통합쿼리를 사용하면 좋은 경우
- 빅쿼리로 로드하기 전, 원본 데이터를 어떻게 변환하면 좋은지 확인하기 위해 통합 쿼리를 연구 목적으로 사용할 때
- 스프레드 시트의 데이터를 '대화형'으로 편집하기 위해 구글 시트에 보관하고, 쿼리 결과에 시트 내 실제 데이터를 반영하는 것이 필요할 때.
무슨소리인지 모르겠다 - 데이터에 대한 SQL 쿼리가 빈번하지 않을 경우, 외부 데이터 원본에 데이터를 보관할 수 있다.
1. 빅쿼리로 로드하기 전, 원본 데이터를 어떻게 변환하면 좋은지 확인하기 위해 통합 쿼리를 연구 목적으로 사용할 때
👉 읽었는데 무슨 말인지 정확히 모르겠다...
그래도 정리를 해보자면, autodetect를 사용하면 몇 raw를 보고 판단하여 데이터 타입을 샘플링해서 처리한다. 그래서 자기 기술적인 파일을 사용하거나, csv나 json의 경우 스키마를 직접 선언해 주어야 한다. 하지만 이러한 상황을 처리 하기 위한 리소스가 충분하지 않을 때, 통합 쿼리를 조회할 수 있는 환경을 데이터 분석가들에게 제공하는 개념이다.
2. 스프레드 시트의 데이터를 '대화형'으로 편집하기 위해 구글 시트에 보관하고, 쿼리 결과에 시트 내 실제 데이터를 반영하는 것이 필요할 때.
👉설명을 요약하면, 스프레드 시트에 있는 데이터를 빅쿼리에 올려서 쿼리하는 경우는 거의 없다. 왜냐하면 스프레드시트에 데이터가 올라가 있는 상황이라면, 스프레드시트를 사용하는 것이 훨씬 편리하기 때문.
여기서 대화형이란, Explore 기능을 말한다. 스프레드시트를 한국어로 표시하게되면 이 대화형 기능이 hide되는 것을 확인했다. 한국어로는 도구 > 탐색이며 영어로는 Tools > Explore이다. 아래 이미지가 영문으로 바꿨을 때 나오는 대화가 가능한 뷰이다.
왜 이걸 이제 알았을까!
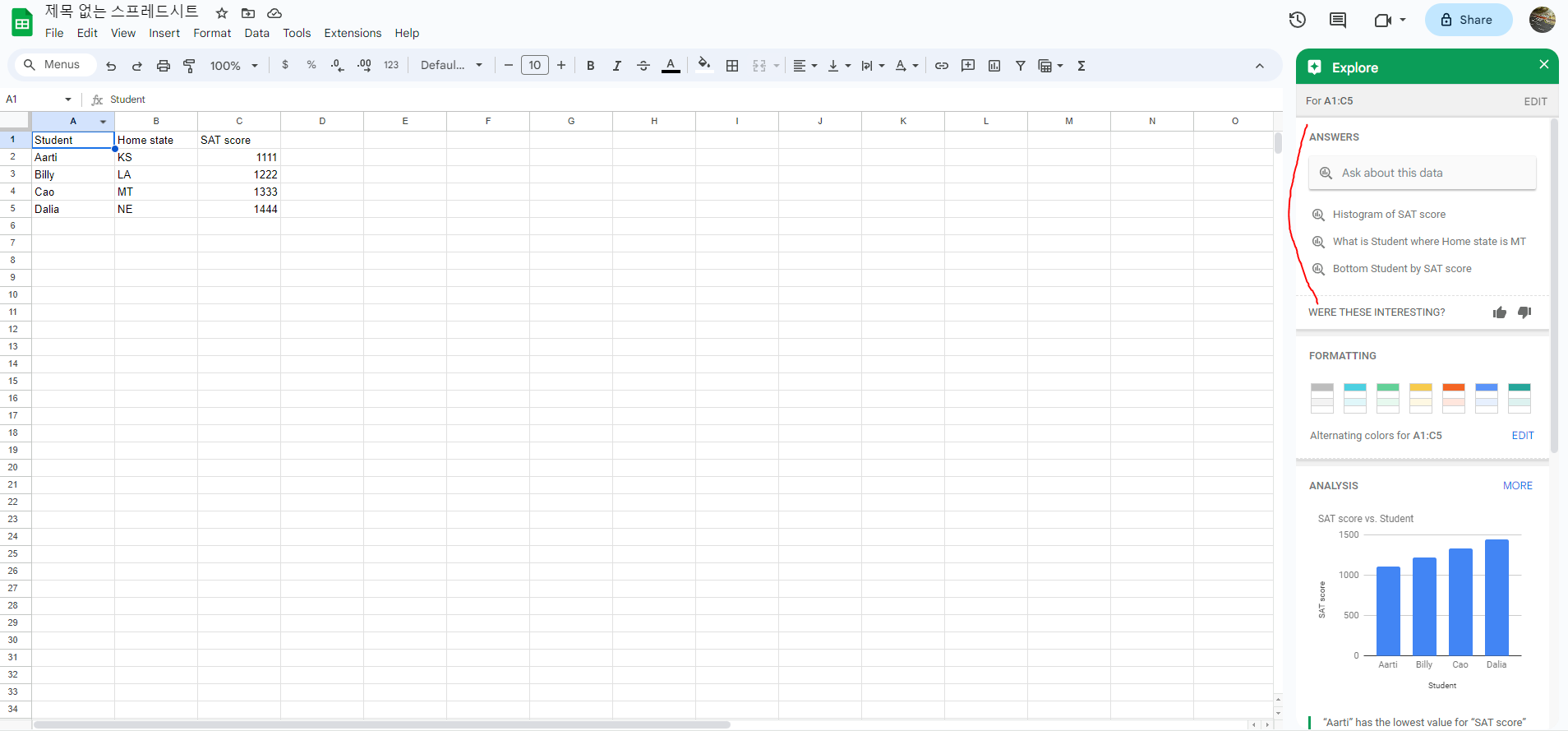
구글 시트와 빅쿼리를 통합하는 경우는 다음과 같다.
- 빅쿼리의 데이터를 이용해 스프레드시트를 생성하는 경우
- 시트에서 빅쿼리 연결한 후 빅쿼리에서 데이터 내보내기
- 시트를 이용해 빅쿼리 테이블을 조회하는 경우
- 앞서 말한 것처럼, 스프레드시트가 사용성이 뛰어나기 위해. 1번의 이유와 비슷한 맥락이다.
- 큰 규모의 데이터(00만개 이상)은 시트로 로드하는 것은 비효율(이라하고 불가능)적이다. 하지만, 시트 데이터를 table로 집어넣고 큰 규모의 데이터와 JOIN하는 것은 가능하다.
- 시트의 데이터를 SQL을 이용해 조회하는 경우
사내에 bigquery 환경을 구축하고 사용하기 위해 고군분투 중인데... 쉽지 않다...

데이터 분석가로 일하고 있습니다.