
C++11기준
map, hash map차이점 설명해봐라.
map은 이진 트리 말하는거고
hash map은 unordered map말하는 거임?
std::map
기본적으로 다 Red-Black Tree이다.(균형 이진 트리)
추가/탐색/삭제 => O(Log N)을 가진다.
hash_map
-
C# vs C++
C# dictionary == C++ map이다?
라고 생각하는 사람들이 있는데 그렇지 않다.
C# dictionary != C++ std::map -
C# dictionary
C# dictionary == C++ unordered_map
즉, C#의 dictionary는 hash_map구조로 되어있다는 점을 기억을 하자. -
hash_map
추가/탐색/삭제 => O(1)
개빠르다..!
근데 항상 상수시간(O(1))은 아니다.
메모리를 내주고 속도를 취한다.
예시
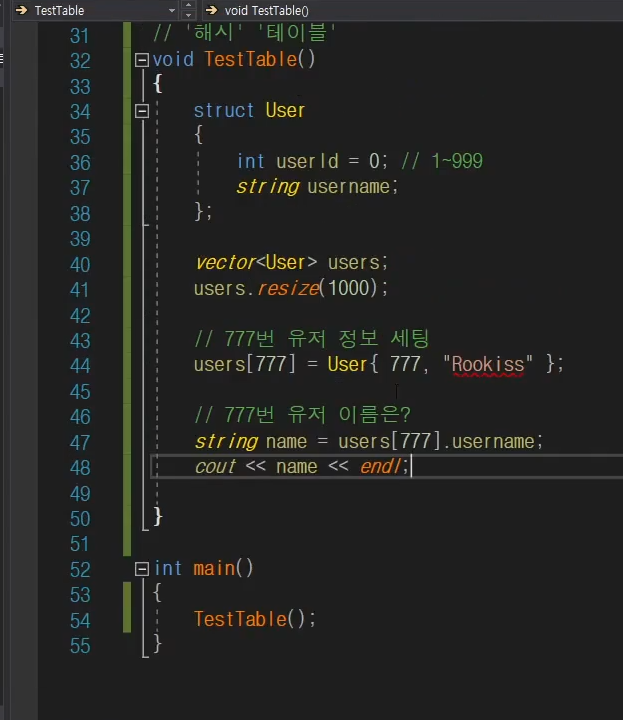
이런식으로 구조체 만들고 동적배열로 User가지고 있는다음 인덱스에 정보 채워넣고 바로 상수시간만에 접근을 해준다.
그냥 뭐 다른 알고리즘 필요없이 제일 빠르다!
여기서 사용하는 777이라는 것을 key로 사용을 한다.
key를 알면 데이터를 상수시간만에 찾을 수 있다.
근데 이것을 실전에서 쓰면 문제가 발생을 한다.
이까지가 "Table"에 대한 내용이다.
문제점 1.
만약에 User가 3억명 이상이라면은??
users.resize(3억);
이거 말이 안됨.그래서 이 문제를 해결하기 위해서 나온게 "Hash"라는 것이다.
Hash란?
해시값을 취한다?
일단 이상한 문자열로 바꿔주는 함수라고 생각하면 된다.
이상한 문자열로 바꿔줄 때 적용되는 알고리즘은 다양함.

뭐 대충 이런식으로 바꿔주고 DB에다가 저장을 한다는 것이다.
그래서 홈페이지 비번 까먹을 때도 인증 단계를 거처서 새 비밀번호를 바꾸는 식으로 간다.
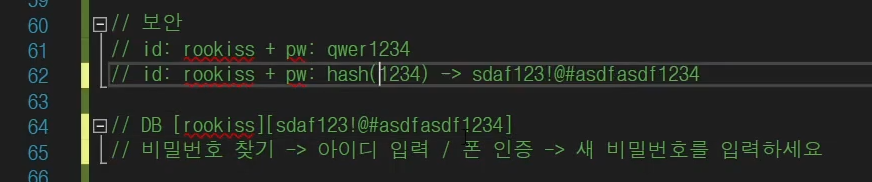
해시값을 역으로 추적하는게 사이트에서도 거의 불가능 하기 때문이다.
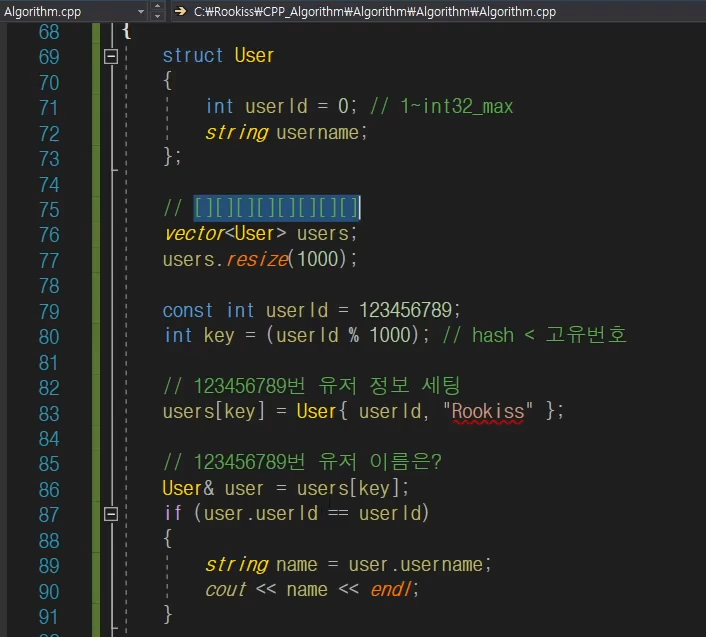
const int userID = 123789;
int key = userID % 1000;
// 이게 임시 해시 알고리즘임.지금은 간단한게 말도 안되는 해쉬알고리즘 1000으로 나눈 나머지를 key값으로 사용을 하여 데이터를 저장할 수는 있지만 실전에서는 사용못한다.
문제점 2.
"충돌"이 발생한다는 문제점이 있다.
즉, key값이 충돌할 때 == 해시값이 충돌을 할 때 문제가 발생을 함.
같은 key가 만들어지니까.
만약 ID가 큰 값을 가지는데
(Id = 1234124343789 이런식 이라면은)
실제 사용하는 데이터가 크지 않을 경우, 충돌이 발생한 자리를 대신해서 다른 빈자리를 찾아 나서면 된다.
대표적으로
-
선형 조사법 (linear probling)
-
이차 조사법 (quadratic probing)
두가지가 있다.
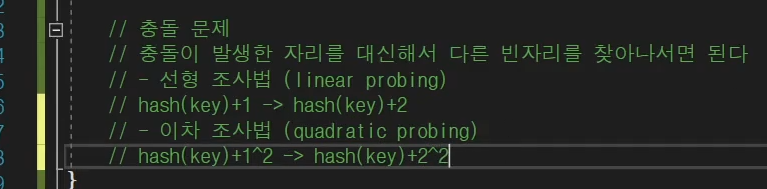
이런식으로 분산을 해서 사용을 해서 충돌을 피한다.
근데 이것도 한계가 있음 -> User가 엄청 늘어날 경우 애초에 bucket이 다 차버릴 수 있어서
"체이닝" 이라는 것을 사용한다.
말그대로 벡터나 연결리스트로 충돌이 되는 키값을 연결해버리는것임. 양꼬치 마냥.
그래서 이차 std::vector를 만들어서 관리를 할 수 있을 것이다.
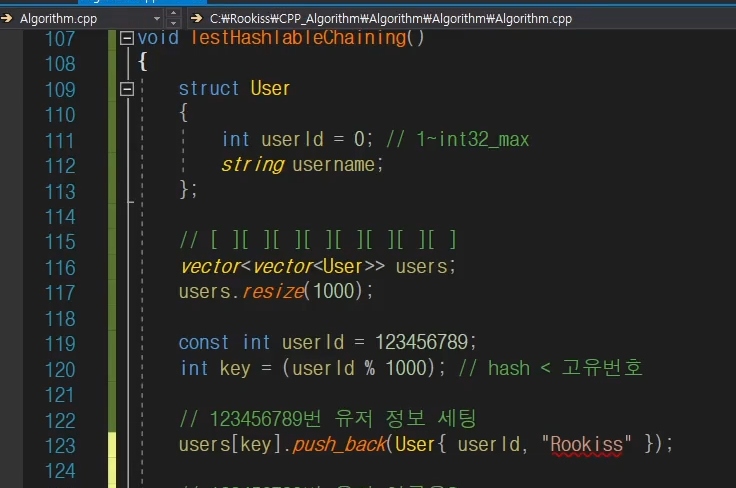
여기서 키값에 접근을 할려면은
버킷에 접근을 해서
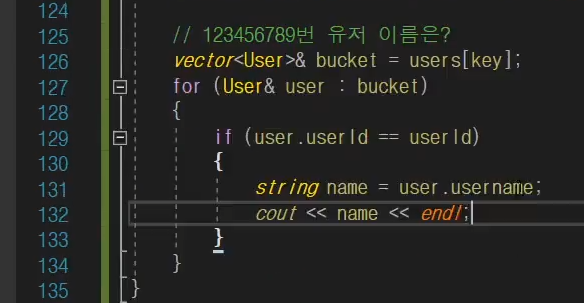
이렇게 찾을 수 있을 것이다.
키 값이 중복이 되더라도
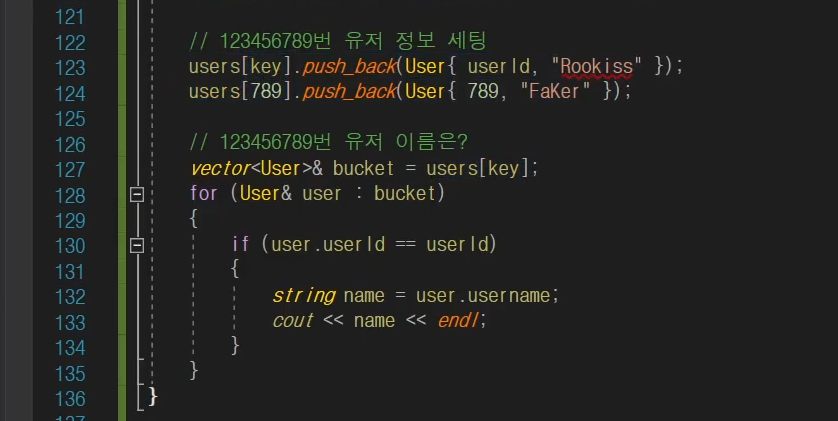
잘 찾을 수 있다.
정리 ❗
면접이나 어디에서 누군가
map이랑 unordered_map(hash_table) 차이점을 설명을 해보라고 하면은
map은 Red-Black Tree이다. 즉, 균형 이진 트리로 만들어져 있어서 트리 구조로 관리를 하고
데이터를 추가/삭제할 때 이진 트리로 동작을 하지만 한쪽으로 쏠리는 것을 방지하는 형태로 되어있다. 또한 시간 복잡도는 O(Log N)을 따른다.
Hash_map은 속도 측면에서는 map보다 훨씬 빠르다. 메모리를 내어주고 속도를 가져가는 방법이기 때문에 해시값의 충돌이 발생하지 않는다면 빨라서 사용하기에 편하다.
