
이 글은 우아콘2020 QueryDSL 영상을 보고 작성한 글입니당🙂
SELECT 개선하기
SQL에서 exists를 사용할 경우 해당 조건을 찾으면 바로 쿼리가 종료되고 데이터를 반환하지만, QueryDSL에서의 exists는 count메서드를 사용하기 때문에, 끝까지 돌게 된다.
→ 그렇기 때문에 찾으면 바로 종료하는 쿼리를 만들어 사용해야 성능적으로 훨씬 이득이다.
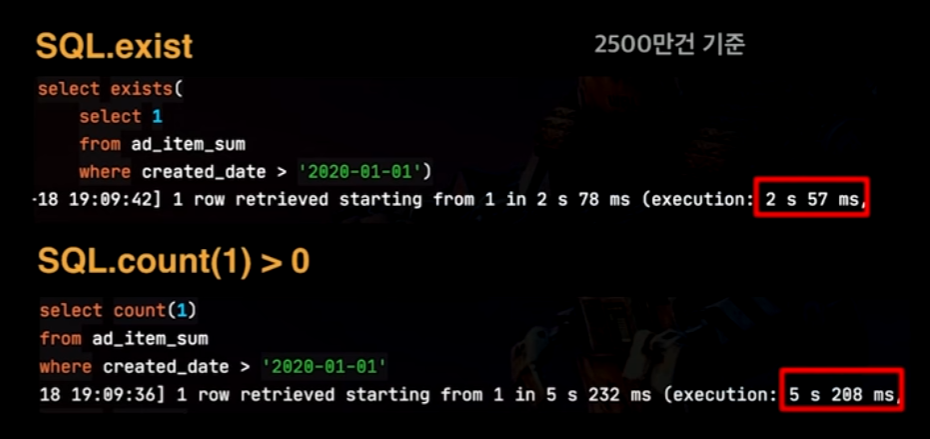
→ count는 끝까지 확인하기 때문에 실행속도가 차이가 난다.
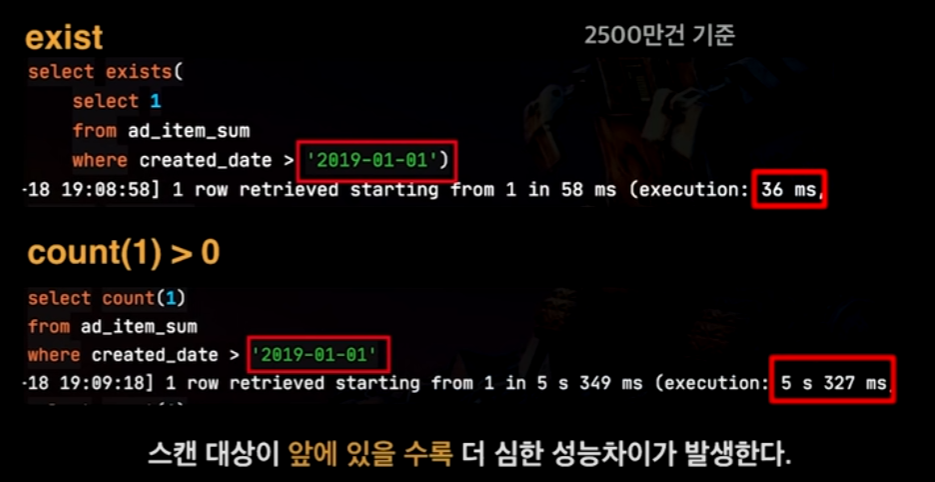
→ exists가 스캔하는 대상이 앞에 있을 수록 count(1)과는 엄청난 시간 차이를 가지게 된다.
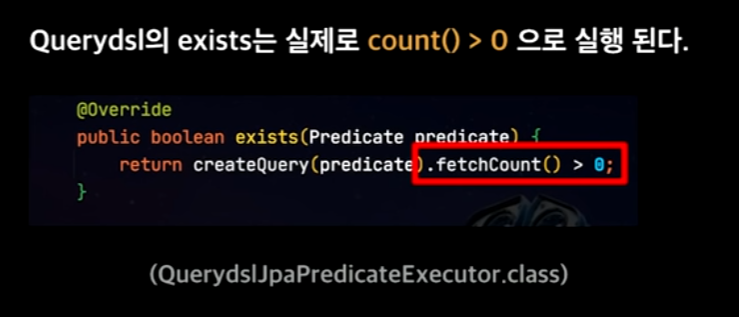
→ 아쉽게도 QueryDSL에서는 count()를 사용해서 exist를 구현하게 되므로, 성능이 굉장히 느리다.
∴ 따라서, SQL.exists 처럼 실행되도록 새로 구현을 해서 사용하는 것이 좋다.
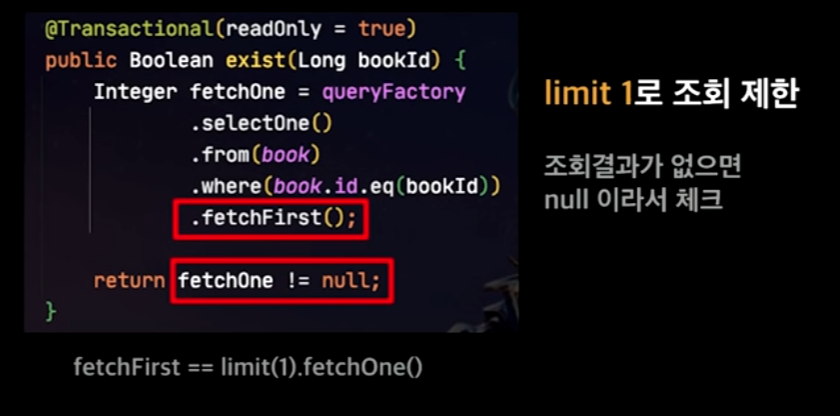
위 처럼 구현하게 되면, 첫번째 결과를 찾으면 바로 쿼리가 종료되므로, SQL.exist와 동일하다.
다만, fetchOne과 null을 비교해줘야한다. 찾는 데이터가 없더라도 0이 반환되는 것이 아니라 null이 반환되기 때문!!
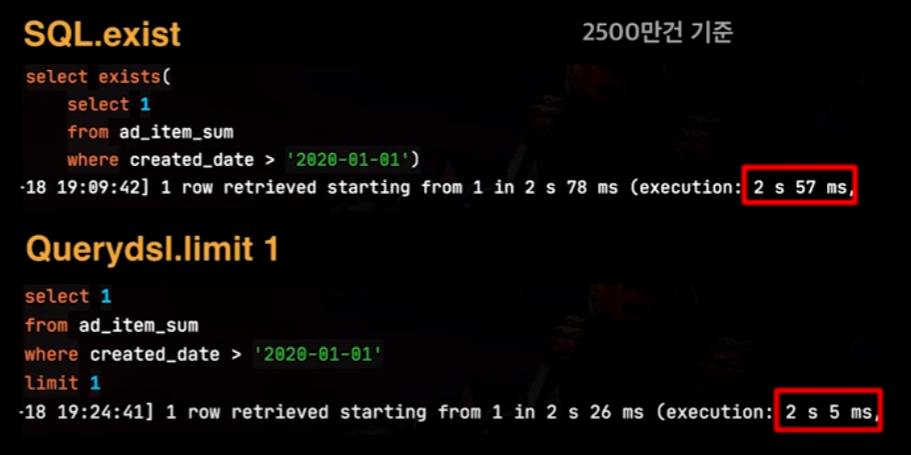
이렇게 되면 위와 같이 시간이 훨씬 줄어드는 것을 볼 수 있다.
Cross Join 회피
JPA나 QueryDSL을 사용하다보면 묵시적으로 Join을 하다보면 where절이나 이런데서 cross join으로 나가는 것을 발견할 수 있다.
(Hibernate 이슈라서 Spring Data JPA에서도 발견됨)
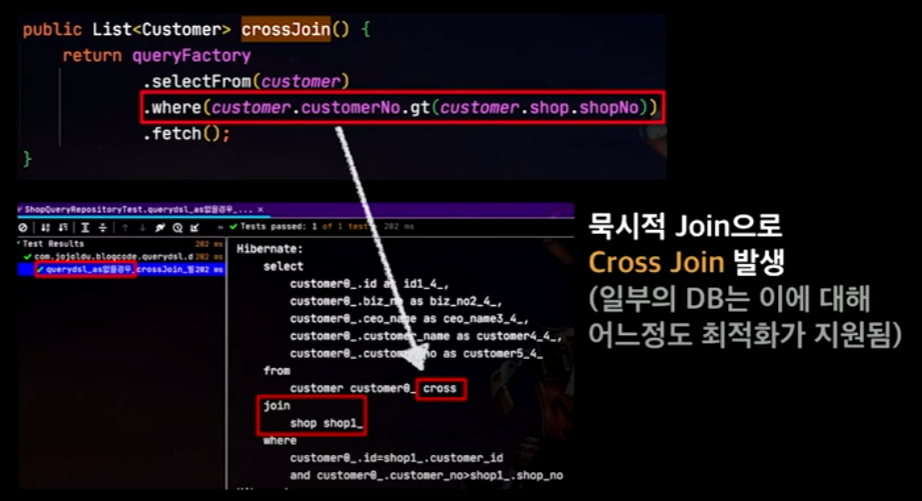
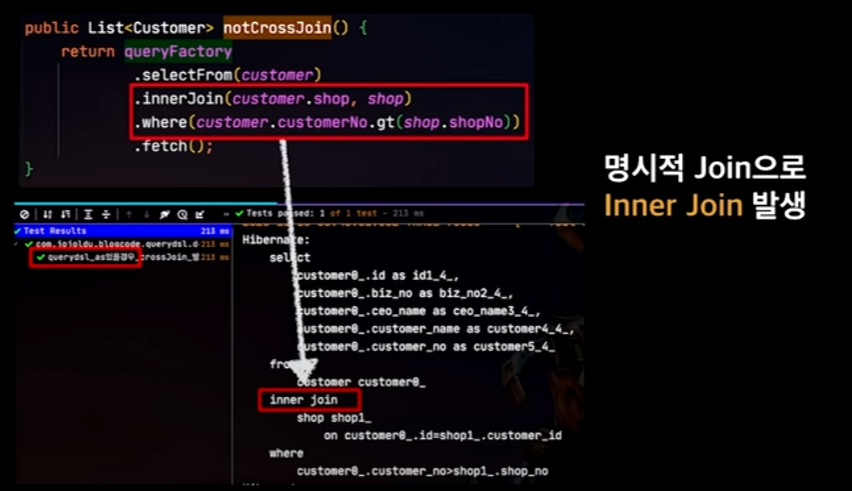
→ 이를 해결하기 위해서는 명시적으로 Join을 해주면 된다. 그렇게 하면 Inner Join이 되기 때문!
Entity 보다는 Dto를 우선
JPA를 쓰다보면 Entity를 써야한다고 오해하는 경우가 많은데, JPA는 그냥 Entity를 쓸 수 있게 해주는 거지.. 써야한다(x)는 아니다.
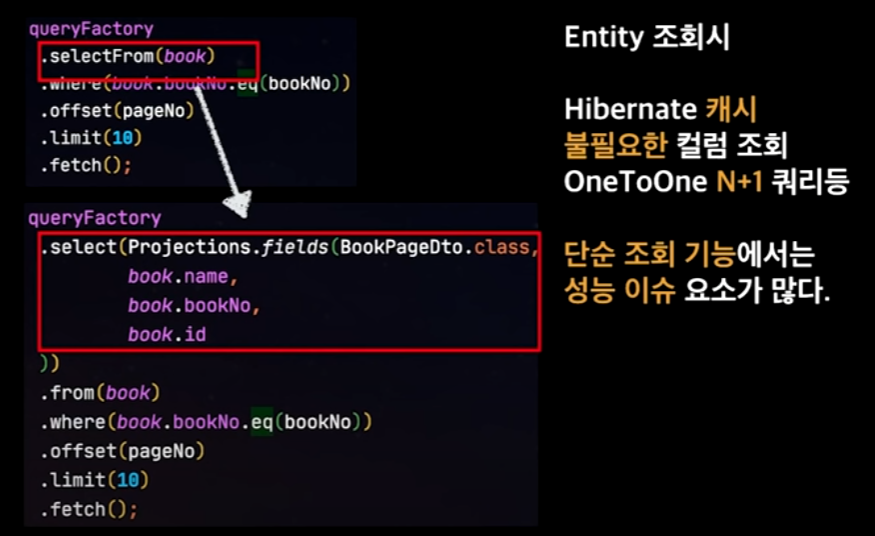
→ Hibernate 1차, 2차 캐시나 OneToOne 관계에서 N+1 쿼리가 생기는 등 불필요한 컬럼이 조회된다고 한다.
그럼 언제 Entity/Dto를 조회해야 하는가?

조회컬럼 최소화하기
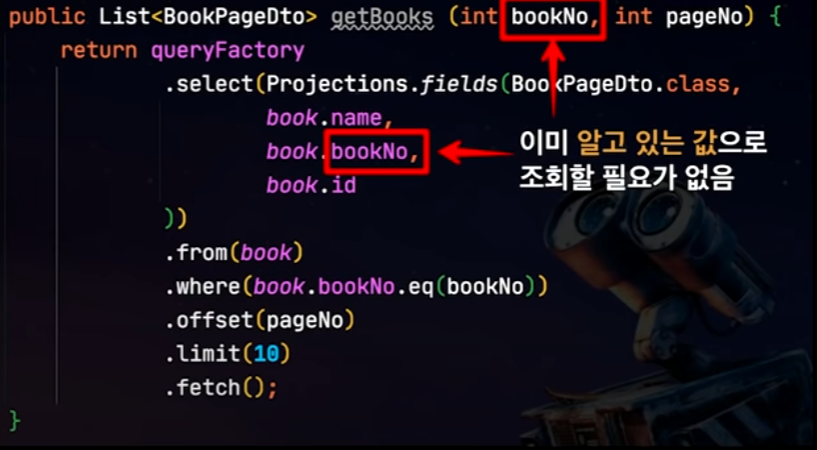
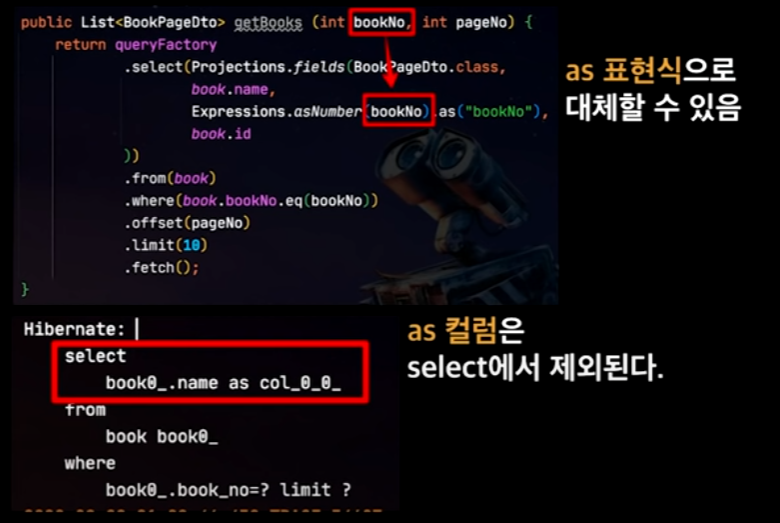
Select 컬럼에 Entity 자제
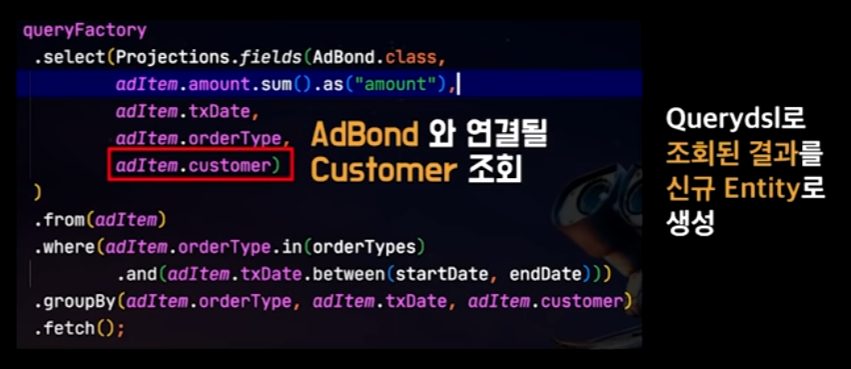
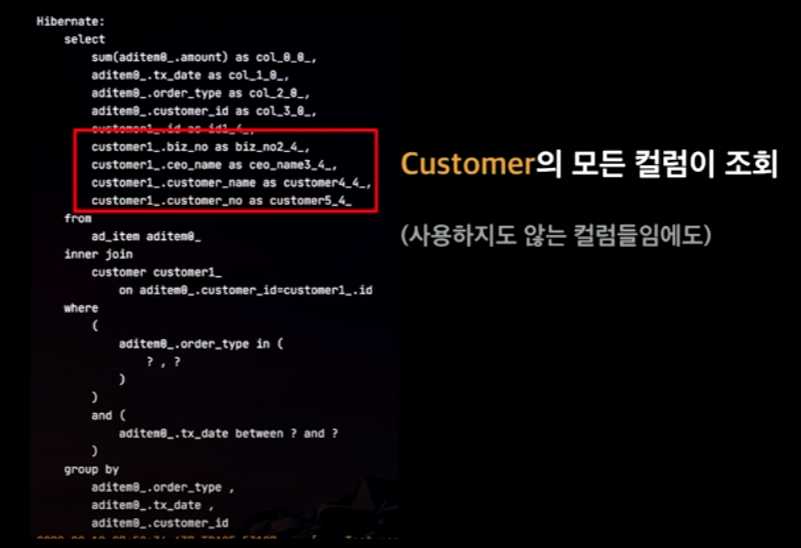
문제1. customer의 모든 컬럼이 조회됨
문제2. OneToOne 관계에서 N+1문제 발생
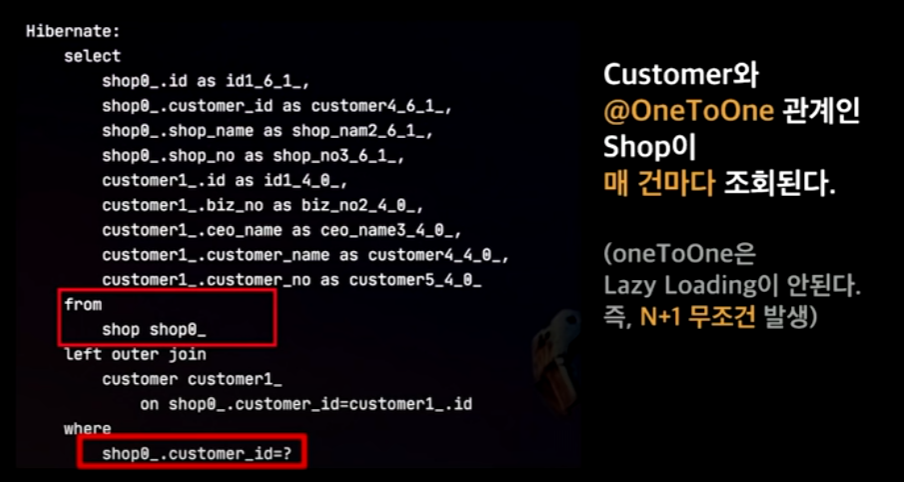
→ 만약 여기서 shop에도 @OneToOne이 있다면.. 100배, 1000배의 쿼리가 수행한다.
그럼 연관된 Entity가 있다면 반대편 Entity도 존재할텐데.. 어떻게 해결을 해야할까?
바로바로, Join column에 들어갈 Entity의 ID만 있으면 된다.
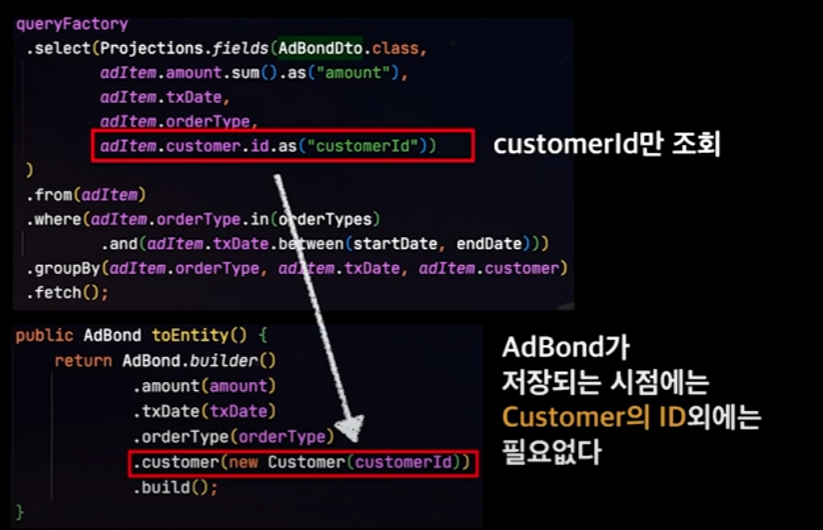
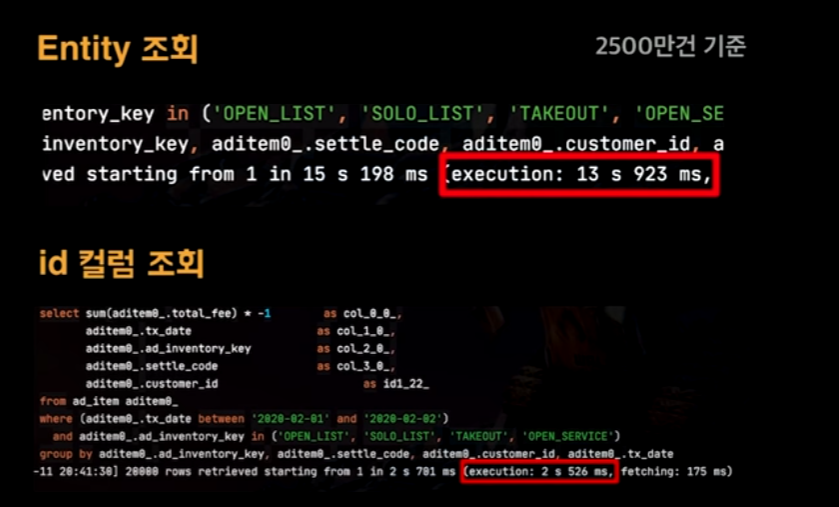
이렇게 되면, 아래와 같은 성능차이를 볼 수 있다.
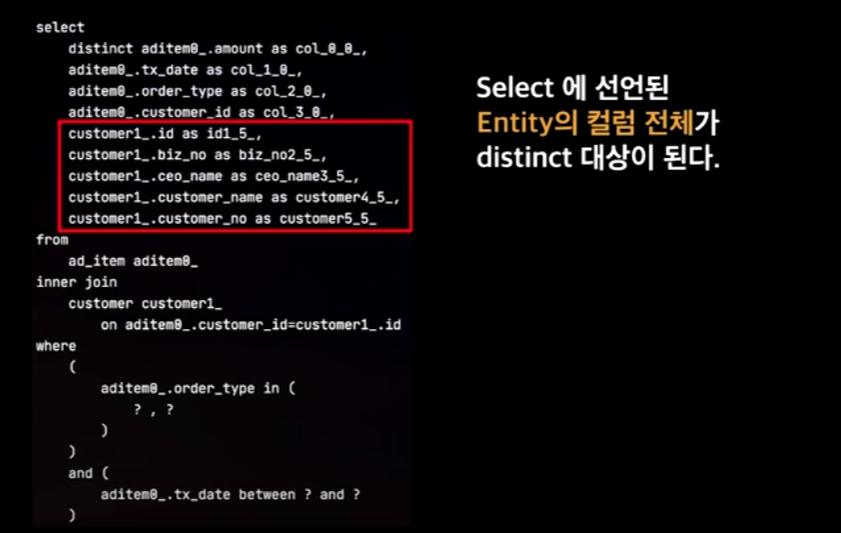
문제3. distinct
Select에 선언된 Entity 컬럼 전체가 distinct의 대상이 되기 때문에, distinct에 필요한 시간/공간 메모리가 추가적으로 필요하게 된다.
→ 성능 저하 ㅠ
Group By 최적화
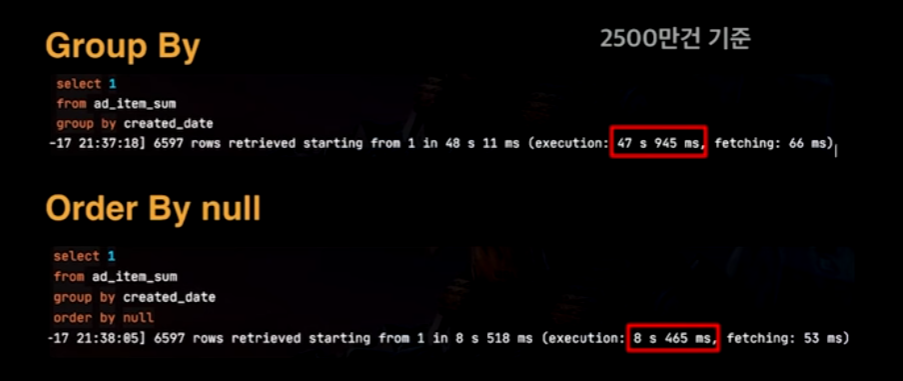
MySQL에서는 Group By를 실행하면 Filesort가 필수로 발생하는데, (Index가 아닌 경우) 이 때, order by null을 수행하면 Filesort가 제거된다.
그러나 QueryDSL에서는 지원하지 않는다.
그래서, 직접 OrderByNull이라는 클래스를 구현해서 적용하는 방법이 있다.
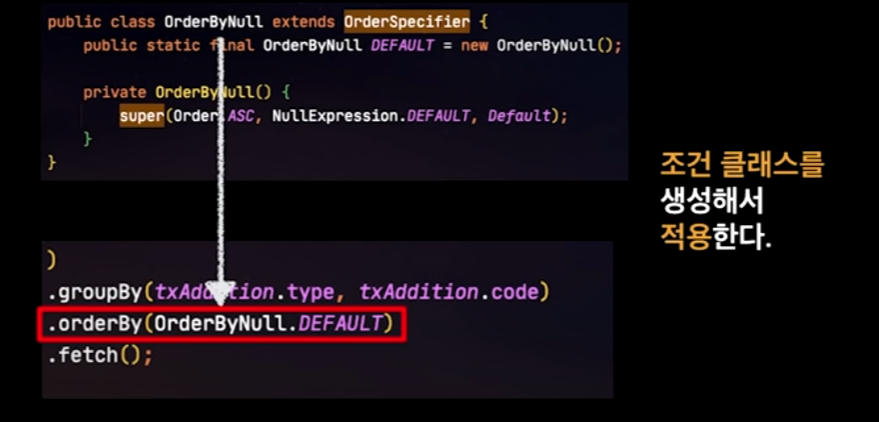
이렇게 하면, 아래와 같은 성능차이가 난다.
추가적으로 성능을 개선한다면, 정렬이 필요하더라도 조회결과가 100건 이하라면 애플리케이션에서 정렬해야하는 것이 좋다.
다만!! 페이징이라면 order by null을 사용하지 못한다.


2개의 댓글

Querydsl로 하나의 데이터만 검색할 때 별 생각 없이 fetchFirst()를 사용한 적이 있는데 exsit()와 차이가 있었군요
좋은 내용 감사합니다 😃
2 s 57 ms 랑 2 s 5 ms를 비교해보면
전자는 2057ms이고 후자는 2005ms인데 52ms차이면 2%정도 성능 향상이 이뤄진건가요?
아니면 뭔가 제가 계산을 잘못했나요