pytorch 모델 저장 및 불러오기 관련
본 내용 사이트
https://pytorch.org/tutorials/beginner/saving_loading_models.html (영문)
https://tutorials.pytorch.kr/beginner/saving_loading_models.html (한글)
번역본보다 영문 설명흐름이 더 나은 듯
모델 저장 및 불러오기
- 함수
- torch.save : Models, Tensors, dictionaries를 저장할 수 있음
python의 pickle 사용하여 직렬화된 객체1 를 디스크에 저장. - torch.load : 직렬화된 객체 파일을 역직렬화하고 메모리에 올림(?). 데이터를 특정 장치에 불러올 때에도 사용함
- torch.nn.Module.load_state_dict: 역직렬화 된 state_dict를 사용하여 모델의 매개변수들을 불러옴.
cf. state_dict : 모델의 학습 중 학습되는 매개변수(ex) Weight, bias) - model.parameter( ) 로 접근 가능
사용 방법등은 본 사이트의 내용을 참고 (상단)
State_dict를 사용하는 이유
state_dict를 활용하는 방식을 권장하고 있음
전체 모델을 save/load 하는 방식
1. python의 pickle 모듈을 사용하여 전체모듈 을 저장(?)
첫번째 모듈 : 프로그래밍 에서 말하는 일반적인 모듈
두번째 모듈 :nn.Module ? 인건가첫번째랑 개념으로 쓴 것 같음
2. 직렬화된 데이터가(=모델) 모델 저장시 사용한 특정 클래스 및 디렉토리 경로(구조)에 얽매인다는 것이 단점
3. 이런 일이 발생하는 이유 : pickle이 model class 자체를 저장하지 못해서, 해당 클래스를 갖고 있는 파일로 가는 경로를 저장하기 때문.
4. 그래서, 다른 프로젝트에 사용되거나,refactor2 이후에 code가 여러가지 방식으로 break될 수 있음
- 그래서, 전체 저장 방식이 훨씬 직관적이고 코드도 간단함에도 state_dict방식을 추천
관련 개념들
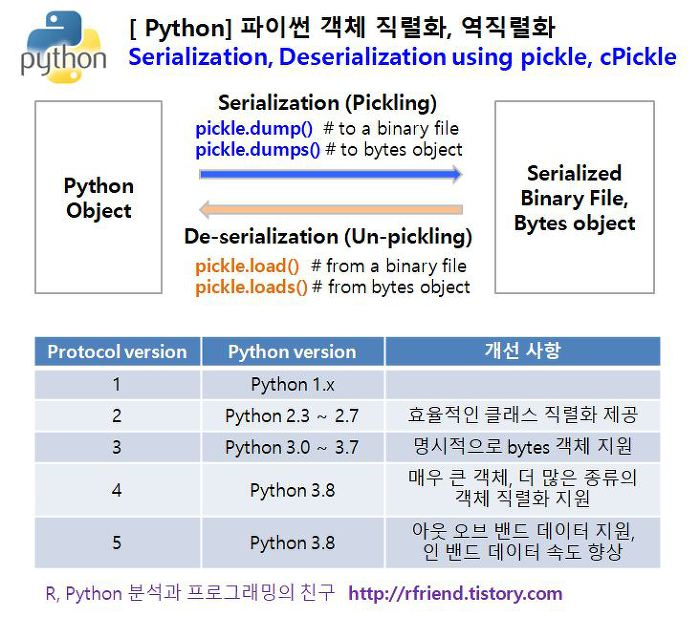
개념1-직렬화와 역직렬화
- 직렬화(serialization) : 파이썬 객체를 일정한 규칙(protocol)에 따라 효율적으로 저장하고 전송할 때, 데이터를 줄로 세워 저장하는 것
- 역직렬화(de-) : 직렬화된 파일이나 바이트를 원래의 객체로 복원
cf. Pickle, JSON, YAML 등이 있음
| Pickle | JSON, YAML |
|---|---|
| 식별불가능, 전송효율 좋음 | 사람이 식별가능, 전송효율 떨어짐 |
주의 : pickle의 경우 파이썬 버젼별로 Pickle Protocol Version이 다름
따라서, 상위 버전에서 저장 -> 하위 버전에서 역직렬화 불가능
개념2-코드 리팩토링
- 리팩토링의 조건 2가지
- 외부에서 본 프로그램의 동작은 변하지 x
- 프로그램 내부의 구조를 개선
cf. 디버깅도 리팩토링으로 볼 수 있나? (x) --> 디버깅은 프로그램 동작이 변함
참고 사이트
직렬화, 역직렬화 : https://rfriend.tistory.com/525
리팩토링 : https://jwprogramming.tistory.com/180
