pyspark - kafka streaming

사진과 같이 Kafka broker에 저장된 토픽을 structured streaming을 통해 PySpark를 이용하여 실시간 스트리밍하는 것을 도전해보았다.
(상당히 많은 오류를 접하며 굉장히 당황스러웠다...)
+) 2022.02.23
https://velog.io/@statco19/PySpark-Kafka-Streaming2
1편에서 부족했던 부분을 보완하여 2편을 작성하였다.
jar files
본인에게 맞는 kafka 버전과 spark 버전을 꼭 확인한 이후, 버전에 맞게 진행해야 한다.
우선 kafka가 설치되어 있는 폴더로 가서 jars 디렉토리에 접근한다(필자의 경우 ~/kafka_2.12-2.5.0/jars).
아래의 jar 파일이 다운로드 되어 있는지 확인한다.
kafka-clients-2.5.0.jar
spark-streaming-kafka-0-10_2.12-3.2.0.jar
spark-streaming_2.12-3.2.0.jar
spark-sql-kafka-0-10_2.12-3.2.0.jar
spark-token-provider-kafka-0-10_2.12-3.2.0.jar설치되어 있지 않다면 jars 디렉토리에서 wget 명령어를 통해 파일을 설치한다.
각각의 파일을 구글링하면 mvnrepository 사이트에서 url 링크를 얻을 수 있다.
https://mvnrepository.com/artifact/org.apache.spark/
위의 url에 접속하면 여러 가지 필요한 jar 파일을 구할 수 있다.
예시)
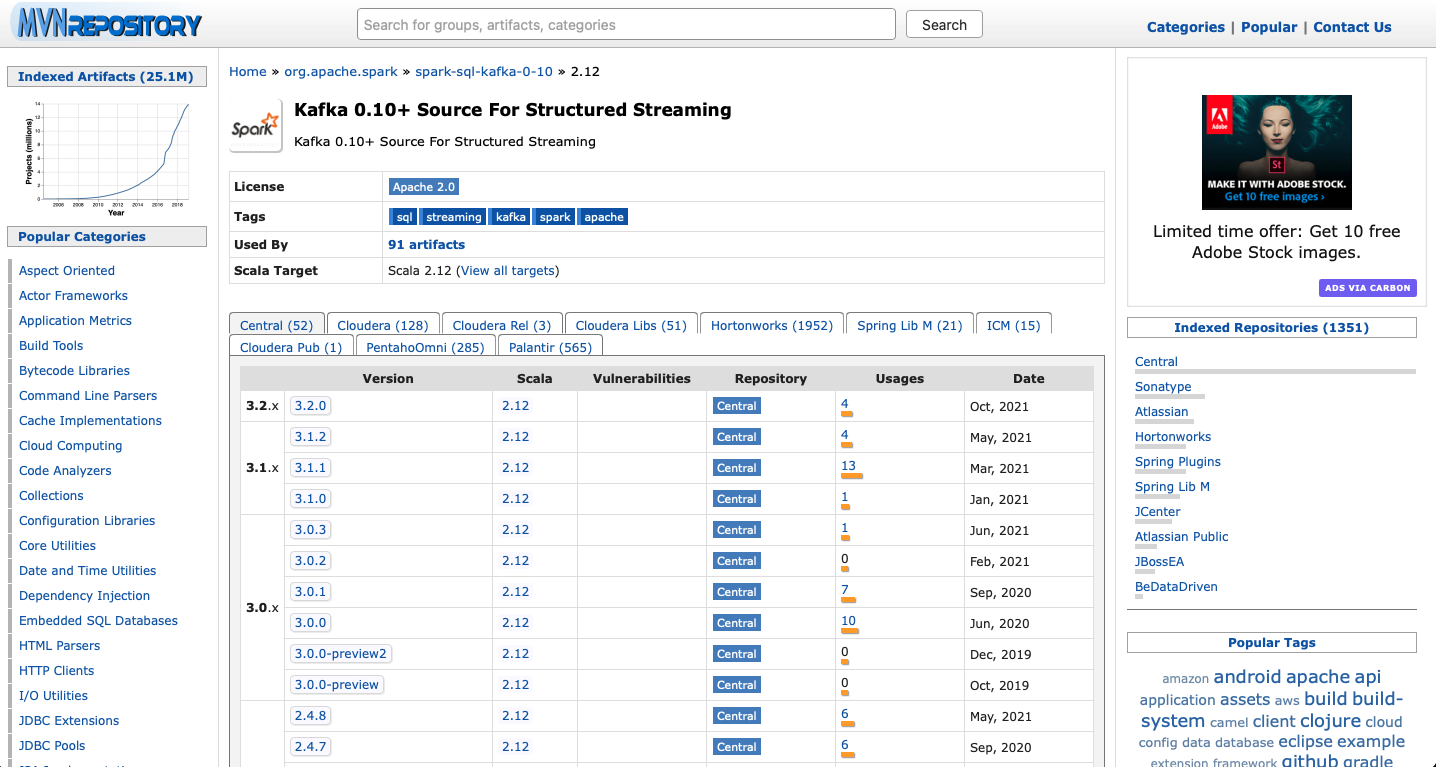
필자는 스파크가 3.2.0 버전이기에 3.2.0 버튼을 눌러 들어가고
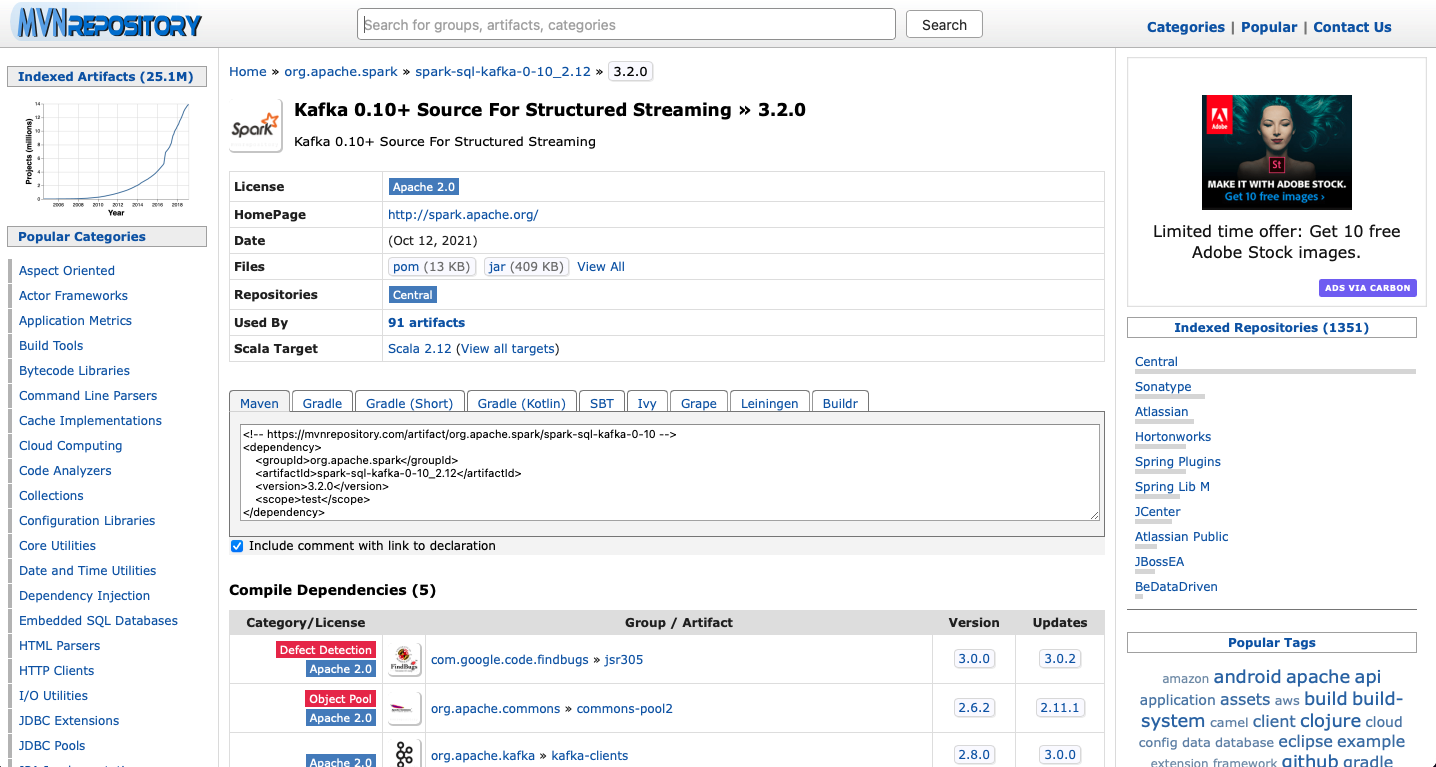
여기 View All 버튼을 누르면
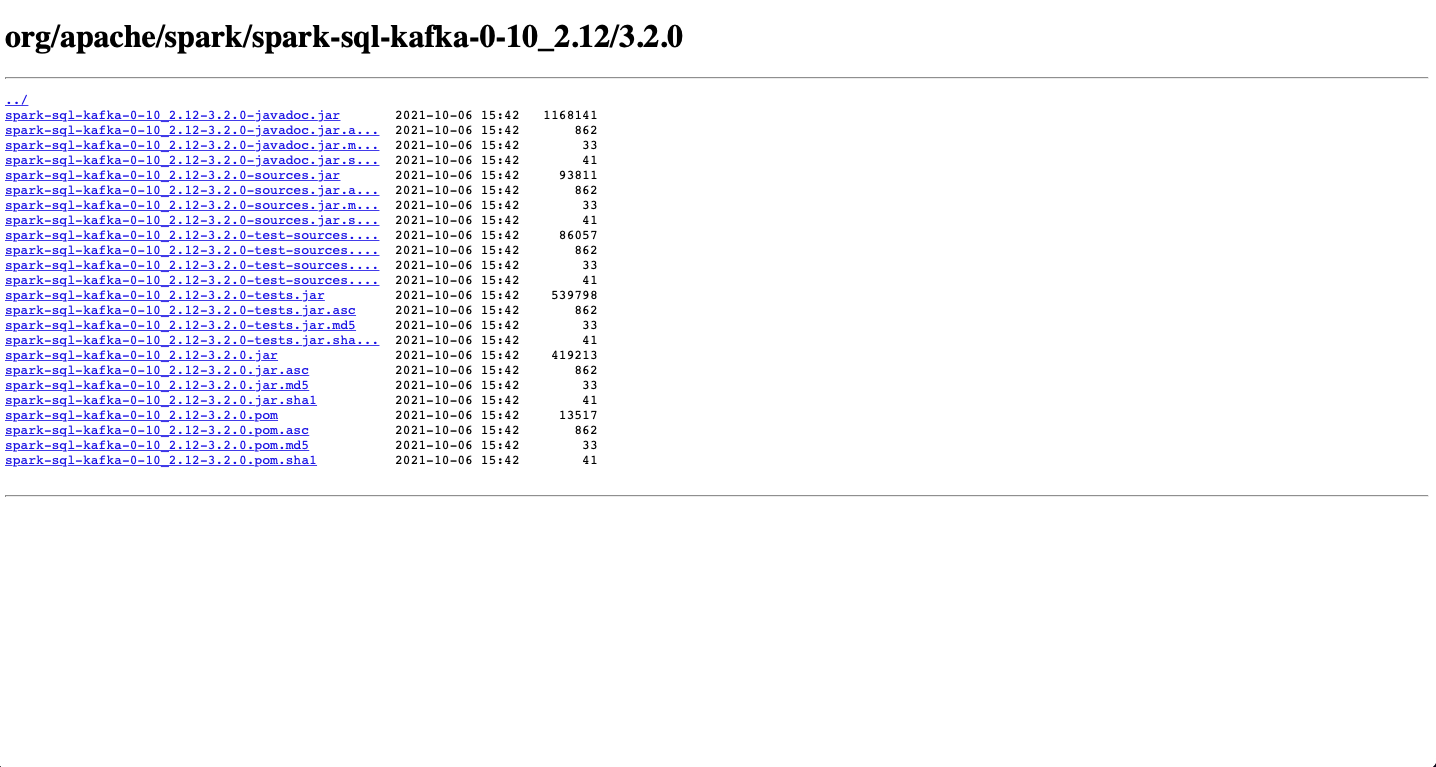
위 화면에 오게 된다. 여기서 필요한 알맞은 버전의 .jar 파일이 존재함을 확인하고,
wget
wget https://repo1.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.12/3.2.0/spark-sql-kafka-0-10_2.12-3.2.0.jar와 같은 형식으로 wget 명령어로 필요한 jar 파일을 설치해 줄 수 있다.
여기까지 왔으면 절반은 성공했다.
streaming code(python)
그 이후 jupyter나 .py파일을 생성한 이후
import os
spark_version = '3.2.0'
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.0,org.apache.kafka:kafka-clients:2.5.0:{}'.format(spark_version)
from pyspark.sql.functions import *
from pyspark.sql.types import *
from pyspark.sql import *
from pyspark.sql.functions import udf
from pyspark.sql.functions import col, pandas_udf, split
kafka_bootstrap_servers = '{kafka-server-IP}:9092'
topic = 'topic name'
spark = SparkSession \
.builder \
.appName("PySparkShell") \ # sc 커맨드로 pyspark 구동을 확인할 때 나오는 appName을 사용했다.
.getOrCreate()
df = spark \
.readStream\
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("startingOffsets", "earliest") \
.option("failOnDataLoss","False") \
.option("subscribe", topic) \
.load()위의 코드를 실행하면 df라는 데이터프레임 변수와 카프카 브로커가 연동이 되었다. 이제 스트리밍이 가능해진 것이다!(여기까지 찾는데 무려 4시간 이상이 소요되었다..)
df.printSchema()
# 결과
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)writeStream
아쉽게도 카프카 데이터는 스키마만 확인할 수 있고, 데이터 자체를 df.show() 메서드로 나타낼 수 없다.
그 대신 아래의 코드로 읽어올 수 있다.
import time
query = df.writeStream.format("console").start()
time.sleep(10) # sleep 10 seconds
query.stop()위의 코드 결과를 첨부하려 했으나 가상머신 위에서 돌고 있던 JVM이 메모리 부족을 호소하며 더 이상 카프카에서 아무 것도 할 수 없게 되었다. 가상머신이 AWS free tier 머신이라 RAM이 1GB 밖에 되지 않아 부족했던 모양이다. 다음 번에는 유료 가상머신에 카프카를 설치하여 재시도할 생각이다. (이후 성공하면 결과를 첨부해 수정할 예정이다)
df_read = spark \
.read\
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("startingOffsets", "earliest") \
.option("failOnDataLoss","False") \
.option("subscribe", '2021-test') \
.load()위의 코드는 readStream이 아닌 read로 카프카 데이터를 읽어오는 코드이다. 이 코드 역시 카프카 데이터를 읽어온 것이기 때문에 .show() 메서드는 사용할 수 없다.
