
오늘은 인덱스의 종류에 대해서 알아볼 것이다.
인덱스 종류
Clustered(영한 사전)
Non-Clustered(색인)
Clustered -> 실제로 데이터가 정렬되는 순서에 영향을 줌.
데이터는 leaf page에 저장이 된다.
leaf page = data page
잎사귀에 실제 데이터가 때려박히게 된다.
데이터는 Clustered Index 키 순서로 정렬된다.
이전시간의 인덱스는 RID라는게 있어서
그녀석을 한번더 참조를 하는 식이였다.
Non-Clustered Index ?
-> Clustered Index 유뮤에 따라서 다르게 동작함
1) Clustered Index 없는 경우
- Clustered Index가 없으면 데이터는 Heap Table이라는 곳에 저장
- Heap RID -> Heap Table에 접근 -> 데이터 추출2) Clustered Index 있는 경우
- Heap Table없음. Leaf Table(Leaf page?)에 실제 데이터(원본데이터)가 있다.
- Clustered Index의 실제 키 값을 들고 있는다.정리하자면 실제 데이터 (원본데이터) 어디에 넣고 관리를 할 것인가가 핵심임.
Clustered가 있으면 leaf Page에서 관리를 하는 것이고
없으면 하면 Heap Table이 생긴다 는 것이다.
1) 임시 테스트 테이블 만들고 데이터 복사

2) 인덱스 추가

3) 인덱스 정보

이래나옴
4) 인덱스 번호 찾기


index_OrderDetails의 index_id번호는 2번이다.
5) 조회

이렇게 조회를 하면된다 DB이름, 테이블이름, 인덱스 번호

이렇게 나옴
880 824 848 849 850 851 852
이런식이다.
6) 824 페이지 대표로 까보기


이렇게나오는데 지금 Non-clustered index라서
Heap RID를 이용해서 실제로
데이터가있는 Heap Table에서 데이터를 꺼내 쓴다고 했었다!
Heap RID ([페이지 주소(4)][파일ID(2)][슬롯(2)] ROW)
Heap Table[ {Page} {Page} {Page} {Page} ]
데이터가 어떤 슬롯에 어떤 페이지에 있는지는 Heap RID가 가르키고 있기 때문이다
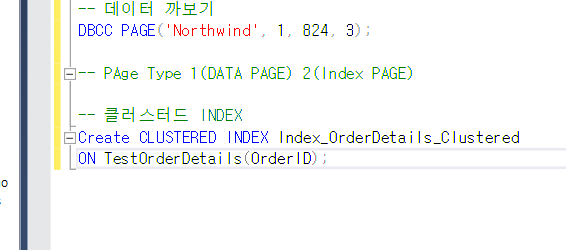
그다음 페이지 인덱스와
CLustered Index 생성방법이다.
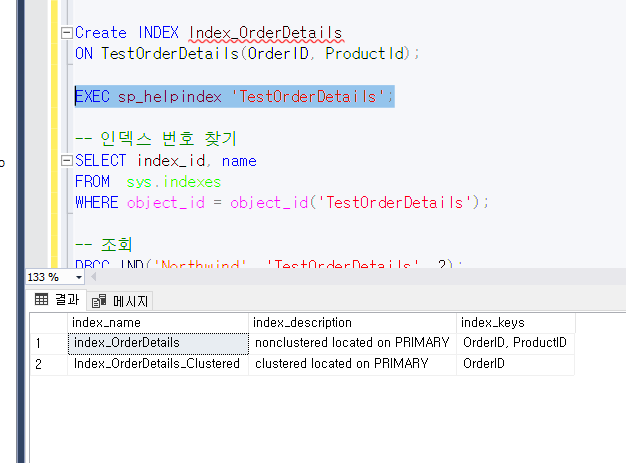
생성 됬는지 확인해보면 이렇게 잘 생성되고 나온다.
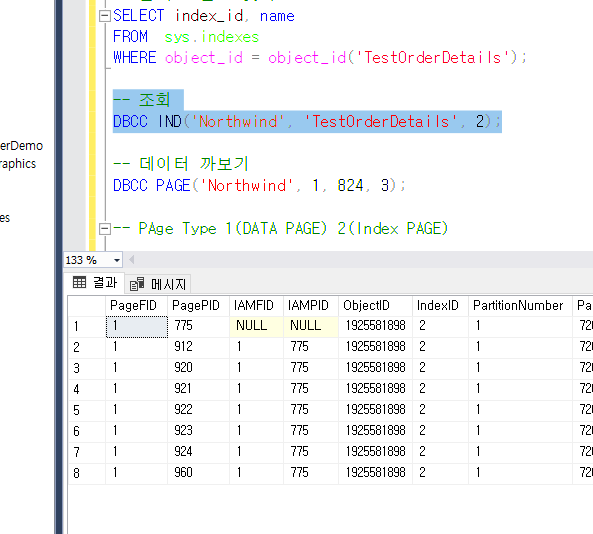
2번 인덱스를 조회를 해보면 지금 PagePID가 다 변경이 되어있는 것을 볼 수 있다.
클러스터드가 물리적으로 다 변경을 시키기 때문이다.
그리고
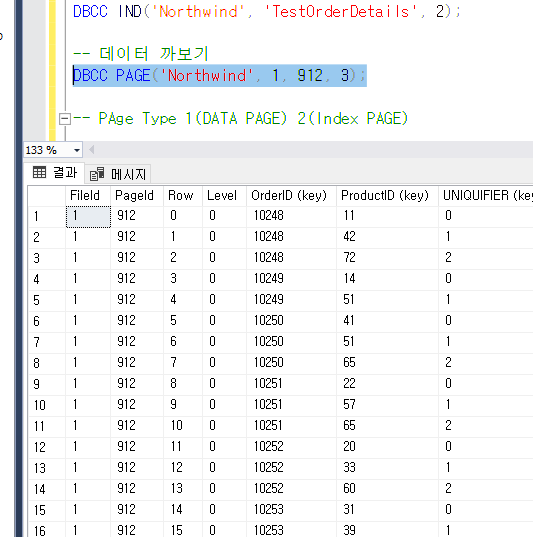
데이터를 까보면 기존에 있던 Heap RID가 사라진 것을 확인이 가능하다.
기존에는
이렇게 Heap Rid가 있음
그리고 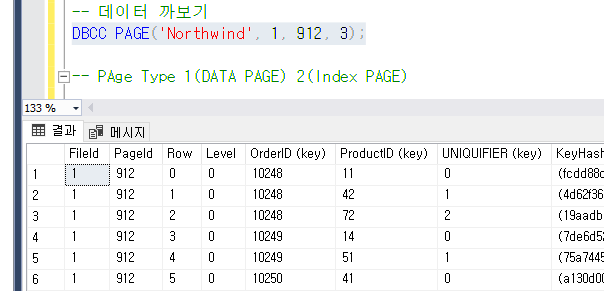
이런 UNIQUIFIRE 라는 애가 생겼는데
같은 데이터 끼리 생기는데
CLustered Index같은 경우 같은 동일한 값에도 Clustered를 걸 수 있다.
왜 생긴 거냐면은
지금
OrderID가 10248이 같은게 3개가 있는데
OrderID에만 Clustered를 걸어줘서 구분하기 위해서 10248의 0, 1, 2
이런식으로 걸어줘서 Leaf Page에 가서 데이터를 가져오게 된다.
Clustered 조회
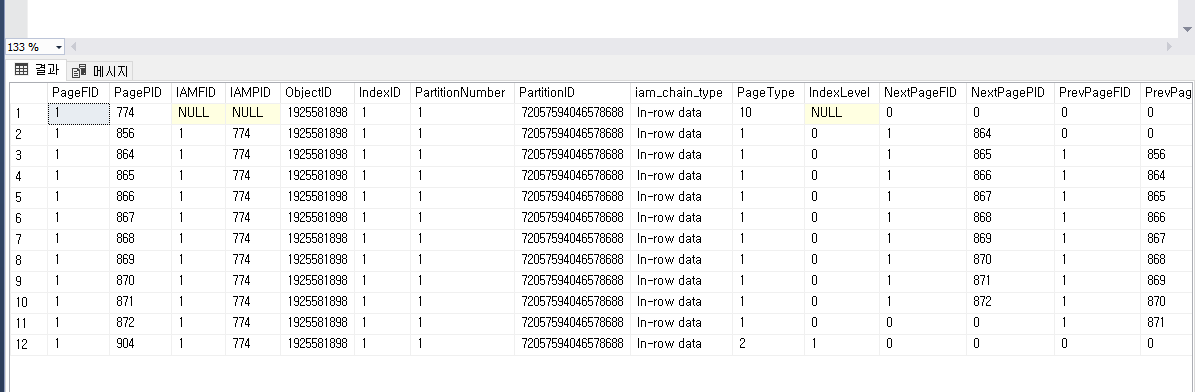
뭐 이렇게 나오는데 지금
904번이
856 864 865 ~ 872
이런식이다.
그라고 Page Type을 보면 904빼고 다 1이라 실제 물리적으로 데이터가 저장되어있는 페이지를 가지고 있는 것을 볼 수 있다.
856 864 865 ~ 872 들이 물리적으로 실제 데이터를 물고있는 페이지이다.
<정리>
[ Non-Clustered만 있을 경우 ]
일 경우 Heap RID -> Heap Table접근 -> 데이터 추출
[ Non-Clustered && Clustered 둘다 사용할 경우 ]
일 경우 Heap Table이 없다.
데이터 뽑아 올 때는 Clustered의 실제 키 값 들고있는데 -> Leaf Page
그래서 데이터 접근하는 방식이 Non-Clustered 일 경우
1. 8802. 824 848 849 850 851 852
Heap RID( [페이지 주소][페이지 주소]) RId를 이용해서
3. Heap Table( [ {Page} {Page} ) 찾고 끝.
이렇게 밑으로 내려오면서 끝나는데
Clustered일 경우
- 880
- 824 848 849 850 851 852 "키를 가져와서"
Clustered ->
-
904
-
856 864 865 ~ 872
이렇게 접근을 하게 된다.
