Lecture | CS50
🦵🏻 들어가기 전

컴퓨터 과학은 문제 해결에 대한 학문이다. 문제 해결은 입력을 전달받아 출력을 만들어내는 과정이다. 그 중간에 있는 과정이 컴퓨터 과학이다.
👩🏻💻
1. 2진법
입력과 출력을 표현하기 위해선 모두가 동의할 약속(표준)이 필요하다. 컴퓨터 과학의 가장 첫 번째 개념은 어떻게 표현하는 지에 대한 표현 방법이다.
1.1. 10진법 vs 2진법
우리가 일상에서 사용하는 0-9 총 10개의 기호로 표현하는 것은 10진법이다. 하지만 컴퓨터에는 이렇게 많은 숫자가 없다. 오로지 0과 1로만 데이터를 표현하다. 이처럼 0과 1로만 표현하는 것을 2진법이라고 한다.
컴퓨터는 0과 1로 숫자 뿐만 아니라 글자, 사진, 영상, 소리 등을 저장할 수 있다. 어떻게 이것이 가능할까?

우리는 123이라는 숫자를 보고, '백이십삼'으로 읽는다. 1을 백의자리, 2를 십의자리, 3을 일의자리로 보기 때문이다. 이러한 표현에 대한 약속이 있기 때문에 이 과정이 자연스럽다. 10진법에서는 자리수를 10의 거듭제곱으로 표현한다.

비슷하게 2진법에서는 두 개의 숫자만 있으므로, 각 자리수가 2의 거듭제곱을 의미한다. 따라서, 2진법에서 100은 2²x1 + 2¹x0 + 1x0 = 4이다.
2진법은 전기를 통해 연산하는, 즉 전기를 켜고 끄는 방식으로 작동하는 컴퓨터에 적합한 방법이다. 컴퓨터에는 굉장히 많은 스위치(트렌지스터)가 있고 on/off 상태를 통해 0과 1을 표현한다.
1.2. 비트
컴퓨터는 2진법에서 하나의 자릿수를 표현하는 단위를 비트(bit)라고 한다. 이진 숫자라는 뜻을 가진 binary digit의 줄임말이며, 0과 1, 두 가지 값만 가질 수 있는 측정 단위이다. 디지털 데이터를 여러 비트로 나타냄으로써 많은 양의 정보를 저장할 수 있다. 또한, 저장되어 있는 데이터를 수정하기 위해 비트에 수학적 연산을 수행할 수 있다.
1.3. 비트열

하나의 비트는 0과 1 두 가지의 값만 저장할 수 있다. 컴퓨터 내부에서 물리적으로 표현될 때는, 켜고 끌 수 있는 스위치라고 생각할 수 있다. 하나의 비트로는 많은 양의 데이터를 나타낼 수 없다. 따라서, 여러 숫자 조합을 나타내기 위해 비트열을 사용한다.

바이트는 여덟 개의 비트가 모여 만들어진 것이다. 비트 하나가 0과 1로 표현될 수 있기 때문에 2^8 = 256개의 서로 다른 바이트가 존재할 수 있다.
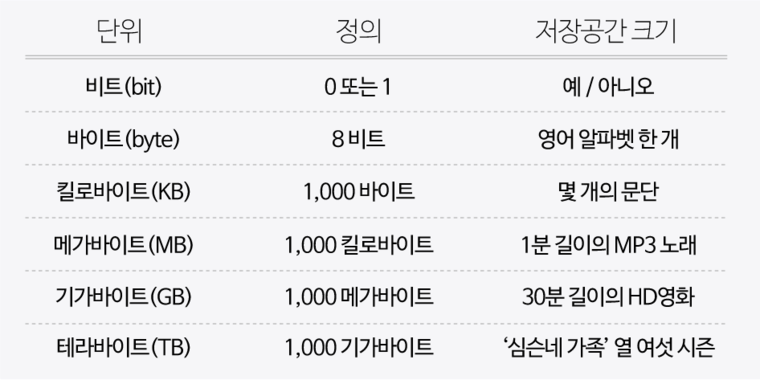
바이트가 모이면 더 큰 단위가 될 수 있다. 킬로바이트는 1,000 바이트, 메가바이트는 1,000 킬로바이트(100만 바이트), 기가바이트는 1,000 메가바이트(10억 바이트)이다. 테라바이트는 1,000 기가바이트(1조 바이트)이며, 심지어 페타바이트와 엑사바이트와 같은 더 큰 단위도 존재한다.
2. 정보의 표현
2.1. 문자의 표현
컴퓨터는 스위치를 on/off 하면서 숫자를 표현할 수 있다. 그럼 과연 문자는 어떻게 표현할까? 문자를 숫자로 표현할 수 있도록 정해진 약속(표준)이 있다.
2.2. 아스키코드 ASCII

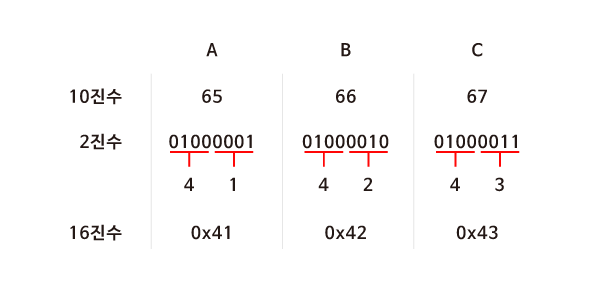
- 총 128개의 부호로 정의되어 있다. 가령, 알파벳 A는 10진법으로 65이다. 이진법으로 표현하면 1000001이다.
- 아스키코드는 7자리 수의 이진법까지 있고, 대문자와 소문자이 차이는 2^5자리만 다르다. 그래서 2^5만큼 숫자 크기 차이가 난다. 대문자가 0이고 소문자가 1이 들어간다.
2.3. 유니코드
- 더 많은 비트를 사용하여 아스키코드에서 사용할 수 없는 다양한 다른 문자들도 표현 가능하도록 지원한다.
- 😂 이런 이모티콘까지 표현할 수 있게 해주었다. 10진법으로 128,514이고 2진법으로는 11111011000000010이다.
2.4. 그림, 영상, 음악의 표현
그림도 역시 숫자로 표현할 수 있다. 우리가 스크린을 통해 보는 그림을 자세히 살펴 보면 수많은 작은 점들이 빨간색, 초록색, 파란색을 띄고 있다. 이런 작은 점을 픽셀이라고 부른다.
각각의 픽셀은 세 가지 색을 서로 다른 비율로 조합하여 특정한 색을 갖게 된다. 예를 들어 빨간색 72, 초록색 72, 파란색 33을 섞게 되면 노란색이 되는 것과 같은 방식이다.
이 숫자들을 표현하는 방식을 RGB(Red, Green, Blue)라고 한다.
영상 또한 수많은 그림을 빠르게 연속적으로 이어 붙여놓은 것이기 때문에 숫자로 표현이 가능하다. 음악도 마찬가지로 각 음표를 숫자로 표현할 수 있다.
3. 알고리즘 - 1
숫자, 글자, 색깔 등을 컴퓨터가 이해할 수 있는 2진법으로 표현하는 것은 입력에 해당한다. 어떻게 입력에서 출력을 얻을 수 있을까?
알고리즘은 입력에서 받은 자료를 출력형태로 만드는 처리과정이다.
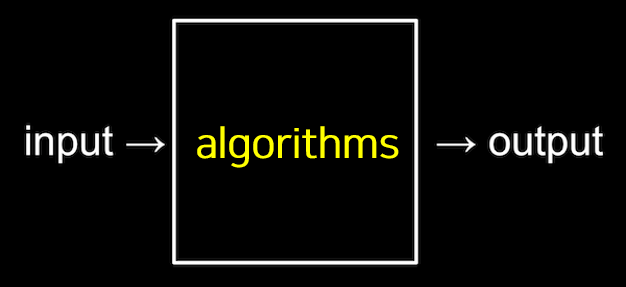
- 입력값을 출력값의 형태로 바꾸기 위해 수행되어야 하는 명령들에 대한 규칙들의 순서적 나열이다.
- 출력값이 같더라도 알고리즘에 따라 출력까지의 시간이 다를 수 있다.
3.1. 정확하고 효율적인 알고리즘
알고리즘을 평가할 때는 정확성도 중요하지만, 효율성도 중요하다. 작업을 완료하기까지 얼마나 시간과 노력을 덜 들일 수 있는지에 대한 것이다.
전화번호부에서 Mike Smith를 찾는 일을 한다고 가정해보자.
- 한 페이지 한 페이지를 넘겨본다.
- 두 페이지씩 넘겨본다.
- 전화번호부의 가운데를 편다. 찾는 이름이 없는 절반은 버린다. (반복)
3.2. 의사코드
컴퓨터가 수행할 작업을 프로그램 언어가 아니라 사람이 사용하는 언어로 알고리즘의 논리적 절차를 작성한 코드이다.
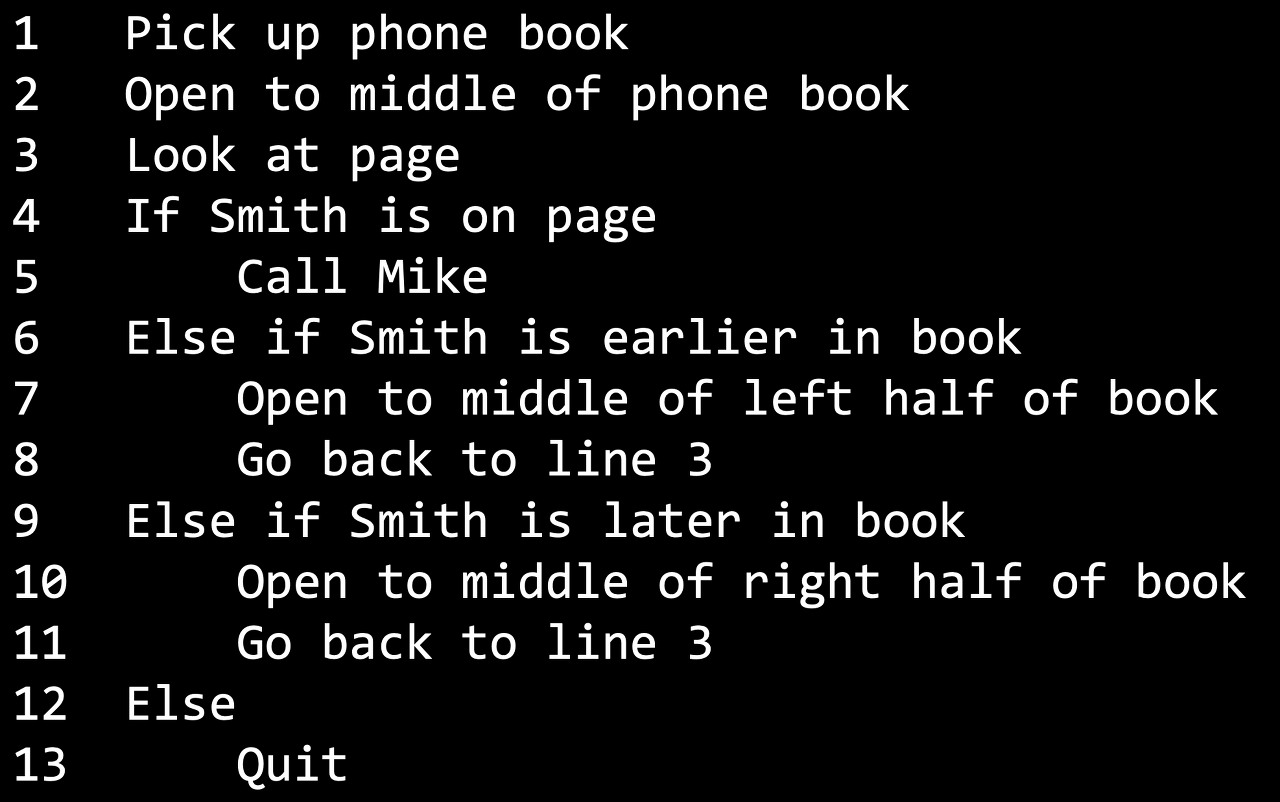
- 함수는
컴퓨터에게 무엇을 할지 알려주는 동사이다. - 조건은
여러 선택지 중 하나를 고르는 것이다. - 결정을 내리기 위한 질문이 필요한데, 이것을 불리언이라고 한다.
답이 예/아니오로 나오는 질문이다. - 루프는
뭔가를 계속해서 반복하는 순환이다.
의사 코드에 위에 설명된 모든 구성요소들이 들어있다.
3.3. 여러분의 뇌는 알고리즘을 풀 수 있다.
알고리즘은 순서대로 문제를 풀기 위해 지시 절차 모음이다. 알고리즘은 컴퓨터에 의해 실행되지만 인간도 알고리즘을 갖고 있다. 예를 들어, 방 안에 사람을 세어보자.
1)
let N = 0
for each eprson in room
Set N = N + 11번째 줄 N은 변수의 초기값을 0으로 설정한 것이고, 두 번째 줄은 루프의 시작이다. 루프는 연속적인 절차를 여러 번 반복하는 것을 뜻한다. 3번째 줄의 들여쓰기는 반복될 것임을 의미한다.
2)
let N = 0
for each pair of people in room
Set N = N + 2
if 1 person remain then
Set N = N + 1두 번째 코드는 2명씩 세어서 훨씬 효율적이지만 버그가 있다. 방 안에 있는 사람이 홀수인 경우가 문제다. 그래서 하나의 조건을 도입했는데, 다른 표현으로는 곁가지(branch)라고 한다. 이렇게 3의 배수, 4의 배수로도 사람을 셀 수 있다.
결론적으로, 알고리즘은 문제를 풀기 위한 지시의 모음이다.
4. 스크래치
4.1. 소개
알고리즘을 구성하는 요소로는 함수, 조건, 불리언 표현, 루프 등이 있다. 스크래치는 그래픽 프로그래밍 언어로 블록을 옮겨 붙여서 알고리즘을 만들 수 있다. 화면 왼 편에는 함수, 변수 등을 나타내는 퍼즐 조각이 있고 화면 중간으로 옮길 수 있다. 오른쪽에는 알고리즘 결과를 보여준다.
블록에 따라 컴퓨터가 수행하는 일의 종류가 달라진다. 하나의 블록은 블랙 박스의 역할을 하게 된다. (컴퓨터는 입력이 주어졌을 때, 블랙 박스를 거쳐 출력이 된다.)
4.2. 변수와 루프/조건문
변수를 사용하면 정보를 저장하고 다시 재사용할 수 있다. 조건문에서는 참/거짓 값을 가지는 불리언 변수를 사용한다.
- repeat until 방식에서 혼동했던 부분
- if에서 loop를 기대했던 부분
5. C 기초
C는 아주 오래되고 전통적인 순수 텍스트 기반의 언어다.

int main(void): 프로그램의 시작점{}: 우리가 작성할 코드는 모두 이 안에 넣는다printf(""): 스크래치에서의 say라는 함수는 없고, 화면에 문자를 보여주는 역할을 하는 출력함수가 있다. 언제나 텍스트는 쌍따옴표로 감싸야 한다. 그리고 문장에 마침표를 찍듯이 세미콜론을 붙여야 한다.\n: 줄바꿈 기능#incldue<stdio.h>: stdio.h라는 파일 안에 미리 작성된 함수들에 접근할 수 있도록 한다.파일이름.c: c로 작성할 코드를 저장할 때 수동으로 확장자를 붙여줘야 한다.
5.1. 컴파일러
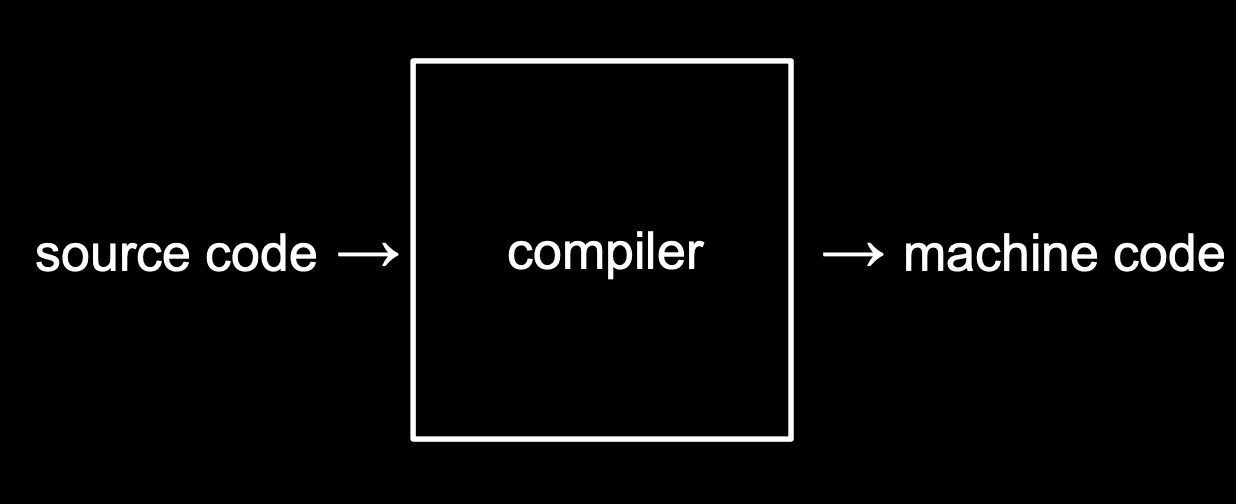
우리가 작성한 코드는 소스코드라고 불린다. 이를 2진수로 작성된 머신 코드로 변환해야 컴퓨터가 이해할 수 있는데, 이 작업을 해주는 프로그램을 컴파일러라고 한다.
clang hello.c: clang이라는 컴파일러로 hello.c 코드를 컴파일하라는 의미다../a.out: 지금 있는 현재 폴더에 a.out 프로그램을 실행하라는 뜻이다.//or/* */: 주석으로 컴파일러에 의해 완전히 무시된다.ls: 현재 폴더에 있는 파일 리스트를 보여준다rm: 삭제하라는 명령어*: 실행가능한 머신코드라는 뜻clang -o hello hello.c: 다른 이름으로 파일 변경하기- /명령어 프롬프트도 마우스와 그래픽 UI로 할 수 있는 모든 일을 할 수 있다.
5.2. 문자열
string answer = get_string("what's your name?\n");할당연산자 =오른쪽에 있는 것을 왼쪽에 지정한다는 뜻이다. 우리가 일반적으로 사용하는 '같다' 등호와는 다르다.- 변수명은 마음대로 해도 된다. 위의 String은 형식지정자로 answer에 들어갈 것이 문자열이라고 알려주는 역할을 한다. 데이터의 종류를 명시하는 것이다.
- get_string 함수가 받아온 사용자의 입력값을 answer라는 변수에 저장한다는 의미다.
printf("hello, %s\n", answer);- printf는 화면상에 출력할 때 사용하는 함수이고, 괄호를 쓴다. 괄호 안에는 프로그래밍에서 인자 혹은 매개 변수라고하는 우리의 입력이 들어간다.
- string의 첫 글자를 따서 %s 문자열 인자를 받는다고 알려준다. 그리고 쉼표를 찍고 오른편에 변수명을 넣는다. 여러 개의 인자를 받을 수도 있고 그렇다면 쉼표로 구분해줘야한다.
%s: 화면 상에 출력하고자 하는 구절이나 문장을 적는데 그 값이 뭔지는 아직 모른다면 %와 문자열을 의미하는 s를 적어 형식지정자를 사용한다.
$make string- clang 명령어를 사용하는 대신 편리하게 make 프로그램을 활용할 수 있다.
#include <cs50.h>- string / get_string 함수를 가져오기 위해서 cs50.h 파일을 포함시키는 코드다.
5.3. 조건문과 루프
조건문
int i = 0; // 변수값은 정수이고 변수명은 i이며 그 값에 0을 저장(초기화)
i++; // 변수의 값을 1씩 증가시킨다. i = i + 1; 혹은 i += 1;로도 표현한다.if(x<y){
printf("x is less than y\n");
}else{
printf("x is not less than y\n");
}- 괄호 안에 조건이 들어가고 참이면 {}에 수행하고자 하는 작업이 들어간다. 조건이 거짓이면 else{}에 들어간 작업이 수행된다.
if(x<y){
printf("x is less than y\n");
}else if(x > y)
{
printf("x is more than y\n");
}else(x == y){
printf("x is equal to y")
}- 마지막 else if 에서 if 뒤에는 생략되어도 된다. 왜냐하면 위의 두가지 경우의 수가 참이 아니라면 남은 가능성은 하나 밖에 없기 때문이다.
- =는 오른쪽에서 왼쪽 방향으로 할당하는 연산자고, == 가 우리가 아는 '같다'의 의미를 가진다.
루프
스크래치에서 forever/repeat n 블록을 통해서 수행했었다. 무언가를 계속 반복하는 것이다. c에서는 while/for를 통해서 루프를 구현할 수 있다.
while(true)
{
printf("hello, world\n");
}- while에 들어간 조건문이 언제나 참이므로 무한루프되는 코드다.
int i = 0;
while(i < 50)
{
printf("hello, world\n");
i++;
}- i는 0으로 설정
- 50보다 작은가?
- TRUE -> 출력을 실행 -> i는 1이 증가한다.
- 2로 돌아가 반복한다. i는 50보다 작은가?
- FALSE -> 종료
- 결과적으로, 50번 반복하는 코드가 된다.
for(int i = 0; i < 50 ; i++)
{
pinrtf("hello, world\n");
}- for(변수 초기화; 변수 조건; 변수 증가)에 해당하는 코드를 넣는 것. while보다 훨씬 코드가 간단해졌음을 알 수 있다.
👀 에러 메세지를 읽을 때 가장 첫 번째 메세지를 읽어봐라. 몇 번째 라인에서 에러가 발생했는지도 알려준다.
5.4. 자료형, 형식지정자, 연산자
변수의 데이터 타입(자료형)
변수를 선언할 때 데이터 값의 타입을 미리 지정해준다.
-bool 불리언 표현 eg. True, False, 1, 0, yes, no
-char 문자 하나 eg. 'a', 'Z', '?'
-string 문자열 // 여러 개의 char 라고 생각하면 된다.
-int 특정 크기까지의 정수 // 약 40억까지 셀 수 있다고 한다.
-long 더 큰 크기의 정수
-float 부동소수점을 갖는 실수
-double 부동소수점을 포함한 더 큰 실수
형식지정자
printf 함수에서는 데이터 타입을 위한 형식 지정자를 사용할 수 있다. 자바와 c언어가 다른 점이 있다.
- %c : char
- %f : float, double
- %i : int
- %li : long
- %s : string
기타 연산자 및 주석
- 수학 연산자 : + - * / %
- 비교 연산자 : > < ==
- 논리 연산자 : && || !
- 주석 : //
Scanner scan = new Scanner(System.in);
int i ;
do{
System.out.print("Positive Integer : ")
int i = scan.nextInt();
}while(i < 1);
System.out,printf("%d를 입력하셨습니다.", i);
if(i % 2 == 0){
System.out.print("입력하신 값은 짝수입니다.")
}else{
System.out.print("입력하신 값은 홀수입니다.")
}주석
- 이 코드를 처음 보는 동료들에게 이 코드가 무슨 일을 하는지 설명하는 것이다.
- 코드의 길이가 수 백, 수 천줄이 된다면(헉?) 주석으로 잘 설명하는 것이 중요하다. 주석 습관을 잘 들이자.
5.5. 사용자 정의 함수
사용자 정의 함수를 만드는 것의 효용에 대해서만 생각을 해보자. 이 코드가 어떻게 작동하는지 메인 코드에서 보여주지 길게 보여주지 않아도 된다. 자주 사용하는 함수를 일일이 다 칠 필요가 없다.
처음에 강의 들었을 때, 입력(파라미터와 인자)과 출력을 이해하지 못했던 것과 같다.
5.6. 중첩루프
for(int i = 0; i < 10; i++){
for(int j = 0; j < 10; j++){
System.out.print("#");
}System.out.println();
}- {왼쪽에서 오른쪽으로 #를 열의 수만큼 찍고 줄바꿈} 이것을 행의 수만큼 반복하는 것이다. 우리는 #를 열의 수 x 행의 수만큼 찍게 된다는 걸 볼 수 있다. 결국 #기호를 찍으라는 코드가 (열의 수 * 행의 수)만큼 반복되었다는 뜻이다.
5.7. 정수 오버플로우
for(int i = 1; ; i*=2){
printf("%i\n", i);
sleep(1);
}-
1에다가 2를 무한정 곱하는 for문이다. sleep(1)이라는 함수도 재밌었다. 이 때 변수 i를 int에 저장했기 때문에, int에 저장가능한 수를 넘은 이후에는 에러가 뜨고 0이 출력된다.
-
정수를 계속 키우는 프로그램에서 10억을 넘기자 앞으로 넘어갈 1의 자리가 없어진다. int는 4바이트의 정수만 저장할 수 있다.
- 실제 사례
-
Y2K문제 : 연도를 마지막 두 자리수로 저장했던 관습에 의해 99년도 다음해에 00으로 오버플로우가 되고, 2000년도가 아니라 1900년도로 인식하게 되는 치명적인 오류. 이 오류를 시정하기 위해 수백만 달러를 투자해 더 많은 메모리를 활용해 해결하도록 했다. 통찰력 부족에서 기인한 단순하고 값비싼 문제였다.
-
보잉 787 : 248일을 1/100초로 계산하면 2의 32제곱이 나온다. 보잉을 설계할 때 사용한 변수보다 더욱 커지게 되는 기점이 248일이었다. 그 이후가 되면 강제로 안전 모드로 진입하면서 전력을 잃는 문제가 생겼다. 이를 해결하기 위해 주기적으로 재가동을 해서 변수를 다시 0으로 리셋했다.
결론적으로, 우리가 다루고자 하는 데이터의 범위를 멀리 보고 프로그램을 작성하는 것이 중요하다.
5.8. 컴파일링
정리
-
main 함수 : 프로그램의 시작점으로 실행버튼을 클릭하는 것과 같다.
-
printf 함수 : 출력을 담당하는 함수이다. 이 함수를 사용하기 위해
stdio.h 라이브러리가 필요했다. 정확히 말하면,헤더 파일로 C언어로 작성되어 있으며,printf의 프로토 타입이 있어서 컴파일러가 컴파일 할 때 printf가 무엇인지 알려주는 역할을 한다. -
clang hello.c (컴파일)-> ./a.out (실행) 0과 1로 가득찬 파일 a.out을 실행하는 과정이다. a.out이라는 의미없는 파일명 대신 유의미한 파일 이름으로 컴파일 하고 싶다면, clang -o hello hello.c라는 명령행 인자를 추가해줘야 한다.
-
cs50 라이브러리를 사용한 프로그램을 컴파일 할 때는 clang에 또 하나의 프로그램이 필요했다. clang에게 cs50 라이브러리에 있는 모든 0과 1들을 연결하라는 의미다.
-
가장 간단한 방법으로 make 프로그램을 이용하면 이 모든 컴파일 과정을 자동으로 처리할 수 있었다.
컴파일링의 4단계
-
전처리: #으로 시작되는 C 소스코드는 전처리기에서 실질적인 컴파일이 이루어지기 전에 무언가를 실행하라고 알려준다.#include는 전처리기에 다른 파일의 내용을 포함시키라고 알려준다. 전처리기는 새로운 파일을 생성하는데 이 파일은 C소스 코드 형태이며 stdio.h파일의 내용이 #include 부분에 포함된다. -
컴파일 : 컴파일러라고 불리는 프로그램이 C코드를
어셈블리어라는 저수준 프로그래밍 언어로 컴파일한다. 어셈블리는 C보다 연산의 종류가 훨씬 적지만, 여러 연산들이 함께 사용되면 C에서 할 수 있는 모든 것들을 수행할 수 있다. C코드를 어셈블리 코드로 변환시켜줘서 컴퓨터가 이해할 수 있는 언어와 최대한 가까운 프로그램으로 만들어 준다. 컴파일이라는 용어는 소스 코드를 오브젝트 코드로 변환하는 전체 과정을 통틀어 일컫기도 하지만, 구체적으로는전처리한 소스 코드를 어셈블리 코드로 변환시키는 단계를 말하기도 한다. -
어셈블 : 소스 코드가 어셈블리 코드로 변환되면,
어셈블리 코드를 오브젝트 코드로 변환시키는 단계다. 이 작업은 어셈블러라는 프로그램이 수행한다. 소스코드에서 오브젝트 코드로 컴파일 되어야 할 파일이 딱 한개라면, 컴파일 작업은 여기서 끝난다. -
링크 : 만약 프로그램이 여러 개의 파일로 이루어져 있어(cs50.h이나 math.h 같은 라이브러리를 포함해) 하나의 오브젝트 파일로 합쳐져야 한다면 링크라는 마지막 단계가 필요하다.
링커는 여러 개의 다른 오브젝트 코드 파일을 하나의 오브젝트 코드 파일로합쳐준다.
5.9. 디버깅
버그: 코드에 들어있는 오류로, 프로그래머들이 숙명적으로 마주한다.디버깅: 코드에 있는 버그를 식별하고 고치는 과정이다. 디버거라고 하는 프로그램을 사용해 디버깅을 한다.디버거: 프로그램을 특정 행(중지점)에서 멈추고 한 번에 한 행씩 차례로 실행할 수 있도록 해서 버그를 찾는데 도움이 된다. 코드가 어떻게 실행되는지 단계별로 따라갈 수 있기 때문이다.printf:디버깅의 또 다른 방법으로 문제가 되는 변수를 직접 출력해서 볼 수 있다.
for(int i = 0; i <= 10; i++){
printf("i is now %i", i);
printf("#\n");
}- #를 10번만 실행하고 싶었는데, 11번이 출력되어서 printf를 사용해서 카운트 역할을 하는 변수를 직접 출력해서 버그를 찾으려고 했었다.
고무 오리

- 디버깅을 위한 또다른 팁.
한숨 돌리고 전환한 뒤에 다시 생각해보는 것이다.러버덕을 두고 내가 작성한 코드를 한 줄 한 줄 말로 설명해주는 과정을 거치다 보면,아하! 모먼트가 오는 경우도 있다.
5.10. 코드의 디자인
다른 사람과 협업으로 프로그램을 만들 때, 내가 만드는 코드의 내용 뿐만 아니라 형식에도 신경을 써야 한다. 그에 따라서 코드를 이해하고 수정하는 속도가 달라진다.

-
for 문을 사용하는 서로 다른 형식이 있다. 많은 회사들이 코드를 작성할 때, 특정한 스타일 가이드를 따로도록 한다.
-
help50, debug50, check50은 코드의 정확성을 위한 프로그램이었고, style50은 스타일을 위한 프로그램이었다.
-
정확하게 짜여졌는가? 코드는 보기 좋은가? 그리고 좋은 코드의 세번째 축은 디자인이다.
6. 배열
특정 자료형의 변수를 선언하면 메모리상 어딘가에 특정 크기만큼의 자리를 차지하게 된다. 비슷한 종류의 값을 모아서 저장해 사용하고 싶다면 어떻게 할까? 그리고 그 이점은?


- 각각의 자료형은 서로 다른 크기의 메모리를 차지한다.
- 자바에서는 char가 2바이트였던 것 같다.
- 쉽게 생각해서 원고지 모양으로 나뉘어진 노란색 사각형이 메모리라고 생각하자. 작은 사각형 하나가 1바이트를 의미한다.
배열
같은 자료형의 연관된 데이터를 메모리 상에 연이어서 저장하고 이를 하나의 변수에 담아 관리하기 위해 사용된다.
점수 3개 평균 구하기
- 변수 3개를 따로 만들어서 점수를 입력하고 평균을 내는 것
- 배열을 만들어서 하나의 변수에 관리하는 것.
점수의 갯수가 바뀌는 상황에 제약이 남아있다. 좀 더 동적으로 선언하고 저장하는 방법을 알아보자.
(1)
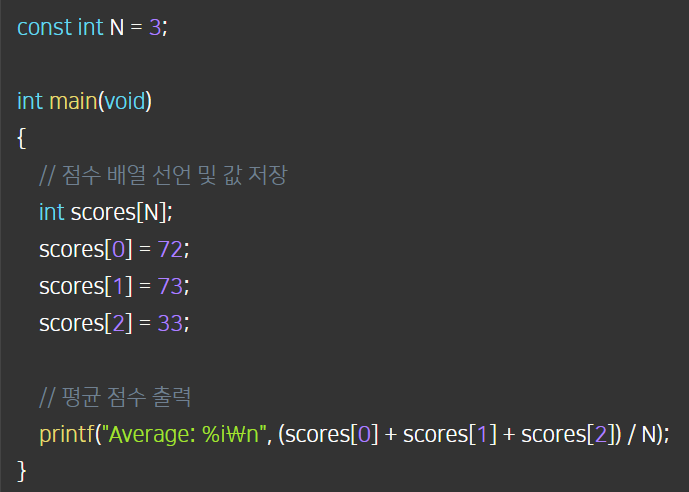
- 전역변수를 만들어 상수를 고정해서 점수 갯수가 바뀌었을 때, 수정해야 하는 코드가 줄었다. 하지만 배열의 인덱스마다 점수를 직접 지정해줘야 하는 불편함이 남아있다.
(2)
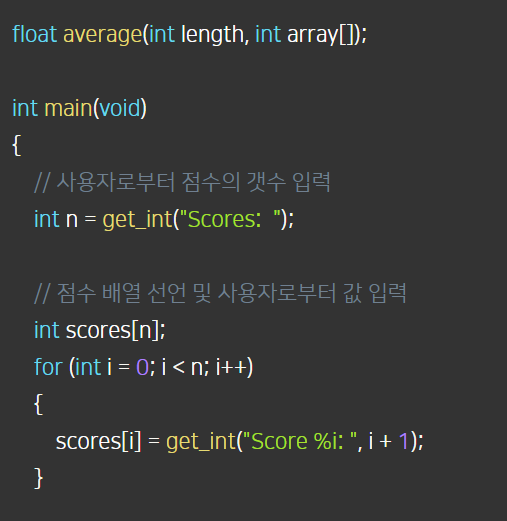
- get_int 함수를 이용해 사용자로부터 점수의 갯수를 입력받았다.
- 반복문을 이용해 사용자로부터 점수를 직접 입력 받았다. 반복문 안에 입력 받는 코드를 넣는 아이디어를 이 시점에 얻었다.

- 평균을 계산하는 사용자 정의 함수를 만들었다. 컴파일 할 때 오류가 발생했는데, 메인보다 아래 위치하고 있어서 생긴 문제였다. 카피/페이스트가 용납되는 지점이다.
- 함수에서 파라미터를 받을 때, 배열 자체를 파라미터로 받는 아이디어를 얻었다. 인자에 넣을 때는 배열의 이름만 넣어주면 되었고, 파라미터에는 대괄호를 넣어서 배열임을 알려주어야 했다.
- 리턴값에서 float로 강제형변환을 해주었다. 정수/정수 = 정수이므로 실제 실수가 나와도 정수가 되어 유실되는 값이 있다는 것을 유의해야 한다. 그저 결과 정수를 강제형변환으로 실수로 바꿔줬다고 해도, 애초에 유실되는 값은 다시 복원시킬 수 없다. 이 부분 생각을 못했었다. 그리고 사실 정수/실수 or 실수/정수는 실수이기 때문에 둘 중에 하나만 강제형변환 해주어도 되었다.
6.1. 문자열과 배열
문자열
- 문자 자료형 데이터들의 배열이다.
- '문자가 나열되어 있다' 또는 '배열되어 있다'라는 의미로 추측해볼 수 있다.
- String s = "HI!";에서 s는 문자의 배열이기 때문에 메모리상 아래 그림과 같이 저장되고, 인덱스로 각 문자에 접근할 수 있다. 자바에서는 같은 방식으로 할 수 없었다.
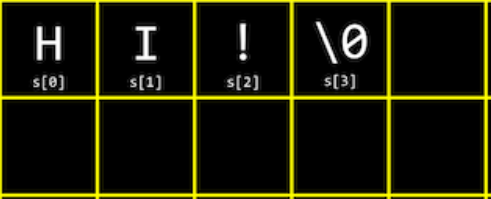
- 가장 끝의 \0은 문자열의 끝을 나타내는 널 종단 문자이다. 모든 비트가 0인 1바이트를 의미한다.
#include <stdio.h>
#include <cs50.h>
int main(void){
string names[4];
names[0] = "SURI";
names[1] = "Hoon";
names[2] = "Jong";
names[3] = "Hye";
printf("%s\n", names[1]);
printf("%c%c%c%c\n", names[2][0],names[2][1], names[2][2], names[2][3]);
} //이차원 배열 개념을 사용해서 names 배열의 각 요소의 문자 하나 하나에 접근하는 것

- 메모리에 저장되는 방식
문자열의 길이 및 탐색
#include <stdio.h>
#include <cs50.h>
int main(void){
string s = get_string("input : ");
printf("Output:\n");
for(int i = 0; s[i] != '\0'; i++){
printf("%c\n", s[i]);
}
}- for문에서
조건식이 참인 동안 루프가 실행된다는 아주 기초적인 부분을 혼동할 때가 있다. - 문자열이 끝나는 걸 어떻게 알 수 있을까? 문자열의 끝에 널 종단 문자 '\0'이 있었다. 따라서 그에 따른 조건문을 넣어주었다. 아이디어겟!
- 혹은 strlen()이라는 함수를 넣어줄 수도 있다. n = strlen(s) 이렇게 조건문 변수 초기화 부분에 두 가지 이상의 식을 넣을 수 있다는 아이디어겟!
- 계속해서 반복해야 하는 질문(함수)가 있다면 위에서나, 혹은 변수 초기화 영역에서 고정시켜 주고 가는 것이 나을 것이다. 이건
시간과 메모리의 저울질이라는 이야기도 했었다. 변수를 새로 만들어 메모리를 잡아 먹을 것인가? 혹은 함수를 반복해서 불러서 시간을 잡아먹을 것인가?
문자열 탐색 및 수정
string s = get_string("before : ");
printf("after : ");
for(int i = 0, n = strlen(s); i < n; i++){
if(s[i] >= 'a' && s[i] <= 'z'){ // 비교연산자로 소문자 체크
printf("%c", s[i]-32);
}else{
printf("%c", s[i]);
}
}
printf("\n");
char result = 'a' - 32;
printf("%c\n", result); //A- 소문자인지 체크하는 부분을 비교연산자로 할 수 있었던 것은
아스키코드 상에서 숫자값으로 비교할 수 있기 때문이다. 또한, 소문자와 대문자의 차이는 32만큼이기 때문에 32를 빼주어 출력하면 대문자로 출력이 된다. 소문자가 아니면 그대로 출력하면 된다. (자바에서도 저런 경우에 대문자 A가 출력이 되는 걸 확인할 수 있었다.) toupper() 이라는 함수로 간단하게 변환할 수 있다. 소문자를 대문자로 반환해서 출력하기 위해서 처음에 사용한 로직은 아스키코드를 이용해 32를 빼주는 것이었다. 하지만 그보다더 중요한건 남이 만들어 놓은 도우미 함수를 이용해서 처리하는 거였다.
6.2. 명령행 인자
#include <cs50.h>
#include <stdio.h>
int main(int argc, string argv[]){ // void 대신 명령행 인자
if(argc == 2){
printf("hello, %s\n", argv[1]);
}else{
printf("hello, world!\n");
}
}
- 첫 번째 변수 argc는 main 함수가 받게 될 입력의 개수이다.
- argv[]는 그 입력이 포함되어 있는 배열이다. 프로그램을 명령행에서 실행하므로, 입력은 문자열로 주어진다. argv[]는 string 배열이 된다.
- argv[0]에는 프로그램의 이름이 저장이 된다. 하나의 입력이 더 주어지면 argv[1]에 저장되므로, argv[1]로 입력된 인자를 호출해야 한다.
int main(int argc, string argv[]){
if(argc != 2){
printf("missing command-line arguments\n");
return 1;
}else{
printf("hello, %s\n", argv[1]);
return 0;
}
}이걸로 뭘 할 수 있을까?
- 글의 난이도를 판독할 수 있다,
- 암호문을 만들 수도 있다.
개인실험
// 암호문 만들어보기
int main(int argc, string argv[]){
printf("serect note : \n");
int i = 1;
while(i < argc){
for(int k = 0; k < strlen(argv[i]); k++){
char c = argv[i][k]+1;
printf("%c", c);
}
printf(" \n");
i++;
}
}
- 루프 중첩, 아스키코드 차트를 활용해서 암호문으로 번역할 수 있었다. 해보면 막상 어렵지 않은 논리였다. 너무 쫄지 않기.
7. 알고리즘 - 2
이번 시간에는 언어적인 문법보다는 개념을 배운다. 메모리를 바이트로 나누면 매우 편리하다. 메모리를 바이트의 격자 배열로 취급하면 원하는 대로 사용할 수 있다. 자료구조를 사용할 수 있다. 아직 이 말이 와닿지는 않는다.
7.1. 검색 알고리즘
배열은 한 자료형의 여러 값들이 메모리상에 모여 있는 구조다. 컴퓨터는 이 값들에 접근할 때 배열의 인덱스 하나하나를 접근한다. 어떤 값이 배열 안에 속해 있는지를 찾아 보기 위해서 배열이 정렬되어 있는지 여부에 따라 아래와 같은 방법을 사용할 수 있다.
배열을 설명하면서 빨간 서랍을 예시로 들었다. 첫 번째 학생은 숫자들이 어떻게 정렬되어 있는지 알지 못하는 상태이고, 서랍 안에서 50이라는 숫자를 찾기 위해서 차례대로 서랍을 모두 열어볼 수 밖에 없었다.
선형 검색
배열의 인덱스를 처음부터 끝까지 하나씩 증가시키면서 방문하여 그 값이 속하는지를 검사합니다.
두 번째 학생은, 배열이 정렬되어 있다는 조건 하에, 가운데를 선택해 두 개로 쪼개면서 선택하면서 탐색하는 방법을 택했다. 이진은 binary이고 첫 시간에 전화번호에서 Mike Smith를 찾은 분할 정복 기법을 떠올리면 된다.
이진(binary) 검색
만약 배열이 정렬되어 있다면, 배열 중간 인덱스부터 시작하여 찾고자 하는 값과 비교하며 그보다 작은(작은 값이 저장되어 있는) 인덱스 또는 큰 (큰 값이 저장되어 있는) 인덱스로 이동을 반복하면 됩니다.
Q. 만약 정렬되지 않은 배열이 있다면, 선형 검색이 빠를까요 이진 검색이 빠를까요? 정렬되지 않은 배열에 이진 검색을 사용하는 건 운에 달려 있을 뿐.
7.2. 알고리즘 표기법
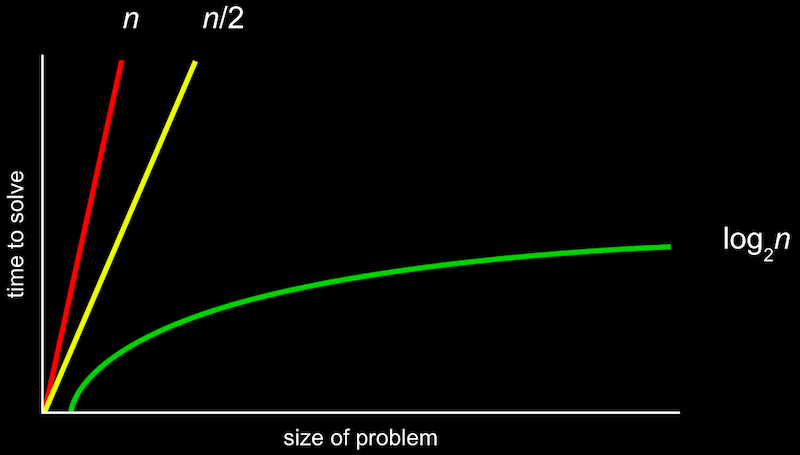
알고리즘을 실행하는 데 걸리는 시간을 비교한 함수
특정 알고리즘을 작성하였을 때, 실행 시간을 표기하는 방법(상한/하한)에 대해서 배워본다.
- Big-O 표기법
O는on the order of의 약자로-만큼의 정도로 커지는 것이라고 볼 수 있다.
O(n)은 n만큼 커지는 것이므로 n이 늘어날수록 선형적으로 증가하게 된다. O(n/2)도 결국 n이 매우 커지면 1/2은 큰 의미가 없어지므로 O(n)의 범주라고 할 수 있다.
아래와 같은 Big O 표기가 실행 시간을 나타내기 위해 많이 사용된다.
- O(n^2)
- O(n log n)
- O(n) - 선형 검색
- O(log n) - 이진 검색
- O(1)
- Big-Ω 표기법
Big O가 알고리즘 실행 시간의 상한을 나타낸 것이라면,Big Ω는 알고리즘 실행 시간의 하한을 나타낸다. 선형 검색에서 n개의 항목이 있을 때 최대 n번의 검색을 해야 하므로 상한이 O(n)이 되지만 운이 좋다면 한 번만에 검색을 끝낼 수도 있으므로 하한은 Ω(1)이 된다.
아래와 같은 Big Ω 표기가 많이 사용된다.
- Ω(n^2)
- Ω(n log n)
- Ω(n) - 배열 안에 존재하는 값의 개수 세기
- Ω(log n)
- Ω(1) - 선형 검색, 이진 검색
Q. 실행시간의 상한이 낮은 알고리즘이 더 좋을까요, 하한이 낮은 알고리즘이 더 좋을까요?
실행시간의 상한이 낮은 알고리즘이 좋다. 데이터는 가변적이기 때문에 최악의 경우에서 값이 일정하게 나오는 게 중요하다.
7.3. 선형검색
- 원하는 원소가 발견될 때까지 처음부터 마지막 자료까지 차례대로 검색한다.
- 정확하지만 효율적이지 못한 방법이다. 리스트의 길이가 n이라고 했을 때, 최악의 경우 리스트의 모든 원소를 확인해야 하므로 n번만큼 실행된다.
- 반대로 최선의 상황은 처음 시도에 찾고자 하는 값이 있는 경우다.
- 자료가 정렬되어 있지 않거나 그 어떤 정보도 없어 하나씩 찾아야 하는 경우에 유용하다. 이런 경우 무작위로 탐색하는 것보다 순서대로 탐색하는 것이 더 효율적이다.
- 검색 이전에 정렬은 왜 중요한가? 정렬은 시간이 오래 걸리고 공간을 더 차지한다. 하지만 이 추가적인 과정을 진행하면 리스트를 여러번 검색해야 하거나 매우 큰 리스트를 다를 경우 시간을 단축할 수 있다.
선형검색의 다양한 사례에 대해서 살펴본다.
#include <cs50.h>
#include <stdio.h>
int main(void){
//numbers 배열 정의 및 값 입력
int numbers[5] = {3, 5, 7, 2, 50};
// 값 50 검색하기
for(int i = 0; i < 5; i++){
if(numbers[i] == 50){
printf("%d번째에 찾는 값이 있습니다.\n", i+1);
return 0;
}
}
printf("찾으시는 값이 없습니다.");
return 1;
// c언어에서 return의 의미에 대해 알 것 같다. 결국 동일하다. 마침표의 역할.
}#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(int argc, string argv[]){
//전화번호부와 이름이 입력된 배열
string names[4] = {"SURI", "MING", "TAN", "VIHO"};
string numbers[4] = {"1234", "4567", "5678", "3627"};
//전화번호부에 argv[1] 입력값이 있으면 그에 맞는 번호 출력하기
for(int i = 0; i < 4; i++){
if(strcmp(names[i], argv[1]) == 0){
printf("찾으시는 번호는 %s입니다\n", numbers[i]);
return 0;
}
}
printf("찾으시는 번호가 없습니다.");
return 1;
}여기에서 아쉬운 점이 있다면? names 배열과 numbers 배열이 서로 같은 인덱스를 가져야 한다는 점이 한계다. 만약에 하나의 배열을 다른 식으로 정리한다면 그에 상응하는 다른 배열의 인덱스를 재정렬하기가 까다롭다. 이럴 때 더 좋은 방법은 새로운 자료형으로 구조체를 정의해서 이름과 번호를 묶어주는 것이다.
#include <cs50.h>
#include <stdio.h>
#include <string.h>
//typedef struct 이용한 구조체 선언하기
typedef struct{
string name;
string number;
}
person;
int main(int argc, string argv[]){
person people[4];
people[0].name = "EMMA";
people[0].number = "617–555–0100";
people[1].name = "RODRIGO";
people[1].number = "617–555–0101";
people[2].name = "BRIAN";
people[2].number = "617–555–0102";
people[3].name = "DAVID";
people[3].number = "617–555–0103";
for(int i = 0; i < 4; i++){
if(strcmp(people[i].name, argv[1]) == 0){
printf("찾으시는 번호는 %s입니다\n", people[i].number);
return 0;
}
}
printf("찾으시는 번호가 없습니다.");
return 1;
}- typedef struct를 이용한 구조체 선언하기(새로운 개념이었다)
- person이라는 이름의 구조체를 자료형으로 정의하고 person 자료형의 배열을 선언하면 그 안에 포함된 속성값은 ‘.’으로 연결해서 접근할 수 있다. person a; 라는 변수가 있다면, a.name 또는 a.number 이 각각 이름과 전화번호를 저장하는 변수가 된다.
- 이름과 전화번호부가 하나의 인덱스에 묶이니까 데이터 관리가 훨씬 수월하다.
7.4. 버블 정렬
정렬되지 않은 리스트를 탐색하는 것보다 정렬한 뒤 탐색하는 것이 더 효율적이다.
버블 정렬은 두 개의 인접한 자료값을 비교하면서 만약 순서에 맞지 않는다면 위치를 교환하는 방식으로 정렬하는 방법이다. 단 두개의 요소만 정렬해주는 좁은 범위의 정렬에 집중한다. 이 접근법은 간단하지만 단 하나의 요소를 정렬하기 위해 너무 많이 교환하는 낭비가 발생할 수 있다. 마치 거품이(비교/교환) 터지면서 위로 올라오는 방식이기 때문에 버블 정렬이라고 부른다.
Repeat n–1 times
For i from 0 to n–2
If i'th and i+1'th elements out of order
Swap them중첩 루프를 돌아야 하고, n개의 값이 주어졌을 때 각 루프는 각각 n-1번, n-2번 반복되므로 (n-1)*(n-1) = n^2-2n+1번의 비교 및 교환이 필요하다. 여기서 가장 크기가 큰 요소는 n^2 이므로 위와 같은 코드로 작성한 버블 정렬 실행 시간의 상한은 O(n^2)이라고 말할 수 있습니다.정렬이 되어 있는지 여부에 관계 없이 루프를 돌며 비교를 해야 하므로 버블정렬의 실행 시간의 하한도 여전히 Ω(n^2)이 된다. (비교 및 교환이 일어나는 횟수 바로 이해가 안 된다. 나는 (n-1)(n-2)/2라고 생각했는데.)
버블 정렬이 효율적인 경우는, 리스트가 작고 정렬이 되어 있지 않았을 때이며 비효율적인 경우는 정렬이 되어 있지 않고 리스트가 많을 때다.
7.5. 선택 정렬
배열 안의 자료 중 가장 작은 수(혹은 가장 큰 수)를 찾아 첫 번째의 위치(혹은 가장 마지막 위치)와 교환해주는 방식의 정렬이다. 교환 횟수를 최소화하는 반면 각 자료를 비교하는 횟수는 증가한다.
For i from 0 to n–1
Find smallest item between i'th item and last item
Swap smallest item with i'th item여기서도 두 번의 루프를 돌아야 한다. 바깥 루프에서는 숫자들을 처음부터 순서대로 방문하고, 안쪽 루프에서는 가장 작은 값을 찾아야 한다. 따라서 소요 시간의 상한은 O(n^2)이 된다. 하한도 마찬가지로 Ω(n^2) 이다. 버블 정렬과 동일하다.
선택정렬로 정렬되는 배열은 n-1번의 교환이 필요하다. 버블 정렬의 교환 횟수보다는 적다. 그러나 한 번의 교환이 일어나기 위해서 정렬되지 않은 모든 수와 비교가 이루어져야 하므로, n^2번의 비교가 이루어진다.
상한 시간을 찾는 식으로, 1+...+ n-1 + n = (n)(n+1)/2
7.5. 정렬 알고리즘의 실행시간
실행시간의 상한
- O(n^2): 선택 정렬, 버블 정렬
- O(n log n)
- O(n): 선형 검색
- O(log n): 이진 검색
- O(1)
실행시간의 하한
- Ω(n^2): 선택 정렬, 버블 정렬
- Ω(n log n)
- Ω(n)
- Ω(log n)
- Ω(1): 선형 검색, 이진 검색
여기서 버블 정렬을 좀 더 잘 할 수 있는 방법은 없을까? 만약 정렬이 모두 되어 있는 숫자 리스트가 주어진다면 어떨까?
알고리즘을 멈추거나 줄이는 조건문이 있으면 좋을 것이다. 이미 정렬이 되어 있다면 좋은 기회이기 때문이다.
여기서 안쪽 루프에서 만약 교환이 하나도 일어나지 않는다면 이미 정렬이 잘 되어 있는 상황이다. 따라서 바깥쪽 루프를 ‘교환이 일어나지 않을때’까지만 수행하도록 다음과 같이 바꿀 수 있다.
Repeat until no swaps
For i from 0 to n–2
If i'th and i+1'th elements out of order
Swap them최선의 경우 버블 정렬은 n-1만 실행되면 된다. 따라서 최종적으로 버블 정렬의 하한은 Ω(n)이 됩니다. 상황에 따라서는 선택 정렬보다 더 빠른 방법이 된다.
최종적인 실행시간의 하한
- Ω(n^2): 선택 정렬
- Ω(n log n)
- Ω(n): 버블 정렬
- Ω(log n)
- Ω(1): 선형 검색, 이진 검색
Q. 선택 정렬의 실행 시간의 하한도 버블 정렬처럼 단축시킬 수 있을까?
7.6. 재귀
재귀 함수는 내부에서 자기 자신을 호출한다.
#include <cs50.h>
#include <stdio.h>
#include <string.h>
void draw(int h);
int main(void){
int height = get_int("Height : ");
draw(height);
}
void draw(int h){
for(int i =1; i <= h; i++){
for(int j = 1; j <=i; j++){
printf("#");
}
printf("\n");
}
}
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void){
int height = get_int("Height : ");
draw(height);
}
void draw(int h){
if(h == 0){
return;
} // h=0이면 아무것도 출력하지 않는 조건문 추가
draw(h-1); // 이부분이 포인트
for(int i = 0; i < h; i++){
printf("#")
}
printf("\n");
}- draw 함수 안에서 draw 함수를 다시 호출한다.
- 재귀를 사용하면 중첩 반복문을 사용하지 않고, 작은 피라미드로 큰 피라미드를 정의한다.
- 실행문의 순서가 아직 완전히 이해되진 않지만, 어쨌든 # - ## - ### - #### 이 순서로 출력이 된다.
구글의 유머와 하드코딩 웃기다. 구글에 recursion 검색하면 did you mean: recursion? 이라고 나온다. 컴퓨터 과학자들의 수준 높은 유머인건가.
7.7. 병합 정렬
버블/선택 정렬보다도 뛰어난 알고리즘으로 첫 시간에 배운 전화번호부의 분할 정복 탐색처럼 데이터를 반으로 나누어 가다는 것과 공통점이 있다. 원소가 한 개가 될 때까지 계속해서 반으로 나누다가 다시 합쳐나가며 정렬을 하는 방식이다.
7 | 4 | 5 | 2 | 6 | 3 | 8 | 1 → 가장 작은 부분 (숫자 1개)으로 나눠진 결과입니다.
4 7 | 2 5 | 3 6 | 1 8 → 숫자 1개씩을 정렬하여 병합한 결과입니다.
2 4 5 7 | 1 3 6 8 → 숫자 2개씩을 정렬하여 병합한 결과입니다.
1 2 3 4 5 6 7 8 → 마지막으로 숫자 4개씩을 정렬하여 병합한 결과입니다. 병합 정렬 실행 시간의 상한은 O(n log n)이다. 숫자들을 반으로 나누는 데는 O(log n)의 시간이 들고, 각 반으로 나눈 부분들을 다시 정렬해서 병합하는 데 각각 O(n)의 시간이 걸리기 때문이다.
실행 시간의 하한도 역시 Ω(n log n)이다. 숫자들이 이미 정렬되었는지 여부에 관계 없이 나누고 병합하는 과정이 필요하기 때문이다.
정렬되어 있지 않을 때 정렬하는 속도가 매우 빠르다는 장점이 있지만, 이미 정렬되어 있을 때도 불필요한 정렬을 하기 때문에 효율적이지 않다. 그리고 메모리를 많이 사용하게 된다고 한다. 댓글을 보니 stack overflow가 있을 수 있다는 말도 나왔다.
8. 메모리
8.1. 메모리 주소
16진수
- 컴퓨터 과학에서는 숫자를 10진수나 2진수 대신 16진수로 표현하는 경우가 많다. 데이터를 처리할 때 16진수를 사용하면 장점이 있기 때문이다.
16진수를 사용하면 10진수보다 2진수를 간단하게 나타낼 수 있다.
10진수를 16진수로 바꾸어보기
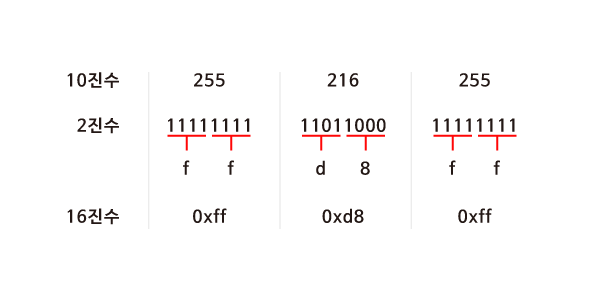
- 2진수로 모든 데이터를 표현하기에는 너무 길어지므로 16진수로 바꾸어본다.
- 2^4이 16이기 때문에 4bits씩 두 덩어리로 나누어보면 0000부터 1111까지는 16진수로 표현할 수 있다.
- 16진수에서 10부터 15까지는 a - f로 처리한다.
- 16진수 앞에는 0x를 붙혀 16진수임을 알린다.
- 2개의 16진수는 1byte의 2진수로 변환되기 때문에 정보를 표현하기 매우 유용하다.
- 처음엔 바로 와닿지 않았는데 확인해보니 정말 가능하다. 4bits씩 나누면 2^0/2^4/2^8 x (0-15)로 뭐든 표현할 수 있기 때문에 16진수로 퉁쳐서 표현 가능하다.
메모리 주소

- 정수형 변수 n에 50이라는 값을 저장하고 출력하려고 한다.
- n은 int 타입이므로 메모리 어딘가에 4바이트 만큼의 자리를 차지하고 저장되어 있다.
int n = 50;
printf("%p\n", &n); //Ox7ffe00b3adbd와 같은 16진법으로 표현된 메모리 주소를 얻게 된다.
printf("%i\n", *&n); // 50, 변수 n의 메모리상 주소를 먼저 얻고 난 뒤 값을 얻어와 출력한다.- c에서는
변수의 메모리상 주소를 받기 위해 &이라는 연산자를 사용한다.형식지정자는 %p를 사용했다. *을 사용하면 메모리 주소에 있는 실제 값을 얻을 수 있다.
👀 문제 중에 'CS50'을 16진수로 표현하는 게 있었는데, 아스키코드 표를 보니 0부터 9까지의 숫자도 다시 두 자리 숫자로 약속되어 있었다. 모두들 그렇게 답을 풀어냈다.
8.2. 포인터
포인터 역할을 하는 변수 선언하기
int n = 50;
int *p = &n // *p라는 포인터 변수에 변수 n의 주소를 저장
printf("%p\n", p); // n의 주소를 출력
printf("%i\n", *p); // 변수 n의 값을 출력- 이부분 약간 헷갈릴 수도 있으니, 계속 보는 게 좋을 것 같다.
- * : 이 변수가 포인터라는 의미이다. 주소의 값을 불러온다는 뜻도 있었다.
- int : 이 포인터 변수가 가리키는 변수의 자료형이 int라는 뜻이다.
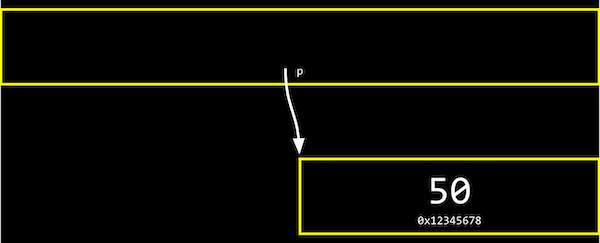
- 포인터 변수 p의 값인 n의 주소를 생각하지 않고,
추상적으로 단지 p가 n을 가리키고 있다는 것만 생각해도 된다. (검은 색 메일 박스를 열었을 때, n의 주소값이 들어있었던 걸 생각하자) - 포인터를 기반으로 다양한 데이터 구조를 정의하고 사용할 수 있다. 구글, 페이스북 회사에서 데이터를 관리할 때 사용하는 알고리즘의 기반이 되기도 한다.
- 최신 컴퓨터는 64bits 포인터로 사용한다. 하지만 현대 하드웨어가 그럴 뿐 꼭 그럴 필요는 없다.
Q. 포인터의 크기는 메모리의 크기와 어떤 관계가 있을까?
8.3. 문자열
새로운 문맥에서 문자열이 무엇인지 제대로 알아보자.
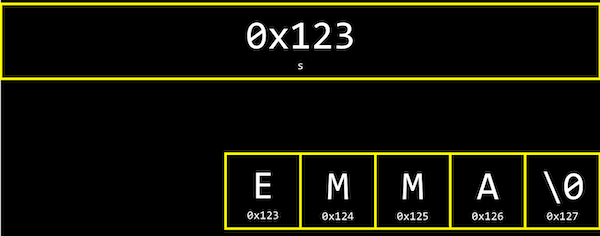
string s = “EMMA”;- 여기에서 변수 s는 결국 문자열을 가리키는 포인터다. 더 자세히는 문자열의 가장 첫 번째 문자의 주소를 가리킨다.
- 사실 string은 존재하지 않는 자료형이다. 선의의 거짓말을 했다. cs50라이브러리에 만들어진 보조바퀴다. 그 안에 string은
typedef char *string이렇게 정의되어 있다. - 여기서 typedef는 새로운 자료형을, char *은 문자에 대한 포인터를, string은 자료형의 이름을 의미한다.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
string s = "EMMA";
printf("%s\n", s);
}//#include <cs50.h> 보조바퀴 제거
#include <stdio.h>
int main(void)
{
char *s = "EMMA";
printf("%s\n", s);
}- 1번과 2번 두 코드는 동일하게 동작한다.
#include <stdio.h>
int main(void){
printf("%s\n", s) // EMMA 형식지정자 %s에 의해 첫글자만 출력하는 것이 아닌, 널종단문자까지 출력한다.
printf("%c\n", *s); // E
printf("%p\n", s); // 0x42ad9a 동일
printf("%p\n", &s[0]); //0x42ad9a 동일
printf("%p\n", &s[1]); // 0x42ad9b 1바이트 차이므로, b만 바뀌어있음
}👀 string은 어떤 char의 주소를 가지고 있는 변수이다. 문자 하나를 가리키는 주소다. 문자열의 끝을 8개의 0비트로 채워진 널 종단 문자를 사용해 끝을 알게 된다. 결국 문자열은 여러 문자의 묶음을 추상화한 것이다. 그저 주소를 저장한 포인터 변수일 뿐이다.
8.3. 문자열 비교
int main(void){
printf("%c\n", *s); // E
printf("%c\n", *(s+1)); // M
printf("%c\n", *(s+2)); // M
printf("%c\n", *(s+3)); // A
}- 포인터 연산
- 컴퓨터 과학에서 구문 설탕이라고 불리는 것. 내부 연산으로 해서 s[1/2/3] 이것과 같다.
#include <stdio.h>
#include <cs50.h>
int main(void){
char *s = get_string("s : ");
char *t = get_string("t : ");
// 같은 문자열을 입력한 상황
printf("%p\n", s); //0x181d6a0
printf("%p\n", t); //0x181d6e0
if(s == t){
printf("same\n");
}else{
printf("different\n");
}
}
- 같은 문자열을 입력했는데, 값이 다르다고 나온다. 왜냐하면 서로 다른 메모리 영역에 저장이 되어 있고, string과 char *s는 포인터 변수이기 때문에, 메모리 주소를 비교해서 값이 다르다고 나온다.
- get_string 함수는 그동안 호출 될 때마다 입력되는 첫 글자의 주소, 포인터를 반환하고 있었구나.
Q. 문자열을 비교하는 코드는 어떻게 작성해야 할까요? 이거 답을 찾아봤는데, 내 코드가 만족스럽지는 않다. 그래도 기능은 한다. 포인터 연산으로 해서 문자 하나 하나를 비교하는 식을 만들었다.
8.4. 문자열 복사
#include <stdio.h>
#include <cs50.h>
#include <ctype.h>
int main(void){
string s = get_string("string : "); // emma 입력
string t = s; // 문자열 복사
t[0] = toupper(t[0]); // 대문자로 바꾸기
printf("%s\n", s); //Emma
printf("%s\n", t); //Emma
}- 문자열을 입력 받아서 복사하고 대문자로 바꾼다음에 원본과 복사본을 모두 출력해봤더니, 둘 다 Emma로 되었다. 왜 그럴까, 바로 떠올리지 못했다가 고민 후에 떠올렸다. string 변수가 포인터 변수라는 중요한 포인트를 알았다면 바로 떠올렸어야 하는데! 둘은 결국 같은 문자열을 지목하게 된다. 그러니 그 문자열을 바꾼 것이다. (그림참고)
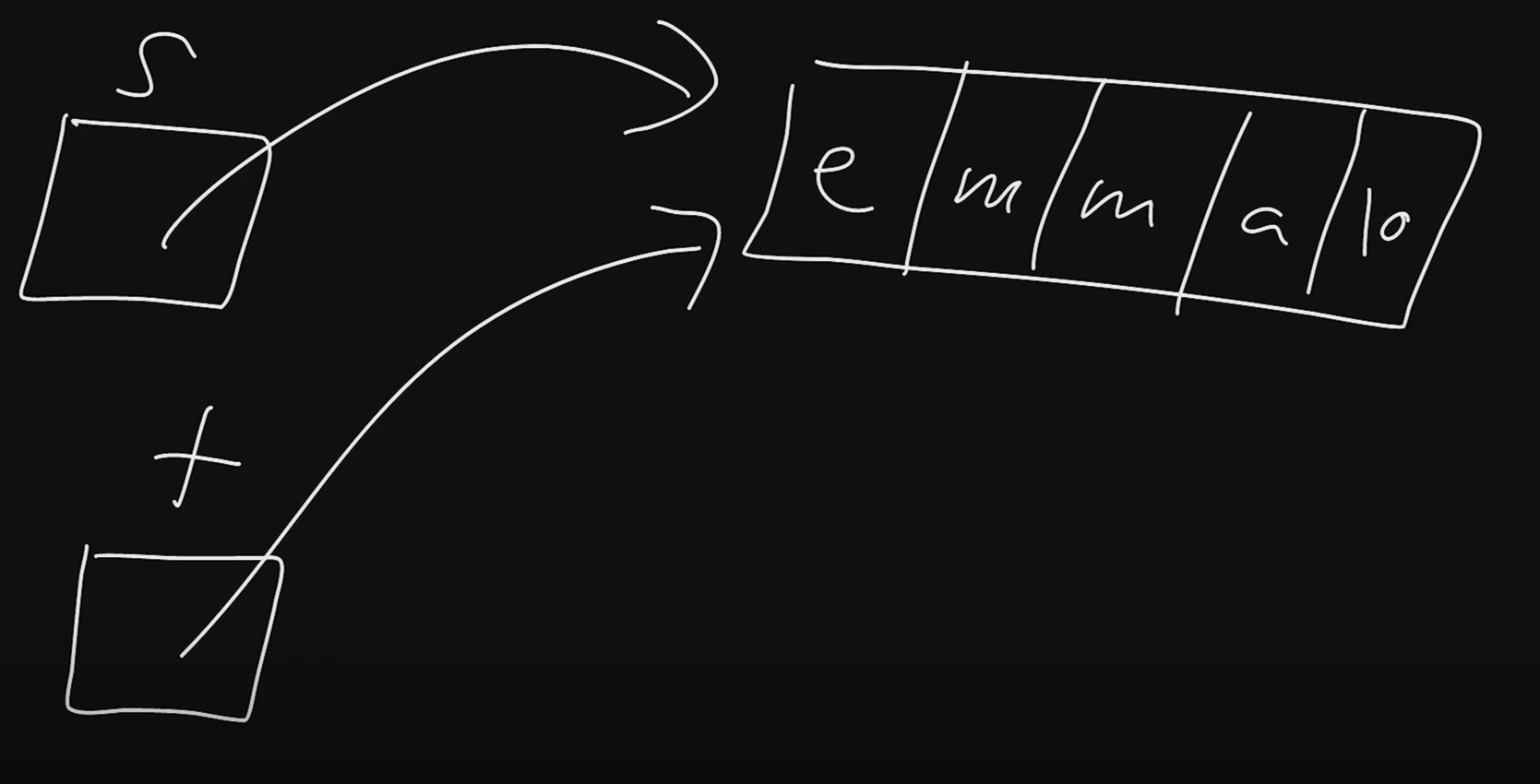
이번엔 메모리를 추가로 할당해서 같은 문자열이 두 개 생기도록 해보자. malloc 함수 또한, 할당한 메모리의 첫 바이트 주소를 돌려준다. 즉, 메모리 할당이란 메모리 일부분을 가져와서 그곳을 가리키는 포인터를 주는 거다.
#include <stdio.h>
#include <cs50.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h>
int main(void){
char *s = get_string("string : ");
char *t = malloc(strlen(s)+1); //메모리를 할당하는 함수
/*for(int i = 0, n = strlen(s); i <= n; i++){
t[i] = s[i];
}*/
strcpy(t, s); // 중첩문을 사용하지 않고 간단하게 문자열을 복사한다.
t[0] = toupper(t[0]);
printf("%s\n", s);
printf("%s\n", t);
}char *s = get_string("string : "); //hello 입력
printf("%p\n", s); //s[0]의 주소값
printf("%s\n", *s); // s[0]의 값
printf("%s\n", s); // hello
최종 정리
int main(void){
int n = 50;
int *p = &n;
printf("%p\n", p); // n의 주소
printf("%i\n", *p); // n의 값
char *c = "hello world";
printf("%p\n", c); // 첫 번째 글자 'h'의 주소
printf("%c\n", *c); // 'h'
printf("%s\n", c); // "hello world"
}8.6. 메모리 할당과 해제
malloc 함수를 이용하여 메모리를 할당한 이후에는 free라는 함수를 이용해 메모리를 해제해줘야 한다. 그렇지 않은 경우 저장한 값은 쓰레기 값으로 남아 메모리 용량의 낭비가 발생(메모리 누수)한다.
컴퓨터가 어떤 프로그램을 오래 돌리면서 점점 더 느려지면서 메모리가 부족하다고 에러 메시지를 띄운다면, 그 프로그램의 작성자가 malloc을 계속 호출하면서 메모리를 많이 할당하지만 전혀 해제하지 않았기 때문이다.
valgrind
어디서 메무리 누수가 나는지 알 수 있을까? 우리가 작성한 코드에서 메모리와 관련된 문제가 있는지 확인할 수 있는 프로그램이다.
valgrind의 검사내용의 이해를 쉽게 돕기 위해 help 50 valgrind ./filename을 사용할 수도 있다.
#include <stdlib.h>
void f(void)
{
int *x = malloc(10 * sizeof(int));
//x[10] = 0;
x[9] = 0;
free(x);
}
int main(void)
{
f();
return 0;
}- 포인터 x에 int형의 사이즈(4바이트)의 10배에 해당하는 크기의 메모리, 즉 40바이트를 할당한다.
- x의 10번째 값으로 0을 할당한다.
- 위 코드를 valgrind로 검사해보면
버퍼 오버플로우와메모리 누수두 가지 에러를 확인할 수 있다.
- Invalid write of size 4 (버퍼 오버 플로우)
- LEAK SUMMARY : 40bytes in 1 blocks (메모리 누수)
- 해결하기
x[10] = 0;코드에서 할당하지 않은 11번째 인덱스에 접근한 것이므로, 0-9사이의 인덱스에 접근하도록 바꿔준다.free(x);코드를 추가해서 메모리를 해제해준다.
8.7. 메모리 교환, 스택, 힙
두 개의 서로 다른 종류의 물을 바꿔 담기 위해서 별도의 임시공간이 필요했다. 이걸 코드로 표현하면 다음과 같다.
#include <stdio.h>
void swap(int a, int b); // swap 함수를 위한 프로토 타입
int main(void){
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(x, y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
- 논리적으로 문제가 없어 보이는데 왜 swap이 되지 않았을까? 함수에 인자를 전달할 때 a과 b자체가 아니라 복사본을 전달받는다. 함수 내에서 새롭게 정의된 a, b이기 때문에 원본은 적용되지 않았던 거다. 잉?

- 메모리 안에는 데이터가 저장되는 구역이 나뉘어져 있다.
- 머신코드 영역에는 프로그램이 실행될 때 컴파일된 바이너리가 저장된다.
- 글로벌 영역에는 프로그램 안에서 저장된 전역번수가 저장된다.
- 힙 영역에는 amlloc으로 할당된 메모리의 데이터가 저장된다.
- 스택에는 프로그램 내의 함수와 관련된 것들이 저장된다.
- 이를 바탕으로 생각하면 위의 코드에서 a, b, x, y, tmp 모두 스택 영역에 저장되지만 서로 다른 위치에 저장된 변수다. a와 b는 위에 쌓인 식판을 걷어가듯 함수 호출이 끝나면 사라져 버린다.
그럼 이 문제를 해결해보자. (자바에서는 문제가 없었다.)

- a와 b를 x와 y를 가리키는 포인터로 지정해서 문제를 해결할 수 있다.
#include <stdio.h>
void swap(int*a, int *b);
int main(void){
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(&x, &y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int *a, int *b){
int tmp = *a;
*a = *b;
*b = tmp;
}
8.8. 파일 쓰기
stack overflow, heap overflow, buffer overflow
힙 영역에서는 malloc 에 의해 메모리가 더 할당될수록, 점점 사용하는 메모리의 범위가 아래로 늘어난다.
마찬가지로 스택 영역에서도 함수가 더 많이 호출 될수록 사용하는 메모리의 범위가 점점 위로 늘어난다.
이렇게 점점 늘어나다 보면 제한된 메모리 용량 하에서는 기존의 값을 침범하는 상황도 발생할 것입니다.
이를 힙 오버플로우 또는 스택 오버플로우라고 일컫는다.
cs50 라이브러리 없이 get_int를 구현해보자.
#include <stdio.h>
int main(void)
{
int x;
printf("x: ");
scanf("%i", &x); // swap과 마찬가지 케이스로 주소를 전달
printf("x : %i\n", x);
이번에는 get_string을 구현해보자
#include <stdio.h>
int main(void)
{
char s[5];
printf("s : ");
scanf("%s", s);
printf("s : %s\n", s);
}- 여러번의 시행착오 끝에 마지막 최종본이다.
- "위 코드들에서 scanf라는 함수는 사용자로부터 형식 지정자에 해당되는 값을 입력받아 저장하는 함수입니다. get_int 코드에서 int x를 정의한 후에 scanf에 s가 아닌 &s로 그 주소를 입력해주는 부분을 유의하기 바랍니다. scanf 함수의 변수가 실제로 스택 영역 안에 s가 저장된 주소로 찾아가서 사용자가 입력한 값을 저장하도록 하기 위함입니다. 반면 get_string 코드에서는 scanf에 그대로 s를 입력해줬습니다. 그 이유는 s를 크기가 5인 문자열, 즉 크기가 5인 char 자료형의 배열로 정의하였기 때문입니다. clang 컴파일러는 문자 배열의 이름을 포인터처럼 다룹니다. 즉 scanf에 s라는 배열의 첫 바이트 주소를 넘겨주는 것이죠."
파일쓰기
사용자로부터 입력을 받아 파일에 저장하는 프로그램을 작성해보자.
#include <stdio.h>
#include <string.h>
#include <cs50.h>
int main(void)
{
//Open file
//fopen 함수를 이용해 FILE 자료형으로 파일을 불러온다. 첫 번째 인자는 파일의 이름, 두 번째 인자는 모드로 r, w, a가 있다.
FILE *file = fopen("phonebook.csv", "a");
//Get strings from users
char *name = get_string("name : ");
char *number = get_string("number : ");
//Print(write) Strings to file
fprintf(file, "%s, %s\n", name, number);
//Close file
fclose(file);
}👀 실시간으로 파일에 쓰기 되는 거 사실 신기했다. 다운로드 받아서 nubmers 같은 프로그램으로 열기를 하니 꽤 근사한 전화번호북으로 출력되었다. 내가 코드를 직접 치려니 떠올리지 못했지만, 개념은 이해할 수 있을 것 같다.
8.9. 파일 읽기
파일의 내용을 읽어서 파일의 형식이 JPEG 이미지인지 검사하는 프로그램을 작성해본다.
#include <stdio.h>
int main(int argc, char *argv[]){
// Ensure user ran program with two words at prompt
if(argc != 2){
return 1;
}
// Open file
FILE *file = fopen(argv[1], "r"); // 입력받은 파일명을 '읽기'모드로 불러온다.
if(file == NULL){
return 1;
}
// Read 3 bytes from file
unsigned char bytes[3];
fread(bytes, 3, 1, file);
// Check if bytes are 0xff 0xd8 0xff
//JPEG 파일의 첫 세 바이트는 무조건 이렇게 시작한다고 약속되어 있다.
if(bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff){
printf("Maybe\n");
}else{
printf("No\n");
}
}-
만약 argc가 2가 아니라면, 파일명이 입력되지 않았거나 파일명 외의 다른 인자가 입력되었기 때문에 1(오류)을 리턴하고 프로그램을 종료한다.
-
파일이 제대로 열리지 않으면 fopen 함수는 NULL을 리턴하기 때문에 이를 검사해서 file을 제대로 쓸 수 있는지를 검사하고, 아니라면 역시 1(오류)를 리턴하고 프로그램을 종료한다.
-
그 후 크기가 3인 문자 배열을 만들고, fread 함수를 이용해서 파일에서 첫 3바이트를 읽어옵니다. read 함수의 각 인자는 (배열, 읽을 바이트 수, 읽을 횟수, 읽을 파일)을 의미한다.
-
마지막으로 읽어들인 각 바이트가 각각 0xFF, 0xD8, 0xFF 인지를 확인한다. 이는 JPEG 형식의 파일을 정의할 때 만든 약속으로, JPEG 파일의 시작점에 꼭 포함되어 있어야 한다.
Q. JPEG 외에 다른 파일 형식도 그 형식임을 알려주는 약속이 있을까요? 있다. 그것을 파일 시그니처라고 부른다고 한다.
9. 자료구조
9.1. malloc과 pointer 복습
#include <stdio.h>
int main(void){
int *x; // 정수형 포인터 변수 x
int *y;
x = mallox(sizeof(int));
*x = 42; // malloc이 할당해준 4바이트 크기의 메모리에 가서 42를 넣어라. (x에 저장된 주소로 가서 42를 저장한다.)
// *y = 13; 이렇게만 되면 버그가 있다.
y = x;
*y = 13;
// y에게 x의 주소값을 주었다. 그리고 다음 줄로 인해 42는 사라지고 13이 덮어써진다.
}- int(4bytes) 크기의 메모리를 만들고 메모리 영역의 첫 주소를 x에 반환한다. x는 포인터 변수이기 때문에 주소를 받을 수 있다.
- malloc 함수는 할당받고 싶은 크기를 유일한 인자로 받는다.
- *는 역참조 연산자다.
- y는 포인터로만 선언되었을 뿐, 어디를 가리킬지에 대해서는 아직 정의가 되지 않았다.
초기화되지 않은 \*y는 프로그램 어딘가를 임의로 가리키고 있을 수도 있다. 따라서 그 곳에 13이라는 값을 저장하는 것이 오류를 발생시킬 수도 있다. - 안전을 생각하여 초기화하지 않은 변수에는 뭐가 있는지 모른다고 가정한다. *y로 가짜 주소를 찾아가면 코드의 메모리 문제나 세그멘테이션 오류 같은 안 좋은 일들이 발생할 수 잆다. 없거나 잘못된 주소에 접근하면 말이다. 간단히 말하면, 할당하지 않은 메모리를 사용하면 안 좋은 일이 벌어질 수 있다.
9.2. 배열의 크기 조정하기
배열의 크기를 바꾸기 위해 어떻게 해야할까? 메모리를 옮기면 된다.
#include <stdio.h>
#include <stdlib.h>
int main(void){
// int list[3];
int *list = malloc(3 * sizeof(int));
if (list == NULL){
return 1;
} // 메모리가 부족할 때 프로그램을 끝내도록 한다.
list[0] = 1; // 메모리 덩어리의 첫 번째 바이트
list[1] = 2;
list[2] = 3;
// 배열의 크기를 바꾸고 싶다.
int *tmp = malloc(4 * sizeof(int));
if (tmp == NULL){
return 1;
}
// Copy integers from old array into new array
for(int i = 0; i < 3; i++){
tmp[i] = list[i];
}
tmp[3] = 4;
// 메모리 해제
free(list);
list = tmp;
for(int i = 0; i < 4; i++){
printf("%i\n", list[i]);
}
}- 포인터 연산으로 대괄호 안에 숫자에 따라 청크 단위로 움직이게 된다. 여기에서는 4바이트 단위로.
- 배열은 본질적으로 메모리 덩어리이다.
- *(list+1) = 2; 저번에 배운 표현대로 하면 이렇게 바꿀 수도 있겠다. 그리고 출력결과는 동일하다.
int *tmp = realloc(list, 4 * sizeof(int));
if (tmp == NULL){
return 1;
}
tmp[3] = 4;
list = tmp;
for(int i = 0; i < 4; i++){
printf("%i\n", list[i]);
}- realloc 함수를 사용해서 여러 줄의 코드를 줄일 수 있다. 복사하는 코드, 메모리 해제하는 코드를 줄였다.
- 마지막에 메모리 해제를 한 번 더 추가해줘야 한다. free(list); 어느 학생이 제기한 문제였는데, 직접 valgrind로 체크해보니 메모리 누수를 확인할 수 있었다.
9.3. 연결 리스트 : 도입
자료구조
- 여러분의 컴퓨터 메모리에 정보를 각기 다른 방법으로 저장할 수 있게 해준다.
- 일종의 메모리 레이아웃, 또는 지도라고 생각할 수 있다.
배열은 각 인덱스의 값이 메모리상에서 연이어 저장되어 있었다. 그리고 크기가 고정된 메모리 덩어리여서, 크기를 늘리고 싶으면 더 많은 메모리를 다시 할당하고 복사하는 번거로운 과정을 거쳐야 했다. 물론 인덱싱해서 랜덤 접근할 수 있다는 것과 바이너리 검색 같은 곳에 적용할 수 있다는 장점이 있긴 하지만 말이다.
연결 리스트
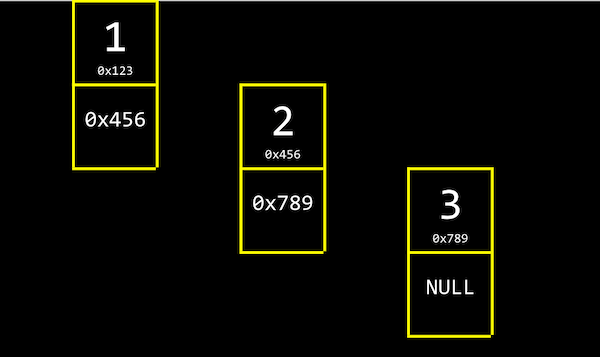
- 다음 메모리 덩어리의 주소를 가리키는 포인터를 함께 저장한다.
- 각 값이 메모리 상 여러 군데에 나뉘어져 있지만, 다음 값의 메모리 주소를 기억하고 있어서 값을 연이어 읽어들일 수 있다.
- 각 인덱스의 메모리 주소에서 자신의 갓과 함께 바로 다음 값의 주소(포인터)를 저장한다.
- 3은 다음 값이 없기 때문에 NULL(0으로 채워진 값)을 다음 값의 주소로 저장한다.
typedef struct node
{
int number;
struct node *next;
}
node;- node라는 이름의 구조체는 number와 *next 두 개의 필드가 함께 정의되어 있다.
- number는 각 node가 가지는 값, *next는 다음 노드의 주소를 가리키는 포인터가 된다.
- typedef struct 대신에 node를 함께 명시해준 것은, 구조체 안에서 node를 사용하기 위함이다.
- node는 직사각형으로 나타낼 수 있는 메모리 덩어리를 의미한다.
9.4. 연결리스트 : 코딩
#include <stdio.h>
#include <stdlib.h>
// 연결 리스트의 기본 단위가 되는 node 구조체를 정의한다
typedef struct node
{
//node 안에서 정수형 값이 저장되는 변수를 number로 지정한다.
int number;
//다음 node의 주소를 가리키는 포인터를 *next로 지정한다.
struct node *next;
}
node;
int main(void){
// list라는 이름의 node 포인터를 정의한다. 연결 리스트의 첫 번째 구조체를 가리킬 것이지만, 현재는 NULL로 초기화되어 있다. (아무것도 가리키지 않는 상태)
node *list = NULL;
// 새로운 node를 위해 메모리를 할당하고 임시 변수를 만든다.
node *n = malloc(sizeof(node));
if(n != NULL)
{
// 포인터 변수n이 가리키는 node의 number 필드에 2라는 값을 부여
n->number = 2; // (*n).number = 2;
// n 다음에 정의된 node가 없으므로 NULL로 초기화한다.
n->next = NULL;
}
// 첫 번째 node가 정의되었기 때문에 list에게 임시 변수 n이 가리키는 주소값을 부여한다.
list = n;
// list에 다른 node를 연결하기 위해 새로운 메모리를 다시 할당한다.
node *n = malloc(sizeof(node));
if(n != NULL)
{
n->number = 4;
n->next = NULL;
}
// 아래 코드도 맞지만 반복문을 활용해 시야를 멀리 보자.
// list->next = n;
// tmp 변수를 만들어 list가 가리키고 있는 구조체의 next 필드가 NULL인지 파악한다. 그럼 그게 리스트의 끝일 것이다.
node *tmp = list;
while (tmp->next != NULL)
{
tmp = tmp->next;
}
tmp->next = n;
// 리스트의 처음에 1을 끼워넣고 싶은 상황이다.
node *n = malloc(sizeof(node));
if (n! == NULL){
n->number = 1;
n->next = NULL;
}
// list의 link를 중간에 잃지 않게 하기 위한 단계
n->next = list;
list = n;
// 중간에 3을 더 추가하고자 한다면?
// 출력하는 과정
for(node *tmp = list; tmp!=NULL; tmp = tmp->next){
printf("%i\n", tmp->number);
}
// 메모리 해제하기 위해 list에 연결된 node들을 처음부터 방문하면서 free 해준다.
while(list!=NULL){
node *tmp = list->next;
free(list);
list=tmp;
}
}
malloc을 사용할 때마다 검사를 해주어야 한다. 반환된 값을 항상 체크해줘야 한다. 정밀하게 코드를 짜기 위해서n이 NULL이 아닌지 검사하고 나머지를 실행해야 한다.- n은 node를 가리키는 포인터 변수로, malloc이 반환하는 주소값을 갖는다. 그렇기 때문에 바로 n.number로 접근할 수 없었던 것이다.
- 반복 x 그림 x 구체화하면서 어쨌든 코드를 하나 하나 다 따라가니 이해는 된다. 그런데 어떻게 이런 아이디어를 생각해낼 수 있을까?
- free(list)하는 부분에서 맨 마지막에는 list->next가 null이 되는 경우가 나올텐데, 이건 상관이 없을까? 오류가 작동하지 않는가?
9.5. 연결리스트 : 시연
배열과 비교할 때 연결리스트의 장점/단점
-
새로운 값을 추가할 때 다시 메모리를 할당하지 않아도 된다. 크기를 조절하고 기존의 값을 옮기지 않고, 포인터를 바꿔주면 된다. (장점)
-
자료구조를 리스트로 만들면 역동성을 추구한 것이다. (장점)
-
임의 접근이 불가능하다. 빵 부스러기를 찾아 하나하나 세어보아야 하고, 어떤 장소로 바로 갈 수는 없다. (단점)
-
임의 접근으로 이진탐색 알고리즘을 잘 사용할 수 있는데, 그 능력을 잃어버린다. (단점)
-
연결 리스트에 값을 추가하거나 검색하는 경우, 해당하는 위치까지 각 node들을 따라 이동해야 한다. 따라서 연결 리스트의 크기가 n일 때, 실행 시간은 O(n)이 된다. 배열의 경우 임의 접근이 가능하기 때문에, 정렬되어 있는 경우, 이진 검색을 이용하면 O(log n)의 실행 시간이 소용되는 것에 비해 불리하다. (단점)
즉, 데이터 구조는 각각 장단점이 존재한다. 프로그래밍을 할 때 목적에 부합하는 가장 효율적인 데이터 구조를 고민해서 사용하는 것이 중요하다.
9.5. 연결리스트 : 트리
포인터와 자료 구조를 사용해서 메모리에 여러 요소를 잇고 더 멋진 무언가를 만들 수 있다. 계층적인 2차원 구조의 가계도에 대해 알고 있을 거다. 여기에서 영감을 얻는다.
1차원적인 자료구조만 아니고 수직적인 개념을 사용해서 더 흥미로운 방식으로 요소를 배열한다면? 배열과 연결리스트의 장점을 가져와 본다.(이진 탐색도 가능하게 하고, 역동성도 갖는다.) 더 많은 공간을 할당하고 자료구조들을 이어 붙여서 개념상 2차원으로 만든다.
전에는 next라는 하나의 포인터만 가졌지만, 두 개의 포인터를 가진 새로운 구조체를 만든다.
typedef struct node{
int number;
struct node *left;
struct node *right;
}
node;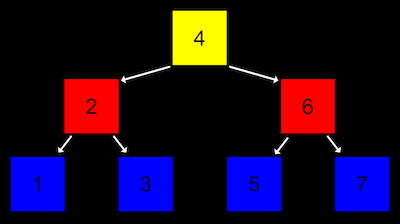
트리는 연결리스트를 기반으로 한 새로운 데이터 구조이다.- 연결리스트에서의 각 노드 (연결 리스트 내의 한 요소를 지칭)들의 연결이 1차원적으로 구성되어 있다면,
트리에서의 노드들의 연결은 2차원적으로 구성되어 있다고 볼 수 있다. - 각 노드는 일정한 층에 속하고, 다음 층의 노드들을 가리키는 포인터를 가지게 된다.
- 트리의 한 예다. 나무가 거꾸로 뒤집혀 있는 형태를 생각하면 된다.
- 가장 높은 층에서 트리가 시작되는 노드를
루트라고 한다. 루트 노드는 다음 층의 노드들을 가리키고 있고, 이를자식 노드라고 한다. - 왼쪽에 있는 모든 것들이 더 작고, 오른쪽에 있는 모든 것들이 더 크다. 이것은
재귀적 정의다. 어떤 노드를 보든 간에 참이기 때문이다. - 위 그림은
이진 검색 트리이다. 노드가 구성되어 있는 구조를 살펴보면 일정한 규칙이 있다. 이 새로운 자료 구조는 2차원이고 재귀적으로 정의되어 있다. 이진 검색을 수행하는 데 유리하다. - 이 트리의 높이는 로그를 따른다. 정확히는 밑이 2인 로그다. 트리에 7개의 요소가 있다면 어떤 값을 찾는데 3단계 밖에 걸리지 않을 것이다. (코드 스테이츠 문제가 결국 이 개념을 묻는 것이었구나.)
//이진 검색 트리의 노드 구조체
typedef struct node
{
// 노드의 값
int number;
// 왼쪽 자식 노드
struct node *left;
// 오른쪽 자식 노드
struct node *right;
} node;
// 이진 검색 함수 (*tree는 이진 검색 트리를 가리키는 포인터)
bool search(node *tree)
{
// 트리가 비어있는 경우 ‘false’를 반환하고 함수 종료
if (tree == NULL)
{
return false;
}
// 현재 노드의 값이 50보다 크면 왼쪽 노드 검색
else if (50 < tree->number)
{
return search(tree->left);
}
// 현재 노드의 값이 50보다 작으면 오른쪽 노드 검색
else if (50 > tree->number)
{
return search(tree->right);
}
// 위 모든 조건이 만족하지 않으면 노드의 값이 50이므로 ‘true’ 반환
else {
return true;
}
}
- search라는 함수는 숫자 50이 트리에 있으면 true 아니면 false를 반환한다. 어떻게 트리를 탐색할까? 트리의 루트의 주소를 입력받는다. 트리의 가장 위에 있는 루트라는 노드를 알려주면 된다. 트리의 루트를 알면 모든 곳으로 갈 수 있다. 연결리스트에도 마찬가지였다.
- 실행 속도 측면에서 보면 이진 탐색 트리의 탐색 속도는 어떨까? 이진 탐색이 가능한 배열과 같은 실행 시간을 가진다. O(log n)이 된다.
- 이진 탐색 트리에 값을 추가하려면? 그저 0을 넣고 8을 넣을 수 없다. 트리의 균형이 사라질 것이다. 더 높은 수준의 수업에서 다룰 것이다. 이진 검색 트리의 균형을 유지할 수 있는 알고리즘이 있다. 어떤 값을 넣으면 요소들을 움직이게 되는 것이다. 그냥 포인터를 업데이트하는 것이다.
- 이진 검색 트리를 활용하였을 때 검색 실행 시간과 노드 삽입 시간은 모두 O(log n)이다. (노드 삽입 시간은 잘 모르겠다.)
9.5. 해시테이블
해시테이블은 배열과 연결리스트의 조합이다. 연결 리스트의 배열이다. 해시 테이블에서는 단어나 이름같은 입력값이 들어온다면, 그 단어에 포함된 문자를 보고 어디에 그 이름을 넣을지 결정하는 방식이 흔하게 사용된다.
여러 값들을 몇 개의 바구니에 나눠 담는 상황을 생각해보자. 강의에서는 강의장 단상 위에 A부터 Z까지 라벨링한 바구니 26개를 일렬로 늘어트려 놓고, 해리포터 출연진들의 이름표를 넣는 상황을 연출했었다.
해시 함수라는 맞춤형 함수를 통해 어떤 바구니에 담기는 지가 결정 된다. 바구니에 담기는 값들은 바구니에서 새롭게 정의되는 연결 리스트로 이어진다.
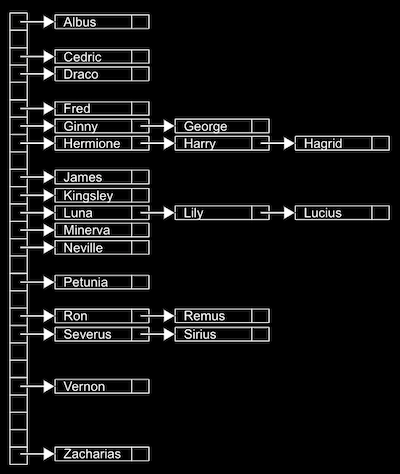
- 사람의 이름이 해시테이블에 저장된다고 생각해보자.
- 해시 함수는 이름의 가장 첫 글자인 경우다.
- 알파벳 개수에 해당하는 총 26개의 포인터들이 있을 수 있고, 포인터는 알파벳을 시작으로 하는 이름들을 저장하는 연결 리스트를 가리키게 된다. (배열은 임의 접근이 가능하기 때문에 바로 접근할 수 있다는 게.. 사람이 걸어서 가는 것과 비교했을 때도 재밌는 포인트였다.)
- 만약
해시 함수가 이상적이라면, 각 바구니에는 단 하나의 값들만 담기게 될 것이다. 따라서검색 시간은 O(1)이 된다. 하지만 그렇지 않은 경우, 최악의 상황에는 단 하나의 바구니에 모든 값들이 담겨서 O(n)이 될 수도 있다. (강의에서는 바구니를 이름의 첫 세글자로 분류하는 것까지 보여줬었다) - 일반적으로는 최대한 많은 바구니를 만드는 해시 함수를 사용하기 때문에 거의 O(1)에 가깝다고 볼 수 있습니다.
시간과 공간 사이의 균형!
"아주 이상적인 해시 함수를 가지고 있어서 이름표들이 각각 다른 결과를 가져서 충돌이 서로 일어나지 않도록 하는 알고리즘을 코드로 구현할 수 있다면, O(1)을 가질 수 있다. 얼마나 많은 공간을 사용할 것인지, 이상적인 해시 함수를 찾기 위해 얼마나 많은 노력을 할 것인지 그 사이의 긴장 상태이다. 해시 테이블은 탐색하는 실행 시간이 1이 될 수도 있다. 만약 모든 이름표가 각기 다른 바구니에 들어간다면 말이다. 하지만 여전히 같은 글자로 시작하는 이름이 많으면, 엄밀히 말하면, 해시 테이블은 O(n)이다. 그럼에도, 모든 이름을 연결 리스트나 배열에 넣는 것보다는 이편이 훨씬 빠르다.
9.6. 트라이
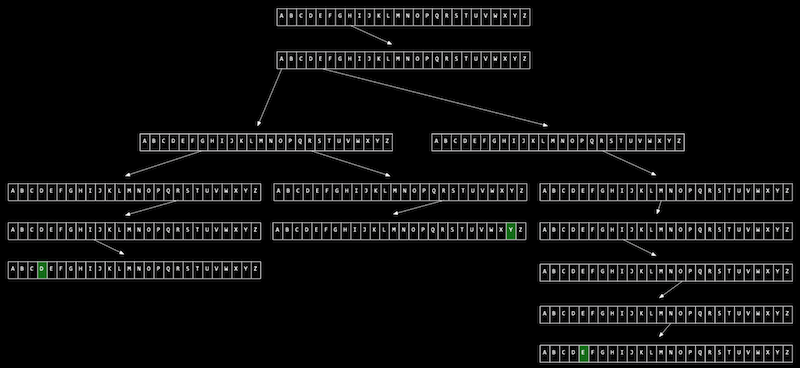
트라이는 기본적으로트리 형태의 자료 구조이다. 특이한 점은 각 노드가배열로 이루어져있다는 것이다.- 여기에서는 영어 알파벳으로 이루어진 문자열 값을 저장한다면, 이 노드는 a부터 z까지의 값을 가지는 배열이 된다. 배열의 각 요소, 알파벳은 다음 층의 노드(a-z 배열)를 가리킨다.
- 트라이에서 값을 검색하는 데 걸리는 시간은 문자열의 길이에 의해 한정된다. 일반적인 영어 이름의 길이를 n이라고 했을 때, 검색 시간은 O(n)이 되지만, 대부분의 이름은 그리 크지 않은 상수값이기 때문에 O(1)이라고 볼 수 있다.
9.7. 스택, 큐, 딕셔너리
우리가 여태껏 배운 배열, 연결 리스트, 해시 테이블, 트라이 외에도 많은 자료 구조들이 있다. 위의 자료구조를 기반으로 문제를 해결하는 새로운 자료 구조를 만들 수도 있다.
큐
- 메모리 구조에서 살펴봤듯이 값이 아래로 쌓이는 구조다.
- 값을 넣고 뺄 때 ‘선입 선출’ 또는 ‘FIFO’라는 방식을 따르게 된다. 가장 먼저 들어온 값이 가장 먼저 나가는 것이다. 은행에서 줄을 설 때 가장 먼저 줄을 선 사람이 가장 먼저 업무를 처리하게 되는 것과 동일하다.
- 배열이나 연결 리스트를 통해 구현 가능하다.
스택
- 메모리 구조에서 살펴봤듯이 값이 위로 쌓이는 구조다.
- 값을 넣고 뺄 때 ‘후입 선출’ 또는 ‘LIFO’라는 방식을 따르게 된다. 가장 나중에 들어온 값이 가장 먼저 나가는 것이다.
- 뷔페에서 접시를 쌓아 뒀을 때 사람들이 가장 위에 있는(즉, 가장 나중에 쌓인) 접시를 가장 먼저 들고 가는 것과 동일하다.
역시 배열이나 연결 리스트를 통해 구현 가능합니다.
