파일 저장소이다보니, 시간이 흐를수록 DISK 공간이 차게되고, 결국 DISK 확장을 해야하는 순간이 마주하게 됩니다.
수직적으로 확장한다면 당장의 문제를 해결할 수 있겠지만 언젠가는 수평 확장을 해야합니다. 이를 위해서 수평확장이 용이한 구조를 만들려고 합니다.
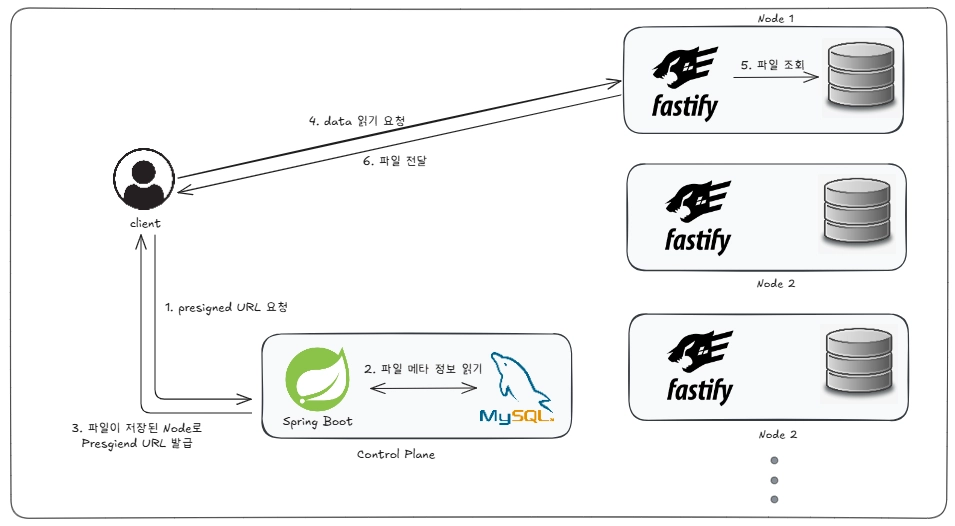
1. 초기 구조와 확장 구조 설계
1.1 초기 구조
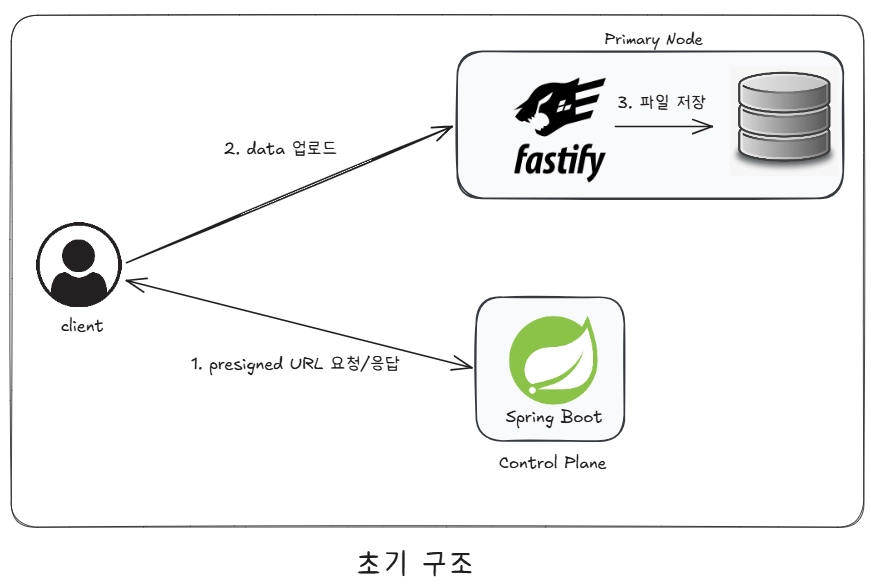
초기 구조에서는 Presigned URL 발급 시, 고정된 Node IP 주소를 반환했습니다.
운영 서버는 원본 + 복제, 총 2대였고 복제 서버는 복제만 담당했기 때문에, 업로드는 단 1개의 서버로만 처리했습니다.
이 구조의 문제는 명확합니다. DISK가 가득 찼을 때 수직 확장 외에 선택지가 없다는 것입니다. 따라서 DISK를 수평으로 확장할 수 있는 구조가 필요했습니다.
1.2 확장성 높은 구조로 바꾸기 위해 필요한 것
확장 가능한 구조를 만들기 위해 다음 3가지를 핵심 기준으로 삼았습니다.
- 쓰기 — 어떤 Node의 DISK에 파일을 저장할 것인가?
- 읽기 — 파일을 읽을 때, 어떤 Node에 저장되어 있는지 알아낼 수 있는가?
- 간편성 — 확장을 쉽게 하려면 무엇이 필요한가?
이 3가지를 중심으로 설계를 진행했습니다.
2. 확장성 있는 구조 설계하기
2.1 쓰기 구조
어떤 Node의 DISK에 파일을 저장할 것인가?
크게 2가지를 기준으로 저장할 node를 판단해야겠다고 생각하였습니다.
- 남아있는 DISK 용량이 많은 node
- 현재 처리 중인 요청의 개수가 적은 node
첫 번째는 모든 DISK에 균등하게 파일을 분배하기 위함이고, 두 번째는 하나의 node에 작업이 몰리지 않도록 하기 위함입니다.
우선순위가 1번이 높기 때문에, 우선 1번만을 확실하게 구현하고 2번은 추후 트래픽 분산을 처리할 때 구현하기로 하였습니다.
해당 트래픽 분산은 쓰기 뿐만 아니라, 읽기 요청에서도 고려해야할 부분이기에 추후 별도로 생각하는 것으로 하고, 확장성 구조 자체에만 집중하는 것이 좋다고 판단하였습니다.
2.2 읽기 구조
파일이 어디 node에 저장되어있는지를 알아낼 수 있을까?
요청 시, 사용되는 정보는 3가지 (user, bucket, path)입니다. (여기서 path는 node 번호가 아닌, 디렉토리 경로라고 생각하면 됩니다.) 즉, 사용자는 어디 node에 저장되어있는 지를 모르기 때문에, 서버에서 이를 확인하여 찾아줘야할 책임이 있습니다.
2.2.1 파일 위치 찾기
control plane이 node 에 직접 물어보는 방법도 있을 것이고, control plane 자체에 파일 정보를 저장하는 방법도 있을 것 같습니다.
node 에 일일이 물어보는 방법
정확성은 높을지 몰라도, presigned url을 발급받는 시점마다 모든 node에 요청을 보내게 되면, 두 가지 문제가 생깁니다.
- 불필요한 API 요청 - node의 개수가 늘어날수록 비효율적
- 사용자 대기 시간 증가 - 파일을 가지고 있는 node를 찾을 때까지 대기
control plane 자체에 저장하는 방법
파일 정보를 저장해야한다는 번거로움이 있을 수는 있겠지만, 사용자에게 빠른 응답을 보낼 수 있다는 장점이 있습니다.
다만, 파일 정보 업데이트를 실패하는 경우 정합성이 깨지는 문제가 있을 수 있습니다.
정합성 문제를 고려하더라도 두 번째 방법이 적합하다고 생각하여, control plane에 저장하는 방법을 선택하기로 하였습니다.
2.2.2 파일 메타 정보 저장하기
파일이 업로드가 완료되었을 때, 파일 정보들(위치 등)을 control plane에 저장해야 합니다. 따라서 업로드 성공 시 파일 정보 저장용 필드와 API를 추가해야합니다.
업로드 전에 presigned url을 발급하는 순간에 미리 저장하는 방법도 있을 수 있습니다.
하지만 업로드 전에 저장을 하게 되면 실제 파일이 저장되지 않았는데 메타정보에는 저장되는 경우가 생길 수 있습니다. 따라서 반드시 파일 업로드가 완료된 이후에 메타정보를 저장해야합니다.
public class StoredObject {
@Id
private UUID id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "bucket_id", nullable = false)
private Bucket bucket;
@Column(nullable = false, length = 1024)
private String storagePath;
...
@Column(length = 255, nullable = false)
private String primaryNodeIp;
@Column(length = 255)
private String secondaryNodeIp;아래의 파일 위치를 저장하는 2가지 필드를 추가하였습니다.
다만 이렇게 추가하게 될 경우, 추후 IP 주소가 바뀌게 되었을 때 데이터를 전부 바꿔야하는 문제가 있습니다. 따라서 enum이나 문자열로 맵핑시키는 방법으로 수정할 필요가 있습니다.
2.3 간편한 확장
환경 변수에 새로운 node의 ip만 추가하면, 자동으로 처리를 진행시키고 싶었습니다. control plane과 node가 강하게 묶여있는 게 아니기 때문에 충분히 가능하다고 생각하였습니다.
3. 구현
3.1 쓰기 구조
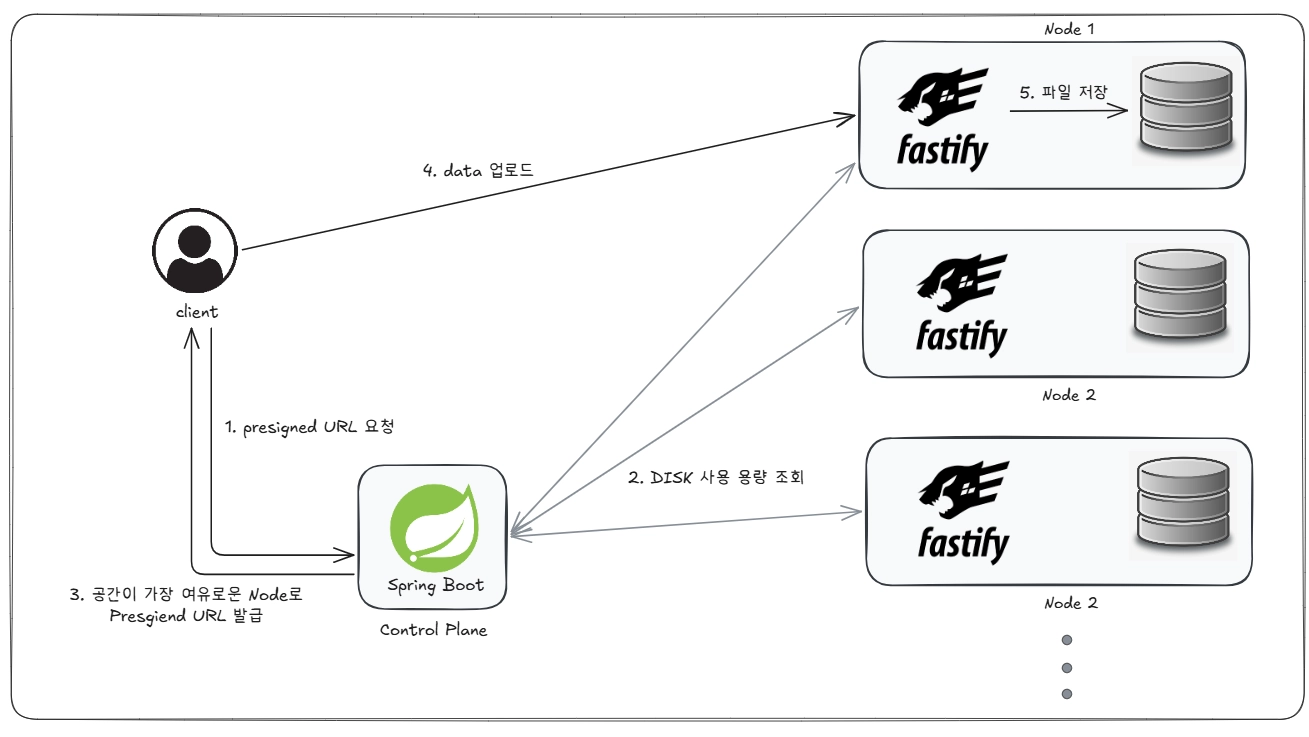
흐름은 다음과 같습니다.
- Control plane에 각각의 node ip 주소를 저장한다.
- 모든 node ip 주소로 DISK 사용 용량을 조회한다.
- 가장 여유 공간이 많은 node를 선택한다.
- 해당 node를 presigned url 로 발급한다.
- 사용자는 해당 node에 파일을 업로드한다.
3.1.2 코드
흐름은 위와 유사합니다.
Presigned URL 요청 → disk 사용량 조회 → 선택 → presigned URL 발급입니다.
아래는 presigned url 발급 코드입니다.
public class PresignedUrlService {
...
public String generateUploadPresignedUrl(String bucket, String objectKey, long fileSize) {
log.info("Upload Presigned URL 생성 요청 - bucket: {}, objectKey: {}, fileSize: {}", bucket, objectKey, fileSize);
StorageNodeDiskInfo selectedNode = storageNodeDiskService.selectOptimalNodeForUpload(fileSize);
log.info("Selected storage node - ip: {}, availableSpace: {} Bytes", selectedNode.getNodeIp(), selectedNode.getAvailableSpace());
return generatePresignedUrl(DIRECT_PATH, bucket, objectKey, fileSize, "PUT", selectedNode.getNodeIp(), STORAGE_NODE_PORT);
}
...
}아래는 disk 공간 조회 코드입니다.
public class StorageNodeDiskService {
private static final Logger log = LoggerFactory.getLogger(StorageNodeDiskService.class);
@Value("${storage.node.ips:}")
private String storageNodeIpsString;
@Value("${storage.node.port:3000}")
private Integer storageNodePort;
@Value("${storage.node.disk-query-timeout-ms:5000}")
private Long diskQueryTimeoutMs;
private final RestTemplate restTemplate;
public StorageNodeDiskService(RestTemplate restTemplate) {
this.restTemplate = restTemplate;
}
/**
* 업로드를 위한 최적의 노드 선택
*/
public StorageNodeDiskInfo selectOptimalNodeForUpload(long uploadFileSize) {
List<StorageNodeDiskInfo> nodeDiskInfos = getAllStorageNodesDiskUsage();
return nodeDiskInfos.stream()
.filter(nodeDisk -> nodeDisk.getAvailableSpace() >= uploadFileSize)
.max(Comparator.comparing(StorageNodeDiskInfo::getAvailableSpace))
.orElseThrow(() -> {
log.error("[Storage node] 적절한 Storage Node를 찾을 수 없습니다. (요청 크기: {} Byte)", fileSize);
return new RuntimeException("가용한 저장 공간이 부족하거나 활성화된 노드가 없습니다.");
});
}
/**
* 등록된 모든 Storage Node의 디스크 용량 조회
*
* @return Storage Node 디스크 정보 리스트
*/
private List<StorageNodeDiskInfo> getAllStorageNodesDiskUsage() {
List<String> nodeIpList = this.getValidNodeIps();
log.info("[Storage node] 등록된 node ip 개수 : {} ", nodeIpList.size());
List<CompletableFuture<StorageNodeDiskInfo>> futures = nodeIpList.stream()
.map(nodeIp -> CompletableFuture.supplyAsync(() -> queryDiskUsageToStorageNode(nodeIp.trim())))
.toList();
return futures.stream().map(future -> {
try {
return future.orTimeout(diskQueryTimeoutMs, TimeUnit.MILLISECONDS).join();
} catch (Exception e) {
log.warn("[Storage node] DISK 사용량 조회 타임아웃", e);
return null;
}
}).filter(Objects::nonNull).collect(Collectors.toList());
}
/**
* 환경 변수에 등록된 node ip 들을 반환
*/
private List<String> getValidNodeIps() {
if (storageNodeIpsString == null || storageNodeIpsString.isBlank()) {
throw new IllegalStateException("Storage Node IP가 설정되지 않았습니다");
}
List<String> nodeIps = Arrays.stream(storageNodeIpsString.split(","))
.map(String::trim)
.filter(ip -> !ip.isEmpty())
.toList();
if (nodeIps.isEmpty()) {
throw new IllegalStateException("유효한 Storage Node IP가 없습니다");
}
return nodeIps;
}
/**
* 단일 Storage Node의 디스크 사용량 조회
*/
private StorageNodeDiskInfo queryDiskUsageToStorageNode(String nodeIp) {
try {
String url = String.format("http://%s:%d/%s", nodeIp, storageNodePort, DISK_USAGE_API_ENDPOINT);
StorageNodeDiskInfo diskInfo = restTemplate.getForObject(url, StorageNodeDiskInfo.class);
if (diskInfo != null) {
log.debug("[Storage node] DISK '{}' IP의, - 사용 가능 DISK 용량: {} MB", nodeIp, diskInfo.getAvailableSpace());
}
return diskInfo;
} catch (Exception e) {
log.warn("[Storage node] disk 용량을 불러오는데 실패하였습니다 - ip: {}", nodeIp, e);
return null;
}
}
}보완할 점
- 현재는 DISK 공간만을 조회하여, 비어있는 DISK 용량의 최대 node만을 찾습니다. 트래픽도 고려하면 좋을 것 같습니다.
3.1.3 업로드 성공 시, 메타 정보 저장
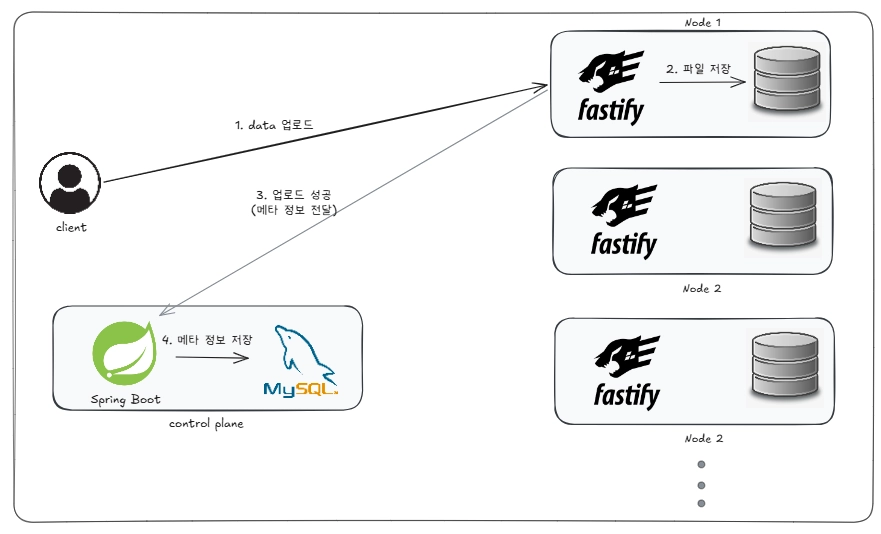
파일 업로드가 완료되면, 어떤 DISK에 저장되었는지를 알 수 있게 메타정보를 control plane으로 전달해주어야합니다.
3.3.1 node 메타 정보 저장 요청 로직
(로그나 불필요한 코드 제외)
export async function uploadFile(
request: FastifyRequest<{ Querystring: PresignedQuery }>,
replicationQueue: ReplicationQueueRepository,
): Promise<FileInfo> {
const { bucket, objectKey } = request.query;
const mimetype = request.headers["content-type"] ?? DEFAULT_CONTENT_TYPE;
const bodyStream = request.body;
// 업로드 전, 유효성 검사
validatePresignedUrlRequest(request.query, "PUT");
validateReplicationBodyStream(bodyStream);
// 파일 업로드
const filePath = await saveStreamToStorage(bucket, objectKey, bodyStream, request.log);
const fileInfo = await collectStreamFileInfo(bucket, objectKey, filePath, mimetype)
// 파일 다중화 로직 (바로 복제하는 것이 아니라, 저장해뒀다가 하나씩 복제함)
replicationQueue.registerReplicationTask(bucket, objectKey);
// ** 파일 업로드 완료 시에, control plane으로 메타 정보를 전달하는 로직 **
notifyUploadComplete(
{
bucket,
objectKey,
fileSize: fileInfo.size,
etag: fileInfo.etag ?? "",
storagePath: fileInfo.storagePath,
primaryNodeIp: NodeIpDetector.getCurrentNodeIp(),
},
request.log,
);
return fileInfo;
}async function notifyUploadComplete(
uploadInfo: {
bucket: string;
objectKey: string;
fileSize: number;
etag: string;
storagePath: string;
primaryNodeIp: string;
},
log: FastifyBaseLogger,
) {
try {
const controlPlaneUrl = process.env.CONTROL_PLANE_URL;
if (!controlPlaneUrl) {
throw new Error("CONTROL_PLANE_URL 값이 설정되지 않았습니다.");
}
const response = await fetch(
`${controlPlaneUrl}/api/stored-objects/upload-complete`,
{
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(uploadInfo),
},
);
if (!response.ok) {
throw new Error(
`Upload complete failed: ${response.status} ${response.statusText}`,
);
}
} catch (error: unknown) {
// TODO : 실패한 메타데이터 전송 요청을 별도로 저장하고, 이를 재시도하는 로직 필요
log.error(
error instanceof Error
? {
message: error.message,
stack: error.stack,
name: error.name,
}
: { error },
"[upload complete] control plane 호출 실패",
);
throw error;
}보완해야할 점
- 메타데이터 전송이 실패하는 경우, control plane에 파일 메타 정보가 없어서, 조회가 불가능하게 됩니다. 이에 대한 대비책이 필요합니다.
- 다중화(복제)된 node ip 정보 또한, control plane으로 전달해야합니다. 이를 통해 원본이 깨졌을 때, secondary로 요청을 할 수 있습니다.
3.2 읽기 구조
코드는 primary node ip를 조회해서 요청하는 방식입니다.
public class PresignedUrlService {
public String generateGetPresignedUrl(String bucket, String objectKey, long fileSize) {
log.info("업로드 Presigned URL 생성 요청 - bucket: {}, objectKey: {}", bucket, objectKey);
StoredObject storedObject = storedObjectService.getObject(bucket, objectKey);
String presignedUrl = generatePresignedUrl(DIRECT_PATH, bucket, objectKey, fileSize, "GET",
storedObject.getPrimaryNodeIp(), STORAGE_NODE_PORT);
log.info("업로드 Presigned URL 생성 - url: {}", presignedUrl);
return presignedUrl;
메타정보만 잘 저장되어 있고 읽을 수 있다면, 파일 조회는 어렵지 않습니다.
보완해야할 점
primary node에 파일이 존재하지 않을 수도 있습니다. 이때는secondary node의 IP로 presigned url을 발급해야합니다. 따라서 해당 파일이 존재하는지 확인하고 presigned url을 발급할 필요가 있습니다.- 원본 파일이 깨진 경우, secondary 로 재요청을 보낼 수 있어야합니다.
3.3 확장성
제가 의도한 확장은 이것저것 추가하는 것 없이, 다음 2개의 절차로 간단하게 확장시키고 싶었습니다.
- docker로 VM에 storage node 서버 띄우기
- control plane의 .env에 IP 등록하기
현재 .env 파일에 ip를 추가하면 자동으로 요청이 가도록 설정하였습니다.
# Control Plane .env 파일
# storage node
STORAGE_NODE_IPS=20.196.137.76,20.200.201.246
STORAGE_NODE_PORT=3000
STORAGE_NODE_DISK_QUERY_TIMEOUT_MS=5000STORAGE_NODE_IPS 에 ,를 기준으로 각각의 IP를 등록합니다.
Storage node에도 다음 2가지 정보를 추가하였습니다
# Storage Node .env 파일
NODE_IP=storage node의 IP 정보
CONTROL_PLANE_URL= 20.194.156.789:8080NODE_IP는 파일 메타 정보를 보낼 때, 파일의 위치를 알려주기 위한 정보입니다.
CONTROL_PLANE_URL 은 파일 메타정보를 보낼 서버 주소입니다.
위 정보만을 수정하고, docker를 통해 서버를 띄우면 간단하게 확장할 수 있습니다.
4. 결과 테스트
4.1 쓰기 테스트
2개의 node 서버를 대상으로 테스트를 하였고, DISK 공간을 모두 유사하게 맞춰두었습니다.
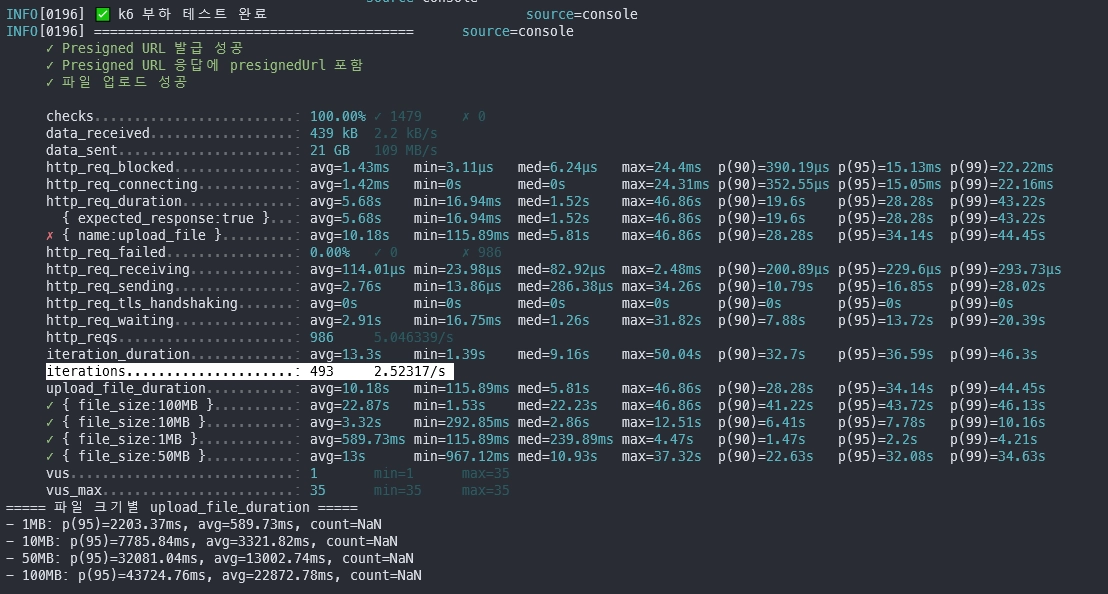
총 493개의 파일 업로드 요청을 했고 그 결과를 확인해보았습니다.
SELECT t.primary_node_ip, COUNT(*) AS cnt
FROM tb_objects t
GROUP BY t.primary_node_ip;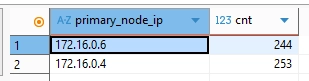
결과를 확인하면 상당히 고르게 분배된 것을 볼 수 있었습니다.
트래픽 분산 로그
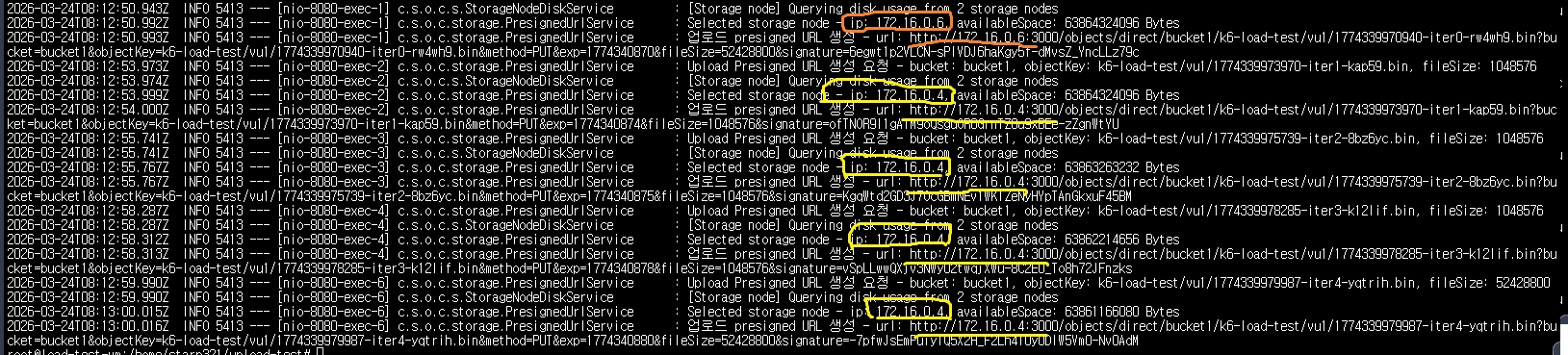
2개의 서버를 등록해둬서, 2개로 나눠진 걸 볼 수 있습니다.
5. 마무리
5.1 시간이 많이 걸렸던 부분?
사실 힘들다기보다는, 시간이 많이 걸렸던 부분이 있다.
controller 등록을 했는데, 빌드 후에 API가 작동을 안해서 어떤 문제인지 찾기가 어려웠다. 금방 끝날 것 같아서, VM 내부의 vim 으로 작업을 진행하고 테스트를 했는데 오히려 이게 발목을 더 잡은 듯 하다.
문제의 원인은 /gradlew build 시에, clean 을 하지 않아서 controller에서 API 인식을 못했던 것이다. clean 하고 하니 됐는데, 기쁘기도 했지만, 전혀 예상치 못한 곳에서 해결이 되어서 당황스럽기도 했다.
두 번째는 bucket 의 생성 여부인데, bucket 을 생성하지 않고 저장하다 보니, Control plane에서 에러가 발생하였고, 그 에러 메시지가 storage node의 로그에 제대로 출력이 안되었다.
- 로그를 제대로 명시하자
이전부터 로그 처리와 응답의 에러 포맷을 통일 시키는 것을 미루고 있었다. 이로 인해서 로그에 상태코드만 나왔을 뿐, 메세지가 안나왔었는데 이 문제로 인해 근본적인 원인 파악이 어려웠던 것 같다.
- 응답 및 로그 포맷, http 글로벌 응답 처리를 하자
클라이언트 → 서버 통신의 경우에는 어떤 응답이 보이는지 바로 보이지만, 서버내부 → 서버 통신간에는 예외처리나 로그를 제대로 찍지 않는 이상 어떤 오류나 응답이 왔는지 명확하게 보이지 않는다. 명확하게 보기 위해서는 로그, 포맷 등이 필수인 것 같다.
- 상수화 및 리팩토링
급하게 테스트를 돌려보고 싶다는 마음에, port 번호나 엔드포인트 등을 문자열로 하드코딩으로 박아버렸다. 이로 인해서 어떤 코드는 포트가 있고, 어떤 코드는 포트가 없다. 그 기준이 모호하니 상수화로 일관적으로 관리할 수 있도록 하자.
기능을 더 추가할 게 많지만서도, 리팩토링도 해야하고 정말 할게 많다.
5.2 AI 사용 관련 느낀점
이번에 AI를 사용해서 코딩을 했는데, 몇 가지 느낀점이 있어 작성한다.
- “아직 구현하지마” 를 명시적으로 달아둘 것 해당 텍스트가 없으면, 자기 마음대로 설계가 완료되었다고 구현을 시작해버린다. 위 텍스트를 명시해서 설계에만 집중하도록 하자.
- 한번 잘못 구현을 했다면, 대화창을 새로 파서 시작하자 이전 맥락을 과하게 기억하는듯 하다. 마음에 안들어서 지웠던 코드들이 다시 생성되어있는 모습을 많이 발견한다. 이런 부분들을 명시적으로 요청해도, 이 부분과 연관된 다른 부분들이 문제인지, 수정을 원치 않은 다른 부분들도 AI가 마음대로 수정한다. 따라서 한번 잘못되었으면, 다시 대화창을 새로 파서 시작하자. 정정하는 것보다 새로하는게 더 빠르다.
- 세션에서 읽기보다는 md 파일로 만들어 달라고 하자 원래는 세션으로만 읽고 요청을 했는데, 어느 부분을 특정지어서 말하는 게 너무 불편하다. ‘1의 storoedObject 엔티티의 A 필드를 ~~’ 이라고 하는 것보다, 그냥 md 문서를 내가 수정하는게 효율이 좋다. 뿐만아니라, 세션에서 하게 되면 다른 AI를 사용하는 게 힘든데, md 문서는 그대로 들고가면 되니 얼마나 효율적인가.
5.3 남아있는 과제
트래픽을 효과적으로 분산시키기
현재의 방식은, 트래픽을 분산하는 것이 아니라, DISK 용량을 분산시키기 위한 전략이라서 트래픽 자체를 효과적으로 막을 수 있는 방법은 아니다.
따라서 트래픽 또한 분산할 수 있도록 좋을 것 같다.
DISK 용량이 이상적으로 동일하다면, 트래픽이 잘 분산되지만, 그런 상황은 잘 발생하지 않는다.
이상적인 상황일땐 어떨 지 궁금해서 재미로 실제 성능을 한번 테스트를 진행해보았다.
이전과 마찬가지로 VUs=35로 진행해보았다. 디스크를 비우고 시작했으니, 이론상으로는 트래픽이 거의 균등하게 분배된다. 따라서 이전에 비해 2배 빨라져야한다.
| 파일 크기 | 이전 전송 속도 (MB/s) | 현재 초당 전송 속도 (MB/s) |
|---|---|---|
| 1MB | 0.54 MB/s | 1.61 MB/s |
| 10MB | 1.71 MB/s | 3.22 MB/s |
| 50MB | 1.79 MB/s | 3.77 MB/s |
| 100MB | 1.95 MB/s | 4.39 MB/s |
약 2배 늘어난 것을 확인할 수 있었다. 이상적인 수치이다.
이밖에
- 메타데이터 전송이 실패하는 경우에 대한 대비책
- 다중화(복제)된 파일 위치 정보 전송
primary node에 파일이 존재하지 않는 경우에 대한 대비책- 원본 파일이 깨진 경우, secondary 로 재요청
뿐만아니라 내가 못 본 여러가지 사항이 있을 것 같다.
5.4 하면서 느낀 점
어떤 문제를 해결하다 보면, 해결 과정에서 새로운 문제들이 보이게 된다. 이번 경험에도 확장성만 높이려고 했지만, 이로 인한 안정성, 트래픽 분산 등 정말 많은 새로운 문제들이 나왔다.
특히 트래픽 분산 부분은, 하면서 해결하면 좋을 것 같아서 유혹을 많이 받았다. (그만큼 해보고 싶은 매력적인 기능이었다)
하지만 이전 경험으로부터 다른 길로 새는게 좋지 않다는 걸 알고있다. 그리고 최근에 읽었던 toss의 핵심 가치에서도 이를 피하는 것을 추천하고 있던게 기억이 났다.

toss는 뛰어난 개발자가 많은 집단이다 보니, 그들에게서 어떤 시행착오가 있었고 어떤 행동 지침이 있었는지를 참고하면 많은 도움이 된다고 생각한다.
아마 이전의 나였다면 핵심이 아닌 다른 일들에 매몰되느라, 가장 중요한 확장성을 놓치지 않았을까 싶다.
개발 공부도 중요하지만 종종 이러한 좋은 마인드셋들을 읽어보면서, 나에게 적용해보는 것 또한 중요하다고 느꼈다.
