
검색 기능 구현
회사에서 검색 기능을 구현하게 되며, 찾게 된 정보를 정렬하는 게시물이다.
거창하게 Elastic Search를 무작정 적용하는 것 보단, 현재 데이터의 수가 적고, 사용자 수가 적기 때문에, 새로운 기능을 구현하는데 더 집중하고 있다. 빠르게 적용해야하기 때문에, 현재 사용하고 있는 Postgresql을 활용한 Full text index에 관한 정보를 찾던 중 좋은 정보를 찾은것 같아 정리하려고 한다.
2018년 10월에 있었던 Postgres 컨퍼런스에서 발표한 PPT 자료를 기반으로 정리하는 내용이다.
Full Text Search란?(FTS)
Full text search
- 쿼리(qeury)에 맞는 문서(document)를 찾아내는 것
- (추가적으로 원할 시) 찾아낸 데이터를 정렬한다.
Typical Search
- 쿼리(query)로부터 모든 단어가 포함된 문서(document)를 찾는다.
- 관련성에 따라 정렬하여 반환한다.
그래서 document가 뭔데?
- Arbitrary text attribute
- 임의의 문자 속성
- Combination of text attributes from the same or different tables (result of join)
- 테이블을 join해서 얻은 데이터들을 조합해서 얻은 텍스트 속성
이렇게 정의되어 있다.
msg (id, lid, subject, body);
lists (lid, list);
SELECT l.list || m.subject || m.body_plain as doc그러니까 위와 같이, 데이터를 불러오거나, 검색하며 생기는 텍스트들을 말한다.
그럼 왜 PostgreSQL로 FTS를 사용해야 하나?
DB의 내용을 외부 확장 검색 엔진을 사용해서 사용할 경우 빠르다는 장점이 있지만, 단점을 강조하고 있다.
- 모든 documents에 인덱스를 적용할 수 없다는 점
- 발표 자료에서는 인덱스 적용이 가능하더라도, 가상의 인덱스라고 한다.
- 복잡한 쿼리를 사용할 수 없다.
- 유지 보수를 계속 해줘야한다.
- 근데 이건 모든 시스템이 다 똑같지 않나..?
- 때로는 인증을 받아야하는 경우도 있다.
- 즉시 검색하는 기능이 없다.
- 새로운 데이터를 DB로 받고, 인덱스를 재정렬해야하기 때문
- 데이터의 일관성을 지원하지 않는다.
사실 대규모 서비스에서 Elastic Search를 기본적으로 사용하고, 이에 따른 인프라적 지식이 더 동반하는것도 사실인것 같긴하다.
이렇게 말하면서 Postgres에서는 DB 검색엔진의 완전히 통합된 기능을 강조한다.
- 트랜잭션
- 동시 접속 가능
- 복구
- 인덱스 사용
- 기능적으로 제공하는 파서, 딕셔너리 등
- 확장 가능성
전통적인 검색 기능
과거 검색 기능은 언어적인 지원 그러니까, 형태소, 단어, 색인 기능, 단어의 시제등을 정리하며 Stop-words(noise-words) 불용어 단어 검색을 방어하게 만들며 문장에 의미가 없는 단어들 에 대한 기능이 제공되지 않는다.
또한 단어의 중요성을 나타내는 중요도에 대한 처리가 없어 검색의 결과가 항상 비슷하다.
--Slow, documents should be seq. scanned
--9.3+ index support of ~* (pg_trgm)
select * from man_lines where man_line ~* '(?:
(?:p(?:ostgres(?:ql)?|g?sql)|sql)) (?:(?:(?:mak|us)e|do|is))';
-- One of (postgresql,sql,postgres,pgsql,psql) space One of (do,is,use,make)FTS 데이터 타입과 operator
두가지를 설명하는데, tsvector, tsquery이다.
tsvector
검색에 최적화된 document 데이터 유형
- Sorted array of lexems
- 정렬된 어휘 배열
- Positional information
- 위치적 정보
- Structural information (importance)
- 구조적 정보
tsquery
boolean과 & | ! ()를 사용하는 쿼리를 위한 문자 데이터
Full text search operator는 결국 아래와 같은 구조를 따른다
tsvector @@ tsquery
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector
@@
'cat & rat':: tsquery;FTS configuration
- 파서가 문장을 한쌍의 토큰과 타입의 형식으로 쪼갠다
- 토큰들은 특정 토큰 타입을 딕셔너리로 사용하는 어휘로 변환한다.
또한 설정의 특징으로는 다음과 같다.
-
확장성
- pluggable한 파서와 딕셔너리
- FTS 설정은 파서와 딕셔너리를 정의할 수 있다
- FTS 설정은 documents와 쿼리 처리에 사용할 수 있다.
\dF{,p,d}[+] [pattern] — psql FTS
- SQL 인터페이스
위의 기본 틀을 따라서 쿼리를 작성한다{CREATE | ALTER | DROP} TEXT SEARCH {CONFIGURATION | DICTIONARY | PARSER}
FTS in PostgreSQL
Document to tsvector
- to_tsvector([cfg], text | json | jsonb)
- cfg — FTS configuration,
- GUC default_text_search_config
- GUC (Grand Unified Configuration) → 쉽게 생각하면 PostgreSQL의 설정 파라미터를 의미
→ 데이터베이스의 성능, 보안, 로깅, 메모리 사용, 연결 설정 등 다양한 동작에 영향을 미친다
select to_tsvector('It is a very long story about true and false');
to_tsvector
---------------------------------------
'fals':10 'long':5 'stori':6 'true':8
(1 row)
select to_tsvector('simple', 'It is a very long story about true and false');
to_tsvector
---------------------------------------------------------------------------------------
'a':3 'about':7 'and':9 'false':10 'is':2 'it':1 'long':5 'story':6 'true':8 'very':4
(1 row)위에서 'It is a very long story about true and false 문장에서 to_tsvector값을 확인한 결과불용어를 제거하고, 단어가 나타난 위치를 표기한다. 또한 자세히 보면 false를 fals로 변환한 것을 볼 수 있는데, 이것은 어간처리가 되어 변형된 것이다.
simple 옵션이 붙자, 모든 문장의 단어들을 나열하고 위치정보를 표기하는 것을 볼 수 있다.
설정되는 cofinguration에 따라 찾는 결과 값이 달라질 수 있다는 것을 의미한다.
simple 옵션은 불용어를 제거하지 않고, 어간도 추출하지 않으며, 입력된 단어를 그대로 검색 벡터에 포함하게 되는 설정이다.
JSON[b] to tsvector
-
json과 jonb의 결과 값은 다르게 나타나진다.
-
JSON
- JSON 데이터 타입은 텍스트 기반
- 데이터가 그대로 저장된다.
- JSON 데이터의 구조는 수정되지 않고, 저장 시 키의 순서가 보존된다.
-
JSONB
- JSONB 데이터 타입은 이진 표현(Binary JSON)으로 저장.
- 이 타입은 JSON 데이터가 저장될 때 더 효율적으로 처리되며, 키의 순서가 자동으로 정렬된다.
- 불필요한 공백은 제거되며, 검색과 같은 작업에서 더 빠른 성능을 제공한다.
-
구체적인 차이점
- 키의 순서:
JSON에서는 키가 원래 순서대로 보존된다.
JSONB에서는 키가 사전 순으로 정렬된다. - 단어 위치:
to_tsvector는 JSON과 JSONB 모두에서 텍스트 검색 벡터를 생성한다.
단어 위치 정보는 데이터의 원래 순서를 반영하기 때문에, JSONB에서는 이 위치 정보가 다르게 나타난다.
- 키의 순서:
-
공백 및 포맷팅:
JSON에서는 공백이 그대로 유지된다.
JSONB에서는 공백이 제거되고, 데이터가 더 최적화된 형태로 저장된다.
select to_tsvector(jb) from (values ('
{
"abstract": "It is a very long story about true and false",
"title": "Peace and War",
"publisher": "Moscow International house"
}
'::json[b])) foo(jb) as tsvector_json[b]
tsvector_json
--------------------------------------------------------------------------------------------
'fals':10 'hous':18 'intern':17 'long':5 'moscow':16 'peac':12 'stori':6 'true':8 'war':14
(1 row)
tsvector_jsonb
--------------------------------------------------------------------------------------------
'fals':14 'hous':18 'intern':17 'long':9 'moscow':16 'peac':1 'stori':10 'true':12 'war':3
(1 row)peac와 war의 위치가 JSON과 JSONB에서 다르게 나타내고 있는데 이는, JSONB에서는 키가 정렬되었기 때문에 peac가 먼저 나오고, 그다음에 war가 나오는 것이다.
반면에, JSON에서는 원래 입력된 순서대로 출력하기 때문에 위의 두 결과가 다르게 나타나게 되는것이다.
따라서 JSONB는 검색과 같은 작업에서 더 효율적이지만, 데이터의 순서와 형식을 유지해야 한다면 JSON을 사용하는 것이 더 적합할 수 있다.
Tsvector editing functions
검색할 때, 순위를 매기기 위해 표시하는 기능도 있다.
setweight(tsvector, «char», text[]
setweight 함수는 tsvector 안의 단어들에 가중치를 부여한다. 가중치는 A, B, C, D로 나뉘며, A가 가장 높은 가중치를 의미한다.
select setweight( to_tsvector('english', '20-th anniversary of PostgreSQL'),
'A', '{postgresql,20}');
setweight
------------------------------------------------
'20':1A 'anniversari':3 'postgresql':5A 'th':2
(1 row)ts_delete(tsvector, text[])
text[] 삭제할 단어들 배열이다.
ts_vector에 들어간 어휘 중 입력된 문자열을 제거하는 것.
select ts_delete( to_tsvector('english', '20-th anniversary of PostgreSQL'),
'{20,postgresql}'::text[]);
ts_delete
------------------------
'anniversari':3 'th':2
(1 row)unnest(tsvector)
unnest(tsvector) 함수는 PostgreSQL에서 tsvector 타입의 데이터를 개별 단어로 분해하여 행 태로 반환하는 함수이다. 이 함수는 텍스트 검색 벡터를 한 줄로 된 단어 목록으로 변환하는 데 사용한다.
unnest 함수는 tsvector 타입을 입력받아 그 안에 있는 각 단어를 개별 행으로 반환한다. 이를 통해 텍스트 검색 벡터의 내용을 보다 쉽게 분석하거나, 다른 쿼리와 결합할 수 있다
select * from unnest( setweight( to_tsvector('english',
'20-th anniversary of PostgreSQL'),'A', '{postgresql,20}'));
| lexeme | positions | weights |
|---|---|---|
| 20 | {1} | {A} |
| anniversari | {3} | {D} |
| postgresql | {5} | {A} |
| th | {2} | {D} |
(4 rows)
이 함수를 활용하여 텍스트 분석을 보다 세밀하게 수행할 수 있으며, 다른 SQL 쿼리와 결합하여 복잡한 검색 및 분석 작업을 수행할 수 있다.
tsvector_to_array(tsvector)
tsvector 타입의 데이터를 배열(text[])로 변환하는 함수array_to_tsvector(text[])
반대도 있다.
select tsvector_to_array( to_tsvector('english',
'20-th anniversary of PostgreSQL'));
tsvector_to_array
--------------------------------
{20,anniversari,postgresql,th}
(1 row)ts_filter(tsvector,text[])
tsvector 데이터 타입에서 특정 단어들만을 필터링하여 남기는 함수이다.
이 함수는 tsvector에 포함된 단어들 중에서 지정된 단어 배열에 포함된 단어들만을 유지하고, 나머지 단어들은 제거한다.
select ts_filter($$'20':2A 'anniversari':4C 'postgresql':1A,6A 'th':3$$::tsvector,
'{C}');
ts_filter
------------------
'anniversari':4C
(1 row)
select ts_filter($$'20':2A 'anniversari':4C 'postgresql':1A,6A 'th':3$$::tsvector,
'{C,A}');
ts_filter
---------------------------------------------
'20':2A 'anniversari':4C 'postgresql':1A,6A
(1 row)특정 단어들만을 남겨두고 나머지를 제거하고자 할 때 유용하다. 이를 통해 텍스트 검색에서 원하는 키워드만을 강조하거나, 검색 결과를 필터링할 수 있다. 예를 들어, 특정 중요 키워드들만을 검색하거나 분석할 때 이 함수를 사용하여 효율적으로 결과를 도출할 수 있다.
- 아래 이미지는 발표 자료에 있는 PostgreSQL에서 to_tsvector 함수가 작동하는 과정을 나타낸 흐름도이다.
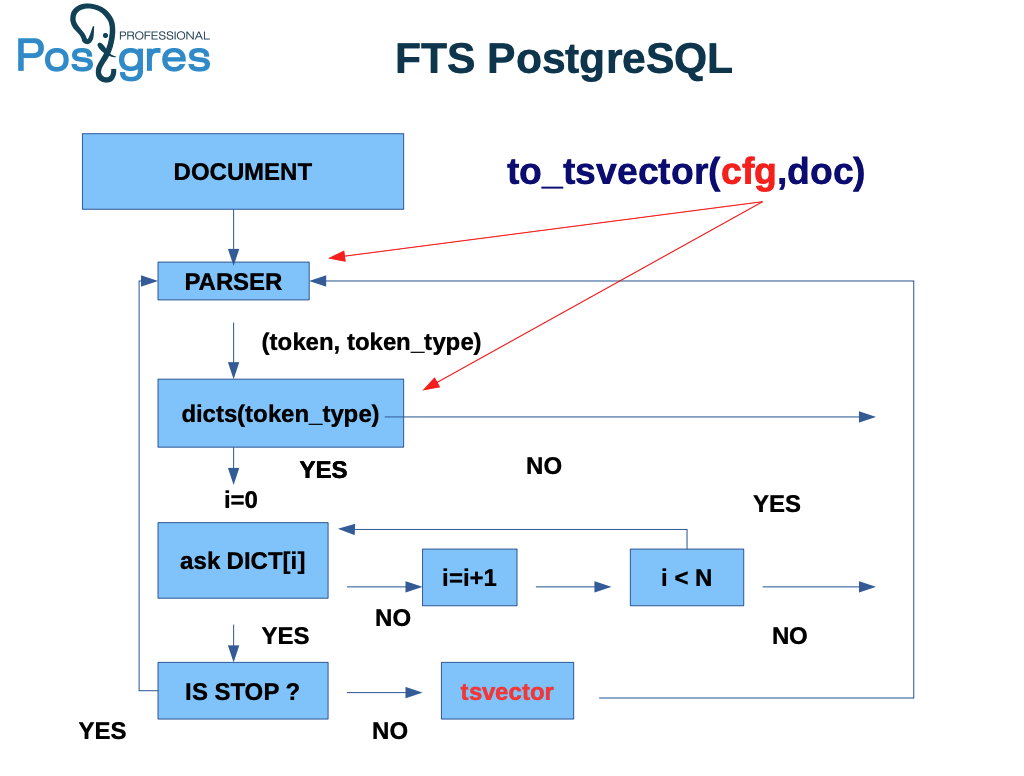
흐름도 해석
- DOCUMENT 입력:
시작점은 문서(DOCUMENT)이다. 이 문서는 to_tsvector 함수의 두 번째 인수로 입력된다.
- PARSER 단계:
문서가 파서(PARSER)를 통과한다. 파서는 문서를 개별 단어(토큰)와 해당 단어의 유형(token_type)으로 분리한다.
이 과정에서 텍스트가 의미 있는 단어들로 분리되며, 각 단어는 그 특성에 따라 특정한 유형이 할당된다.
- 토큰 처리:
파서에서 생성된 (token, token_type) 쌍이 dicts(token_type)로 전달된다.
여기서 dicts(token_type)은 지정된 단어 유형에 따라 해당 단어가 특정 사전에 속하는지 확인하는 단계이다.
cfg (configuration)는 to_tsvector 함수의 첫 번째 인수로, 텍스트의 분석 방식을 결정하는 설정이다. 이 설정은 사전, 불용어(Stop words) 목록, 어간 추출(stemming) 규칙 등을 정의한다.
- 사전 조회:
각 단어가 사전에 있는지 확인하기 위해 반복문이 실행된다 (i=0으로 시작).
ask DICT[i]: 사전(DICT[i])에 해당 단어가 있는지 묻는다.
YES: 단어가 사전에 존재한다면, 단어가 불용어(STOP)인지 확인한다.
NO: 단어가 사전에 없으면 다음 사전을 조회하기 위해 i=i+1로 인덱스를 증가시킨다. 이 과정은 사용 가능한 사전의 수(N)보다 작은 경우 반복된다.
- STOP 검사:
단어가 사전에 존재하면, 그 단어가 불용어(검색에서 무시될 단어)인지 확인한다.
YES: 불용어인 경우 해당 단어는 무시되고, 다음 단어로 넘어간다.
NO: 불용어가 아니면 해당 단어가 tsvector에 추가된다.
- tsvector 생성:
불용어로 판별되지 않은 모든 단어들은 최종적으로 tsvector에 포함된다.
이 과정이 모든 단어에 대해 반복되며, 최종적으로 tsvector가 반환된다.

이 그림은 PostgreSQL의 텍스트 검색 파서(parser)가 문서를 분석하여 다양한 토큰(token)으로 분해하는 과정을 설명하고 있다. parser는 문서를 입력받아 특정 규칙에 따라 단어(토큰)들을 식별하고, 각 토큰에 대해 고유한 토큰 유형(token type)을 할당한다.
주요 구성 요소 설명
- 토큰(token):
문서가 파싱될 때 생성되는 개별적인 단위이다. 문장의 단어, 숫자, URL, 이메일 주소 등 다양한 형태의 텍스트가 토큰으로 변환된다.
- 토큰 유형(token type):
각 토큰에는 특정한 유형이 할당된다. 이 유형은 토큰이 어떤 종류의 텍스트인지 설명해준다. 예를 들어, 일반 단어, 이메일 주소, 숫자 등이 있다.
- ts_token_type('default'):
그림에 나온 쿼리는 ts_token_type('default') 함수를 사용하여 PostgreSQL의 기본 파서가 인식하는 모든 토큰 유형을 출력한다.
이 함수는 각 토큰 유형에 대한 고유 ID (tokid), 별칭 (alias), 설명 (description)을 반환한다.
주요 토큰 유형
asciiword (ID: 1):
ASCII 문자로 이루어진 단어를 의미한다. 예를 들어, "word"는 이 유형으로 분류된다.
word (ID: 2):
모든 문자로 이루어진 단어이다. 문자와 숫자가 포함될 수 있으며, 비-ASCII 문자도 포함된다.
numword (ID: 3):
문자와 숫자가 섞인 단어이다. 예를 들어, "abc123"과 같은 단어가 해당된다.
email (ID: 4):
이메일 주소를 나타낸다. 예를 들어, "user@example.com"은 이 유형으로 분류된다.
url (ID: 5):
URL을 나타낸다. 예를 들어, "http://example.com"과 같은 텍스트가 해당된다.
host (ID: 6):
호스트 이름이나 도메인 이름을 나타낸다. 예를 들어, "example.com"은 이 유형으로 분류된다.
sfloat (ID: 7):
과학적 표기법으로 작성된 숫자를 나타낸다. 예를 들어, "1.23e10"과 같은 숫자가 해당된다.
version (ID: 8):
버전 번호를 나타낸다. 예를 들어, "v1.0"과 같은 텍스트가 해당된다.
hword_numpart (ID: 9):
하이픈으로 연결된 단어와 숫자가 혼합된 부분이다. 예를 들어, "word-123"에서 "word-123"이 해당된다.
hword_part (ID: 10):
하이픈으로 연결된 단어의 일부이다. 예를 들어, "long-term"에서 "long"과 "term"이 해당된다.
hword_asciipart (ID: 11):
하이픈으로 연결된 단어 중에서 ASCII 문자로만 이루어진 부분을 나타낸다.
예시: "ascii-only"라는 단어에서 "ascii"와 "only"가 각각 hword_asciipart로 분류된다.
blank (ID: 12):
공백이나 스페이스 기호를 나타낸다. 텍스트에서 공백은 의미가 없으므로, 이 유형은 보통 무시된다.
텍스트에서 단어 사이의 공백이 이에 해당한다.
tag (ID: 13):
XML 태그를 나타낸다.
와 같은 XML 태그가 이에 해당한다.
protocol (ID: 14):
프로토콜 헤더를 나타낸다.
"http", "https", "ftp"와 같은 프로토콜 식별자가 이에 해당한다.
numhword (ID: 15):
하이픈으로 연결된 단어와 숫자가 섞인 부분을 나타낸다.
"model-1234"라는 텍스트에서 "model-1234"가 이에 해당한다.
ascii_hword (ID: 16):
ASCII 문자로 이루어진 하이픈으로 연결된 단어를 나타낸다.
"ascii-word"라는 텍스트에서 "ascii"와 "word"가 이에 해당한다.
hword (ID: 17):
하이픈으로 연결된 단어를 나타낸다.
"long-term"과 같은 단어가 이에 해당한다.
url_path (ID: 18):
URL 경로를 나타낸다.
"http://example.com/path/to/resource"에서 "/path/to/resource"가 이에 해당한다.
file (ID: 19):
설명: 파일 이름이나 경로를 나타낸다.
예시: "/usr/local/bin/file.txt"와 같은 파일 경로나 이름이 이에 해당한다.
float (ID: 20):
소수점이 포함된 숫자를 나타낸다.
"3.14159"와 같은 소수점 숫자가 이에 해당한다.
int (ID: 21):
부호 있는 정수를 나타낸다.
"-1234"와 같은 정수가 이에 해당한다.
uint (ID: 22):
부호 없는 정수를 나타낸다.
"1234"와 같은 양의 정수가 이에 해당한다.
entity (ID: 23):
XML 엔터티를 나타낸다. 엔터티는 특정 문자 또는 기호를 참조하기 위해 사용되는 특수한 구문이다.
"&"는 "&" 기호를 나타내는 XML 엔터티로, 이에 해당한다.
출처:
Postgresql 2018 컨퍼런스 FTS 발표자료
