1113_TIL
- 통계학 라이브 세션 1회차 수강
- 신뢰구간과 신뢰수준
- 모집단으로 부터 추출한 표본을 통해, 표본 평균으로 부터 일정 구간 내에, 설정한 신뢰 수준의 확률에서 모집단의 평균을 구간 추정한다. 이 때, 일정 구간이라 함은, 설정한 신뢰 구간에 따른 Z-score 값 ( 95 %의 신뢰 수준이라면 약 1.96 ) 에 표본 편차를 곱하고, 표본 수의 제곱근으로 나눈 것이며, 이를 표본 평균에서 ± 한 범위를 말하며, 이를 신뢰 구간이라고 한다.
- 예를 들어, sample1 = [5, 10, 17, 29, 14, 25, 16, 13, 9, 17] 과 같은 표본이 있다고 할 때,
표본의 평균은 15.5, 95% 신뢰 구간은 15.5 ± 1.96 6.84 sqrt(10) 으로 설정 되며, 해당 구간 내에 모집단의 평균이 존재할 확률이 95 % 라는 것을 의미한다.
- 예를 들어, sample1 = [5, 10, 17, 29, 14, 25, 16, 13, 9, 17] 과 같은 표본이 있다고 할 때,
- 추출된 표본에 따라 신뢰 구간 또한 달라지게 되며, 이 때, 모집단의 표준 편차를 알 수 없기 때문에, 표본의 표준편차와 모집단의 표준편차가 같다고 가정한다.
- 단일 표본에서 신뢰 구간은 해당 구간 내 모집단 평균이 존재할 확률이 95 % (신뢰 수준만큼) 라는 것을 의미하며, 다르게 말하면, 같은 크기의 무작위 표본을 모집단으로 부터 추출할 때, 그 표본의 신뢰 구간에 모집단의 평균을 포함할 확률이 95 % 라고 말할 수도 있다.
- 모집단으로 부터 추출한 표본을 통해, 표본 평균으로 부터 일정 구간 내에, 설정한 신뢰 수준의 확률에서 모집단의 평균을 구간 추정한다. 이 때, 일정 구간이라 함은, 설정한 신뢰 구간에 따른 Z-score 값 ( 95 %의 신뢰 수준이라면 약 1.96 ) 에 표본 편차를 곱하고, 표본 수의 제곱근으로 나눈 것이며, 이를 표본 평균에서 ± 한 범위를 말하며, 이를 신뢰 구간이라고 한다.
- SQLD 개념 정리
- CASE 절에서, 값이 일치하는 조건으로 경우의 수를 구분한다면 다음과 같이 작성할 수 있다.
column에서 value에 해당하는 값이라면 result를 출력해 new_column에 할당
case 'column' when 'value' then 'result' end as 'new_column' -
연산자 우선 순위 > 1. 괄호 - 2. NOT - 3. 비교 연산자 / SQL 비교 연산자 - 4. AND - 5. OR 순
-
EQUI 조인 > Column 간에 같은 값이 있는 경우, where 절에서 해당 값이 일치하는 조건으로 JOIN
SELECT table1.column_a, table2.column_b, ...
FROM table1, table2
WHERE table1.column_a = table2.column_b;예시 > 
- 집합 연산자
- JOIN이 테이블 간의 결합이라면, 집합 연산자 UNION, INTERSECT, MINUS 는 쿼리 간의 결합으로, 각각 합집합, 교집합, 차집합을 의미한다.
- 그룹 함수
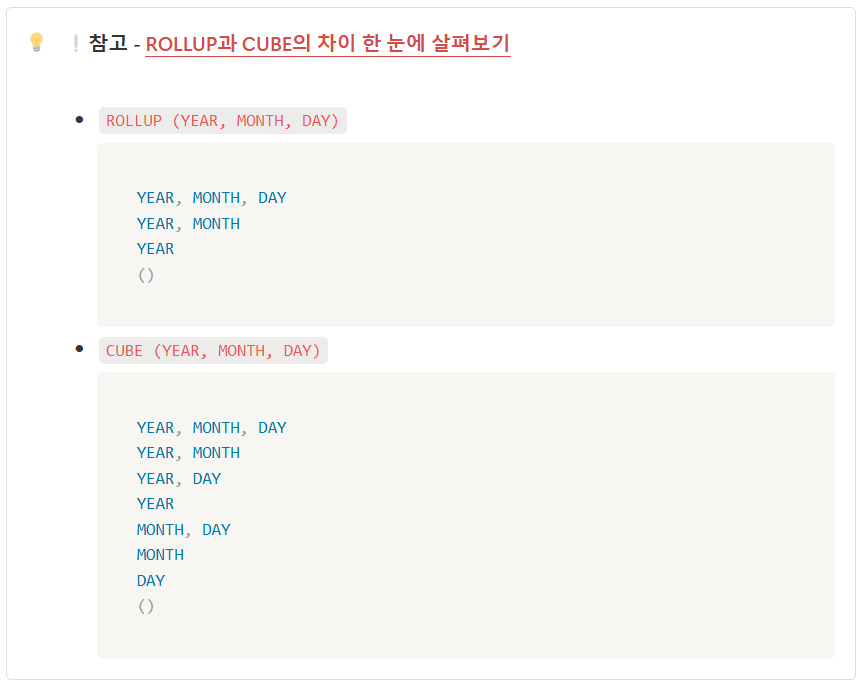
- Group by 에 추가적으로 ROLLUP, CUBE, GROUPING 함수를 사용할 수 있다.
- ROLLUP(A, B, C) > 순차적으로 그룹화, 뒤에 갈수록 세부적 그룹
- CUBE(A, B, C) > 가능한 모든 조합으로 그룹화, 순서 상관 X
- 말로 정리하기보다는 출력 결과로 확인... > https://for-my-wealthy-life.tistory.com/44

안녕하세요