Collation이란?
Collation은 문자열 데이터의 정렬 순서와 비교 방법을 정의하는 규칙입니다. 일본어 데이터를 PostgreSQL에서 기본 ORDER BY로 정렬할 때, 현지에서 기대한 순서와 다르게 나오는 문제를 발견하여 이에 대해 조사한 내용을 공유하려고 합니다.
PostgreSQL에서 Collation
1. Collation List 조회
PostgreSQL에서 사용 가능한 Collation 목록은 다음 쿼리로 확인할 수 있습니다:
SELECT * FROM pg_collation;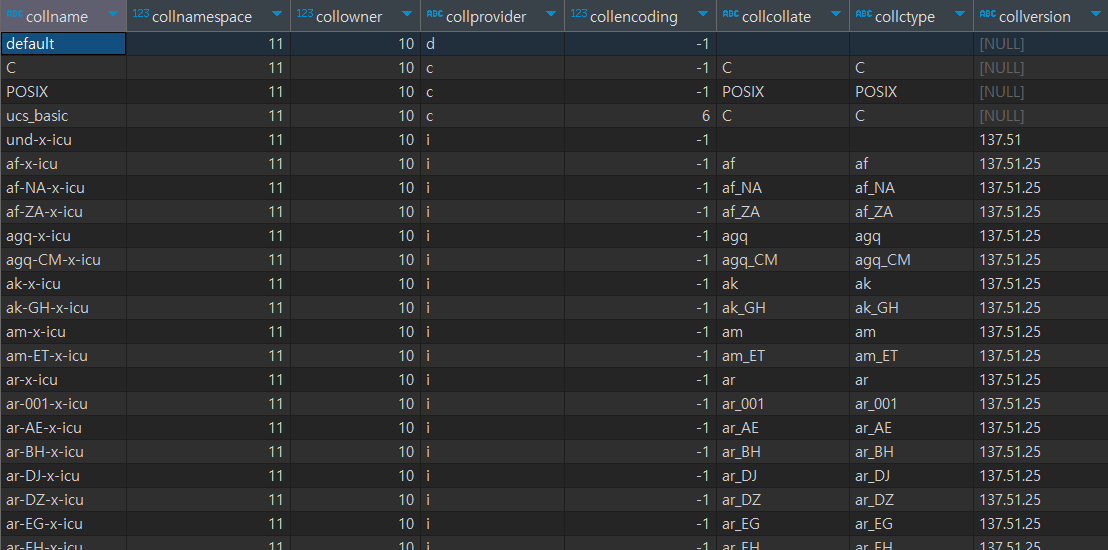
2. 현재 접속한 DB의 Collation 확인
현재 사용 중인 데이터베이스의 Collation 정보는 다음과 같이 확인할 수 있습니다:
SELECT datname, datcollate, datctype
FROM pg_database
WHERE datname = current_database();
3. 기본 Collation 설정
DB를 생성할 때 Collation을 지정하지 않으면, 기본적으로 서버의 로케일(locale)에 따라 Collation이 설정됩니다. 서버의 로케일은 아래 명령어로 확인할 수 있습니다:
$ locale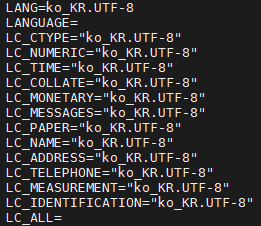
현재 서버의 로케일은 ko_KR.UTF-8입니다.
4. 이미 생성된 DB에 다른 Collation 적용 방법
이미 생성된 데이터베이스에 대해 기본 Collation과 다른 Collation을 적용하는 방법은 두 가지가 있습니다:
4.1 특정 컬럼의 Collation 변경
특정 컬럼의 Collation을 변경하려면 다음과 같이 쿼리를 작성합니다:
ALTER TABLE example_table
ALTER COLUMN name
SET COLLATION "ja-JP-x-icu";4.2 조회 시 ORDER BY에 Collation 명시
쿼리에서 ORDER BY에 직접 Collation을 지정하여 정렬할 수 있습니다:
SELECT name
FROM example_table
ORDER BY name COLLATE "ja-JP-x-icu";위 방법을 통해 일본어 현지에 특화된 Collation(ja-JP-x-icu)으로 데이터를 정렬할 수 있습니다. 일본어의 경우, 기본적으로 숫자 → 영어(소문자) → 영어(대문자) → 히라가나 → 가타카나 → 한자 순으로 정렬됩니다.
ICU(International Components for Unicode)란??
ICU는 다국어와 지역화를 지원하기 위해 개발된 오픈 소스 소프트웨어 라이브러리입니다. 이 라이브러리는 다양한 운영 체제와 프로그래밍 언어에서 사용할 수 있으며, 특히 다음과 같은 기능을 제공합니다:
- 텍스트 처리 및 유니코드 지원
- 문자 인코딩 변환
- 날짜 및 시간 형식 변환
- 숫자 및 통화 형식 변환
- 문자열 비교 및 정렬
- 달력 계산
기본 로케일 처리보다 다양한 언어와 지역에 대해 더욱 정확한 정렬 및 비교를 제공할 수 있습니다.
