
캐시 라인
Array에 접근하는 방식에 따라 심하게는 100정도의 성능 차이를 보인다.
바로 예를 살펴보면은
// 1번
int arr1[100][100];
for (std::size_t row = 0; row < 100; ++row)
for (std::size_t col = 0; col < 100; ++col)
arr1[col][row] = 10;
for (std::size_t row = 0; row < 100; ++row)
for (std::size_t col = 0; col < 100; ++col)
arr1[col][row] *= 0.5f;
// 2번
int arr2[100][100];
for (std::size_t row = 0; row < 100; ++row)
for (std::size_t col = 0; col < 100; ++col)
arr2[col][row] = 10;
for (std::size_t row = 0; row < 100; ++row)
for (std::size_t col = 0; col < 100; ++col)
arr2[row][col] *= 0.5f;
결론부터 말하자면 1번과 2번중에 2번이 100배 정도 빠르다.
그 이유는 "Cache" 때문이다.
1번 방식이 잘못됬다라는 것은 Cache Line을 전혀 생각하지 않았기 때문이다.
먼저 "캐시"라는 것을 알기 위해
하드웨어 메모리를 먼저 보도록 하겠다.
메모리 종류 ❗
하드웨어 관점에 메모리 종류를 본다면은
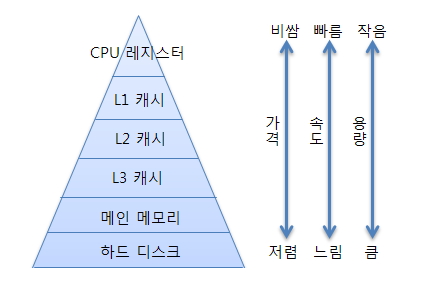
여기서 메인 메모리는 주 기억 장치인 "RAM"을 말한다.

하드웨어 메모리 구조
하드웨어 메모리 구조
레지스터란?
앞서 레지스터에서 배울 땐 CPU내부의 아주 작은 메모리 공간이라고 칭했다. 하지만 CPU 동작원리를 이해하면, 레지스터는 CPU가 요청을 처리하는데 필요한 데이터를 "일시적으로" 저장하는 공간임을 알 수 있다.
1번 방법 접근
아무튼 L3캐시 까지는 CPU안에 들어있다.
그다음 DRAM, SSD순이다.
즉, CPU와 가까울 수록 Access Time이 훨씬 적고 또한 데이터 저장능력도 훨씬 작아진다.
(Computer Architeture를 공부하면된다)
그러면 1번 방법으로 접근을한다고 가정을 하자.
그러면은 컴퓨터 구조는 "Cache Line"이라는 것이 있다.
L1캐시의 하나에 정보가 들어갈 때 캐시 라인만큼의 정보는 같이 딸려들어가는 것이다.
현재 Mordern Computer의 캐시 라인은
64byte정도 되는데
cache access pattern같은 경우에 L1, L2, L3 전부다 다르다.
(intel기준으로 L1 설명할 것이다)
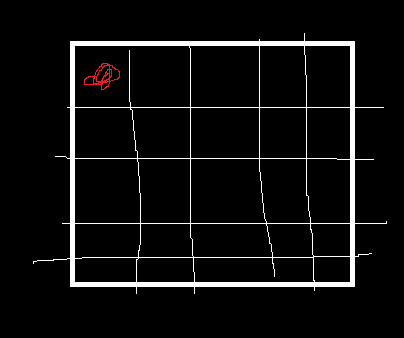
이렇게 2차원 배열이 있을 경우
arr[0][0]에 접근을 하는 경우
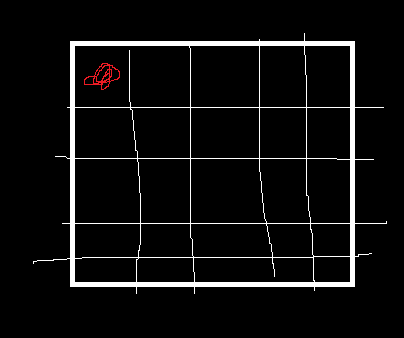
이런식으로 64바이트 만큼 (실제로는 64바이트가 아니지만) 같이 딸려오게 된다는 것이다.
캐시 라인 사용하는 이유 참고
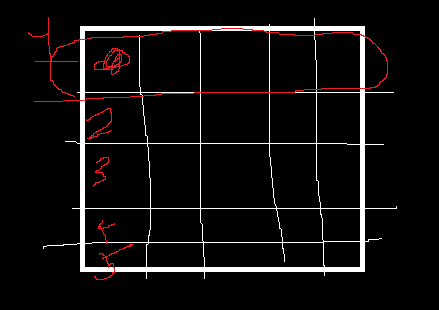
그런데 1번 방법은 현재 1번에 접근한 이후 2번으로 접근을 하는 것이다
그러면 1행의 정보는 L1캐시에 있는 것이 아니라 어디 저기 멀리 정보가 저장이 되어있는 것이다.
그랬을 경우
[1][0]의 데이터(정보)를 가져올 경우
데이터를 가져올려면 CPU가 기다려야한다.
그 시간만큼 손해를 보는 것이다.
그래서 1번 방식이 틀렷다라고 말을 할 수 있는 것이다.
2번 방법 접근
2번방법으로 접근을 할경우 Cache Line덕분에
[0][1]의 정보는 L1캐시에 들어있기 때문에
CPU에서 [0][1]에 접근 하기 위해서는
1 Clock만 필요하다.
여기서 "1 Clock"이란?
정리하자면은
클럭(clock)이란 CPU의 속도를 나타내는 단위입니다. 클럭은 1초 동안 파장이 한 번 움직이는 시간을 의미하는데, 이 시간 동안 처리하는 데이터 양에 따라 CPU의 속도가 달라지게 됩니다.
과거, CPU의 성능을 높이는 가장 편리한 방법은 클럭(동작 주파수)를 올리는 것이었습니다. 하지만 클럭이 높아질수록 발열량과 소비 전력이 커지는 문제가 발생하였습니다. 따라서 최근에는 클럭을 일정 수준으로 유지하는 대신, ‘멀티 코어’나 ‘멀티 스레드’ 같은 방식으로 CPU 성능을 높이고 있습니다. 이를 통해 하나의 CPU로 동시에 처리할 수 있는 연산 개수를 늘려 연산 능력 향상을 꾀하는 것입니다.
즉 1 clock안에 두번째 메모리의 주소에 접근이 가능하다는 것이다.
그리고 열을 계속 이동하다가 다음 행으로갈 때에도 마지막 열에 접근할 때쯤에
컴퓨터가 Memory fatching을 통해 다음 행의 정보를 L1캐시에다가 정보를 대기 시켜놓는다.
따라서 2번의 방법이 1번의 방법보다 100배 빠르다.
정리
이미지나 동영상과 같은 큰 데이터를 다룰 경우
그럴경우에는 항상 Cache Line혹인 L1캐시를 생각을 하고 처리를 해주어야한다.
캐시라인대로 R, W를 하면 훨씬 더 빠른 프로그램을 짤 수 있다.
