간 인덱스는 위치 기반의 서비스를 구현할 때 주로 사용되며 MySQL의 공간 확장을 이용해 간단하게 구현할 수 있다.
MySQL의 공간 확장에는 크게 세 가지 기능이 포함돼 있다.
- 공간 데이터를 저장할 수 있는 데이터 타입 (POINT, LINE, POLYGON, GEOMETRY)
- 공간 데이터 검색을 위한 공간 인덱스 (R-Tree 알고리즘)
- 공간 데이터의 연산 함수 (ST_Contains(), ST_Within())
구조 및 특성
MySQL은 공간 정보의 저장 및 검색을 위해 POINT, LINE, POLYGON, GEOMETRY라는 여러 가지 기하학적 도형 정보를 관리할 수 있는 데이터 타입을 제공한다.
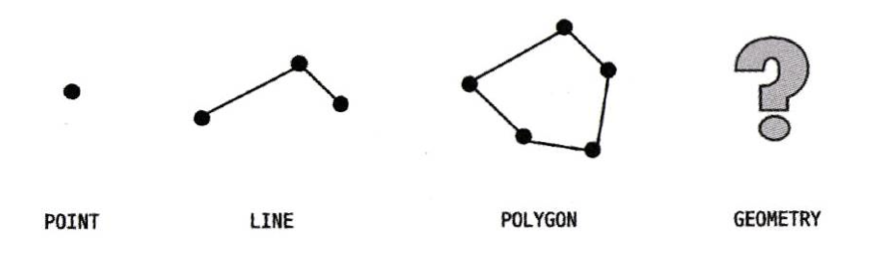
GEOMETRY타입은 나머지 3개 타입의 슈퍼 타입으로, Java의 Object처럼 나머지 모든 객체를 저장할 수 있다. 그리고 R-Tree 알고리즘을 이해하기 위해서 데이터 타입만큼 중요한 개념이 있는데, 바로 MBR이라는 개념이다.
MBR이란?
MBR은 도형을 감싸는 최소 크기의 사각형을 의미한다. 이러한 MBR들의 포함 관계를 B-Tree 형태로 구현한 인덱스가 R-Tree 인덱스다.
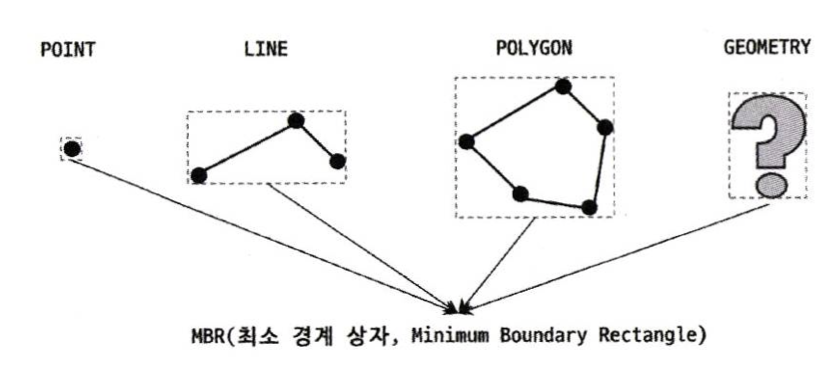
이러한 도형이 저장됐을 때 만들어지는 인덱스 구조를 이해하려면 MBR이 어떻게 되는지 알아야 한다. 예를 들어, 다음과 같은 공간 데이터가 존재한다고 해보자.
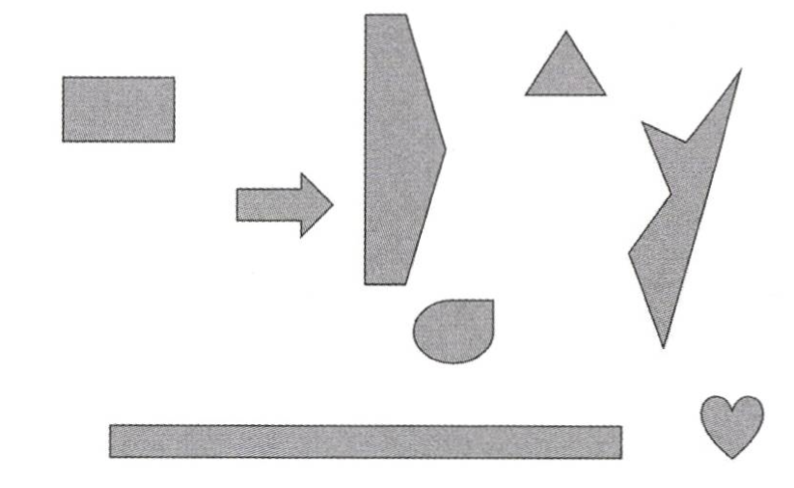
이제 해당 공간 데이터들을 효과적으로 검색하기 위해 인덱스를 만들어야 할 차례다. 이때 사용되는 게 MBR이라는 개념이다. 공간 데이터를 MBR로 그룹화한 모습을 나타내는 그림을 통해 더 자세히 알아보자.
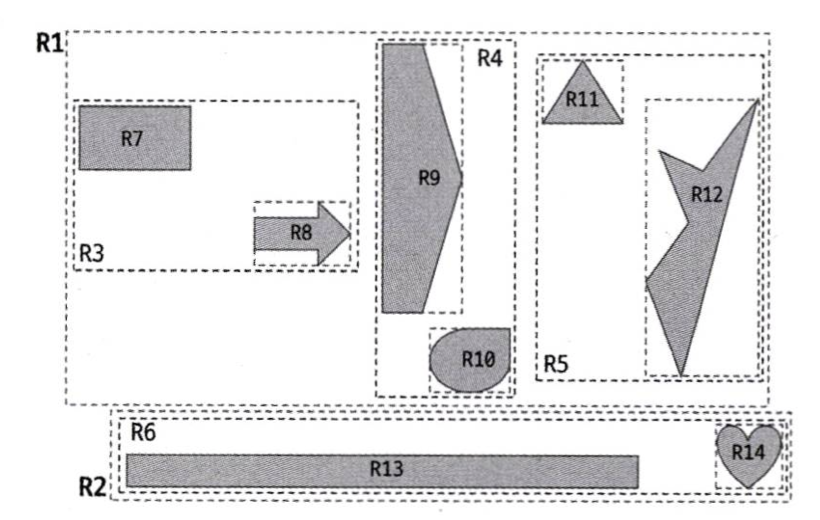
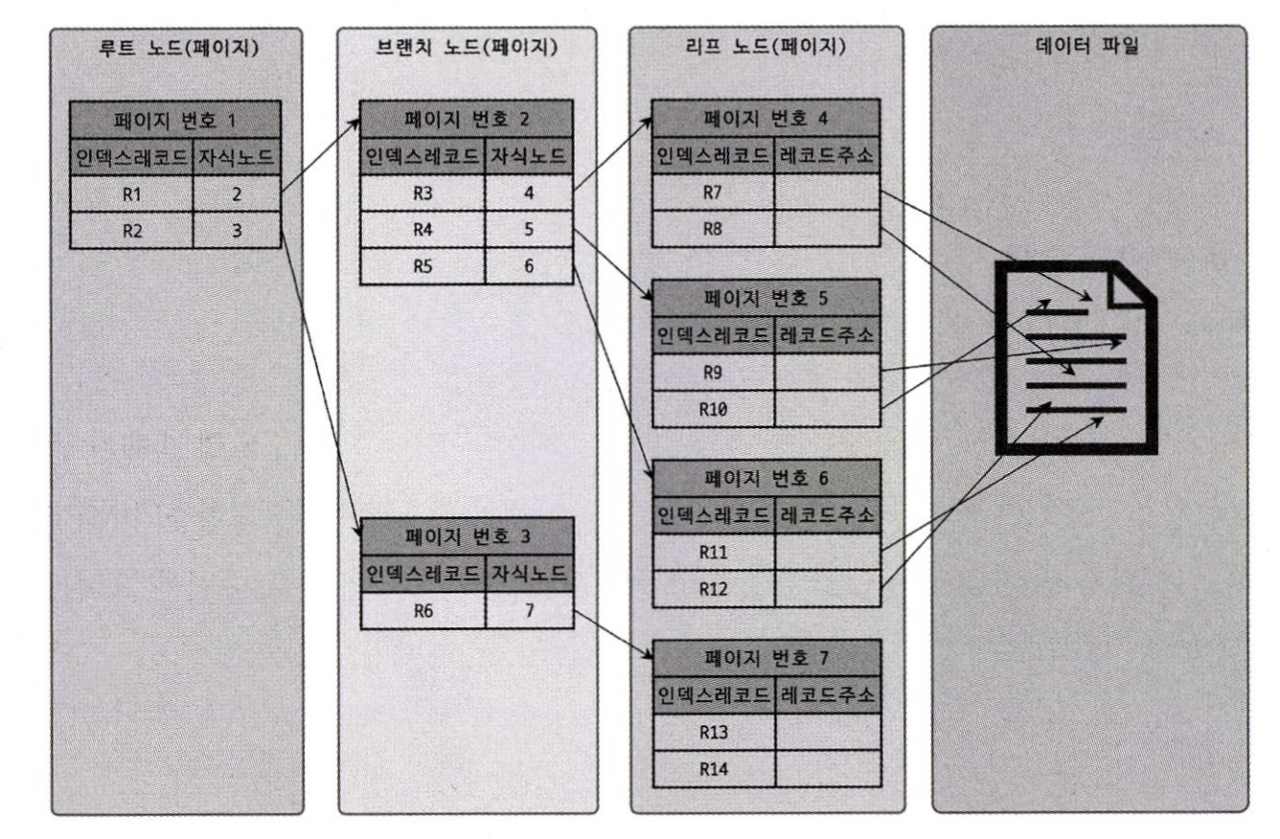
데이터들은 MBR로 둘러싸여 있고 이 MBR들을 그룹화한 차상위 레벨의 MBR이 존재한다. 그리고 차상위 레벨 그룹을 둘러싼 MBR이 최상위 레벨의 MBR이 된다.
- 최상위 레벨: R1 ~ R2
- 차상위 레벨: R3 ~ R6
- 최하위 레벨: R7 ~ R14
이렇듯 공간을 MBR 그룹으로 나눔으로써 해당 공간 데이터를 찾아 들어갈 수 있는 인덱스의 형태가 만들어진다.
최상위 MBR은 루트 노드에 저장되는 정보이며, 차상위 그룹 MBR은 브랜치 노드가 된다.
마지막으로 각 도형의 객체는 리프 노드에 저장되므로 R-Tree 인덱스의 내부를 표현할 수 있게 된다.
그럼 R-Tree 인덱스를 어디서 사용할까?
R-Tree 인덱스는 좌표 시스템에 기반을 둔 정보에 대해 모두 적용할 수 있는 인덱스이다. 따라서 위도, 경도 좌표 저장에 주로 사용된다.
앞서 살펴봤듯, R-Tree는 MBR의 포함 관계를 이용해 만들어진 인덱스다. 그렇기 때문에 ST_Contains() 또는 ST_Within() 등과 같은 포함 관계를 비교하는 함수로 검색을 수행하는 경우에만 인덱스를 사용할 수 있다.
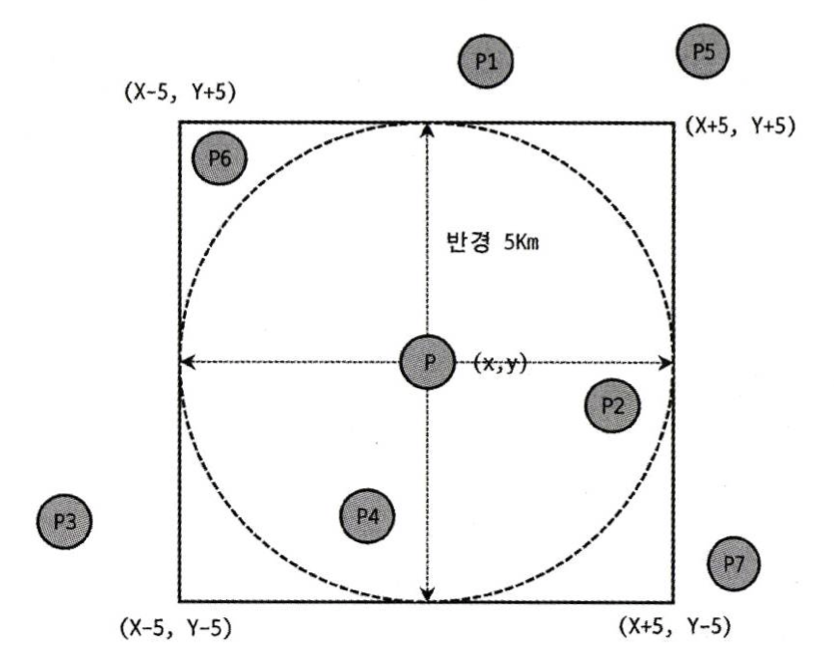
// 사각 상자에 포함된 좌표 px를 검색
SELECT * FROM tb_location WHERE ST_Contains(사각 상자, px);
→ result: P6, P4, P2// 사각 상자 이내에 속해있는 좌표 px를 검색
SELECT * FROM tb_location WHERE ST_Within(px, 사각 상자);
→ result: P6, P4, P2// 공간 좌표 Px가 사각 상자에 포함되고 반경 5Km보다 작은 지점에 속해있는 좌표 검색
SELECT * FROM tb一location WHERE ST_Contains(사각상자, px)
AND ST_Distance_Sphere(p, px)<=5x1000 ; // 5km
→ result: P4, P2
전문 검색 인덱스
Full Text search 인덱스란 문서의 내용 전체를 인덱스화해서 특정 키워드가 포함된 문서를 검색할 수 있도록 하는 인덱스 알고리즘을 말한다.
기존에 살펴봤던 인덱스는 일반적으로 크지 않은 데이터 또는 이미 키워드화한 작은 값에 대한 인덱싱 알고리즘이었다. 또한 전체 일치 또는 좌측 일부 일치와 같은 검색만 가능하다는 제약이 있어 전문 검색 인덱스로는 사용할 수 없다.
전문 검색의 인덱스 알고리즘
전문 검색 인덱스는 문서의 키워드를 인덱싱하는 기법에 따라 크게 단어의 어근 분석과 n-gram 분석 알고리즘으로 구분할 수 있다.
어근 분석 알고리즘
불용어 처리와 어근 분석, 이렇게 두 가지 과정을 거쳐 색인 작업이 수행된다.
불용어 처리
- 검색에서 가치 없는 단어를 모두 필터링해 제거하는 작업
- 상수로 정의해서 사용하는 경우가 많고 사용자가 별도로 정의해 사용할 수도 있다.
어근 분석
- 검색어로 선정된 단어의 뿌리인 원형을 찾는 작업
- 한글은 문장의 형태소를 분석해 명사와 조사를 구분하는 기능이 중요
어근 분석 알고리즘은 매우 전문적인 전문 검색 알고리즘이기 때문에 문장을 해체해서 각 단어의 품사를 식별할 수 있는 문장 구조 인식이 필요하다. 따라서 실제 언어 샘플을 이용해 언어를 학습하는 과정이 필요하고, 완성도를 갖추는 작업은 많은 시간과 노력이 필요하다.
n-gram 알고리즘
어근분석 알고리즘은 많은 시간과 노력이 필요한 만큼 범용성이 떨어진다. 따라서 이런 단점을 보완하기 위해 n-gram 알고리즘이 도입됐다. 전문적인 검색 엔진 도입을 고려하는 것이 아니라면 더 범용적인 n-gram 알고리즘을 사용하면 된다.
n-gram 알고리즘은 본문을 n개씩 잘라서 인덱싱하는 방법이다. 본문을 n개로 잘라 토큰을 생성하므로 인덱스의 크기는 상당히 큰 편이다. 일반적으로 2-gram(Bi-gram) 방식이 많이 사용된다.
2-gram 방식
To be or not to be. That is the question 와 같은 문장이 있을 때, 2-gram 토큰으로 만들어보면 아래와 같다.
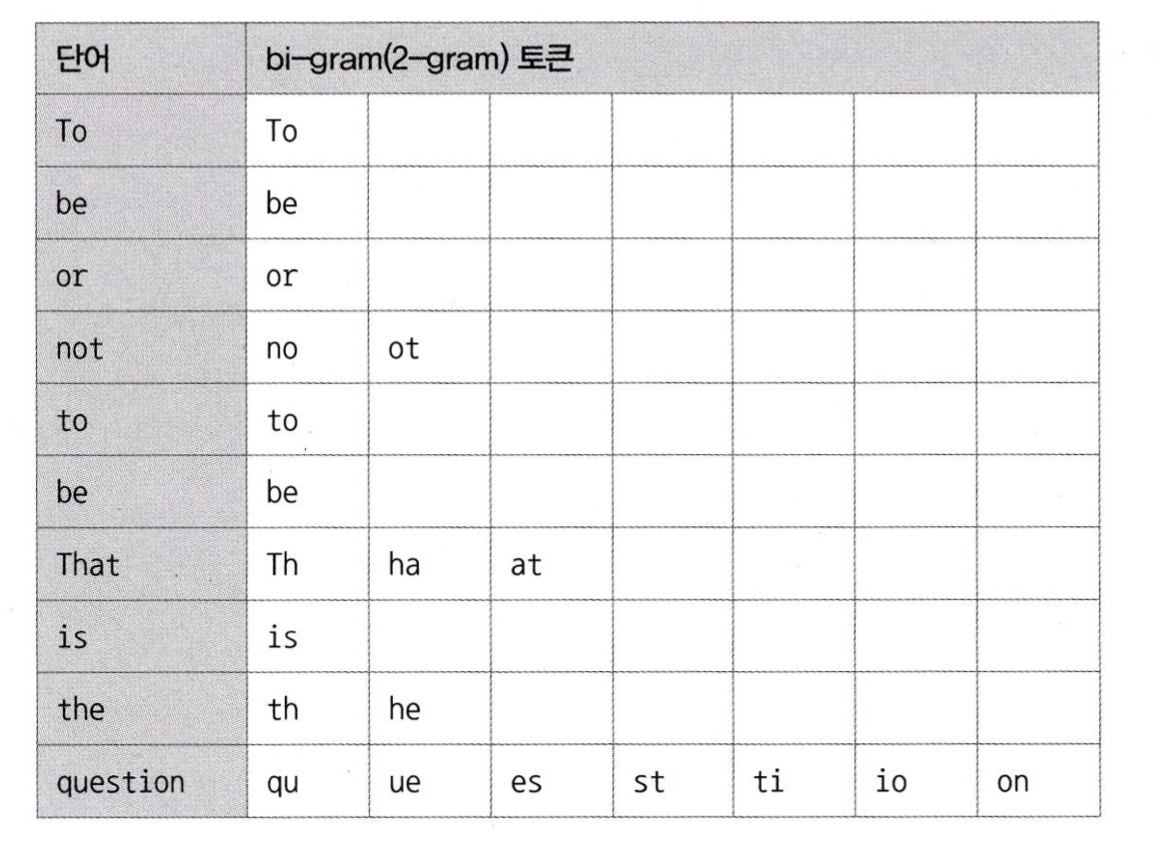
MySQL서버는 이렇게 생성된 토큰에 대해 불용어를 걸러내는 작업을 수행한다. 그리고 구분된 토큰들을 B-Tree 인덱스에 저장한다.
전문 검색 인덱스를 사용하려면?
아래와 같은 두가지 조건을 갖춰야한다.
- 전문 검색을 위한 문법(MATCH …… AGAINST …..)
- 테이블이 전문 검색 대상 컬럼에 대해 전문 인덱스를 보유해야한다.
예를 들어 아래와 같이 전문 검색 인덱스를 생성해줘야만 전문 검색을 사용할 수 있는데,
Create TABLE tb_test (
doc_id INT,
doc_body TEXT,
PRIMARY KEY (doc_id),
FULLTEXT KEY fx_docbody (doc_body) WITH PARSER ngram
// doc_body 컬럼에 전문 검색 인덱스 생성
) ENGINE=InnoDB;이런 식으로 전문 검색 인덱스를 생성하면 아래 처럼 검색해줄 수 있다.
SELECT *
FROM tb_test
WHERE MATCH(doc_body) AGAINST('애플' IN BOOLEAN MODE);여기서 전문 검색 인덱스를 구성하는 컬럼들은 MATCH절 괄호 안에 모두 명시되어 있어야한다.
