목적
csv파일의 자료들을 데이터베이스에 넣기.
들어가며
csv파일을 토대로 데이터베이스의 자료를 입력하는 방법에대해 알아보자.
데이터를 저장할때는 서로 관계된 정보끼리 각 테이블에 잘들어가야한다.
csv파일은 데이터베이스구조와 모양이 같지 않은경우가 많다 .그리고 테이블 컬럼순서가 제각각일수있다.
카테고리 테이블따로 음료테이블 따로있는데 각음료는 메뉴랑 카테고리를 ForeignKey로 가지고있을것이고 이렇게 onetomany, manytomany 관계의 자료를 다룰떄 각데이터에 알맞은 ForeignKey를 어떻게 찾고 매칭시켜서 데이터베이스에 입력할수있는지 알아보자.
시작
준비물: 준비한 데이터(csv파일)
1.먼저 장고 쉘에서 데이터를 조회해보자.
쉘을 실행시킨뒤 우리가 다룰 메뉴 카테고리 드링크 테이블을 불러보자
>>>from product.models import Menu, Category, Drink
>>>Menu.objects.all()그럼 쿼리셋이 비어있을텐데 이제부터 csv파일에 있는 메뉴데이터를 입력해서 메뉴테이블을 채워보자.
그럼 csv파일을 파이썬파일로 어떻게 다루는지 먼저 알아보자
일단 db를 생성할건데 그전에 아래와 같은 파일을 만들것이다.
vi db_uploader.py제일먼저 기본적은 모듈을 불러오자.
import os
import django
import csv (css 파일 쓸꺼니까)
import sys지금 django내부에 있는 views나 models파일이 아닌 외부 파이썬 파일을 작성하고 있기때문에 이 내용이 장고에 적용될수 있도록 설정을 바꿔준다.
os.environ.setdefault(“DJANGO_SETTINGS_MODULT”, “starbucks_sqlite.settings”)settings앞에 경로는 내가 만들어준 프로젝트 이름임
django.setup() 적용을 시켜주고
from product.models import Menu, Category, Drink 모델을 불러온다
가지고있는 csv파일의 경로도 변수화시켜 저장하자
CSV_PATH_PRODUCTS = ‘./products.csv’
with open(CSV_PATH_PRODUCTS) as in_file: (파이썬 내장기능으로 파일열기 가능)(in file이라는 이름으로 열것임)
data_reader = csv.reader(in_file)
for row in data_reader:
print(row) (참고)csv모듈과 관련된 함수가 궁금하다면 구글링을 해보도록하자.
한줄씩 한줄씩 읽어주기 떄문에 그줄을 기준으로 for loop을 돌려준다
python db_uploader.py. (프로젝트 메인 디렉토리에서)
그러면 파이썬이 준비했던 csv파일을 읽어서 한줄씩 프린트 해주었다.
메뉴만 따로 부르기
근데 우리는 메뉴를 넣어야되니까 메뉴만 따로 불러보도록하자
각줄의 컬럼들이 그러니까 메뉴 카테고리 상품 컬럼이 리스트안에 들어가있는걸 알수 있는데, 각줄의 가장 첫번쨰가 메뉴컬럼이 되는걸 알수있다.
저위에 포문에서 print(row[0])
그럼 메뉴 음료 푸드 상품만 프린트될텐데 빈데이터(빈칸) 들이 있을텐데 그게 로우의 0번쨰 데이터가 빈칸이라그렇다.
따라서 빈칸이 아닐때만 프린트해보자
with open(CSV_PATH_PRODUCTS) as in_file: (파이썬 내장기능으로 파일열기 가능)(in file이라는 이름으로 열것임)
data_reader = csv.reader(in_file)
for row in data_reader:
if row[0] != ‘ ’:
print(row[0])그럼 빈공간없이 메뉴음료푸드상품이 한 열로 나온다.
물론
if row[0]:
print(row[0])으로해도 나온다.
근데 우리가 적용을 해서 저장해야될 데이터는 음료부터 상품의 끝까지이지
헤드들은 ( 메뉴, 카테고리, 상품) 필요가 없다.
첫번쨰 부터 읽어져서 같이 프린트 된거지 첫번쨰줄을 우리는 무시해야됌
첫줄을 읽지 않아도 되기떄문에 첫줄을 스킵하는 방법에 대해 알아보자
구글링 예제: HOW TO SKIP FIRST LINE IN CSV?
그럼 폴룹을 돌리기전에
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
print(row[0])그러고 python db_uploader.py 하면 메뉴뺴고 음료 푸드 상품만나왔는데 이제 이기능을 잘쓰도록한다.
테이블에 입력하기
그럼 이제 프린트만 할께 아니고 메뉴테이블에 입력을 하고싶은것인데,
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
Menu.objects.create(name = menu_name)프린트만 해주는게 아니고 메뉴를 크리에이트 해줄것인데 네임이 어떻게 될까. 로우의 0번째 더확실히 하게위해 네임이라는 변수에 로우의 0번쨰 인덱스데이터를 담아주고
실행하면 이론적으로 테이블에 데이터가 들어가야 할것이다.
다시 쉘을 켜보자
from product.models import Menu
Menu.objects.values()데이터베이스에서 직접 보도록하자.
sqlite킨 터미널에서
.tables
select * from menus;지금 음료 푸드 상품 이 데이터 베이스안에 들어가있는것을 알수 있다.
이렇게 csv파일에서 데이터를 가지고 올수있다.
이번엔 좀더 복잡한 데이터를 가져와보자
심화
이번에는 카테고리를 같이 넣는 방법에 대해 알아보자
자 메뉴 데이터를 입력했으니 이제 카테고리 데이터를 입력해보자
카테고리 데이터를 입력할떄 주의해야할점은 포린키를 가지고 있는 메뉴의 아이디를 함꼐넣여줘야 한다는것인데, 그래서 카테고리자료를 불러온다음에 해당하는 메뉴의 아이디값을 다시 찾아오는게 중요하다.
한번해보자
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
Menu.objects.create(name = menu_name)여기서 메뉴를 입력하는 부분을 지우고
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]. #카테고리의 네임은 로우의 1번쨰 인덱스가 될것이다.
print(category_name)python db_uploader.py 으로 실행해보면 우리가 가지고있는 카테고리 데이터들이 한줄에 입력된다.
카테고리 이름과 메뉴이름을 같이한번 뽑아 보도록하자
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]. #카테고리의 네임은 로우의 1번쨰 인덱스가 될것이다.
print(menu_name, category_name)
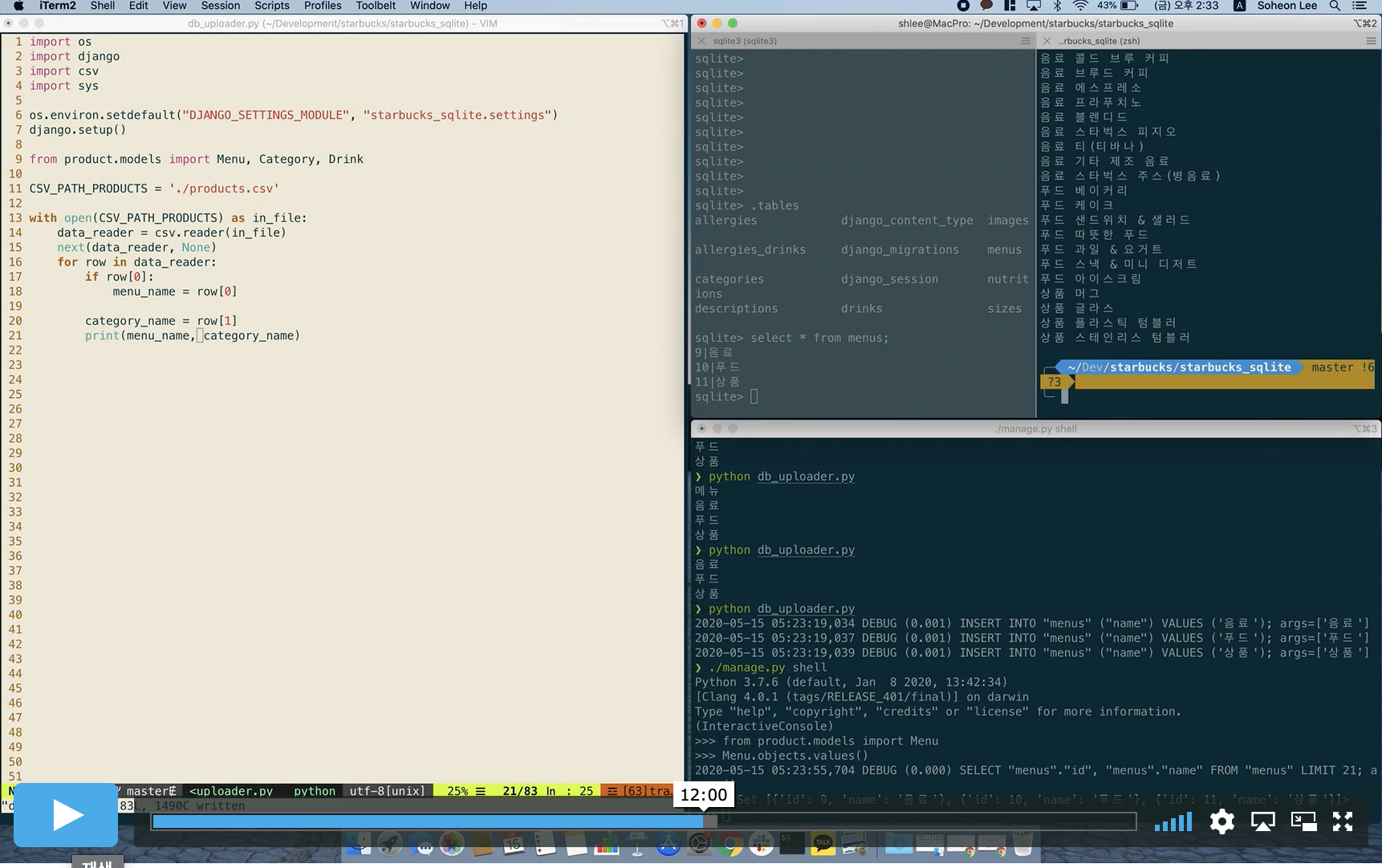
우리가 필요로한건 이 카테고리에해당하는 메뉴의 아이디이기 떄문에 메뉴의 아이디를 뽑아보도록 하자.
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]
menu_id = Menu.objects.get(name = menu_name).id # 메뉴네임을 가지고있는 메뉴객체를 가져와서 그객체의 아이디에 접근해봅니다.
print(menu_id, category_name)프린트해보자
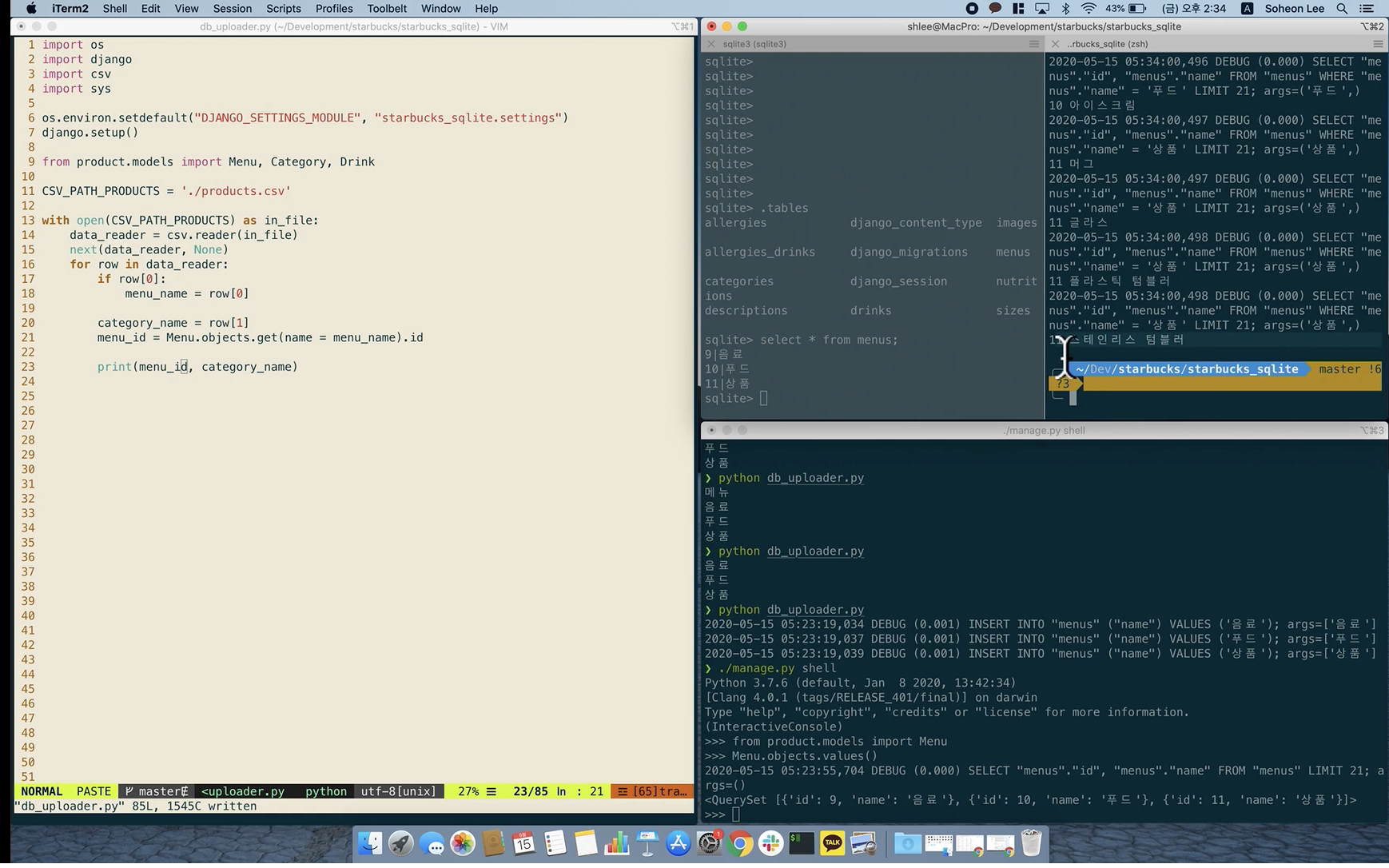
푸드의 아이디 10을 부여받은 아이들과 상품의 아이디11을 부여받은 아이들의 목록을 확인할수잇다.
그럼
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]
menu_id = Menu.objects.get(name = menu_name).id
Category.objects.create(name = category_name, menu_id = menu_id)
현재 카테고리 테이블에 아무것도 없음을 확인해보자
from product.models import Menu, Category, Drink
Category.objects.all() 그럼 쿼리셋이 비어있는것을 볼수있고
그다음 sql이 켜진 터미널에서도
select * from categories;
``` 해보면 아무것도 없다
**하지만 우리가 카테고리를 업로드하는 db업로더를 실행하게되면 (python db_uploader.py) 방금 생성하게된 카테고리 데이터들이 테이블로 들어간것을 알수있다.**
쿼리셋에서도
from product.models import Menu, Category, Drink
Category.objects.all()
데이터가 많이 들어가 있음을 이제 알수 있다.
Category.objects.vlaues()
Category.objects.all()[0].name 이거로 첫번째 데이터를 볼수있다.
이렇게 파이썬에서 프로덕트를 csv파일을 읽어서 장고 모델스의 데이터를 직접 입력하는것이 가능하다.
프로덕트는 어떻게하는지 빠르게 보도록하자
```python
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]
menu_id = Menu.objects.get(name = menu_name).id
category_id = Category.objects.get(name = category_name).id #카테고리 테이블에 데이터가 생성됬기떄문에 겟을할수있다.
그러면 프로덕트를 읽어올수있따
print(row[2])python db_uploader.py 고고
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]
drinks = row[2].split(‘, ‘)
print(drinks)상품들칸에는 여러개가 들어있어서 나눠줘야함
이제 우리가해야할일은 드링크안에있는 파일들을 하나씩 돌면서 모델에 넣어주는것이다.
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]
drinks = row[2].split(‘, ‘)
for drink in drinks:
Drink.object.create(name = drink, menu_id =. enu_id, category_id =. ategory_id)
업로더를 실행시키기 전에 데이터가 비어있는것을 확인해보자
from product.models import Menu, Category, Drink
Drink.objects.all()
sql >> select * from drink;
그럼이제 드링크오브젝트를 크리에이트하는 명령을 넣은 디비업로더를 실행시키고 (python db_uploader.py) 데이터를 확인해보자.
쿼리셋안에도
from product.models import Menu, Category, Drink
Drink.objects.all()이제 데이터들이 입력되어 있을것이다.
for drink in drinks:
if drink:
Drink.object.create(name = drink, menu_id =. enu_id, category_id = category_id)if drink 로인해 드링크의 이름이 존재할때만 저장되도록하게 바꾸면
지금까지 드링크오브젝트 크리에이트와 오브젝트겟 으로 각포린키를 잘연결해서 데이터를 입력하는 과정이었다.
그래서 이제 매번쓰기 귀찮으니까함수를 쓰도록하면
def insert_product:
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader(in_file)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]
for drink in drinks:
if drink:
drink.objects.create(name = drink, menu_id = menu_id, category_id = category_id)
세션 풀코드
import os
import django
import csv
import sys
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "starbucks_sqlite.settings")
django.setup()
from product.models import Menu, Category, Drink
CSV_PATH_PRODUCTS = './products.csv'
def insert_products:
with open(CSV_PATH_PRODUCTS) as in_file:
data_reader = csv.reader(in_file)
next(data_reader, None)
for row in data_reader:
if row[0]:
menu_name = row[0]
category_name = row[1]
menu_id = Menu.objects.get(name = menu_name).id
catagory_id = Category.objects.get(name = category_name).id
drinks = row[2].split(‘, ‘)
for drink in drinks:
if drink:
Drink.object.create(name = drink, menu_id =. enu_id, category_id =. ategory_id)