
PushDataFront 구현
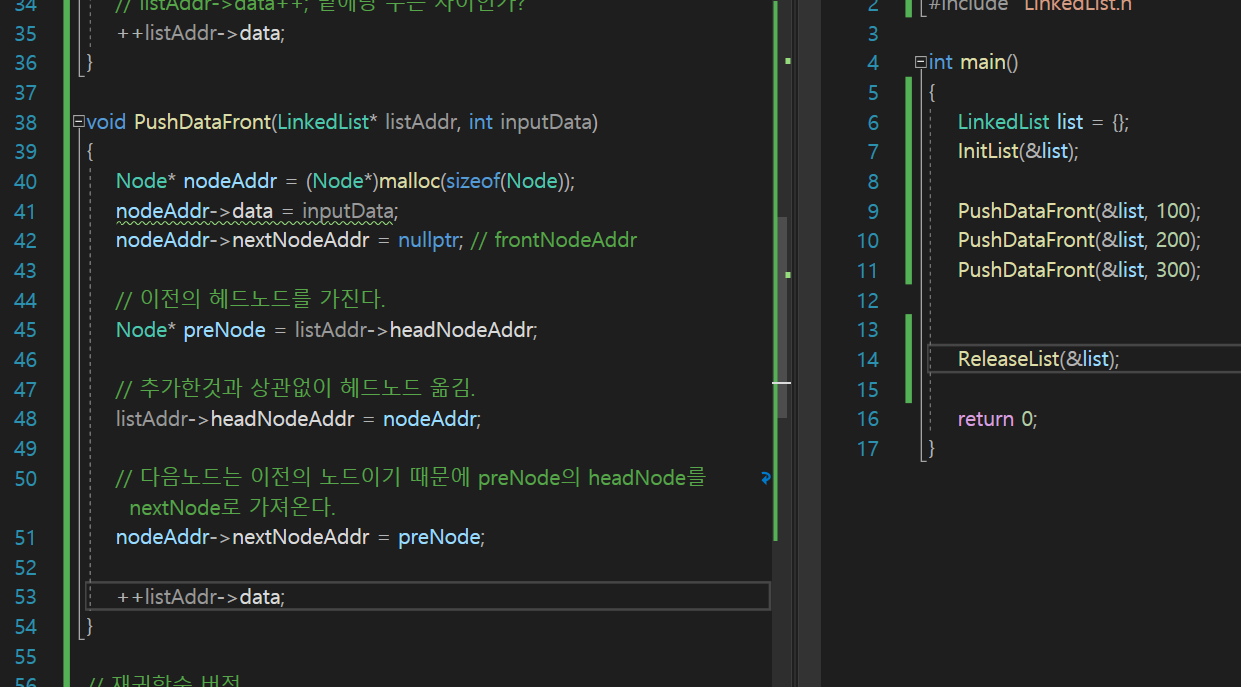
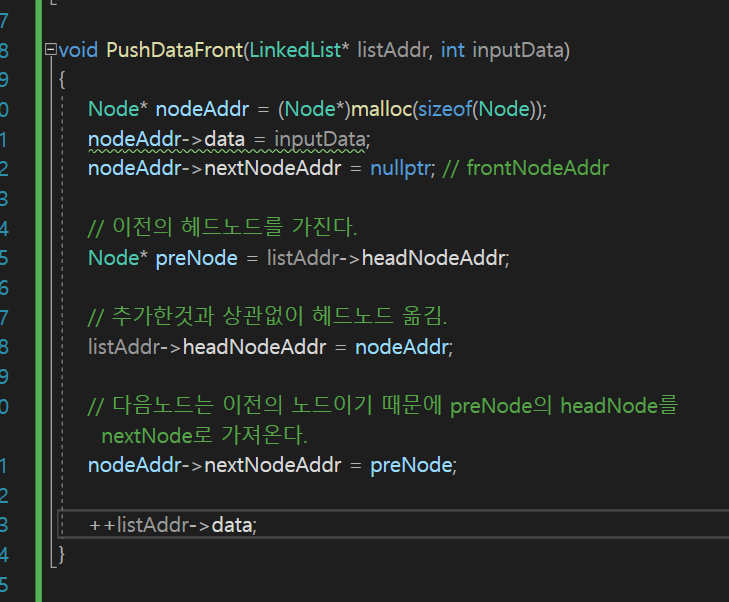
나는 일단 이렇게 구현하였다.
-
현재 malloc()으로 동적 할당한 주소를 nodeAddr이 가지고있는 상태.
-
nodeAddr의 nextNodeAddr은 nullptr이다.
-
헤드를 옮겨야 한다. => 그래야 역으로 타고 올라가니까
-
헤드노드값을 새로 malloc한 주소의 값으로 대체한다. listAddr->headNodeAddr = nodeAddr
-
nextNodeAddr은 (다음 노드는) 이전 노드이다.
-
따라서 preNode의 주소값을 새로 할당해준 nodeAddr의 -> nextNodeAddr로 할당해준다.
수업 PushDataFront
리스트는 데이터를 "노드"라는 단위로 관리를 한다.
포인터로 서로 가르키는 관계만 바꾸면 데이터의 순번을 변경하는데에 있어서 큰 비용이 들지 않는다.
가변배열의 경우


한번에 할당된 공간에 연속되게 데이터를 집어넣음
만약 크기를 정해 놓는다면 1000개라 가정을 할 경우
데이터 복사를 천번 해준다음에 앞에다가 데이터를 넣어주어야한다.
데이터의 수를 n이라고 하고, 복사비용 = a라 하면
복잡도 (학교 알고리즘) ❗
복잡도는 n * a 이다. 이것을 => 시간 복잡도 O(n) 이라한다.
list의 경우
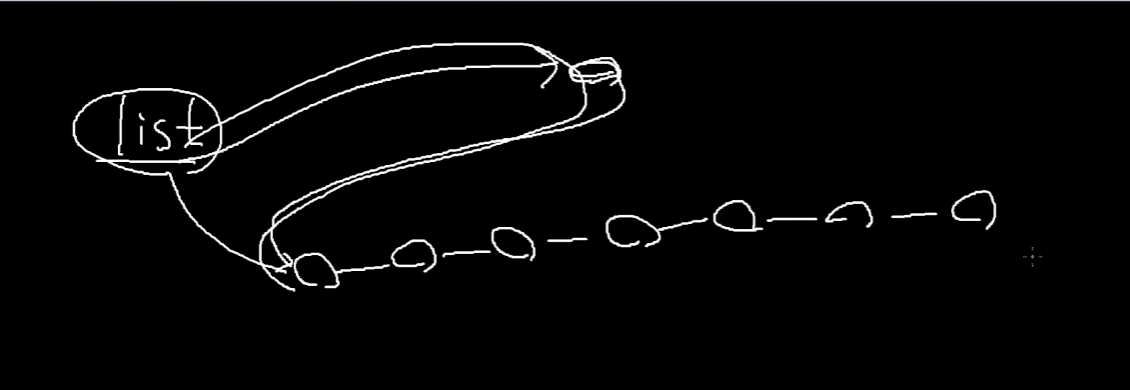
데이터가 아무리 많더라도 PushDataFront, PushDataBack을 통해서 연결이 가능하다.
데이터 넣는 과정이 달라지지 않는다.
데이터의 갯수 n과 무관하게 "고정" 시간 비용이 들 때에는
O(1)의 비용이 든다. == 없는거임
알고리즘에서 가장 빠르다.
자료구조의 목적 ❗
내가 어떤 데이터를 컨테이너 안에 저장 시키고
저장하는 과정에서 맨 앞쪽에 데이터를 채워 넣을 일이 있을 경우
가변배열의 자료구조를 사용하면 안됬다.
"리스트"의 경우에는 데이터를 앞쪽에 집어 넣거나
데이터를 중간에 끼워넣을 떄 유리하다.
장점만 있나?
단점으로 단순이 읽는 속도나 검색이 느리다? => 구체적이지 않다.
리스트가 가변배열에 비해 단점???
시발 모르겠는데?? ❗
오 메모리 구조를 생각하자.
가변배열은 메모리 구조가 "연속적"이다.
반면, 리스트는 힙에 여기 저기 흩뿌려져있는거 포인터로 이어준거임 => 메모리가 연속적이지 않다.
가변배열의 경우
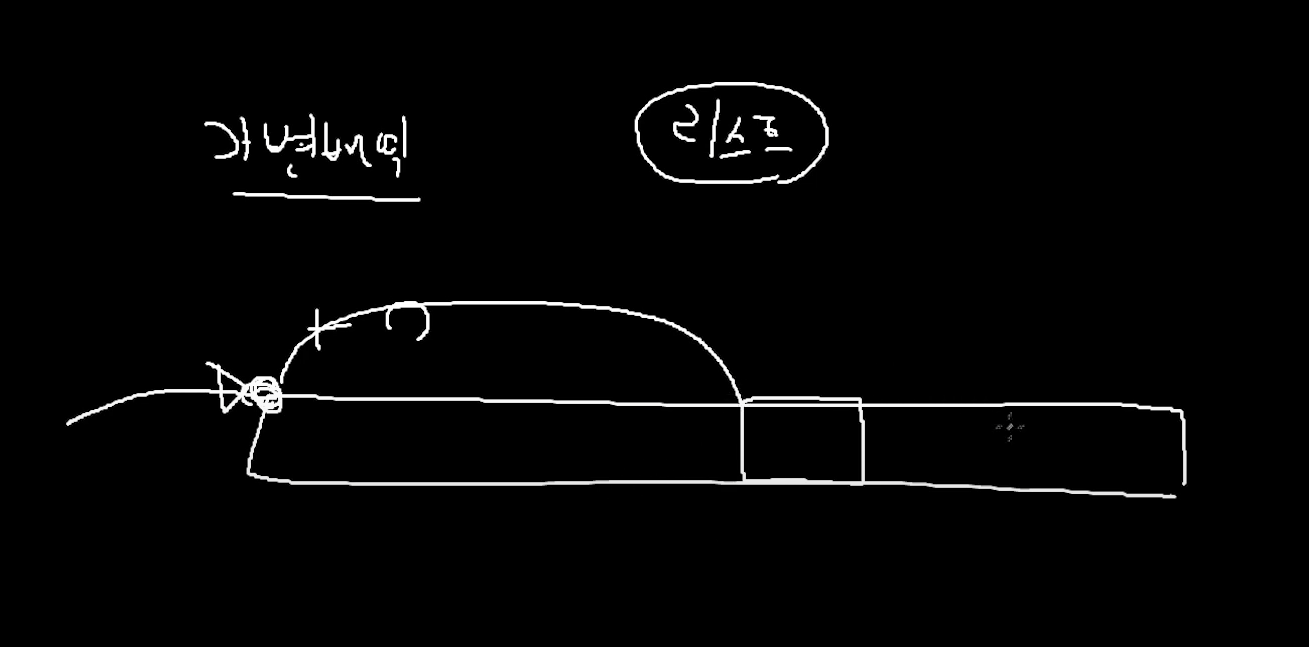
시작주소를 알고있어서 특정 인덱스에 접근을 할 경우
주소 연산을 사용해서 접근이 가능하다.
=> 주소연산으로 한방에 접근 가능
리스트의 경우
주소 연산으로 한방에 갈 수 있나? => 못간다 => 주소가 연속적이지 않아서 => 주소 연산 할 수 없다.
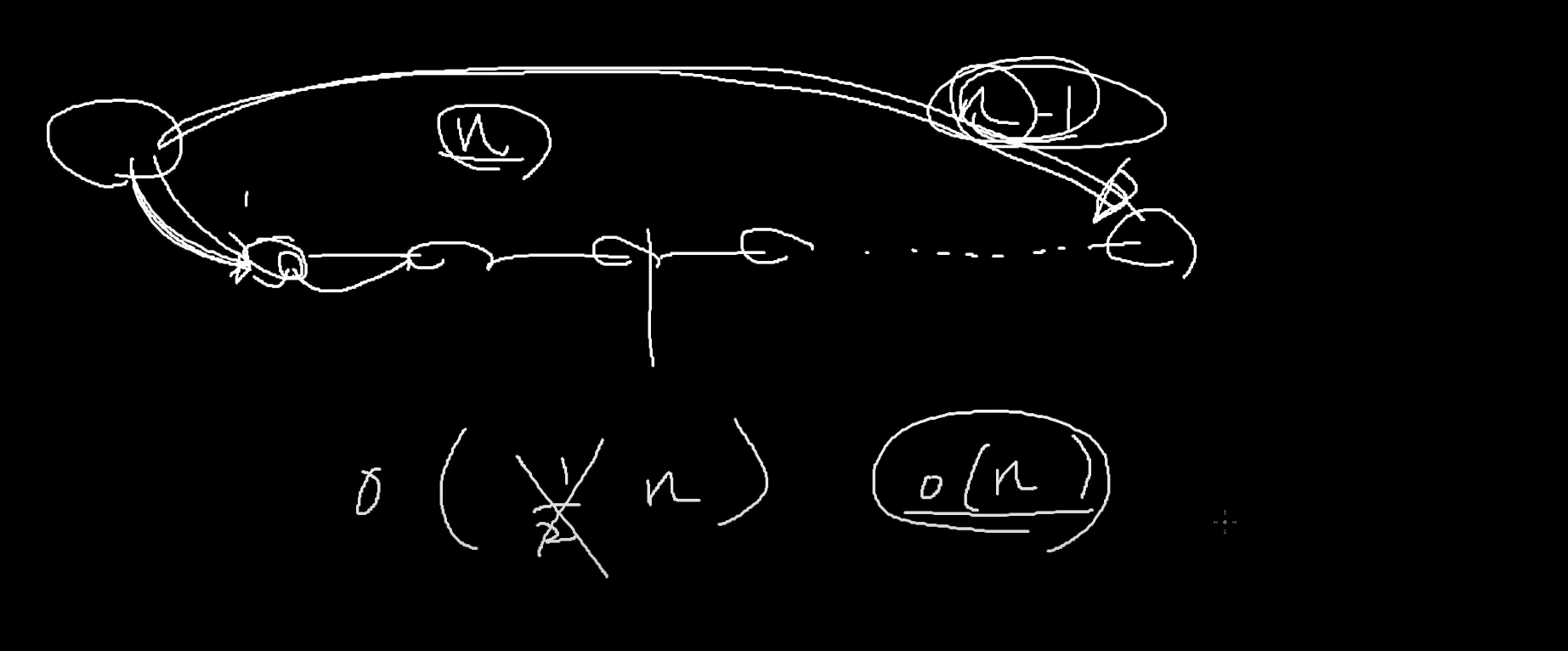
접근할 경우 O(n)이다.
수업에서 Pushfront구현
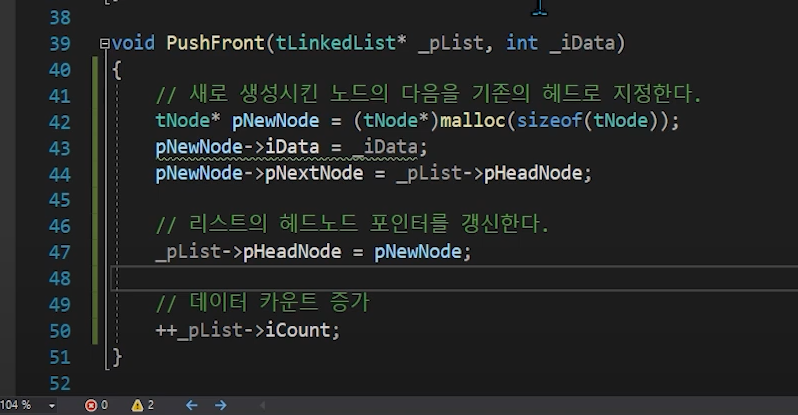
끝
