객체지향 프로그래밍이란?
객체지향 프로그래밍 (Object Oriented Programming, OOP)
컴퓨터 프로그램을 객체(Object) 들의 모임으로 파악하고자 하는 프로그래밍 패러다임 중 하나. 프로그래밍에서 필요한 데이터를 추상화시켜 객체를 만들고, 그 객체들 간의 유기적인 상호작용(메세지를 주고 받으며, 데이터를 처리)을 통해 로직을 구성하는 프로그래밍 방법이다.
객체지향 프로그래밍의 장단점
장점
코드의 재사용성
남이 만든 클래스를 가져와 사용할 수 있고, 상속을 통해 확장하여 사용할 수 있다
유지보수 용이
절차지향 프로그래밍에서는 코드 수정을 위해 일일히 찾아 수정해야하는 반면, 객체지향 프로그래밍에서는 수정해야 할 부분이 클래스 내부의 멤버 변수/메서드로 있기 때문에, 해당 부분만 수정하면 된다.
대형 프로젝트에 적합
클래스 단위로 모듈화시켜 개발할 수 있으므로 업무 분담이 용이하고 대형 프로젝트 개발에 활용이 가능하다
단점
처리 속도가 상대적으로 느림
객체가 많으면 용량이 커질 수 있음
설계 단계에서 많은 시간과 노력이 필요
객체지향 프로그래밍 핵심 개념 5가지
- 클래스, 인스턴스 (객체)
클래스: 객체들이 공통적으로 갖는 속성(attribute)과 행위(behavior)를 모아 변수(field)와 메소드(method)로 정의(추상화)한 것
인스턴스(객체): 클래스에서 정의한 것을 토대로 실제 메모리 상에 할당된 것. 실제 프로그램에서 사용되는 데이터
예를 들어, 사람은 '사람'이라면 갖는 공통점과 차이점이 있다. 김영희, 이철수, Helen, John,.. 이 사람 한 명 한 명을 객체라고 할 수 있으며, 이들(객체)의 공통적인 속성과 행위를 모아 '사람'이라는 큰 틀(클래스)로 정의할 수 있다.
- 추상화 (Abstraction)
목적과 관련이 없는, 불필요한 정보는 숨기고 중요한 정보만을 표현하기 위한 개념.
객체는 실제 그 모습(데이터)이지만, 클래스는 객체들이 어떠한 특징이 있어야 한다고 정의하는 추상화된 개념이다. 즉, 추상화는 객체들의 공통된 속성이나 기능을 파악하여 정의해놓은 설계 기법이라 할 수 있다.
객체지향 관점에서 클래스를 정의하는 방식으로써의 추상화를 말하며, 추상 클래스/메소드(abstract)와는 다른 개념이다.
- 캡슐화 (Encapsulation)
캡슐화의 목적: 1) 정보은닉 2) 코드의 재사용
캡슐화는 기능과 특성의 모음을 클래스라는 캡슐에 분류해서 넣음과 동시에, 객체의 데이터를 외부에서 직접 접근하지 못하게 막고, 메소드를 통해서만 조작이 가능하도록 하는 작업이다. 이를 통해 분산되어 있는 데이터를 한 곳에 모아 재활용을 원활하게 하고, 캡슐화함으로써 불필요하거나 외부에 노출되어서는 안되는 정보를 감추어 클래스 내부에서만 사용하도록 정의할 수 있다. (접근제어자 public, protected, private)
- 상속 (Inheritance)
상속의 목적: 코드의 재사용(코드의 이원화 문제, 중복 제거)
상위(부모)클래스의 속성과 기능을 그대로 이어받아 사용할 수 있게 하고, 기능의 일부분을 변경해야 할 경우 상속받은 하위(자식)클래스에서 해당 기능만 다시 수정(재정의)하여 사용할 수 있게 하는 것이다.
클래스의 상속 관계에 혼란을 줄 수 있기 때문에, 다중 상속은 불가하며, 필요에 따라 인터페이스를 사용할 수 있다.
- 다형성 (Polymorphism)
"형태가 같은데 다른 기능을 하는 것". 즉, 하나의 변수명, 함수명 등이 상황에 따라 다른 의미로 재해석될 수 있는 것을 말한다.
오버로딩(Overloading): 같은 이름의 함수를 여러 개 정의하고, 매개변수의 타입/갯수를 달리하여 매개변수에 따라 다르게 호출할 수 있도록 하는 것
오버라이딩(Overriding): 부모 클래스의 메소드와 같은 이름, 매개변수를 재정의하는 것
getter/setter를 사용하는 이유
멤버변수에 직접 접근하지 못하게 private 접근지정자로 설정하고 getter/setter 메소드를 이용해 이를 불러온다. (정보 은닉)
getter/setter라는 메소드를 통해 접근하기 때문에, 메소드 안에서 매개변수 값이 올바르지 않은 입력에 대해 사전에 처리할 수 있도록 제한/조절할 수 있다.
JVM (Java Virtual Machine)
-
JVM이란 무엇인가
: 설명에 앞서 운영체제는 자바 프로그램을 바로 실행할 수 없다. 자바는 완전한 기계어가 아닌 중간 단계의 바이트코드이기 때문이다. 따라서 이것을 해석하고 실행할 수 있는 가상의 운영체제가 필요하다. 이것이 자바가상기계 JVM(Java Virtual Machine)이다. JVM은 실제의 운영체제를 대신하여 자바 프로그램을 실행하는 **가상의 운영체제 역할**을 한다. 그럼 왜 JVM이 굳이 운영체제를 대신해야 할까? : 답은 **운영체제별로 프로그램을 실행하고 관리하는 방법이 다르기 때문**이라는 이유에 있다. 운영체제별로 자바 프로그램을 별도로 개발하는 것보다는 운영체제와 자바 프로그램을 중계하는 JVM을 두고 어느 운영체제에서든 동일한 결과를 보장받는 자바 프로그램을 개발할 수 있게끔 하는 것이 JVM이 실제 운영체제를 대신하는 이유이다. 바이트코드는 모든 JVM에서 동일한 결과를 보장하지만, **JVM은 OS에 종속(독립)적**이다.- 컴파일 하는 방법
- 자바 프로그램은 .java인 파일을 작성하는 것부터 시작한다.
- 이것을 소스파일이라고 하는데, 이 파일을 컴파일러(javac.exe)로 컴파일 하면 확장자가 .class인 바이트 코드 파일이 생성된다.
- 바이트코드 파일은 JVM 구동 명령어(java.exe)에 의해 JVM의 클래스 로더에 전달되고 클래스 로더는 동적로딩을 통해 필요 클래스들을 Runtime Data Area(JVM의 메모리)에 올린다. (각 명령어는 1바이트 크기의 Opcode와 추가 피연산자로 이루어져있다)
- 클래스 로더의 세부 동작은 어떨까(출처 : https://gyoogle.dev/blog/computer-language/Java/컴파일 과정.html)
- 로드 : 클래스 파일을 가져와서 JVM의 메모리에 로드함.
- 검증 : 자바 언어 명세 && JVM 명세에 맞게 구성됐는지 검사함.
- 준비 : 클래스 필요 메모리 할당함.
- 분석 : 클래스의 상수 풀 내 모든 Symbolic Reference → Direct Reference로 변경함.
- 초기화 : 클래스 변수들을 적절한 값으로 초기화 함.
- 클래스 로더의 세부 동작은 어떨까(출처 : https://gyoogle.dev/blog/computer-language/Java/컴파일 과정.html)
- 실행하는 방법
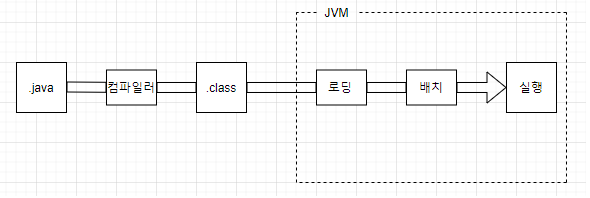 .java 파일 생성 → 컴파일러(javac.exe)가 가상 기계어인 .class파일로 재생성(번역) → JVM이 로딩, 배치를 하여 실행함
.java 파일 생성 → 컴파일러(javac.exe)가 가상 기계어인 .class파일로 재생성(번역) → JVM이 로딩, 배치를 하여 실행함
- 바이트코드란 무엇인가 : JVM이 이해할 수 있는 언어로 변환된 자바 소스 코드를 의미한다. 자바 컴파일러에 의해 변환되는 코드의 명령어 크기가 1바이트라서 자바 바이트코드라고 불린다. 이러한 자바 바이트코드의 확장자는 .class이며 자바 바이트코드는 자바 가상 머신만 설치되어 있으면 어떤 운영체제에서라도 실행될 수 있다.
- JIT 컴파일러란 무엇이며 어떻게 동작하는지 Just-In-Time Compiler : 인터프리터의 단점을 보완하기 위해 도입된 방식으로 바이트코드 전체를 컴파일 하여 네이티브 코드로 변경하고 그 이후에는 해당 메서드를 인터프리팅 하지 않고 네이티브 코드로 직접 실행하는 방식. 하나씩이 아닌 바이트코드 전체가 컴파일된 네이티브 코드를 실행하기 때문에 전체적 실행속도가 인터프리터보다 빠르다.
- JVM 구성 요소

- Class Loader : 클래스 로더는 총 3 단계로 실행된다
- 로딩 : 클래스로더가 바이트코드를 읽으면서 실행을 시작한다.
- 링크 : 클래스간 Reference를 연결한다.
- 초기화 : 클래스를 생성한다.(이 때, static 값들을 생성하고 JVM Area에 저장한다.)
- Execution Engine : .class 파일을 해석한다. ( Interpreter, JIT 방식 + GB)
- Runtime Data Area : JVM이 프로세스로써 수행되기 위해 OS로부터 할당받는 메모리 영역이다. 저장 목적에 따라 다음과 같이 5개로 나눌 수 있다.
- Method Area : 모든 Thread에게 공유되는. 클래스, 변수, 메서드, static 변수, 상수 등이 저장되는 영역
- Heap Area : 모든 Thread에게 공유되는 new 명령어로 생성된 인스턴스와 객체가 저장되는 구역 (GC a.k.a Garbace Collection)
- Stack Area : 각 Thread마다 하나씩 생성. Method안에서 사용되는 값들이 저장되는 구역. 호출시 LIFO로 하나씩 생성, 실행 완료되면 LIFO로 하나씩 지워짐
- Pc Register : 각 Thread마다 하나씩 생성. CPU Register와 역할이 비슷하다. 현재 수행 중인 JVM의 주소 값 저장.
- Native Method Stack : 각 Thread마다 하나씩 생성. 다른 언어의 메서드 호출을 위해 할당되는 구역. 언어에 맞게 Stack이 형성되는 구역이다 (JNI라는 표준 규약을 제공한다.)
- Class Loader : 클래스 로더는 총 3 단계로 실행된다
- JDK와 JRE의 차이
- JRE(Java Runtime Environment) : JVM, 라이브러리 API, 자바 명령 및 기타 인프라 있음 : JVM의 실행환경을 구현한다고 볼 수 있음.
- JDK(Java Development Kit) : 프로그램 개발에 필요한 모든 기능을 갖춤. JVM, 라이브러리 API, 컴파일러 등의 개발도구가 포함됨. : 즉 JDK는 프로그램을 생성하고 *컴파일 할 수 있다.
- JRE(Java Runtime Environment) : JVM, 라이브러리 API, 자바 명령 및 기타 인프라 있음 : JVM의 실행환경을 구현한다고 볼 수 있음.
- 컴파일 하는 방법
