
IN-IT프로젝트에 좋아요와 같은 기능을 추가하고자 고민을 하다가 Redis를 사용하게 되었다.
실은 사용하게 되었다 라기 보단.. 사용해보고 싶었다!
안해봤으니까 새로운건 (조금 빡쳐두) 재밌으니까!

Redis를 왜 사용해보고 싶었냐면,
1. 캐싱서버를 이용해 데이터를 저장해보고 싶었다. (굳이 db를 여러 종류로 쓰면서 까지 효율적인가 궁금했었다)
2. 흔히 쓰는 mysql과는 다른 저장방식이라 궁금했다.
등등 여러 이유가 있었다.
일단 사용하기 위해선 Redis가 무엇인지 정확히 아는 것이 중요하다고 생각했다.
Redis 란?
Redis는 in-memory 데이터 구조 저장소이며, 매우 빠른 속도가 높은성능을 제고아고, 다른 데이터 베이스와 비교하여 더 적은 리소스를 사용하는 장점을 지닌다.
Redis는 문자열, 해시, 목록, 집합, 정렬된 집합 등 다양한 데이터 형식을 지원하기 때문에 따라서, 다양한 언어와 프레임워크에서 사용할 수 있다.
마지막으로 Redis는 다양한 용도로 사용할 수 있다. 예를 들어, Redis는 세션 저장소로 사용될 수 있으며, 대용량 데이터를 처리하는 데 사용될 수 있다. Redis는 또한 데이터베이스, 캐시 및 메시지 브로커로 사용될 수 있으며, 다른 용도로도 사용할 수 있다.
→ 한마디로, 동전지갑 같은 느낌? 간단한데, 이것저것 다 담을수 있고, 여기저기 쓰이는 그런 것으로 보인다.
캐싱전략
redis에는 다양한 캐싱전략이 존재한다.
이 전략들의 특징을 알고, 적절하게 써야 프로젝트의 퍼포먼스를 전반적으로 향상시킬 수 있다.
참고한 사이트 ⬇️
1. https://www.alibabacloud.com/blog/struggling-with-poor-responsiveness-unlock-the-power-of-caching_596214
2. https://www.codepedia.org/vladmihalcea/a-beginners-guide-to-cache-synchronization-strategies/
Cache-Aside (lazy-loading)
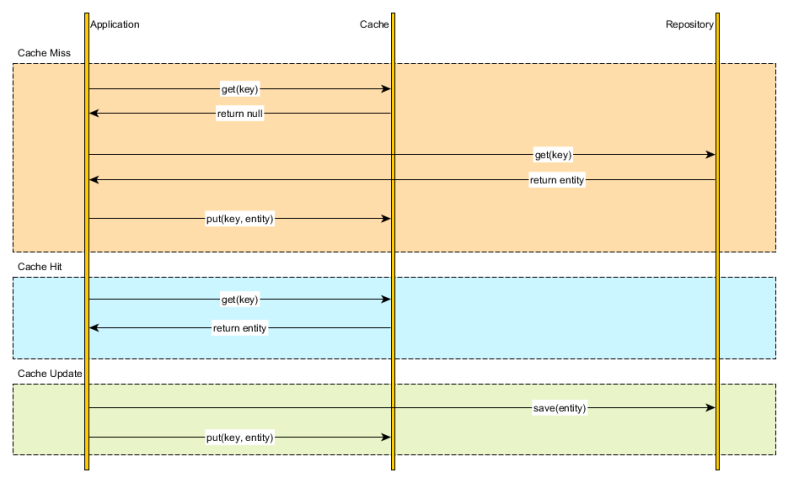
- 캐시와 db는 완전 분리된 상태
따라서, 캐시가 다운될 경우, db에서 가져올 수 있어 캐시 장애 대비 구성 되어있음. - 캐시miss가 생길 경우, db에서 데이터를 가져와서 cache에 넣어놓는다.
따라서, 캐시 miss가 많으면, db connection이 많아져, 부하가 많이 생길 수 있다. - 단건 호출 빈도가 높은 서비스보다는 반복적으로 동일 쿼리를 수행하는 서비스에 적합하다.
- 처음 캐시에 아무 데이터가 없기 때문에 cache warming 작업을 통해 db에서 미리 동기화해주는 방법을 사용하기도 한다.
- 캐시와 db가 적절하게 동기화 되어있는 지 체크해주는 게 관건!
Read-Through
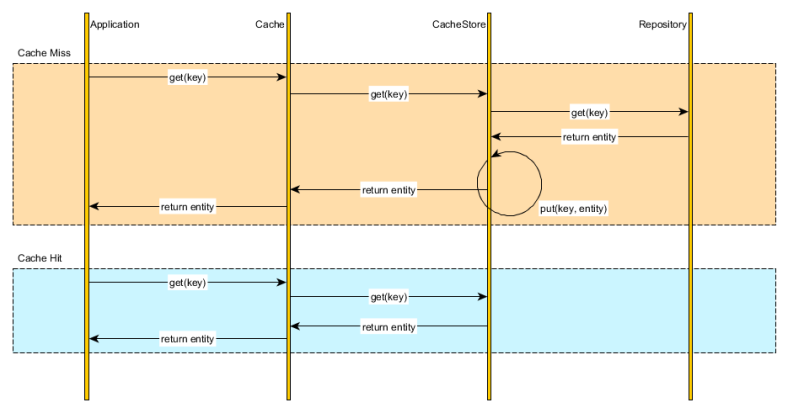
- 캐시가 메인 저장소
- 캐시miss가 발생하면, db에서 불러와서 캐시에 동기화 시킨 후, 캐시가 data를 보내준다.
따라서, 캐시와 db의 정합성문제는 큰 고려대상이 아니다. - 캐시로만 호출이 가능하기 때문에, 캐시가 down되면 상당히 골치가 아프다.
- 이것도 cache warming 작업을 해주는 방법을 사용하기도 한다.
- 캐시 의존도가 높기 때문에, 따로 장애 대안을 생각해두어야한다.
Write-Through
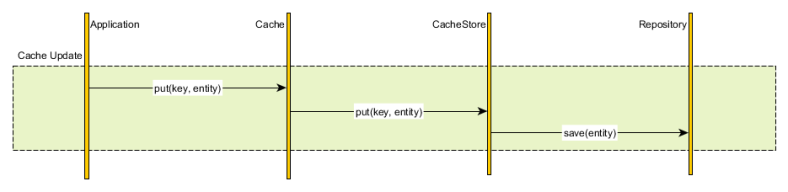
- 데이터 베이스와 cache에 데이터를 동시에 저장 (캐시 → db)
- Read-Through과 마찬가지로 cache가 db동기화 작업을 맡음
- 항상 데이터가 동기화 되어있기 때문에, 데이터를 유실해서는 안되는 상황에 적합하다.
- cache와 db에 총 2번의 write가 계속 발생하게 되어서 성능이슈가 생길 수 있다.
- 자주 사용되지 않는 불필요한 리소스를 저장하는 단점이 있다.
Write-Back (Write-Behind)
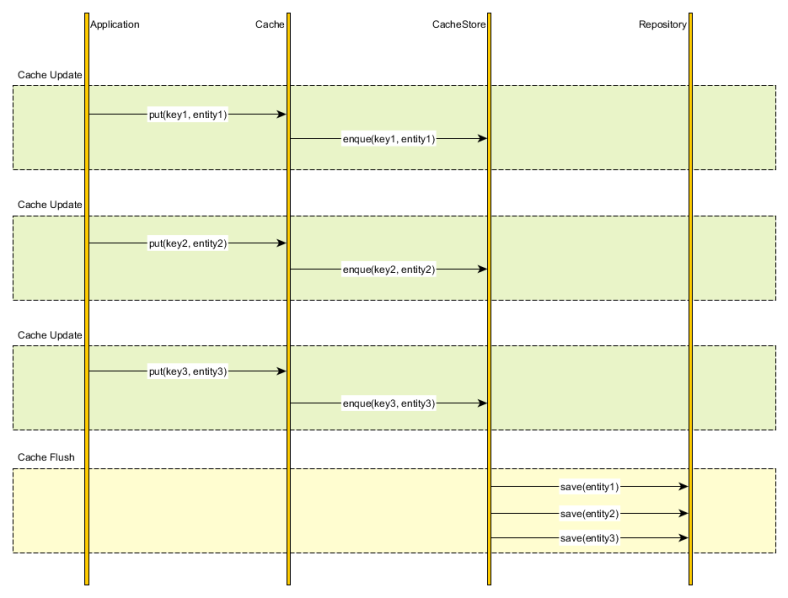
- 캐시와 db를 비동기한다. (스케쥴링 방식으로 한번에 write)
- 일정 주기 배치 작업으로 write 되기 때문에, 쿼리 회수 비용이나 부하를 줄일 수 있다.
- 자주 사용되지 않는 불필요한 리소스를 저장하는 단점이 있다.
- 캐시에서 오류를 발생하면 오류가 영구 소실되는 큰 단점이 존재한다.
Write-Around (추가)

- 모든 데이터를 db에 저장하고, 캐시를 갱신하지 않는 방식
- 캐시 miss 발생하는 경우에만 db와 캐시에 data를 저장한다.
- 따라서 데이터 불일치가 즐비하다.
- 한번 쓰여지고, 잘 읽지 않는 상황에서 자주 사용된다.
캐싱 전략 조합
프로젝트에 사용하기 위해서 여러 캐싱 전략 조합을 생각해보았다.
-
Cache aside + Write around
: 캐시에 요청을 보내고, miss날 경우, db에서 가져온다. write는 db에만 주로 실행되므로, cache 용량의 걱정을 덜 수 있다. -
Read-Through + Write around
: write를 통해 db에 데이터를 저장해두면, 캐시를 통해 읽어올 때, miss가 날 경우 db를 항상 들리므로, 데이터 정합성의 문제를 줄 일 수 있다.
3. Read-Through + Write Through
: 데이터 쓸 때 캐시 → DB / 읽을 때도, 캐시 → DB로 실행방향이 똑같아서, 가장 안정적인 퍼포먼스를 보여준다.
- Read-Through + Write Back
: write 쿼리 회수 비용과 부하를 줄일 수 있고, 성능을 최고로 끌어올릴 수 있는 조합이라고 생각했다.
그 외는, 영구적인 데이터 손실을 우려해서 조합을 생각하지 않았다.
결국 선택한 방법은 3번!!
그 이유는,
일단 좋아요라는 특성이 단순히 보여지는 것 뿐만 아니라, 그 좋아요 순으로 글을 순서화하게 되는 기능이 존재하기 때문에, 데이터 유실이 일어나면 안되고, 또한 데이터 정합성도 중요하다고 판단했기 때문에, 3번을 선택하게 되었다.
어쩌구저쩌구 🗣️

이거 이해하고, 어떤 전략으로 짤지 고민하는 데 엄청 오래 걸렸다.
나름 뿌듯하지만.. 너무 졸렸다는...ㅠ
이제 코드 작성해야한다.
실은 지금 코드는 어느정도 짜여있는데, 너무 많이 다듬어야해서 거의 새로 짜는 급.. 헤헤
어쨋든 마무리 잘해봐야겠다.
