최근 회사에서 LLM프로젝트를 담당하고있고, 기간이 넉넉치 않아서 머리싸메며 공부하면서 작업을 하고 있었는데
마침! 관련된 세미나가 있어서 다녀왔다.
(나에게 너무 필요해 ㅠㅠ)

-
책 한권을 다 놓고 돌렸을때 gpt 3.5로는 3달러, 4o mini로는 0.4달러(...?)였다고 한다.. 너무신기.. (구현에만 치우쳐서 가격을 몰랐는데 생각보다 저렴한걸..?)
-
api들 쓰면 다들 말 안듣는건 같구나..
-
가끔 코드를 llm에게 예시코드를 받기위해서 물어보면, 예전코드를 줄 때가 있다.
이때는, https://aistudio.google.com/prompts/new_chat 이와같은 사이트에 있는 코드 예제를 던져서 해당 버전으로 해달라고 하면 훨씬 최신의 정보를 얻을 수 있다. -
크롤링코드 요청시, 응답, 헤더 등의 다양한 소스를 주고 요청을 하자.
-
hugging face : 학습시킨 모델을 공유하는 플렛폼
-
데이더셋의 용량이 크다면 hugging에 올려서 사용해보자.
-
hugging에서 한국어지원하는 모델 찾고싶다면..?
다른 한국어 모델 찾아보기 : https://huggingface.co/models?search=korean -
RDBMS(답변 그때그때 저장용) + 벡터DB 를 사용해서 프로젝트를 하셨다고..
-
너무 긴 문단은 langchain chunk spliter이용해보자.
-
한국어 embedding 모델
embeddings = HuggingFaceEmbeddings(model_name="upskyy/e5-small-korean")- vectorDB로 검색하면 정확도는 떨어진다(유사도 검색이기 때문)
- embedding projector에서 유사도 ui보기 쉽다.
https://projector.tensorflow.org
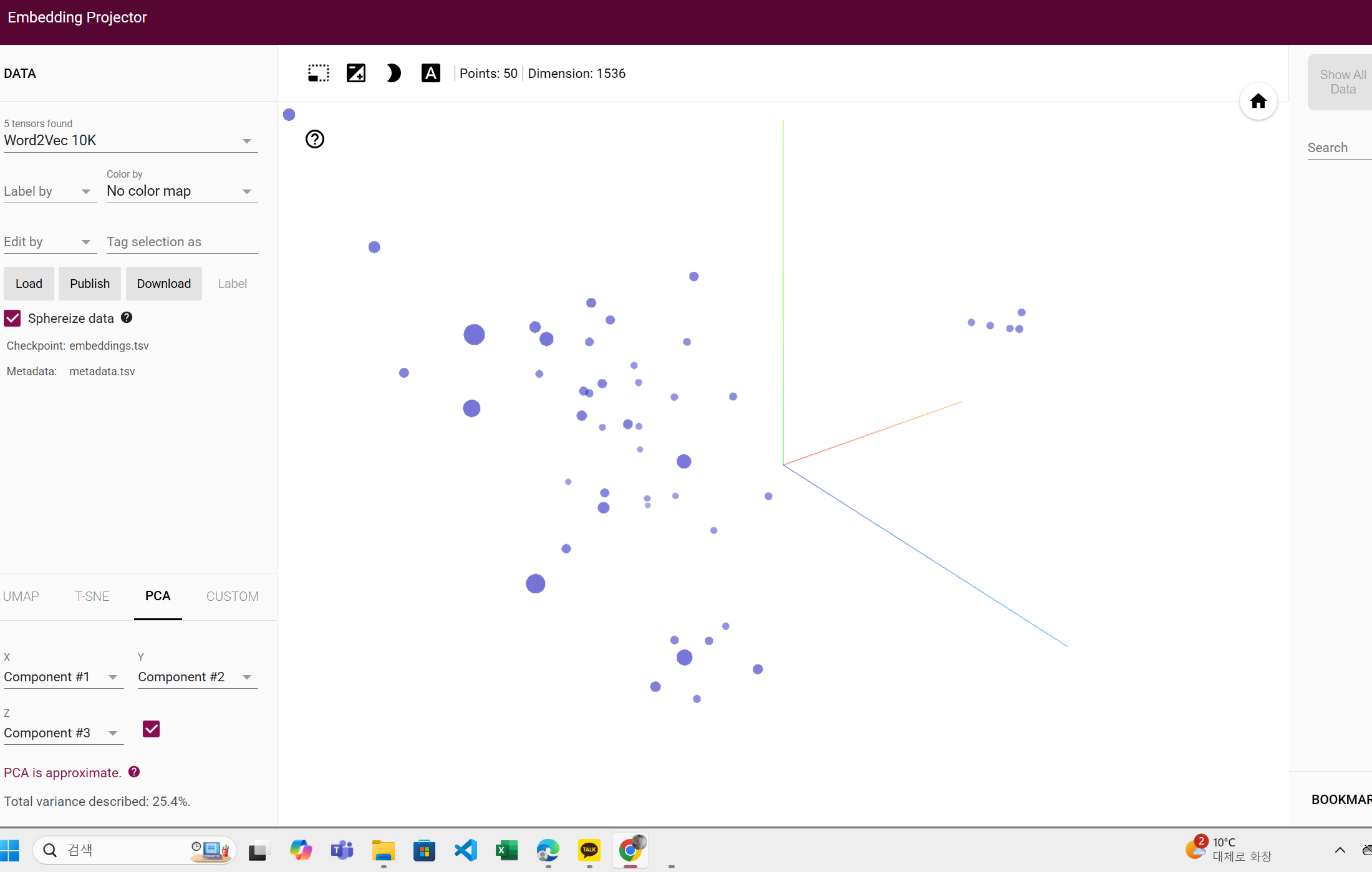
-
벡터화(텍스트 숫자변환)랑 임베딩(의미포함 숫자변환)은 다르구나..
-
임베딩할때 참고하면 좋은 사이트(시각화)
https://damien0x0023.github.io/rnnExplainer/ -
오.. 벡터 토큰화 하는코드 ..
# prompt: texts 내용 tf-idf로 토큰화
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(texts)
# TF-IDF 행렬 출력
print(tfidf_matrix.toarray())
# TF-IDF 어휘 목록 출력
print(tfidf_vectorizer.get_feature_names_out())
[[0. 0. 0. ... 0.46383605 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0.36661165 0. 0. ]
...
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]]
['20달러로' '2판' 'agi의' 'ai' 'ai를' 'api를' 'cs' 'git' 'github' 'gpt' 'llm'
'mysql이다' 'nlp와' 'sql' 'with' '가이드' '가이드북' '개발' '개발을' '개발자' '개발자를' '게임'
'견고한' '고작' '공략집' '공부하는' '과학이다' '구조' '권으로' '그림으로' '글쓰기' '기술' '네트워크' '노트'
'다섯' '대신' '데이터' '도메인' '도커' '디자인' '딥러닝' '라이브러리를' '러스트' '리팩터링' '만렙' '말을'
'매니지먼트' '머신러닝' '면접' '명이' '모두를' '몽고db' '믿어요' '밑바닥부터' '배우는' '분석' '비밀'
'비즈니스' '사토시의' '선형대수학' '소프트웨어' '수학' '시대' '시대의' '시작하기' '시작하는' '실무로' '실전'
'알고리즘이다' '애저' '양자' '어떻게' '언어' '업무' '엑셀' '엔지니어' '엔지니어링' '완벽' '운영체제' '위한'
'이것이' '이다' '이지' '인공지능' '인과추론' '일잘러의' '일타강사의' '자동화하기' '자료구조' '자바' '전문가를'
'제대로' '주도' '직장인' '챗gpt' '챗gpt와' '처음' '첫걸음' '취업을' '컴퓨터' '코딩' '쿠버네티스'
'테스트다' '통하는' '파이썬' '파이썬으로' '패턴' '퍼스트' '프로그래머' '프로그래밍' '프로덕트' '플랫폼' '필수'
'핸즈온' '헤드' '혼자' '활용' '활용한']-
보통 유사도를 검색할때는, cos방식으로 사용한다(거리)방식
-> 사실이게 추천시스템이다. -
차원축소 : 모델압축 및 모델 학습시에 주로 활용됨 (통계기법)
-
임베딩시 차원이 크면 클수록 좋지만, 모델이 계산할때 오래걸린다.
-
임베딩 모델에서 사용하는 모델을 그대로 쓰자~
-
여러문서를 llm에서 쓰고싶다면 notebookllm을 사용하자.
후기
- 그동안 내가 혼자서 했던것들이 영 틀린것은 아니였구나 하고 뿌듯..
- 흥미로운 부분도 새로운 부분도 많았다(특히 통계기법등)
- 정말 궁금한 부분이 사실 들어서 해결되지는 않았지만, 들으면 들을수록 답이 없구나.. 생각이 들었다.
