실제 데이터는 우리가 모델에 편하게 넣을 수 있도록 생기지 않았다. 빈칸, None, NaN 등으로 표시되어 있는 이런 데이터를 그대로 머신러닝 모델에 학습시키면 성능이 엉망이 된다.
https://www.kaggle.com/code/parulpandey/a-guide-to-handling-missing-values-in-python/notebook
결측치의 3가지 종류
- Missing completely at random (MCAR) - 완전 무작위 결측
- 결측값의 발생이 다른 변수와 상관이 없는 경우
ex) 전산오류, 통신문제 등으로 데이터 누락
- Missing at random (MAR) - 무작위 결측
- 결측값의 발생이 특정 변수와 관련이 있으나 얻고자 하는 결과와는 상관이 없는 경우
- Not missing at random (NMAR) - 비무작위 결측
- 결측값 발생이 다른 변수와 상관이 있는 경우
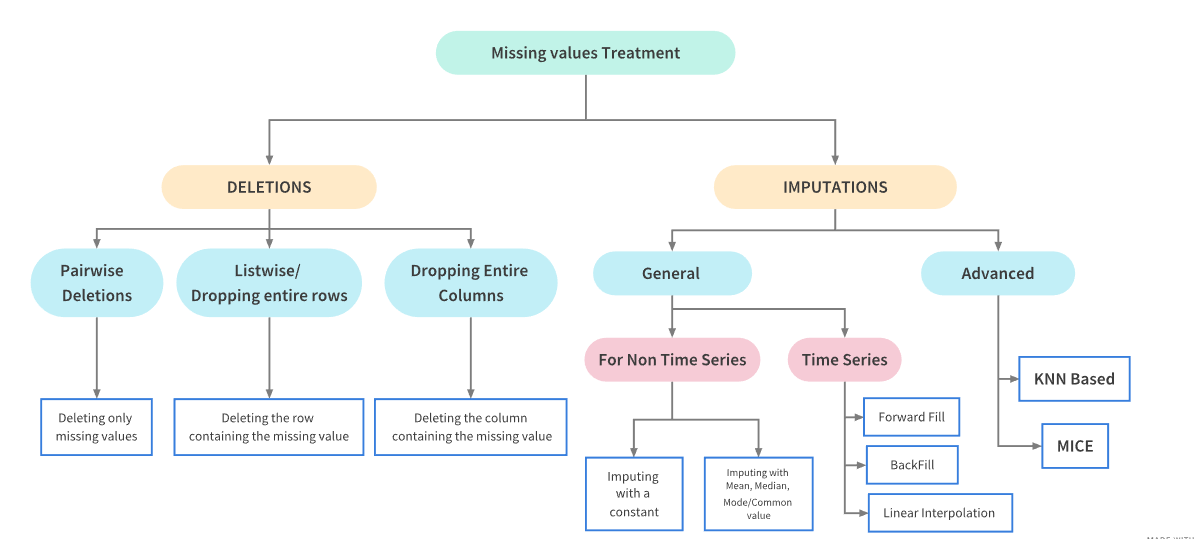
결측치 처리 방법 7가지
1. 아무것도 하지 않기
- 일부 알고리즘은 결측치를 고려해서 학습한다.(xgboost) 결측치를 무시하거나 대체하는 파라미터를 가지고 있는 모델도 있다.
2. 데이터를 제거하기(행 or 열)
- 결측치가 있는 행이나 열 자체를 전체 제거하는 방법이다. 하지만 데이터를 삭제하는 행동 자체가 중요한 정보를 가진 데이터를 잃을 위험이 있다.
- 제거 기준 (가이드라인일 뿐 무조건은 아님!!)
- 10% 미만 : 삭제 or 대치
- 10% ~ 50% : regression or model based imputation
- 50% 이상 : 해당 변수 자체 제거
3. 중앙값, 평균값으로 대체
-
median() 이나 mean()를 사용해서 대체하는 방법
-
단점
- 다른 feature간의 상관관계 고려X
- 절대 범주형 데이터엔 사용 X
4. 최빈값, 0, 상수값으로 대체
-
범주형 데이터에도 가능하다
-
단점
- 다른 feature간의 상관관계 고려 X
- 상수값(-1,-9999,9999)에 따라 데이터에 이상치가 될 수 있다.
5. K-NN 대체
- K-Nearest Neighbor 알고리즘을 사용해 가장 근접한 데이터를 k개 찾는 방식
from impyute.imputation.cs import fast_knn
# KNN 학습
np_imputed = fast_knn(df.values, k=5)
df_imputed = pd.DataFrame(np_imputed)-
KDTree를 생성한 후 가장 가까운 이웃을 찾는다. K개의 NN을 찾은 뒤에 거리에 따라 가중 평균을 취한다
-
장점 : 평균, 중앙값보다 정확한 경우가 있다.
-
단점 : 이상치에 민감
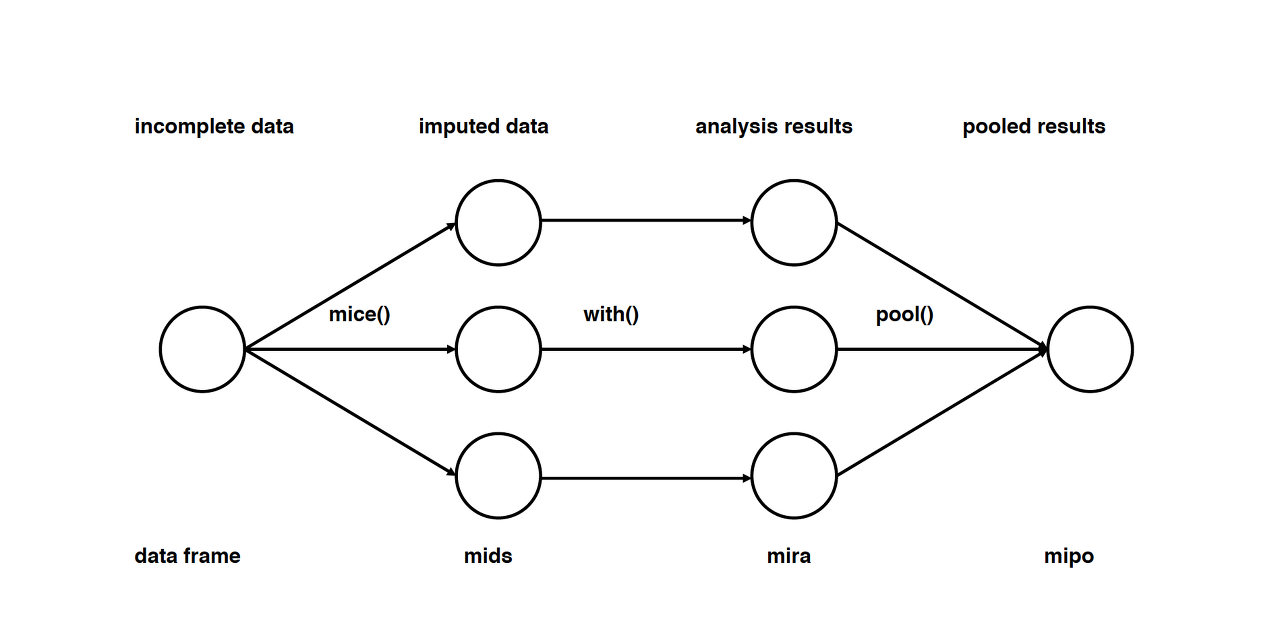
6. MICE(Multivariate Imputation by Chained Equation)
-
누락된 데이터를 여러번 채우는 방식으로 여러 결측치 대치 세트를 만들어 with함수로 특정 통계모델링을 수행하고 pool함수로 생성한 m개의 대치세트를 평균하여 결과를 도출한다. 연속형, 이진형, 범위형 패턴도 처리할 수 있다.
-
imputation : distribution을 토대로 m개의 데이터셋을 imputation
-
Analysis : m개의 완성된 데이터셋을 분석
-
Pooling : 평균, 분산, 신뢰 구간을 계산하여 결과를 종합
from impyute.imputation.cs import mice
# MICE 학습
np_imputed=mice(df.values)
df_imputed = pd.DataFrame(np_immputed)7. 딥러닝을 이용한 Imputation
- 범주형이나 숫자가 아닌 자료형에 효과적이다. DNN을 이용해서 누락된 값을 유추하는 방법
import datawig
imputer = datawig.SimpleImputer(
input_columns = ['X_1', 'X_2', 'X_3'], # impute에 사용할 col 지정
output_column = 'X_5') # 컬럼 X_5의 결측치를 채운다
imputer.fit(train_df=df_null, num_epochs=50)
df_null_only = df_null[df_null['X_5'].isnull()]
np_imputed = imputer.predict(df_null_only)
df_imputed = pd.DataFrame(np_imputed)
AI/Data Science