
Layered Architecture
애플리케이션을 세 가지 주요 계층으로 나누어 구조화하는 방법으로 각 계층은 특정한 책임을 갖고 있으며, 계층 간에는 명확한 역할 분담이 이루어져 코드의 재사용성, 유지보수성, 확장성을 높일 수 있음.
MVC 패턴과 Layered Architecture
- MVC 패턴
- 문제점
- Controller에서 요청에 대한 모든 처리를 수행하기 때문에 책임이 너무 많음
- 기능 추가, 수정, 삭제 등의 유지보수가 힘듦
- 메소드로 분리하여도 메소드를 호출하는 중복 코드가 발생하기 때문에 코드의 재사용성이 떨어짐
💡 Controller의 역할
- 요청에 대한 처리
- 예외처리
- View Template 또는 Data 응답
- 비지니스 로직 처리
- DB 상호작용
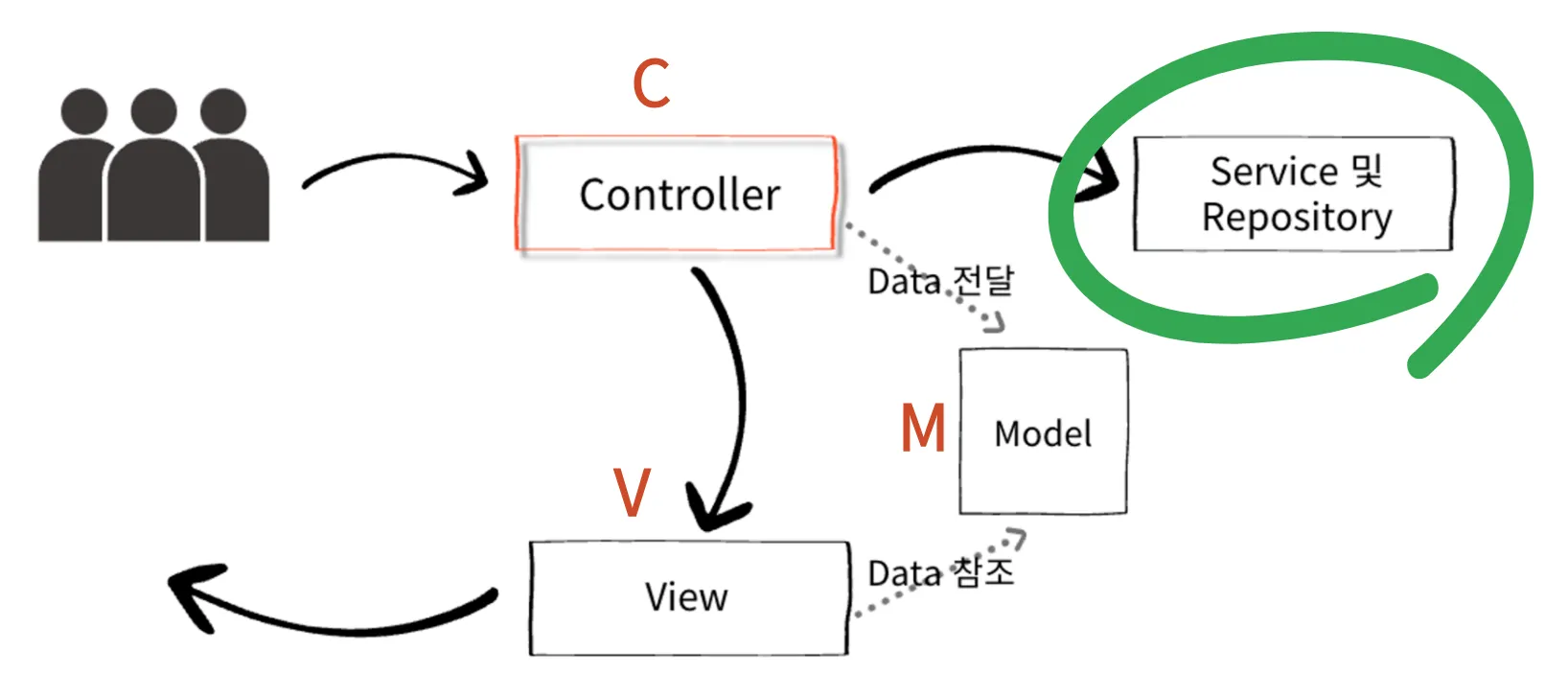
- Layered Architecture
- Presentation Layer(Controller Layer)
- 사용자의 요청을 받고 응답하는 역할 수행
- 화면을 응답하거나 데이터를 응답하는 API 정의
@Controller,@RestController- Business Layer(Service Layer)
- 비지니스 로직 수행
- 요청을 해석하여 Repository Layer에 전달
- 일반적으로 하나의 비지니스 로직은 하나의 트랜잭션으로 동작
@Service- Data Access Layer(Repository Layer)
- 데이터베이스와 연동되어 실제 데이터 관리
@Repository💡 DTO(Data Transfer Object)
계층 간 데이터 전달을 위해 사용되는 객체💡 Entity
데이터를 반환하는 형태로서 JPA에서 사용💡 DAO(Data Access Object)
데이터베이스와 상호작용하는 객체
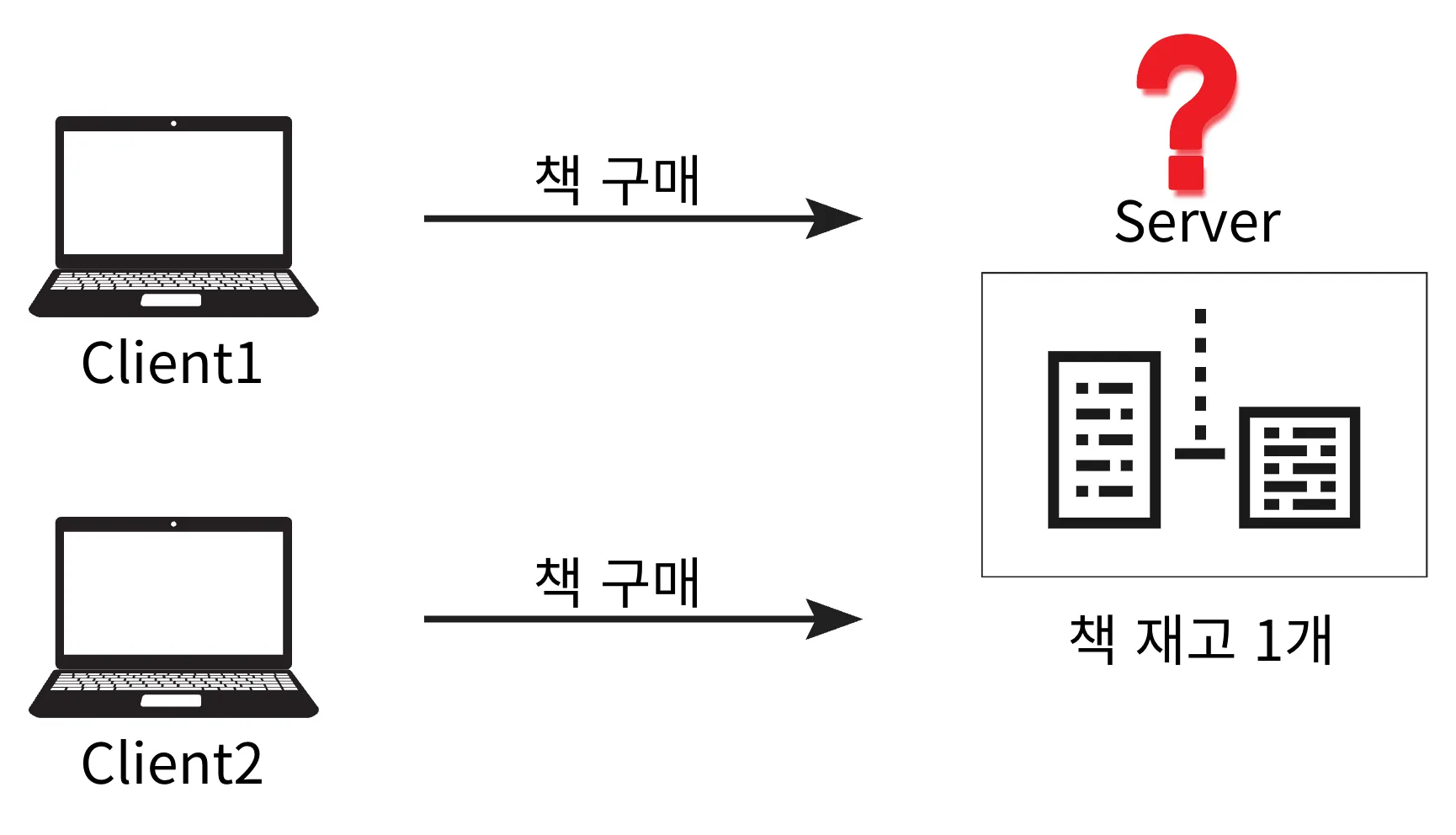
Database
여러 사람이 공유하고 사용할 목적으로 한 곳에서 관리되는 데이터의 조직화된 집합. 데이터를 소프트웨어에서 효율적으로 관리하기 위한 저장소이며, 데이터베이스 관리 시스템(DBMS)에 의해 제어됨.
DBMS(Database Management System)의 주요 기능

- 데이터 정의
- 데이터베이스 구조를 정의할 수 있는 기능 제공
- 데이터 관리
- 데이터를 물리적으로 저장하고, 관리하는 역할 수행
- 데이터를 저장하기 위한 최적화된 구조와 파일 시스템 관리
- 사용자가 데이터를 다룰 수 있도록 쿼리 언어(SQL) 제공
- 데이터 보안
- 사용자 권한 관리, 암호화, 감사 로그 등을 통해 데이터 보호
- 트랜잭션 관리
- 여러 사용자가 동시에 데이터에 접근할 때, 데이터의 일관성을 유지하기 위해 트랜잭션 관리 기능 제공
- ACID 속성 보장
- 백업 및 복구
- DBMS는 데이터 손실에 대비해 백업 및 복구 기능 제공
- 정기적인 백업을 통해 데이터를 보호하며, 장애 발생 시 데이터 복구 가능
- 동시성 제어
- 다수의 사용자가 동시에 데이터베이스에 접근하더라도 데이터 일관성이 유지되도록 하며, 이를 통해 충돌이나 데이터 불일치를 방지
DBMS의 종류
- 관계형 DMBS(RDBMS)
- 가장 많이 사용하는 데이터베이스
- 데이터를 테이블 형태로 구조화하여 저장하고 관리하는 시스템
- 테이블 간의 관계를 이용해 데이터를 연결
ex) Oracle, MySQL, PostgreSQL, Microsoft SQL Server 등- 비관계형 DBMS(NoSQL)
- 테이블이 아닌 key-value, document, graph 등의 다양한 형태로 데이터를 저장하고 관리
- 스키마가 고정되지 않고, 대규모 데이터 처리와 높은 확장성을 제공
ex) MongoDB, Cassandra, Redis 등- 다중 모델 DBMS
- 하나의 데이터베이스 관리 시스템에서 여러 데이터 모델을 지원
- 동일한 DBMS에서 관계형 데이터뿐만 아니라 문서형, 그래프형 데이터도 함께 관리 가능
ex) Amazon DynamoDB, Microsoft Azure Cosmos DB 등
RDBMS의 특징
관계형 데이터베이스 RDB(Relational DataBase)를 관리할 수 있는 소프트웨어로 데이터를 테이블 형식으로 관리. RDBMS는 데이터 간의 관계를 정의하고, 이러한 관계를 바탕으로 복잡한 Query를 실행할 수 있는 기능을 제공.
- 테이블 (Table)
- RDBMS에서 데이터는 테이블이라는 구조에 저장되며 행(row)과 열(column)로 구성
- 열은 데이터의 속성(이름)을 나타내고 타입(데이터 유형)을 가짐
- 행은 관계된 데이터의 묶음을 의미하고 tuple 또는 record라고도 함
- 데이터 무결성
- 테이블은 특정 규칙과 제약 조건(기본키, 외래키, 유니크 키등)을 통해 데이터를 저장함으로써 데이터 무결성(정확성, 일관성, 유효성)을 유지
- 관계 (Relationship)
- 테이블 간의 관계는 외래키(Foreign Key)를 통해 설정
- 1:1 관계: 한 테이블의 한 행이 다른 테이블의 한 행과만 연결
- 1:N 관계: 한 테이블의 한 행이 다른 테이블의 여러 행과 연결
- N:N 관계: 두 테이블의 여러 행이 서로 연결
- SQL (Structured Query Language)
- RDBMS에서 데이터를 정의하고, 관리하기 위한 표준 언어
- 데이터의 CRUD(생성, 조회, 수정, 삭제) 작업을 수행
- 키 (Key)
- 기본 키(Primary Key)
- 테이블 내에서 각 행을 고유하게 식별하는 열 또는 열의 조합
- 기본 키는 중복되지 않으며, NULL 값을 가질 수 없음
- 외래 키(Foreign Key)
- 한 테이블의 열이 다른 테이블의 기본 키를 참조하여 두 테이블 간의 관계를 설정
- 테이블 간의 데이터 무결성 유지 가능
- 유니크 키(Unique Key)
- 기본 키와 유사하지만, 하나의 테이블에 여러 개 존재 가능
- 중복된 값은 허용하지 않지만, NULL 값은 허용
- 트랜잭션 (Tracnsaction)
- RDBMS는 트랜잭션이라는 단위를 통해 데이터베이스 작업을 처리하며, 이를 통해 데이터의 일관성과 무결성을 유지
- 트랜잭션은 ACID 속성을 따름
- Atomicity(원자성): 트랜잭션의 모든 작업은 성공적으로 완료되어야 하며, 하나의 작업이라도 실패 시 진행된 모든 작업을 롤백
- Consistency(일관성): 데이터베이스를 일관된 상태로 유지
- Isolation(고립성): 동시에 실행되는 트랜잭션 간의 영향을 최소화
- Durability(지속성): 트랜잭션이 완료된 후 데이터의 변경 사항은 영구적으로 저장
- 정규화 (Normalization)
- 데이터의 중복을 줄이고, 일관성과 무결성을 유지하기 위해 데이터를 구조화하는 프로세스
- 여러가지 단계가 있으며, 각 단계는 데이터 중복을 줄이고 이상 현상을 방지하는 데 목적을 가짐
- 제1정규형(1NF)
- 제2정규형(2NF)
- 제3정규형(3NF)
- BCNF (Boyce-Codd Normal Form)
- 대체로 BNCF까지만 진행하며, 그 이상 진행하면 정규화의 단점이 나타날 수 있음
- 제4정규형(4NF)
- 제5정규형(5NF)
- 데이터 무결성 (Data Integrity)
- 엔티티 무결성
- 각 테이블의 기본 키(PK)가 중복되지 않고 NULL 값이 아닌 상태 유지
- 참조 무결성
- 외래 키(FK)를 통해 참조되는 데이터가 유효성을 유지하도록 보장
- 도메인 무결성
- 각 열이 정의된 데이터 타입과 제약 조건에 따라 유효한 값을 유지하도록 함
- 인덱스 (Index)
- 특정 열의 검색 성능을 향상시키기 위해 사용
- 테이블의 데이터를 정렬하고, 효율적으로 접근할 수 있도록 지원
- 인덱스가 많아지면 삽입 및 수정 작업의 성능에 영향이 있을 수 있음
JDBC
Java 언어를 사용하여 DB와 상호 작용하기 위한 자바 표준 인터페이스로 데이터베이스 관리 시스템(DBMS)과 통신하여 데이터를 삽입(C), 검색(R) , 수정(U) 및 삭제(D)할 수 있게 해줌.
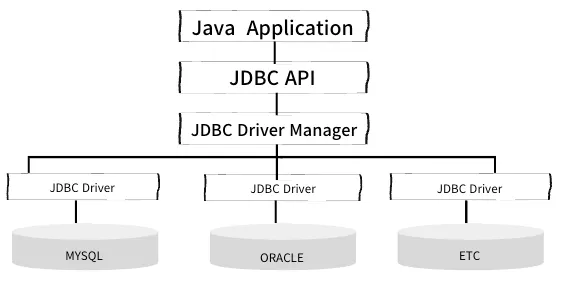
JDBC의 주요 특징
- 표준 API
- 대부분의 RDBMS에 대한 드라이버가 제공되어 여러 종류의 DB 대해 일관된 방식으로 상호 작용 가능
- DB 종류가 바뀌어도 쿼리문이 실행됨
- 데이터베이스 연결
- SQL 쿼리 실행
- Prepared Statement
- 결과 집합 처리(ResultSet)
- 데이터베이스로부터 반환된 결과를 Java 객체로 매핑할 수 있음
- 트랜잭션 관리
- 트랜잭션 시작, 커밋(성공) 또는 롤백(실패) 등의 트랜잭션 관리 작업 수행 가능
Statement VS Prepared Statement
Java에서 데이터베이스에 SQL 쿼리를 실행하기 위한 인터페이스이며, 데이터베이스와의 통신을 통해 쿼리 결과를 반환하거나 데이터 조작을 수행하기 위해 사용.
Statement
- DB와 연결되어 있는 Connection 객체를 통해 SQL문을 Database에 전달하여 실행하고, 결과를 반환받는 객체
- SQL 쿼리를 직접 문자열로 작성하여 데이터베이스에 보냄
- SQL 쿼리는 실행 전에 문자열 형태로 전달되고, 실행 시점에 데이터베이스에 직접 파싱되고 실행
- 매번 실행할 때마다 SQL문을 다시 파싱하기 때문에 성능에 영향을 미칠 수 있고, 보안 취약점을 가질 수 있음
Prepared Statement
- SQL문에
?(placeholder) 를 사용하여 컴파일 단계에서preCompile하여 미리 준비해놓고 쿼리문을 파라미터 바인딩하여 실행하고 결과를 반환- SQL 쿼리를 미리 컴파일하여 데이터베이스에 전송할 때 값만 바뀌는 형태로 전달
- 쿼리가 한 번 컴파일되면 여러 번 실행할 수 있으며, 성능과 보안 측면이 향상됨
- 이스케이핑 처리를 지원하기 때문에 입력 데이터에서 잠재적인 SQL 쿼리 문자열을 무력화함
Persistence Framework
애플리케이션에서 데이터를 영구적으로 저장하고 관리하기 위해 데이터베이스와 같은 저장소와의 상호 작용을 단순화하는 소프트웨어 도구.
- JDBC의 한계
- 간단한 SQL을 실행하는 경우에도 중복된 코드가 많음
- Connection, Prepared Statement, ResultSet 등
- DB에 따라 일관성 없는 정보를 가진 채로 Checked Exception(SQL Exception) 처리를 함
- Checked Exception인
SQLException은 개발자가 명시적으로 처리해야 함- 각 DBMS는 고유한 SQL 문법과 오류 코드 체계를 가지고 있기 때문에 DBMS에 따라 달리 처리해야 함
- Connection과 같은 공유 자원을 제대로 반환하지 않으면 한정된 시스템 자원(CPU, Memory)에 의해 서버가 다운되는 등의 문제 발생
- SQL Query를 개발자가 직접 작성
- 대부분의 테이블에 CRUD하는 쿼리가 포함되기 때문에 중복적인 쿼리 및 코드가 작성됨
- Persistence Framework의 등장
- JDBC 처럼 복잡함이나 번거로움 없이 간단한 작업만으로 Database와 연동되는 시스템
- 모든 Persistence Framework는 내부적으로 JDBC API를 사용하며, preparedStatement를 기본적으로 사용
- 크게 SQL Mapper, ORM 두가지로 나뉨
SQL Mapper
직접 작성한 SQL 문의 실행 결과와 객체(Object)의 필드를 Mapping하여 데이터를 객체화함. 대표적인 SQL Mapper로 Spring JDBC Template, MyBatis가 있음.
- Spring JDBC Template
- Spring Framework에서 제공하는 JDBC 작업을 단순화하고 개선한 유틸리티 클래스
- JDBC Template의 장점
- 간편한 데이터베이스 연결
- Connection 관련 코드들을 직접 작성하지 않고, yml 또는 properties 파일에 설정하는 것으로 해결
- Prepared Statement를 사용
- 예외 처리와 리소스 관리
- DB Connection을 자동으로 처리하여 리소스 누수를 방지
- 결과 집합(ResultSet) 처리
- 데이터를 자바 객체로 변환할 수 있도록 해줌
- 배치 처리 작업 지원
- 동일한 시간에 반복적으로 수행되는 쿼리
- SQL Mapper의 한계
- SQL을 직접 다룸
- 특정 DB에 종속적으로 사용하기 쉬움
- DB마다 쿼리문과 함수가 조금씩 다르기 때문에 다른 DB를 사용하면 수정해야할 가능성이 높음
- 테이블마다 비슷한 CRUD SQL, DAO 개발이 반복되기 때문에 코드 중복 발생
- 테이블 필드가 변경될 시 이와 관련된 모든 DAO의 SQL문, 객체의 필드 등을 수정해야 함
- 코드상으로 SQL과 JDBC API를 분리했지만 논리적으로 강한 의존성을 가지고 있음
- 객체와의 관계는 사라지고 DB에 대한 처리에 집중하게 됨(SQL 의존적인 개발)
- 관계형 DB와 객체지향의 패러다임 불일치
- 객체지향으로 설계된 것을 관계형 DB에 저장하기 어려움
- 테이블에 저장한 데이터를 다시 객체화 하는 것도 어려움
- 객체지향 : 캡슐화, 추상화, 상속, 다형성 → 객체 중심
- 관계형 데이터베이스(RDB) → 데이터 중심
- 각각 지향하는 목적이 다르기 때문에 사용 방법과 표현 방식에 차이 발생
💡 패러다임 불일치 문제를 해결하기 위해 이후 ORM이 등장하게 된다.
