
프로그래머스에서 stream 사용하는 법을 연습한답시고 문제를 풀다가 실행 시간을 보고서는 들었던 생각이 꽤 느리다라는 것이었다. 그래서 같은 문제를 단순 반복문으로 변경해서 풀자 실행 시간이 대폭 감소했다. stream, 람다와 함께 중요하다는 얘기는 많이 들었는데 왜 그런지, 언제 써야 좋은지에 대해서는 생각해보지 않았던 것 같아 정리해보려고 한다.
스트림을 사용하는 이유
- 가독성 향상
선언적으로 코딩이 가능- 필터링, 매핑, 정렬 등의 기능을
체이닝하여 표현 가능// 이름이 "A"로 시작하고 길이가 4 이상인 이름을 찾아 정렬하여 출력하는 경우 // 단순 반복문 List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David"); List<String> filteredAndSortedNames = new ArrayList<>(); for (String name : names) { if (name.startsWith("A") && name.length() >= 4) { filteredAndSortedNames.add(name); } } Collections.sort(filteredAndSortedNames); for (String name : filteredAndSortedNames) { System.out.println(name); } // 스트림 List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David"); names.stream() .filter(name -> name.startsWith("A") && name.length() >= 4) .sorted() .forEach(System.out::println);
- 유지보수성 향상
- 병렬처리 지원
- 대량의 데이터를 빠르고 쉽게 처리 가능
- 멀티 스레드 사용으로 인한 효율적인 데이터 처리
- 간단한 사용법 (
parallel()또는parallelStream()사용)
스트림의 처리 구조와 특징
생성 > 가공 > 소비의 구조
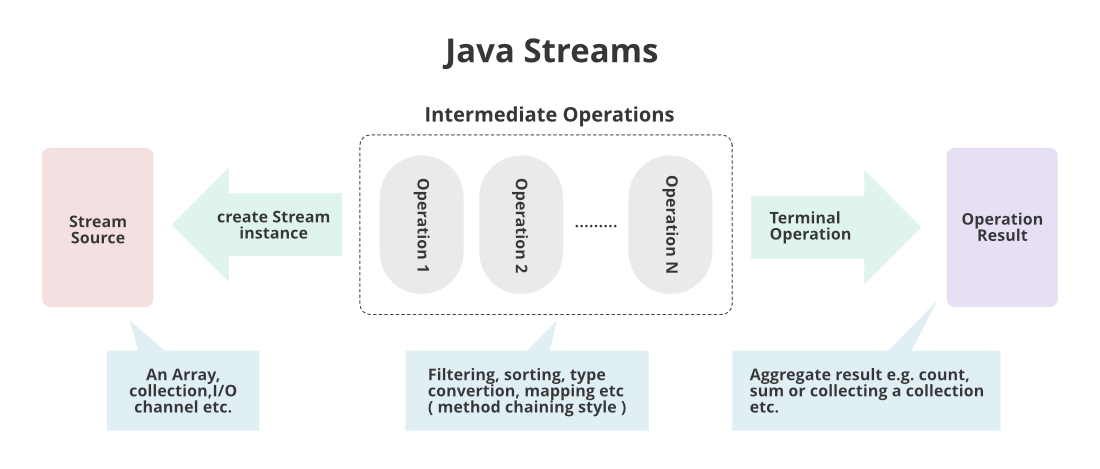
- 생성
- 데이터의 컬렉션을 스트림으로 변환하는 과정
- 스트림을 사용하기 위해 최초 1번 수행 필요
- 모든 데이터가 한꺼번에 메모리에 로드되지 않고 필요할 때만 로드되는 것이 특징
- 대량의 데이터 셋에서의 메모리 사용량 최적화 및 불필요한 데이터를 로드하지 않아도 되어 효율적
- 가공(중간 연산)
- 데이터 집합을 원하는 형태로 가공 (= 중간 처리)
- 필터(filter), 변형(map), 정렬(sort) 등을 나타냄
- 입력값, 결과값 모두 스트림 타입
- 중간 연산을 연결하여 연속해서 여러 번 수행 가능
- 소비(최종 연산)
- 최종 결과물을 얻는 처리 과정
- 데이터 컬렉션 또는 하나의 값(합계, 평균 등)으로 변환된 결과물 획득
- 최종 결과물을 얻기 위해 1번만 수행 가능
- 스트림은 1회성이기 때문에 최종 연산이 수행되면 더 이상의 연산은 불가능
스트림의 데이터 처리 특징
- 지연 평가(Lasy Evaluation)
- 스트림에서 중간 연산들은 호출 즉시 수행되지 않고 최종 연산이 호출될 때까지 지연
- 함수 단위로 데이터가 처리되는 것이 아닌, 데이터가 나타난 흐름의 순서대로 처리
- 하수 처리 시설에서 물이 흘러가는 순서대로 각각 정화 과정을 통해 처리되는 방식과 유사
그래서 스트림은 왜 느릴까?
- 추상화 비용
- 스트림은 데이터 추상화를 위해 다양한 객체를 생성
- 각 연산(필터, 맵 등)은 파이프라인을 구성하며, 내부적으로 추가적인 함수 호출과 람다식 실행
- 함수 호출 오버헤드
- 람다식 및 메소드 참조를 통해 여러 함수 호출 발생
- 병렬 처리 준비
- 데이터 병렬 처리를 지원하기 위해 내부적으로 처리 단계 설계
- 병렬 처리를 사용하지 않아도(단일 스레드여도) 처리 단계 설계
- GC 부담
- 많은 임시 객체(람다, 컬렉션)를 생성하기 때문에 GC(가비지 컬렉션)의 부담 증가
그럼 스트림은 언제 써야 할까?
- 데이터 변환 / 필터링
- 맵핑, 필터링, 정렬, 집계와 같은 복잡한 데이터 로직이 필요한 경우
- 멀티코어 활용
- 대규모 데이터에서 병렬 처리를 통해 성능 향상이 필요한 경우
- 가독성 향상
- 데이터 처리 파이프라인을 간결하게 표현하는 것이 필요한 경우
✅ 정리
- 단순 작업에는 반복문이 더 빠르고 효율적
- 복잡한 데이터 변환이나 필터링 작업이 많은 경우에는 스트림이 효율적 (가독성 향상도 기대 가능)
- 성능이 최우선인 경우, 성능 테스트를 통해 반복문과 스트림을 적절히 조합하는 것이 효율적
