
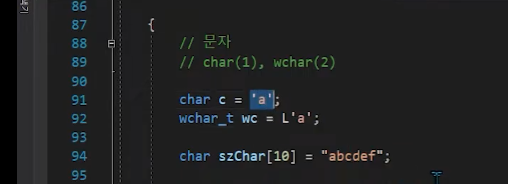
어제 한거는 뭐냐하면은
L 안 붙이면 1바이트이고
L 붙이면 와이드 바이트라해서 모든 문자 하나하나를 2바이트로 보겠다. 이거였다.
1바이트는 엄밀히 말하면 1바이트 아니다.
"멀티바이트 캐릭터 셋"이라고 해가지고
1바이트로 표현할 것은 1바이트로 2바이트로 표현할 것은 2바이트로 이게 멀티바이트 캐릭터 셋이다.
그래서 L안 붙은 문자는 전부다 1바이트이다! 이것은 틀린말이다.
멀티바이트는 문자에 따라서 가변길이로 대응을 하는 것이다.
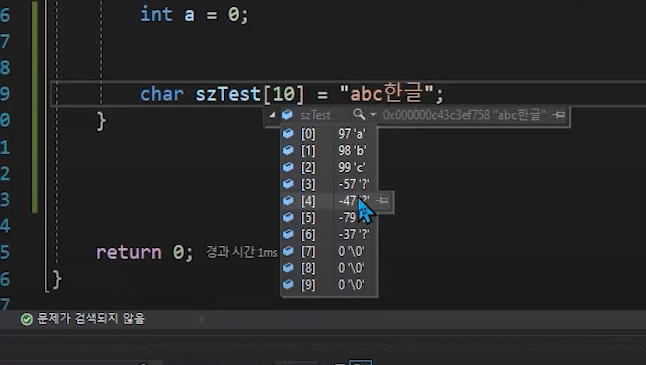
지금 보면은 34는 '한', 45는 '글'이다. 각각 2바이트임 (가짓수가 너무 많아서)
이 멀티바이트 시스템은 윈도우에서만 잔존하는 시스템이다.
다른데서는 멀티바이트 안 쓴다.
(현재는 utf-8이 거으이 표준이다)
와이드 바이트
모든 문자를 2바이트로 표현하는 시스템 == "유니코드"
이것이 호환성 높고 다른언어 호환성 때문에 이거 쓴다
수업도 2바이트 표현방식 따르는 "와이드 바이트 시스템" 쓸것이다.
이거 쓸 것이다.
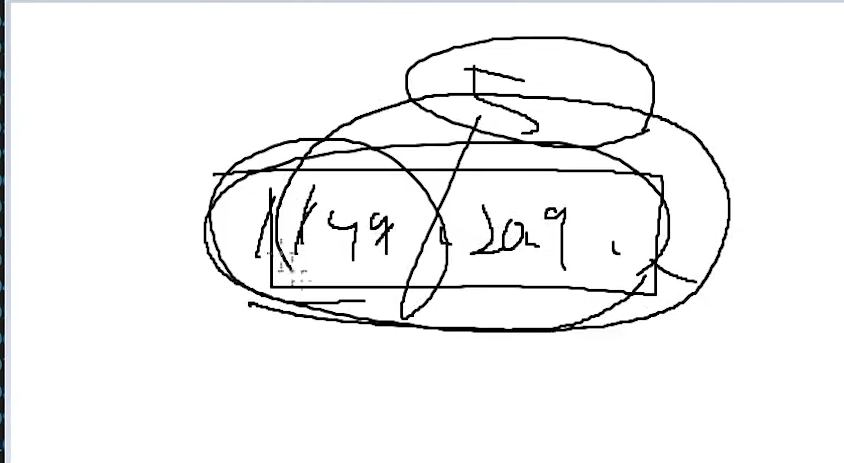
아까 2바이트 방식으로 해석을 하면 '한'이 5만 얼마였는데
1바이트씩 끊어서 보면은 199, 209이다.
wchar_t 쓸꺼임
#include <wchar_t>
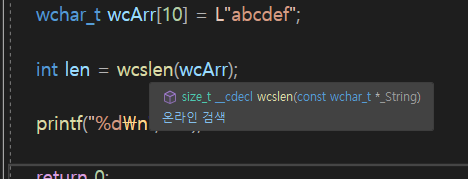
인자로 포인터 타입 요구하는거 보이나??
데이터 초기화 영역
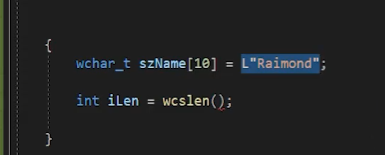
지금 이렇게 szName 에다가 초기화를 했을 때
어제는 ROM영역에 들어간다고 했는데
엄밀히 말하면 데이터 초기화 영역이라는데에 들어간다.
메모리 영역안에 읽기전용 메모리안에, 우리가 작성한 "코드"도 있는 것이고
코드로써 작성한 L"Raimond"가 초기화로써 쓰이고있는데
이런 초기화 값으로 쓰이는 애들은 또 따로 모아 둔다.
메모리 초기화 영역이라고 따로 분류가 된다.
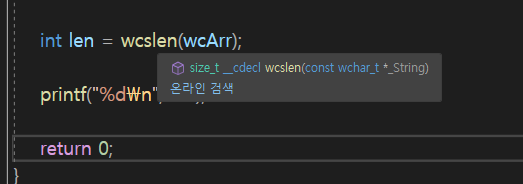
그런데 지금 wchar_t * 로 달라는데 앞에 const붙어 있제?
=> 수정할 수 없는 ROM에서 읽기만 하겠다라고 명시한 부분
const
그래서 wcslen 인자 값을 받을 때 const 포인터로 받은 것이다.
=> 왜? 읽기 전용 메모리는 수정되면 안된다.
그래서 const wchar_t * _String 으로 명시를 해주는 것
(읽기만 하겠다)
