크롤링 관련 프로젝트를 진행하며 신경 써야할 부분에 대해서 정리해보려고 한다.
사실 내가 구현한 프로젝트는 스크래핑이라 지칭하는게 정확하지만, 현 포스트에선 크롤링이라 지칭하겠다.
@Scheduled(cron = "0 0/15 * * * *") // 매 N분마다 실행
fun startCrawling() {
//crawlers는 크롤링 대상 사이트마다 구현된 빈 List
crawlers.forEach { crawler ->
rawler.crawl()
}
}보통 Spring 환경에서 크롤링을 구현하면 위처럼 @Scheduled 어노테이션을 사용해서 데이터를 주기적으로 최신화 할 것이다.
단순히 세팅을 이 정도만 한다면 아래와 같은 문제가 발생할 것이다.
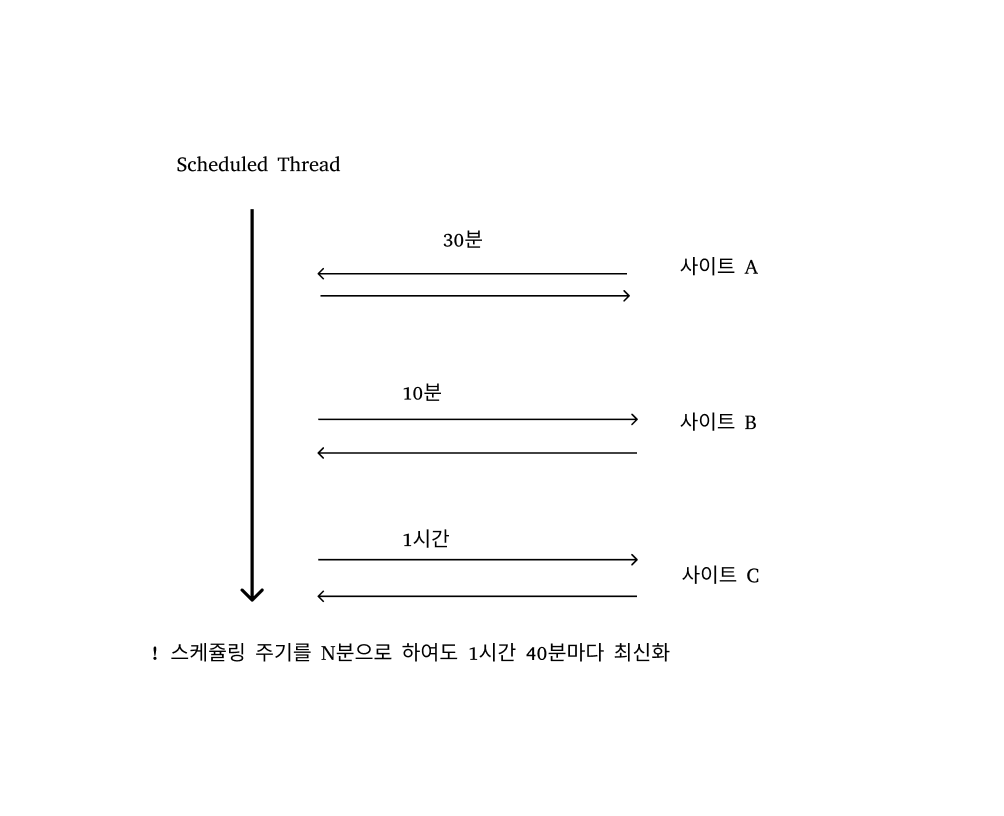
문제: Scheduled 작업은 싱글 쓰레드로 진행된다.
Spring 환경에서 아무 설정도 하지 않는다면 Scheduled 작업은 싱글 쓰레드로 진행된다.
그렇기에 위와 같은 문제가 발생할 수 있다.
@Configuration
@EnableScheduling
class CrawlerSchedulerConfig : SchedulingConfigurer {
override fun configureTasks(taskRegistrar: ScheduledTaskRegistrar) {
val threadPoolTaskScheduler = ThreadPoolTaskScheduler()
threadPoolTaskScheduler.poolSize = 10
threadPoolTaskScheduler.setThreadNamePrefix("scheduler-")
threadPoolTaskScheduler.initialize()
taskRegistrar.setTaskScheduler(threadPoolTaskScheduler)
}
}그렇다면 이와같은 설정으로 쓰레드풀을 늘릴 수 있겠다.
그렇다면 이걸로 충분할까? 아직 문제가 더 남았다.
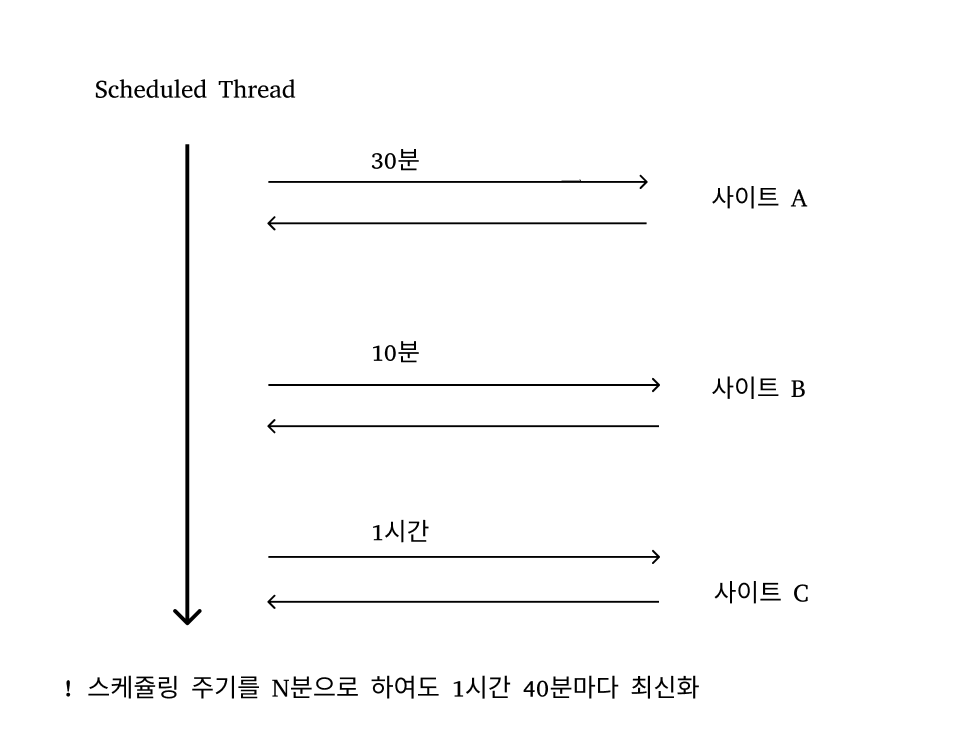
문제: 하나의 스레드가 작업을 완료하는데 시간이 매우 길다면?
그림상으로 하나의 쓰레드가 작업을 완료하는데 100분의 시간의 걸린다.
소스 사이트가 늘어날수록 이 시간은 길어질 것이다
그런데 만약 10분마다 최신화 작업이 스케쥴링 되어 실행되다면?
쓰레드를 할당받기 위해 대기하는 테스크가 점점 쌓일 수도 있고 어쩌면 OOM 에러가 발생할 수도 있다.
일단은 OOM와 같은 치명적인 에러를 발생시키지 않는 것이 중요하기에
// 쓰레드폴에서 쓰레드가 고갈되면 쓰레드 얻으려고 대기하기를 거부 (
threadPoolTaskScheduler.setRejectedExecutionHandler(ThreadPoolExecutor.AbortPolicy())이와 같은 옵션을 추가할 수 있다.
하지만 여전히 최신화 주기가 느려지는 문제가 발생할 수 있다. 다음과 같이 말이다
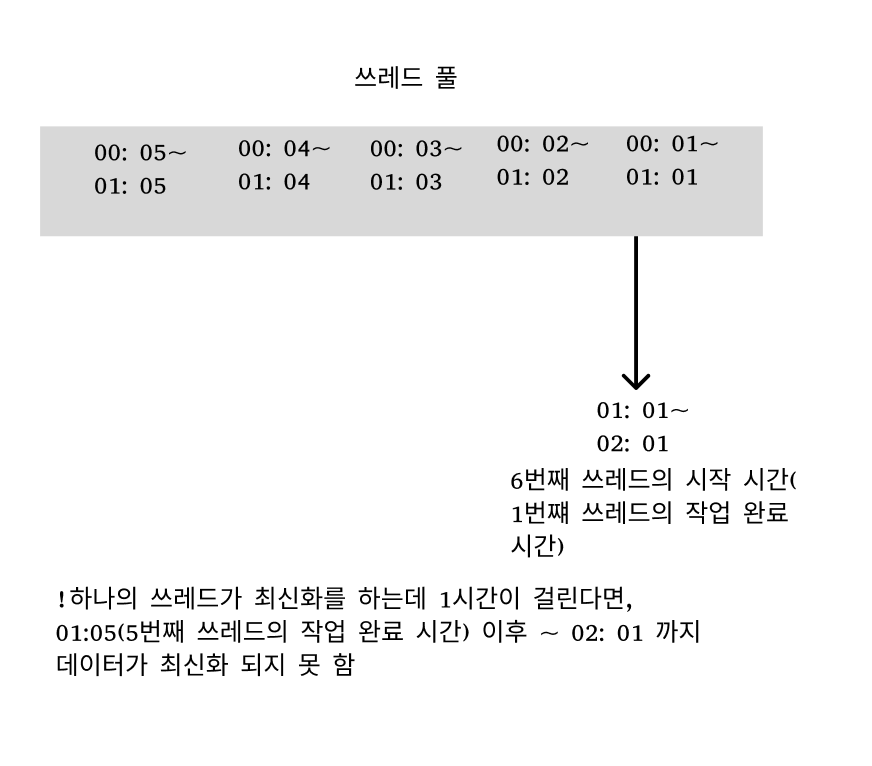
그렇기에 쓰레드풀에 스케쥴링 쓰레드를 빠르게 반환하는 방법에 대해서도 고민해보아야한다.
사이트마다 쓰레드를 새롭게 배정하여 비동기적으로 수행한다.
@Async("thread-per-crawling-source")
override fun crawling() {크롤링 사이트마다 쓰레드를 새롭게 배정하고 비동기적으로 수행하면 하나의 Scheduled 쓰레드가 작업을 완료하는데 걸리는 시간은, 크롤링하는데 최고로 시간이 오래 걸리는 사이트의 작업 시간일 것이다.
그런데 여기서 Selenium을 사용함으로 고려해야할 점이 있다.
Selenium은 WebDriver를 통해서 실제 브라우저에 접속하고 지정된 작업을 수행한다.
그리고 우리가 비동기적으로 작업을 수행하는 쓰레드를 생성하여 멀티 쓰레드 환경을 구성하였기에
이 WebDriver가 싱글톤이나 빈으로 등록하여 공유되는 상황이 되지 않도록 주의해야한다. (WebDriver는 현재 브라우저에 대한 정보 등을 기억한다. 아마 이는 Selenium뿐 아니라 다른 웹 자동화 라이브러리도 다 비슷할 것이라 예상된다)
즉 @Async어노테이션 붙은 메소드마다,
WebDriver를 새로 만들어야한다
@Async("thread-per-crawling-source")
override fun crawling() {
val webDriver = WebDriver()
doSomeThingWith(webDriver,"https:~~")
}
fun doSomethingWith(webDriver: WebDriver, url: String){
}문제: WebDriver를 매번 함수 인자에 넣어야한다.
fun doSomethingWith(webDriver: WebDriver, url: String)위와 같이 단순한 구조에선 괜찮을 수 있지만 비즈니스 로직에서 webDriver를 계속 함수 인자에 포함시켜줘야하며, 이 때문에 클래스 구조가 복잡해질 수록 유지보수성은 떨어질 것이다.
자, 목적은 쓰레드마다 WebDriver가 독립적으로 존재해야함 이다.
그렇다면 매번 함수 인자에 WebDriver를 넘겨주는 것보단, ThreadLocal에 WebDriver를 저장 함으로 쉽게 목적을 달성할 수 있다.
자세히 ThreadLocal에 WebDriver를 배정하는 코드를 보자
class WebDriverManager {
private var threadLocalDriver = ThreadLocal<WebDriver>()
fun getWebDriver(): WebDriver =
threadLocalDriver.get()
?: throw IllegalStateException("WebDriver 등록 실패")
fun setNewWebDriver() {
threadLocalDriver.set(WebDriverFactory.chromeDriver())
} @Bean("webdriver-per-thread")
fun asyncThreadTaskExecutor(): ThreadPoolTaskExecutor =
ThreadPoolTaskExecutor().apply {
corePoolSize = 10 // 항상 유지되는 최소 스레드 개수
maxPoolSize = 20 // 최대 20개까지 확장
setThreadNamePrefix("crawl-thread")
setTaskDecorator { runnable ->
Runnable {
/*
쓰레드마다 서로 다른 WebDriver를 배정하기 위해
쓰레드 할당시, WebDriver등록
쓰레드 반환시, WebDriver제거
*/
webDriverManager.setNewWebDriver()
try {
runnable.run()
} finally {
webDriverManager.removeWebDriver()
}
}
}
initialize()
}이처럼, ThreadPoolTaskExecuter.setTaskDecorator()를 통해
쓰레드 풀에서 작업을 위해 쓰레드가 할당/반환될 때, WebDriver를 ThreadLocal에 배정/제거하는 작업을 수행할 수 있다.
이제 아래와 같이 WebDriverManager를 통해서만 WebDriver에 접근할 수 있다.
@Async("webdriver-per-thread")
override fun crawling() {
doSomeThingWith()
}
fun doSomethingWith(url: String){
// url만 넘겨주면 webDriverManager가 쓰레드로컬에 있는 WebDriver에 접근하여 작업을 수행한다
webDriverManager.getWebDriver(url).~
}정리
- Spring에서 Scheduled 쓰레드는 싱글 쓰레드로 작동한다.그렇기에 오래 걸리는 크롤링과 같은 작업을 할 때는 멀티 쓰레드 환경을 고려해야한다.
- 무한정 쓰레드를 배분하면 OOM이 발생할 수 있기에 쓰레드풀을 사용하는게 좋을 것이다. 하지만 여전히 이는 작업 시간이 길다면 쓰레드를 얻는 시점이 밀리고 밀려 Scheduled 주기가 지켜지지 않을 수 있다.
- 비동기적으로 크롤링을 수행하여, 최대한 Scheduled 쓰레드를 반납하는 시간을 단축시킬 수 있다. 그리고 비동기적으로 작업을 수행한다면 크롤링 작업을 수행하는 WebDriver를 쓰레드마다 독립적으로 관리해야한다.
- 독립적으로 메소드마다 Webdriver를 생성하고 함수 인자로 넘겨주기보단,
ThreadLocal에 저장하고 관리하는 것이 비즈니스로직과 관심사를 분리하고 유지보수에 용이하다고 생각한다.
